Java面试37题总结 有一定基础的同学
ok:for(int i=10;i>0;i--){for( int j=0;j<10;j++){System.out.println("i="+i+"j="+j);if(j=7)break ok;}}
5、 请用最有效率的方法写出计算2乘以8的结果(A) short s=1;s=s+1;(B) short s=1;s+=1;(A)(B)两个代码有没有问题,如果有,是哪里的问题?答:(A)有问题。s+1的运算是先把他们转成int,而int赋值给short会出现类型转换错误(B)没有问题,是因为扩展的复制运算符其实隐含了一个强制类型转换s+=1等价于s=(s的数据类型)s+1
注: ※数据类型转换A:byte、short、char-int-long-float-doubleB: byte、short、char相互之间不转换,他们参与运算首先转换为int类型面试题:byte b1=3,b2=4,b;b=b1+b2;b=3+4;那句是编译失败的呢?为什么?(byte一个字节,short两字节,int四字节)b=b1+b2; //这个是类型提升,把byte转换为int,再赋值给byte的时候出现类型转换问题b=3+4; //常量,先把结果计算出来,然后看是否在byte的范围内,如果在就不报错字符串数据和其他数据做+,结果是字符串类型这里的+不是假发运算,而是字符串连接符System.out.println("hello"+'a'+1)//helloa1System.out.println('a'+1+"hello")//98hello
6、为什么0.01+0.09=0.0999999999,如何解决
public BigDecimal subtract(BigDecimal subtrahend) public BigDecimal multiply(BigDecimal multiplicand)
public BigDecimal divide(BigDecimal divisor) public BigDecimal divide(BigDecimal divisor,int scale,int roundingMode):商,几位小数,如何舍取
A:随着类的加载而加载B:优先于对象存在C:被类的所有对象共享(如果某个成员变量是被所有对象共享,那么它就应该定义为静态的)D:可以通过类名调用其实它本身也可以通过对象名调用推荐使用类名调用静态修饰的内容一般我们称为:与类相关的,类成员
使用final关键字修饰一个变量时,是指引用变量不能变,引用变量所指向的对象中的内容还是可以改变的。例如,对于如下语句: final StringBuffer a=new StringBuffer("immutable");执行如下语句将报告编译期错误: a=new StringBuffer("");但是,执行如下语句则可以通过编译: a.append(" broken!");
final可以修饰类,该类不能被继承。final可以修饰方法,该方法不能被重写。(覆盖,复写)final可以修饰变量,该变量不能被重新赋值。因为这个变量其实常量。
A:字面值常量"hello",10,trueB:自定义常量final int x = 10;
作用域 当前类 同一package 子孙类 其他package
public √ √ √ √
protected √ √ √ ×
friendly √ √ × ×(不写关键字)
private √ × × ×
10、String s=“Hello”;s=s+" World!"这两行代码实现后,原始的String对象中的内容有没有改变?
