【算法岗面试】某小厂E机器学习
文章目录
- 1.deepFM的FM特点,deep部分设置了多少层,依据
- 2.算法题:爬楼梯
- 3.算法题:最大子数组和
- 4.sql题:商品id、类别、价格,mysql找出找出每类前10大的商品
- 5.1000个学生成绩排序,比快排更快的方法
- 6.常用的数据预处理有哪些操作
- 7.transformer的文本抽取
- 8.反欺诈(风控)的分类算法
- 9.大数据spark和hadoop
-
- (1)Scala和PySpark
- (2)Spark原理
- (3)一个具体栗子
- Reference
1.deepFM的FM特点,deep部分设置了多少层,依据
FM模型的FM使用了隐向量特征交叉。
- 为了解决POLY2模型的缺陷,2010年提出FM模型。如下式子是FM(Factor Machine,因子分解机)二阶部分的数学表达式 ∅ FM ( w , x ) = ∑ j 1 = 1 n ∑ j 2 = j 1 + 1 n ( w j 1 ⋅ w j 2 ) x j 1 x j 2 \emptyset \operatorname{FM}(\boldsymbol{w}, \boldsymbol{x})=\sum_{j_{1}=1}^{n} \sum_{j_{2}=j_{1}+1}^{n}\left(\boldsymbol{w}_{j_{1}} \cdot \boldsymbol{w}_{j_{2}}\right) x_{j_{1}} x_{j_{2}} ∅FM(w,x)=j1=1∑nj2=j1+1∑n(wj1⋅wj2)xj1xj2
- FM和POLY2的区别是,FM用两个向量的内积 ( w j 1 ⋅ w j 2 ) \left(\boldsymbol{w}_{j_{1}} \cdot \boldsymbol{w}_{j_{2}}\right) (wj1⋅wj2)取代了单一的权重系数 W h ( j 1 , j 2 ) W_{h\left(j_{1}, j_{2}\right)} Wh(j1,j2)。
- FM权重参数量少了,降低训练开销;
- FM虽然丢失了某些具体特征组合的精确记忆能力,但泛化能力大大提高。
- FM的二阶以上交叉没有很强的意义,因为没法加速。
- FM为每个特征学习了一个隐权重向量(和矩阵分解,用隐向量代表 user 和 item 思想一样,从单纯的 user、item隐向量扩展到了所有特征上)。在特征交叉时,使用两个特征隐向量的内积作为交叉特征的权重。
- FM引入隐向量,更好解决数据稀疏性问题,ex:
- 商品推荐场景,样本有两个特征:频道(channel)和品牌(brand),某训练样本的特征组合是(ESPN, Adidas)。
- 在POLY2中,只有当ESPN和Adidas同时出现在一个训练样本时,模型才能学习到这个组合特征对应的权重;
- 在FM中,ESPN的隐向量也可以通过(ESPN, Gucci)样本进行更新,Adidas的隐向量也可以通过(NBC, Adidas)样本进行更新,即大幅降低模型,对数据稀疏性的要求。
deep设置了3层。层数要根据具体网络,如GCN就不能太深,否则会导致拉普拉斯平滑问题。这里设置3层解决非线性的问题。
2.算法题:爬楼梯
其实就是青蛙跳台阶的题目:
d p [ i ] dp[i] dp[i]是青蛙跳上一个n级的台阶总共跳法数。
class Solution {
public:
int numWays(int n) {
vector<int>dp(n+1,0);
if(n==0) return 1;//否则当n=0时下面这句的dp[1]就访问越界了
dp[0]=dp[1]=1;
for(int i=2;i<=n;i++){
dp[i]=(dp[i-1]+dp[i-2])% 1000000007;
}
return dp[n];
}
};
递归写法:
int fib(int N) {
if (N == 1 || N == 2) return 1;
return fib(N - 1) + fib(N - 2);
}
3.算法题:最大子数组和
- 定义状态:
dp[i]表示nums中以nums[i]结尾子数组的最大子序和。 - 确定状态转移方程:对
dp[i - 1]进行分类讨论:- 大于0则将当前的
nums[i]加到dp[i - 1]上(因为不管nums[i]是大于0还是小于0,以nums[i]为结尾的子数组的最大子序和,都是要加上这个数的,注意定义好的状态)。 - 小于0则另起炉灶,即
dp[i] = nums[i]。
