数据指标间相关性分析
最近想做一个自动化分析指标间相关性系数的东西,不知道能做什么东西,因为连怎么进行相关性分析都不会…… 所以就从头呗,先了解相关性分析,嘿嘿。
先发一版,存太久了
互联网大学中的相关性分析的各种方式汇总:
文中图片来源:相关性分析的五种方法_Munger6的博客-CSDN博客_相关性分析
1、可视化-图表
折线图啊、散点图啊,把数据都放上,用sns.pairplot()
虽然可以清晰地看出相关关系,但是无法对相关关系进行准确的量化,到底相关系数是多少?
当数据超过两组时也无法完成各组数据间的相关分析
2、协方差及协方差矩阵
当两个变量变化趋势相同,协方差为正值,说明两变量正相关;
当两个变量变化趋势相反,协方差为负值,说明两变量负相关;
当两个变量相互独立,协方差为0,说明两变量不相关;
两个变量的协方差:

三个变量的协方差:
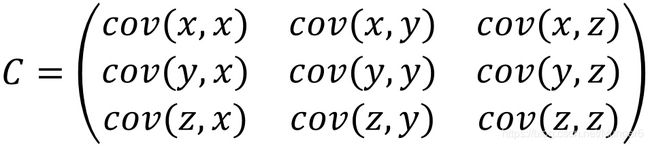
还是对变量间的相关性没有办法度量
3、相关系数(Pearson系数)
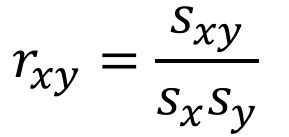
Sxy:样本协方差;Sx:X样本的标准差;Sy:Y样本的标准差;
样本的协方差、标准差,分母是n-1.
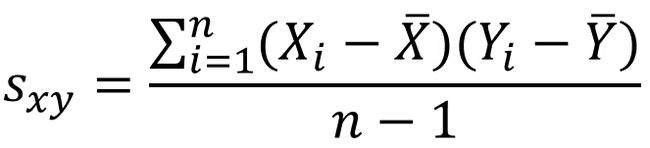
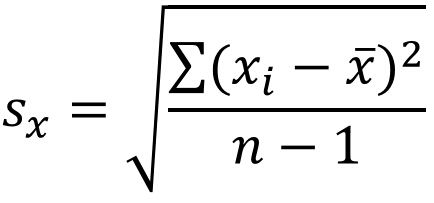
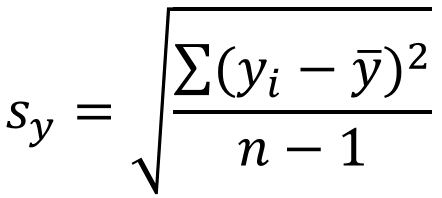
4、回归分析
一元回归:
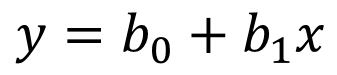
变量系数:
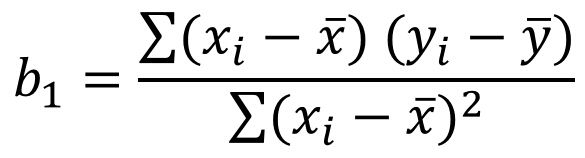
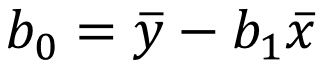
多元回归:
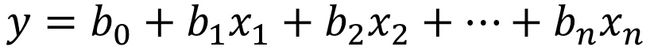
5、信息熵及互信息
1、计算相关性系数判断:
r值代表相关性强度,取值范围为[-1,1],>0 ,为正相关。<0,为负相关。
| |r| | 相关性 |
| >0.95 | 显著性相关 |
| >=0.8&<0.95 | 高度相关 |
| >=0.5&<0.8 | 中度相关 |
| >=0.3&<0.5 | 低度相关 |
| <=0.3 | 弱相关 |
三个相关性系数(pearson, spearman, kendall)反应的都是两个变量之间变化趋势的方向以及程度。
Pearson系数(不是p值):皮尔逊相关系数,线性相关系数,协方差与标准差的比值,对数据质量要求较高:
①数据是正态分布时,因为求皮尔森相关性系数以后,通常还会用t检验之类的方法来进行皮尔森相关性系数检验,而 t检验是基于数据呈正态分布的假设的。
②实验数据之间的差距不能太大,不能有离散点,异常值。
③连续性变量
Spearman系数:斯皮尔曼相关性系数,没有很多数据条件要求,当数据不是正太分布,用这个,适用范围广,适合于定序变量或不满足正态分布假设的等间隔数据
Kendall系数:肯德尔相关性系数,又称肯德尔秩相关系数,应用于 分类变量,适合于定序变量或不满足正态分布假设的等间隔数据
【统计学】区分定类、定序、定距、定比变量!! https://blog.csdn.net/YYIverson/article/details/100068865?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164700775216780255276714%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164700775216780255276714&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-100068865.pc_search_result_control_group&utm_term=%E5%AE%9A%E5%BA%8F%E5%8F%98%E9%87%8F&spm=1018.2226.3001.4187
https://blog.csdn.net/YYIverson/article/details/100068865?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164700775216780255276714%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164700775216780255276714&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-100068865.pc_search_result_control_group&utm_term=%E5%AE%9A%E5%BA%8F%E5%8F%98%E9%87%8F&spm=1018.2226.3001.4187
分类变量可以理解成有类别的变量,可以分为
无序的,比如性别(男、女)、血型(A、B、O、AB);
有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。
通常需要求相关性系数的都是有序分类变量。
import pandas as pd
draw = pd.DataFrame()
print('*Pearson\n',draw.corr())
print('*Spearman\n',draw.corr('spearman'))
print('*kendall',draw.corr('kendall'))2、假设检验
在《赤裸裸的统计学》中,把两个假设称为 零假设 和 对立假设,感觉这种好理解点
3、计算显著性系数判断(主要是P值)
P值是用来进行显著性检验的,用来检验变量之间是否有差异以及差异是否显著。若P值>0.05代表数据之间不存在显著性差异;若P值<0.05,代表数据之间存在显著性的差异。
在《赤裸裸的统计学》书中,讲概率<5%,则推翻零假设

4、R2

相关性学习体系:
适合本小编,还望各位也多多指导指导