因为String被设计为不可变类,它所有的对象都是不可改变的,运行这两行代码只是改变了s的引用,它指向了另一个Hello World!的对象。而原来的对象的内容还是String,并没有改变。
正因为String的这种特性,在开发中,我们基本要对String作大量操作是用StringBuffer和StringBuilder,这样每次修改String就不会在内存中剩余大量冗余内存。
11、String能否被继承
String是final类型的类,所以不能被继承。
12、String与StringBuffer的区别
String表示内容不可变的字符串,StringBuffer为内容可变的字符串。
String实现了equals方法,new String(“abc”).equals(new String(“abc”)的结果为true,而StringBuffer没有实现equals方法,所以,new StringBuffer(“abc”).equals(new StringBuffer(“abc”)的结果为false。
接着要举一个具体的例子来说明,我们要把1到100的所有数字拼起来,组成一个串。
StringBuffer sbf = new StringBuffer();
for(int i=0;i<100;i++)
{
sbf.append(i);
}
上面的代码效率很高,因为只创建了一个StringBuffer对象,而下面的代码效率很低,因为创建了101个对象。
String str = new String();
for(int i=0;i<100;i++)
{
str = str + i;
}
13、StringBuilder与StringBuffer的区别:
StringBuilder是线程不安全的,但是执行效率高
StringBuilder是线程安全的,但执行效率低
在类中最好用StringBuffer,因为类很可能会在多线程的情况下存在,所以用StringBuffer
如果一个字符串在方法里面定义,这种情况下只可能有一个线程访问它,并确定不存在不安全因素了就用StringBuilder
14、String有无length()方法,数组有无length方法
数组没有length()这个方法,有length的属性。String有有length()这个方法。
15、对于下面的语句,一共创建多少个对象:String s="a"+"b"+"c"+"d";
创建一个String对象
对于如下代码:
String s1 = "a";
String s2 = s1 + "b";
String s3 = "a" + "b";
System.out.println(s2 == "ab"); //false
System.out.println(s3 == "ab"); //true
这说明javac编译可以对字符串常量直接相加的表达式进行优化,不必要等到运行期去进行加法运算处理,而是在编译时去掉其中的加号,直接将其编译成一个这些常量相连的结果。
17、写出运行结果System.out.println(a / 0);a = 20;} catch (ArithmeticException e) {a = 30;return a;/** return a在程序执行到这一步的时候,这里不是return a而是return 30;这个返回路径就形成了。* 但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40* 再次回到以前的返回路径,继续走return 30;*/} finally {a = 40;// return a;//如果这样结果就是40了。}结果返回的是30
所以是在return钱执行的finally 但因为return 30这个路径已经形成,所以是返回30
18、finally,final,finalize的区别:int test()
{
try
{ return func1();
}
finally
{ return func2();
}
}
int func1()
{ System.out.println("func1");
return 1;
}
int func2()
{ System.out.println("func2");
return 2;
}
结果:func1
func2
2
结论:finally中的代码比return 和break语句后执行
final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
内部类要访问局部变量,局部变量必须定义成final类型,例如,一段代码……
finally是异常处理语句结构的一部分,表示总是执行。
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。JVM不保证此方法总被调用。
19、写出比较常见的几个Exception
NullPointerException、ArrayIndexOutOfBoundsException、ClassCastException、
OutOfMemoryException、classnotfoundexception、arithmeticexception、
illegalargumentexception、SecturityException、FileNotFoundException
20、sleep()和wait()的区别:
sleep就是正在执行的线程主动让出cpu,cpu去执行其他线程,在sleep指定的时间过后,cpu才会回到这个线程上继续往下执行,如果当前线程进入了同步锁,sleep方法并不会释放锁,即使当前线程使用sleep方法让出了cpu,但其他被同步锁挡住了的线程也无法得到执行。
wait是指在一个已经进入了同步锁的线程内,让自己暂时让出同步锁,以便其他正在等待此锁的线程可以得到同步锁并运行,只有其他线程调用了notify方法(notify并不释放锁,只是告诉调用过wait方法的线程可以去参与获得锁的竞争了,但不是马上得到锁,因为锁还在别人手里,别人还没释放。
24、什么是线程,进程,以及线程的各种状态
线程:线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
进程:进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位.

25、简述synchronized和java.util.concurrent.locks.Lock的异同
private class Subtractor implements Runnable
{
@Override
public void run() {
// TODO Auto-generated method stub
while(true)
{
/*synchronized (ThreadTest.this) {
System.out.println("j--=" + j--);
//这里抛异常了,锁能释放吗?
