【李宏毅2021机器学习深度学习】10-1 概述领域自学习(Domain Adaptation)
![]()
文章目录
- 参考链接
-
- 技术背景:Domain Shift, 解决方法:Domain Adaptation(Transfer Learning 的一种)
- Domain Shift的3种不同类型(输入输出分布不同,输入输出分布概率不同,输入输出关系不同)
- Target Domain(测试资料)的5种不同类型的不同处理办法:
-
- Target Domain 上,就有一大堆的资料:(直接拿 Target Domain 的资料来训练就好了)
- Target Domain 的资料 也有标註,但是量非常地少:(微调,真的小小调,不要偏离太远,记得李沐老师也有讲:[11.1 迁移学习【斯坦福21秋季:实用机器学习中文版】](https://www.bilibili.com/video/BV1SL4y1t7ZL?spm_id_from=333.999.0.0))
- Targe Domain 上有大量的资料,但是这些资料是没有标註(作业要求)
-
- Domain Adversarial Training(类似GAN)
- Considering Decision Boundary
- 问题:根本不知道 Target Domain 裡面,有什麼样的类别:(解决办法参考Universal Domain Adaptation 这篇文章)
- 不只没有 Label,而且 Data 还很少,比如说我就只有一张而已:(Testing Time Training)
- 对 Target Domain 一无所知:(Domain Generalization)
参考链接
视频地址:https://www.bilibili.com/video/BV1zA411K7en?p=43
21年 课堂笔记:https://github.com/unclestrong/DeepLearning_LHY21_Notes
技术背景:Domain Shift, 解决方法:Domain Adaptation(Transfer Learning 的一种)
假设今天测试资料,跟训练资料的分布不一样,怎麼办呢
,那这种问题 叫做Domain Shift,也就是当你的训练资料跟测试资料,它的分布有些不同的时候,这种状况叫做 Domain Shift
那今天就是要讲 Domain Adaptation 的技术,那 Domain Adaptation 的技术,也可以看做是 Transfer Learning 的一种
Transfer Learning 就是,你在 A 任务上学到的技能,可以被用在 B 任务上,那对於 Domain Adaptation 来说,你的训练资料是一个 Domain,你的测试资料是另外一个 Domain,你在训练资料上面,某一个 Domain 上学到的资讯,你要把它用到另外一个 Domain,用到测试资料上面,所以你是把一个 Domain 学到的知识,用在另外一个 Domain 上,所以它可以看做是,Transfer Learning 的其中一个环节,那在过去上课的录影裡面,有完整的讲了 Transfer Learning 相关的技术,那因為今天时间有限,我们就只 Focus 在,Domain Adaptation 的部分就好,如果你有兴趣的话,你可以再看一下过去上课的录影
Domain Shift的3种不同类型(输入输出分布不同,输入输出分布概率不同,输入输出关系不同)
-
模型输入的资料的分布有变化的状况,那输入分布有变化是一种可能性
-
其实还有另外一种可能性是,输出的分布也可能有变化,举例来说 在你的训练资料上面,可能每一个数字它出现的机率都是一样的,但是在测试资料上面,可能每一个输出的机率是不一样的,有可能某一个数字它输出的机率特别大,有没有可能有这种事情发生呢,这也是有可能的
