前言
前几天在Python交流群里边,有个叫【^-^】的粉丝分享了一道Python基础的题目,跟快递信息有关的,题目如下:

现在想要达到的效果如下:

一、思路
针对这个问题,首先需要读取列表的信息,之后对列表进行切割,获取列表中的省或者直辖市信息,之后再判断省位信息中是否包含在地址信息中,使用列表追加的方法,进行处理,这里经常会用到字典和列表来存储信息,屡试不爽。
二、解决方案
针对该问题,粉丝【^-^】给出了解决方法,直接上代码如下:
# coding: utf-8
def sp(s):
citys = []
dizhi = []
dice = {}
dic = {}
for i in s:
# print(i)
a = i[1]
city = a[0:2]
zlib = a[0:2]
citys.append(city)
dizhi.append(zlib)
cityss = set(citys) # 去重
citysss = list(cityss) # 转为列表
d = dice.fromkeys(citysss)
for key in d:
h = []
for j in s:
b = j[1]
lgezi = b[0:2]
if lgezi == key:
h.append(j)
dic[key] = h
# print(dic)
for key in dic:
# 遍历字典
print(key, dic[key])
if __name__ == '__main__':
sp([
['王*龙', '北京市海淀区苏州街大恒科技大厦南座4层'],
['郭*峰', '河南省商丘市高新技术开发区恒宇食品厂'],
['赵*生', '河北省唐山市朝阳道与学院路路口融通大厦2408室'],
['张*', '陕西省咸阳市文汇东路6号西藏民族大学'],
['刘*民', '北京市大兴区南海家园四里7号楼1单元902'],
['郭*兰', '湖北省武汉市湖北省'],
['张*强', '河北省张家口市经开区钻石南路11号'],
['鞠*龙', '山东省潍坊市玉清街江山帝景B区12号楼一单元14楼'],
['李*', '北京市海淀区西二旗智学苑5号楼超市'],
['许*康', '北京市西城区西单北大街甲133号'],
['叶*生', '江苏省扬州市扬子江中路756号'],
['赵*兴', '北京市海淀区西二旗上地信息路1号金远见大楼华纬讯301'],
['徐*革', '北京市海淀区闵庄路3号102栋二层206'],
['徐*', '安徽省淮南市金荷小区(金格商场旁)'],
['雷*', '北京市朝阳区望京街道望京sohoT1C座1201'],
['庄*', '浙江省杭州市恒生电子大厦'],
['蔡*恩', '湖北省武汉市仁和路沙湖港湾B区1103'],
['陈*', '江苏省苏州市巴城镇湖滨北路193号牛吃蟹庄'],
['黄*', '北京市朝阳区霄云路26号鹏润大厦A座33层'],
['魏*飞', '河北省石家庄市新石北路与红旗大街交口开元大厦502室'],
['张*', '山东省济南市兴港路三庆城市主人'],
['段*琪', '山西省临汾市福利路尧乡小区'],
['刘*', '北京市昌平区龙禧三街骊龙园601'],
['王*生', '上海市杨浦区邯郸路复旦大学遗传学楼319室'],
['王*君', '江苏省扬州市叶挺路318号建行营业部'],
['王*义', '北京市东城区环球贸易中心D座'],
['韩*鉴', '北京市门头沟区滨河路葡东小区七号楼4层D门'],
['罗*若', '陕西省西安市龙首北路宫园一号5号楼4单元'],
['王*', '北京市海淀区上地东路盈创动力大厦e座801c源清慧虹信息科技'],
['马*', '湖北省武汉市庙山中路10号名湖豪庭7栋1403'],
['常*峰', '山西省太原市迎新街'],
['侯*', '浙江省杭州市江陵路1541号'],
['许*娟', '上海市宝山区殷高西路高境二村177号502'],
['朱*', '北京市海淀区东升镇宝盛东路奥北科技园领智中心B座5层'],