}*/
lock.lock();
try
{
System.out.println("j--=" + j--);
}finally
{
lock.unlock();
}
}
}
}
26、子线程循环10次,接着主线程循环100,接着又回到子线程循环10次,接着再回到主线程又循环100,如此循环50次,请写出程序。
下面使用jdk5中的并发库来实现的:
public class ThreadTest
{
private static Lock lock = new ReentrantLock();
private static Condition subThreadCondition = lock.newCondition();
private static boolean bBhouldSubThread = false;
public static void main(String [] args)
{
ExecutorService threadPool = Executors.newFixedThreadPool(3);
threadPool.execute(new Runnable(){
public void run()
{
for(int i=0;i<50;i++)
{
lock.lock();
try
{
if(!bBhouldSubThread)
subThreadCondition.await();
for(int j=0;j<10;j++)
{
System.out.println(Thread.currentThread().getName() + ",j=" + j);
}
bBhouldSubThread = false;
subThreadCondition.signal();
}catch(Exception e)
{
}
finally
{
lock.unlock();
}
}
}
});
threadPool.shutdown();
for(int i=0;i<50;i++)
{
lock.lock();
try
{
if(bBhouldSubThread)
subThreadCondition.await();
for(int j=0;j<10;j++)
{
System.out.println(Thread.currentThread().getName() + ",j=" + j);
}
bBhouldSubThread = true;
subThreadCondition.signal();
}catch(Exception e)
{
}
finally
{
lock.unlock();
}
}
}
}
这两个类都实现了List接口(List接口继承了Collection接口),他们都是有序集合,即存储在这两个集合中的元素的位置都是有顺序的,相当于一种动态的数组,我们以后可以按位置索引号取出某个元素,,并且其中的数据是允许重复的,这是HashSet之类的集合的最大不同处,HashSet之类的集合不可以按索引号去检索其中的元素,也不允许有重复的元素(本来题目问的与hashset没有任何关系,但为了说清楚ArrayList与Vector的功能,我们使用对比方式,更有利于说明问题)。
接着才说ArrayList与Vector的区别,这主要包括两个方面:.
(1)同步性:
Vector是线程安全的,也就是说是它的方法之间是线程同步的,而ArrayList是线程序不安全的,它的方法之间是线程不同步的。如果只有一个线程会访问到集合,那最好是使用ArrayList,因为它不考虑线程安全,效率会高些;如果有多个线程会访问到集合,那最好是使用Vector,因为不需要我们自己再去考虑和编写线程安全的代码。
备注:对于Vector&ArrayList、Hashtable&HashMap,要记住线程安全的问题,记住Vector与Hashtable是旧的,是java一诞生就提供了的,它们是线程安全的,ArrayList与HashMap是java2时才提供的,它们是线程不安全的。所以,我们讲课时先讲老的。
(2)数据增长:
ArrayList与Vector都有一个初始的容量大小,当存储进它们里面的元素的个数超过了容量时,就需要增加ArrayList与Vector的存储空间,每次要增加存储空间时,不是只增加一个存储单元,而是增加多个存储单元,每次增加的存储单元的个数在内存空间利用与程序效率之间要取得一定的平衡。Vector默认增长为原来两倍,而ArrayList的增长策略在文档中没有明确规定(从源代码看到的是增长为原来的1.5倍)。ArrayList与Vector都可以设置初始的空间大小,Vector还可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法。
总结:即Vector增长原来的一倍,ArrayList增加原来的0.5倍。
28、HashMap和Hashtable的区别
二.同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的
三.值:只有HashMap可以让你将空值作为一个表的条目的key或value
一个是存储单列数据的集合,另一个是存储键和值这样的双列数据的集合,List中存储的数据是有顺序,并且允许重复;Map中存储的数据是没有顺序的,其键是不能重复的,它的值是可以有重复的。
30、List、Set、Map是否都集成Collection接口?