d p [ i ] = { d p [ i − 1 ] + n u m s [ i ] , if d p [ i − 1 ] > 0 nums [ i ] , if d p [ i − 1 ] ≤ 0 d p[i]=\left\{\begin{array}{lll} d p[i-1]+n u m s[i], & \text { if } & d p[i-1]>0 \\ \text { nums }[i], & \text { if } & d p[i-1] \leq 0 \end{array}\right. dp[i]={dp[i−1]+nums[i], nums [i], if if dp[i−1]>0dp[i−1]≤0写成max的形式就不用分类讨论了: d p [ i ] = max { n u m s [ i ] , d p [ i − 1 ] + n u m s [ i ] } d p[i]=\max \{n u m s[i], d p[i-1]+n u m s[i]\} dp[i]=max{nums[i],dp[i−1]+nums[i]}
- 大于0则将当前的
- 边界+初始条件:只有一个数字时
dp[0] = nums[0]。 - 计算顺序:从小到大。
4.sql题:商品id、类别、价格,mysql找出找出每类前10大的商品
建表:
START TRANSACTION;
CREATE TABLE employee (
name text,
department text,
salary bigint
);
INSERT INTO employee VALUES ( 'alice', 'it', 1000 );
INSERT INTO employee VALUES ( 'bob', 'it', 2000 );
INSERT INTO employee VALUES ( 'david', 'it', 3000 );
INSERT INTO employee VALUES ( 'john', 'it', 2000 );
INSERT INTO employee VALUES ( 'mike', 'it', 9000 );
INSERT INTO employee VALUES ( 'henry', 'sales', 500000 );
INSERT INTO employee VALUES ( 'jason', 'sales', 9999999 );
COMMIT;
给每个部门的人,根据薪资进行部门内排序,可以使用窗口函数,对部门分类,对部门内排序DENSE_RANK(无间隔的分级):
SELECT *, DENSE_RANK() OVER(
PARTITION BY department
ORDER BY salary DESC
) AS innerrank
FROM employee;
最后:
SELECT * FROM (
SELECT *, DENSE_RANK() OVER(
PARTITION BY department
ORDER BY salary DESC
) AS innerrank
FROM employee
) AS t WHERE innerrank <= 3;
5.1000个学生成绩排序,比快排更快的方法
面试官说没有学生ID,最后输出排序后的学生成绩就好。
听了就懵了,还有比快排更快的方法?!说了一个哈希表的方法(不太确定), 以学生成绩为key值,以key为成绩的学生个数作为哈希表的value值。然后因为C++的STL中的map底层用了红黑树,排序一波会更快。
6.常用的数据预处理有哪些操作
去除唯一属性、处理缺失值、属性编码、数据标准化正则化、特征选择、主成分分析。
- 缺失值处理:
- 直接使用含有缺失值的特征
- 删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时是有效的)
- 缺失值补全:如果样本属性的距离是可度量的,则使用该属性有效值的平均值来插补缺失的值
- 高维映射(最精确):将属性映射到高维空间,采用独热码编码(one-hot)。将包含K个离散取值范围的属性值扩展为K+1个属性值,若该属性值缺失,则扩展后的第K+1个属性值置为1。
- 建模预测:将缺失的属性作为预测目标来预测,将数据集按照是否含有特定属性的缺失值分为两类,利用现有的机器学习算法对待预测数据集的缺失值进行预测。
- 数据标准化(归一化):样本属性值缩放为一定范围,如min-max标准化映射结果为0到1的区间中。
- 正则化
- 特征选择(降维):从给定的特征集合中选出相关特征子集。这是为了减轻维数灾难问题,降低学习任务的难度。常见降维方法:SVD、PCA、LDA。
7.transformer的文本抽取
类似作QA的bert模型可以。
8.反欺诈(风控)的分类算法
LR、GBDT / XGBoost分类
9.大数据spark和hadoop
(1)Scala和PySpark
(1)Scala 是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。
Scala 运行在 Java 虚拟机上,并兼容现有的 Java 程序。