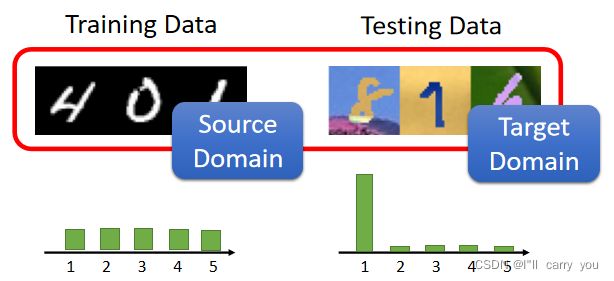
-
那这也是一种 Domain Shift,还有一种更罕 比较罕见,但也不是完全不可能发生的状况是,输入跟输出虽然分布可能是一样的,但它们之间的关係变了
那我们今天呢 只专注在,输入资料不同的 Domain Shift 的上面(这里只讲情况一),好 那在等一下的课程裡面,这个测试的资料,我们说它来自 Target Domain 训练的资料,我们说它来自 Source Domain,所以 Source Domain 是我们的训练资料,Target Domain 是我们的测试资料
Target Domain(测试资料)的5种不同类型的不同处理办法:
Target Domain 上,就有一大堆的资料:(直接拿 Target Domain 的资料来训练就好了)
Target Domain 的资料 也有标註,但是量非常地少:(微调,真的小小调,不要偏离太远,记得李沐老师也有讲:11.1 迁移学习【斯坦福21秋季:实用机器学习中文版】)
那你拿 Target Domain 的 Data,只稍微跑个两 三个(Epoch)就足够了
那為了避免 Overfitting 的情况,过去就有很多的 Solution,比如说 把 Learning Rate 调小一点,举例来说 你要让(fine tune)前,跟(fine tune)后的模型的参数,不要差很多,或者是让(fine tune)前,跟(fine tune)后的模型,它的输入跟输出的关係,不要差很多 等等,那有很多不同的方法,那这边呢 我们就不细讲
Targe Domain 上有大量的资料,但是这些资料是没有标註(作业要求)
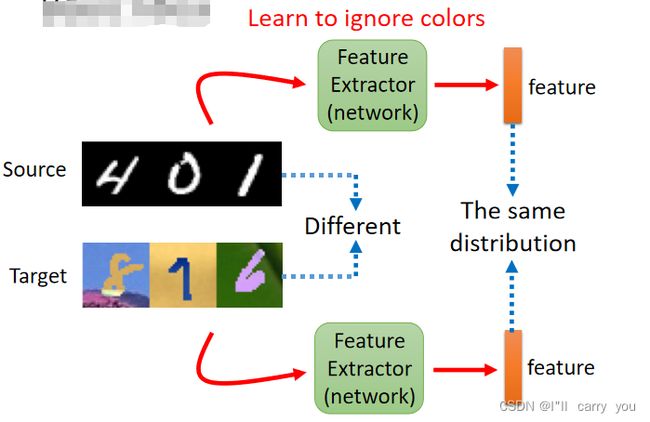
Domain Adversarial Training(类似GAN)
那我们现在要做的事情就是,训练一个 Domain 的 Classifier,这个 Domain 的 Classifier,它就是一个二元的分类器,它吃这个 vector 当作输入,它要做的事情就是判断说,这个 vector 是来自於 Source Domain,还是来自於 Target Domain
而 Feature Extractor 它学习的目标,就是要去想办法骗过这个 Domain Classifier,那听到骗过这件事情
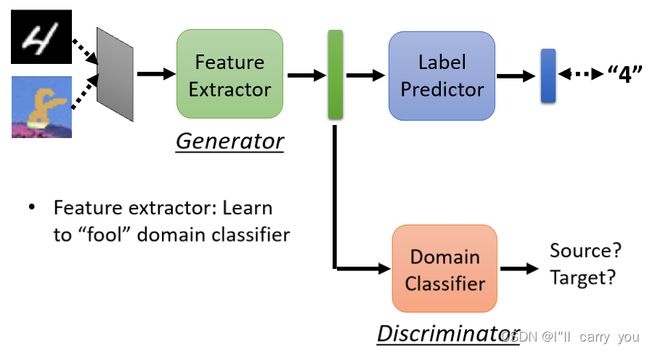

这样做 有点问题的


Considering Decision Boundary
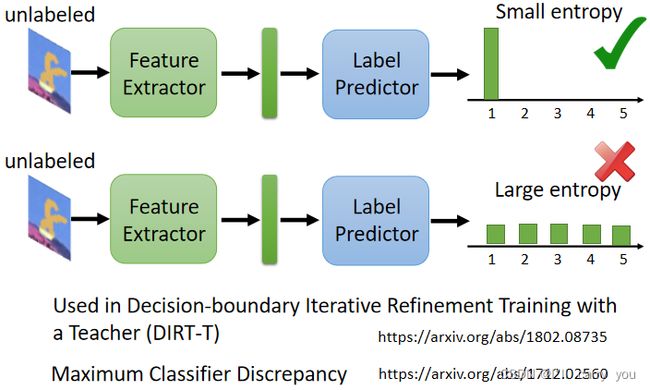
那这只是一种招数,并不是全部,那你可以参考一下文献,比如说有一个知名的方法叫做 DIRT-T,DIRT-T,这个 DIRT-T 它其实,它 Paper 裡面还特别告诉你说,这个要唸 Dirty,要唸 Dirty,这个大家都是这个模型命名大师,都会命名一些很有创意的名字,好 这个 DIRT-T 是一个招数,还有另外一个招数叫这个,Maximum Classifier Discrepancy,如果你要在这个 Domain Adaptation 作业裡面,得到最好的结果的话,那这些招数是不可或缺的,那实际上这些招数怎麼进行,还挺复杂,这个就留给大家自己研究
问题:根本不知道 Target Domain 裡面,有什麼样的类别:(解决办法参考Universal Domain Adaptation 这篇文章)