List,Set是。Collection不是。Collection集合和Map集合都是接口
Map集合和Collection集合的区别:、
Map存储的是键值对,键唯一,值可重复。
Collection存储的是单独出现的。Set是唯一的,List是可重复的
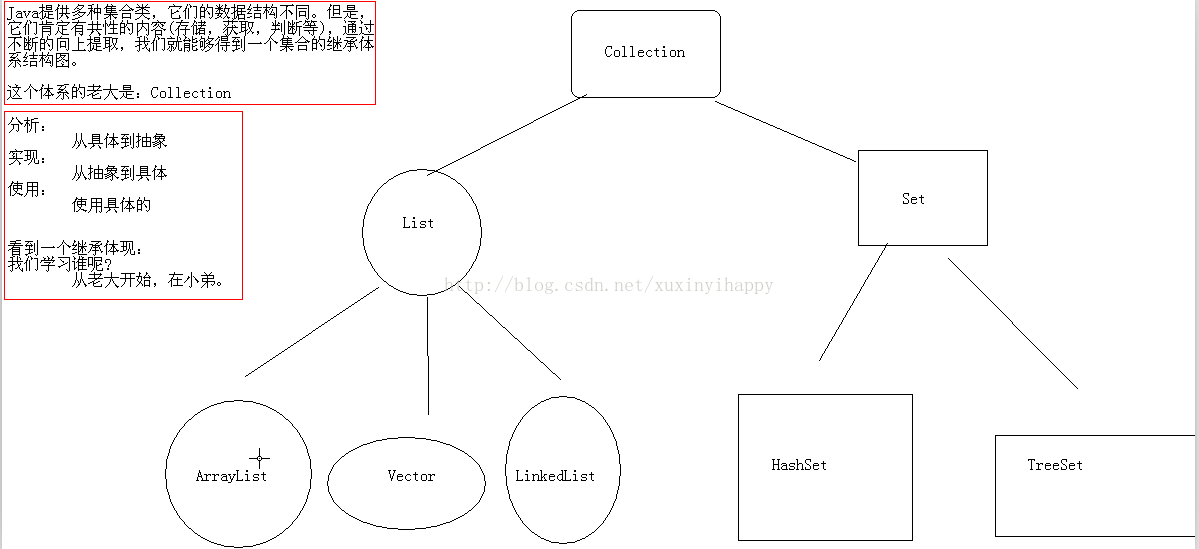
31、ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差,而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
LinkedList也是线程不安全的,LinkedList提供了一些方法,使得LinkedList可以被当作堆栈和队列来使用。
32、Collection与Collections的区别
Collection是集合类的上级接口,继承与他的接口主要有Set 和List.
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
33、你所知道的集合类都有哪些?主要方法?
Map 提供了一个更通用的元素存储方法。 Map 集合类用于存储元素对(称作"键"和"值"),其中每个键映射到一个值。
Collection
ArrayList/VectorList
HashSet/TreeSetSet
34、说出常用的类、包、接口。各举5个PropetiesHashTable
Map
Treemap/HashMap
常用的类:BufferedReader BufferedWriter FileReader FileWirter String Integer java.util.Date,System,Class,List,HashMap
常用的包:java.lang java.io java.util java.sql ,javax.servlet,org.apache.strtuts.action,org.hibernate
常用的接口:Remote List Map Document NodeList ,Servlet,HttpServletRequest,HttpServletResponse,Transaction(Hibernate)、Session(Hibernate),HttpSession
35、描述一下JVM加载class文件的原理和机制
JVM中类的装载是由ClassLoader和它的子类来实现的,Java ClassLoader 是一个重要的Java运行时系统组件。它负责在运行时查找和装入类文件的类。
36、heap和stack有什么区别:
java的内存分为两类,一类是栈内存,一类是堆内存。栈内存是指程序进入一个方法时,会为这个方法单独分配一块私属存储空间,用于存储这个方法内部的局部变量,当这个方法结束时,分配给这个方法的栈会释放,这个栈中的变量也将随之释放。
堆是与栈作用不同的内存,一般用于存放不放在当前方法栈中的那些数据,例如,使用new创建的对象都放在堆里,所以,它不会随方法的结束而消失。方法中的局部变量使用final修饰后,放在堆中,而不是栈中。
37、GC是什么?为什么要有GC?