特征工程:特征提取入门学习(附案例)
文章目录
- 一、字典特征提取
- 二、文本特征提取
-
- 1、特征词(单词)提取
- 2、中文文本特征提取
- 3、文本特征提取改进——Tf-idf
一、字典特征提取
对字典数据进行特征值化
特征提取的API
sklearn.feature_extraction
transfer.fit_transform(X):
X:字典或者包含字典迭代器的返回值
返回一个稀疏矩阵
transfer.get_feature_names_out():返回类别名称
代码实现:
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
"""
字典特征提取
:return:
"""
data = [{'city': '北京', 'temperature': 18}, {'city': '上海', 'temperature': 21}, {'city': '广州', 'temperature': 29},
{'city': '深圳', 'temperature': 30}]
# 1、实例化一个转换器类
# sparse=False 会使返回一个二维数组,否则默认返回一个稀疏矩阵
transfer = DictVectorizer()
# transfer = DictVectorizer(sparse=False)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("特征名字:\n", transfer.get_feature_names_out())
print("data_new:\n", data_new)
return None
if __name__ == '__main__':
dict_demo()

返回一个稀疏矩阵
矩阵中的元组 表示稀疏矩阵非零值的位置(行、列)
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
"""
字典特征提取
:return:
"""
data = [{'city': '北京', 'temperature': 18}, {'city': '上海', 'temperature': 21}, {'city': '广州', 'temperature': 29},
{'city': '深圳', 'temperature': 30}]
# 1、实例化一个转换器类
# sparse=False 会使返回一个二维数组,否则默认返回一个稀疏矩阵
# transfer = DictVectorizer()
transfer = DictVectorizer(sparse=False)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("特征名字:\n", transfer.get_feature_names_out())
print("data_new:\n", data_new)
return None
if __name__ == '__main__':
dict_demo()
transfer = DictVectorizer(sparse=False)
返回一个二维数组

将 字典特征值转换为 one-hot 编码
应用场景:
- 数据集中类别比较多
- 数据集本身就是字典类型
二、文本特征提取
作用:对文本特征进行特征值化
API:
sklearn.feature_extraction
1、特征词(单词)提取
sklearn.feature_extraction.text.CountVectorizer(stop_words=[]):统计样本每个特征词出现的个数。
stop_words:停用词 这些词不希望作为特征词提取。可以传一个列表,然后不提取这些词
主要是空格分隔,一个字母不单独提取
代码实现
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
"""
文本特征抽取
:return:
"""
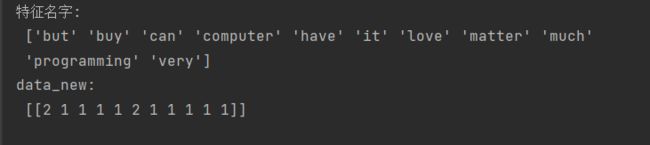
data = ["I love programming very much,but I do not have computer,but It does not matter,I can buy it!"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("特征名字:\n", transfer.get_feature_names_out())
print("data_new:\n", data_new.toarray())
return None
if __name__ == '__main__':
count_demo()

打印出了每个单词出现的频率
修改:加上停用词
transfer = CountVectorizer(stop_words=['do', 'not', 'does'])
2、中文文本特征提取
也可以使用sklearn.feature_extractionAPI进行特征提取,只不过每个词语都要用空格隔开,这种效果显然不好。
可以采用其他库 例如 jieba
安装:pip3 install jieba
代码实现
import jieba
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
"""
中文特征词提取
:return:
"""
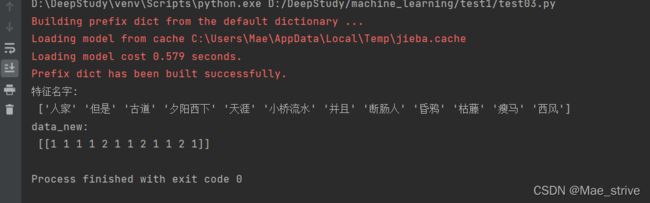
data = "枯藤老树昏鸦,小桥流水人家,古道西风瘦马,夕阳西下,断肠人在天涯。——我是断肠人并且我是瘦马,但是我不在天涯"
# 1、将中文文本进行分词
data_new = [cut_word(data)]
# 2、实例化一个转换器类
transfer = CountVectorizer()
# 3、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("特征名字:\n", transfer.get_feature_names_out())
print("data_new:\n", data_final.toarray())
return None
def cut_word(text):
return " ".join(list(jieba.cut(text)))
if __name__ == '__main__':
count_demo()
实际就是先将中文词给切割开,然后再进行统计
3、文本特征提取改进——Tf-idf
Tf-idf主要思想:如果一个词在一篇文章中出现概率高,而在另一篇当中出现概率低,则很好的认为这个词是关键词。
自动提取关键词,而舍去不必要的词(像因为,所有……这些词在每篇文章中概率都很高)
API:
from sklearn.feature_extraction.text import TfidfVectorizer
```python
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def dfidf_demo():
"""
dfidf特征提取
:return:
"""
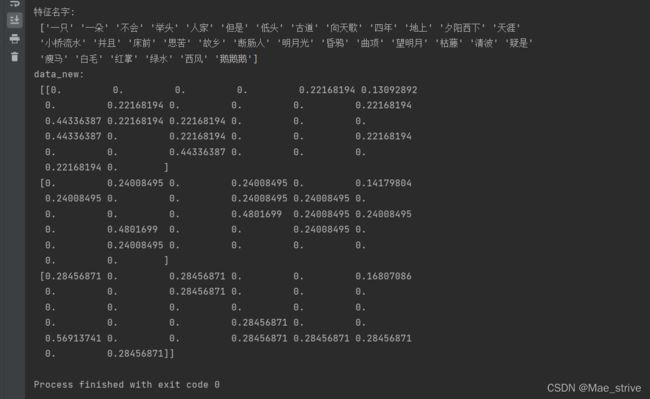
data = ["枯藤老树昏鸦,小桥流水人家,古道西风瘦马,夕阳西下,断肠人在天涯。——我是断肠人并且我是瘦马,但是我不在天涯",
"床前明月光,疑是地上霜,举头望明月,低头思苦想——我是床前的一朵明月光,但是我不四年故乡",
"鹅鹅鹅,曲项向天歌,白毛浮绿水,红掌拨清波——我是一只鹅,但是我不会拨清波"]
# 1、将中文文本进行分词
data_new = []
for sent in data:
print(type(sent))
data_new.append(cut_word(sent))
# 2、实例化一个转换器类
transfer = TfidfVectorizer()
# 3、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("特征名字:\n", transfer.get_feature_names_out())
print("data_new:\n", data_final.toarray())
return None
def cut_word(text):
return " ".join(list(jieba.cut(text)))
if __name__ == '__main__':
dfidf_demo()
概率多大,说明越适合用来分类。