Scala 源代码被编译成 Java 字节码,所以它可以运行于 JVM 之上,并可以调用现有的 Java 类库。
(2)Apache Spark是用 Scala编程语言 编写的。为了用Spark支持Python,Apache Spark社区发布了一个工具PySpark。使用PySpark,也可以使用Python编程语言中的 RDD 。
(3)PySpark提供了 PySpark Shell,它将Python API链接到spark核心并初始化Spark上下文。将Python与Spark集成就对数据科学研究更加方便。
Spark的开发语言是Scala,这是Scala在并行和并发计算方面优势的体现,这是微观层面函数式编程思想的一次胜利。此外,Spark在很多宏观设计层面都借鉴了函数式编程思想,如接口、惰性求值和容错等。
(2)Spark原理
Spark是业界主流的大数据处理利器。
- 分布式:指的是计算节点之间不共享内存,需要通过网络通信的方式交换数据。
- Spark 是一个分布式计算平台。Spark 最典型的应用方式就是建立在大量廉价的计算节点上,这些节点可以是廉价主机,也可以是虚拟的 Docker Container(Docker 容器)。
Spark 的架构图中:
- Spark 程序由 Manager Node(管理节点)进行调度组织
- 由 Worker Node(工作节点)进行具体的计算任务执行
- 最终将结果返回给 Drive Program(驱动程序)。
在物理的 Worker Node 上,数据还会分为不同的 partition(数据分片),可以说 partition 是 Spark 的基础数据单元。
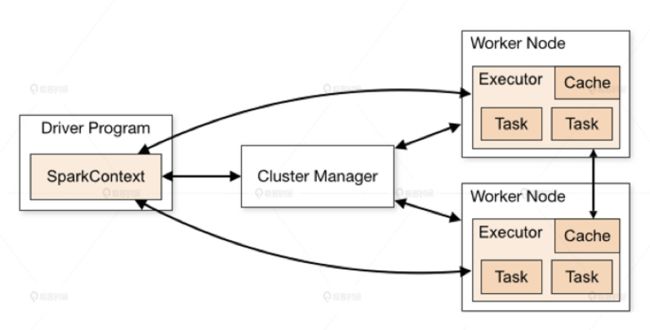
Spark 计算集群能够比传统的单机高性能服务器具备更强大的计算能力,就是由这些成百上千,甚至达到万以上规模的工作节点并行工作带来的。
(3)一个具体栗子
那在执行一个具体任务的时候,Spark 是怎么协同这么多的工作节点,通过并行计算得出最终的结果呢?这里我们用一个任务来解释一下 Spark 的工作过程。
一个具体任务过程:
(1)先从本地硬盘读取文件 textFile;
(2)再从分布式文件系统 HDFS 读取文件 hadoopFile;
(3)然后分别对它们进行处理;
(4)再把两个文件按照 ID 都 join 起来得到最终的结果。
- 在 Spark 平台上处理这个任务的时候,会将这个任务拆解成一个子任务 DAG(Directed Acyclic Graph,有向无环图),再根据 DAG 决定程序各步骤执行的方法。从图 2 中可以看到,这个 Spark 程序分别从 textFile 和 hadoopFile 读取文件,再经过一系列 map、filter 等操作后进行 join,最终得到了处理结果。

-
最关键的过程是要理解哪些是可以纯并行处理的部分,哪些是必须 shuffle(混洗)和 reduce 的部分:这里的
shuffle指的是所有 partition 的数据必须进行洗牌后才能得到下一步的数据,最典型的操作就是图 2 中的groupByKey操作和join操作。以join操作为例,必须对 textFile 数据和 hadoopFile 数据做全量的匹配才可以得到join后的dataframe(Spark 保存数据的结构)。而groupByKey操作则需要对数据中所有相同的 key 进行合并,也需要全局的 shuffle 才能完成。 -
与之相比,
map、filter等操作仅需要逐条地进行数据处理和转换,不需要进行数据间的操作,因此各 partition 之间可以完全并行处理。 -
在得到最终的计算结果之前,程序需要进行
reduce的操作,从各 partition 上汇总统计结果,随着 partition 的数量逐渐减小,reduce操作的并行程度逐渐降低,直到将最终的计算结果汇总到 master 节点(主节点)上。可以说,shuffle和reduce操作的触发决定了纯并行处理阶段的边界。

注意:
(1)shuffle 操作需要在不同计算节点之间进行数据交换,非常消耗计算、通信及存储资源,因此 shuffle 操作是 spark 程序应该尽量避免的。shuffle可以理解为一个串行操作,需要等到在此之前的并行工作完成之后才可以顺序开始。
(2)简述Spark 的计算过程:Stage 内部数据高效并行计算,Stage 边界处进行消耗资源的 shuffle 操作或者最终的 reduce 操作。
Reference
[1] https://zhuanlan.zhihu.com/p/341148358
[2] 一篇文章搞懂机器学习风控建模过程
[3] 风控8个场景中的机器学习应用
[4] 机器学习算法原理系列篇1:金融风控中的机器学习
[5] 数据预处理(方法总结)