那这边还有一个问题,什麼样的问题呢,我们到目前為止,好像都假设说,Source Domain 跟 Target Domain,它的类别都要是一模一样,Source Domain 假设是影像分类的问题,Source Domain 有老虎 狮子跟狗,Target Domain 也应该要有老虎 狮子跟狗,但是真的一定会这样吗
Target Domain 是没有 Label 的,我们根本不知道 Target Domain 裡面,有什麼样的类别
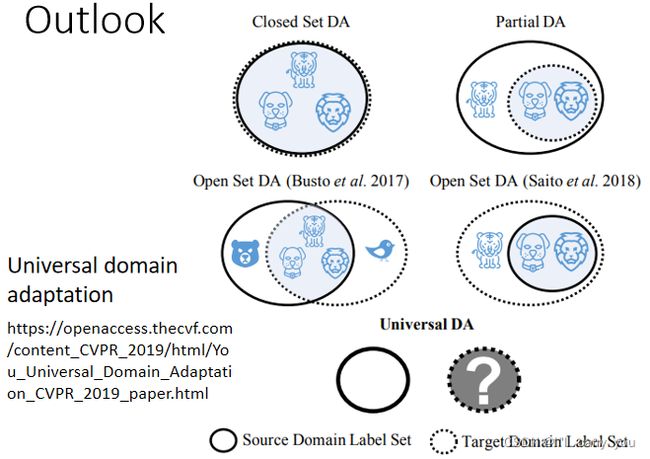
而在这个图示裡面 这个实心的,实线的圈圈代表,Source Domain 裡面有的东西,这个虚实线的圈圈,代表 Target Domain 裡面有的东西,所以呢 有没有可能是,这个 Source Domain 裡面的东西比较多,Target Domain 裡面的东西比较少呢,有没有可能是,Source Domain 裡面的东西比较少,Target Domain 的东西比较多呢,有没有可能两者虽然有交集,但是各自都有独特的类别呢,这都是有可能发生的
所以在这个前提之下,你说 Source Domain 跟 Target Domain,你硬要把它们完全 Align 在一起,听起来有点问题呀,因為举例来说在这个 Case 裡面,哦 你说你要让 Source Domain 的 Data,跟 Target Domain 的 Data,它们的 Feature 完全 Match 在一起,那意味著说,你硬是要让老虎去变得跟狗像,或者是老虎硬是要变得跟狮子像,到时候你就分不出老虎这个类别了
听起来就是有问题的方法,那怎麼解决这个问题,怎麼解决 Source Domain 跟 Target Domain,它可能有不一样的 Label 的问题,那你可以参见这个,Universal Domain Adaptation 这篇文章
不只没有 Label,而且 Data 还很少,比如说我就只有一张而已:(Testing Time Training)
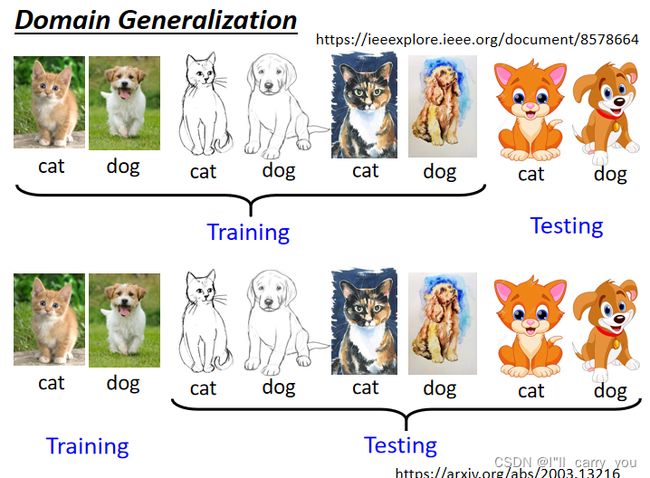
对 Target Domain 一无所知:(Domain Generalization)
这个时候又分成两种情形,对 Target Domain 一无所知的这种问题,这个时候我们就不叫 Domain 的 Adaptation,通常就叫 Domain Generalization
-
一种状况是我的训练资料非常地丰富,本来就包含了各式各样不同的 Domain,假设你要做猫狗的分类器,那你现在呢 在训练资料裡面,有真实的猫跟狗的照片,有素描的猫跟狗的照片,然后有这个水彩画的猫跟狗的照片,期待因為训练资料有多个 Domain,模型可以学到如何弥平 Domain 间的差异,今天有测试资料是卡通的猫跟狗,它也可以处理,这是一种状况,那这种状况你还比较能够想像要怎麼处理,那我们这边就不细讲,我们都只各放一些有代表性的论文,给大家参考
-
但还有另外一种,你会觉得真的不知如何下手的状况是,假设训练资料只有一个 Domain 呢,假设你的训练资料只有一个 Domain,而测试资料有多种不同的 Domain 的话,怎麼处理呢,在文献上也不是没有人试,也是有人试著去解惑这种问题的,那他怎麼做呢,这细节我们就不讲啦,在概念上就是有点像是 Data Augmentation,虽然你只有一个 Domain 的资料,想个 Data Augmentation 的方法,去產生多个 Domain 的资料,然后你就可以套上面这个 Secnario 来做做看,看能不能够在测试的时候,新的 Domain 都可以做好,好 这个是 Domain Generalization
那这个部分就是很简短的跟大家带过,这个 Domain Adaptation 的种种技术,更多的细节,在下一堂课助教的说明裡面