['吴*峰', '湖北省武汉市幸福路鸿福花园1栋3006'],
['付*诚', '北京市海淀区观林园'],
['滕*', '江苏省南京市秣周东路11号双子楼9号楼15楼君度科技'],
['石*刚', '辽宁省大连市大连市经济技术开发区福泉北路20号'],
['程*', '北京市昌平区沙河兆丰家园'],
['武*', '北京市昌平区回龙观西大街龙腾苑五区16号楼1单元202'],
['郭*欣', '北京市西城区阜成门 万通新世界 B座1503']
])
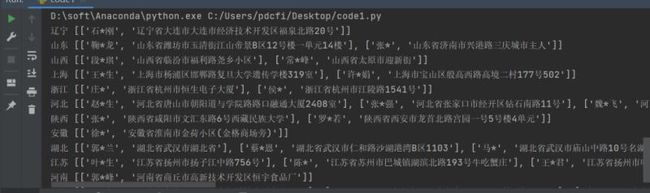
代码不算多,需要花点时间去读,不过涉及的知识点并不复杂,基本上有点Python基础,也可以理解。代码运行之后,可以看到效果如下:
不过后来我在读取这份代码的时候,发现中间有个地方写的着实有些冗余,稍微修改下,代码方面简洁一些,一些函数和变量命名加了一些对应的现实意义的单词,可读性强了一丢丢,代码如下:
# coding: utf-8
def sp(text):
city = []
dice = {}
dic = {}
address = [info[-1] for info in text]
for city_info in address:
city.append(city_info[0:2])
cities = list(set(city)) # 先去重,然后转为列表
# print(cities)
dict_keys = dice.fromkeys(cities)
for key in dict_keys:
h = []
for info in text:
address = info[-1]
city_info = address[0:2]
if city_info == key:
h.append(info)
dic[key] = h
# print(dic)
for key in dic:
# 遍历字典
print(key, dic[key])
if __name__ == '__main__':
sp([
['王*龙', '北京市海淀区苏州街大恒科技大厦南座4层'],
['柴*虎', '北京市昌平区北七家镇顺玮阁小区'],
['韩*', '辽宁省葫芦岛市小庄子乡宝仓村'],
['魏*森', '北京市昌平区于辛庄路,赋腾国创中心,2楼'],
['邓*明', '北京市丰台区新华街三里1号楼305'],
['赵*', '上海市宝山区宝山区高境镇高境一村11号后3号车库'],
['徐*亮', '北京市海淀区花园东路11号泰兴大厦302'],
['张*凡', '北京市昌平区沙河镇松兰堡迎客家园507'],
['赵*', '北京市北京市海淀区农大国际创业园b区6065'],
['顾*天', '北京市海淀区上地东路1号华控大厦'],
['丁*', '上海市杨浦区安波路533弄硕和商务2号楼1102'],
['封*号', '江苏省苏州市陆家镇陆丰东路199号水岸香堤2#2309'],
['王*哲', '上海市静安区曲沃路430弄15号401'],
['刘**', '湖北省武汉市左岭镇 武汉华星光电一号门'],
['付*', '安徽省合肥市长江西路305号电信新技术楼'],
['鲁*', '湖北省武汉市武大科技园宏业楼C座'],
['张*', '北京市朝阳区小营路13号亚非大厦7层8704室'],
['齐*', '湖北省武汉市珞喻路马家庄'],
['王*', '北京市海淀区北坞嘉园北里9号楼三单元D01'],
['陈*龙', '北京市朝阳区北卫新园'],
['曹*生', '江苏省无锡市澄南花苑'],
['沈*', '北京市海淀区中关村南大街甲18号北京国际大厦D座7层'],
['续*', '山西省晋中市中都广场12层畅快车贷'],
['赵*全', '河北省唐山市李钊庄镇大王庄村'],
['成*', '上海市虹口区东五小区641号楼2007'],
['方*', '上海市闵行区联航路1399弄28号1103室'],
['曹*', '上海市浦东新区向城路15号24C'],
['韩*德', '北京市大兴区枣园北里小区1号楼8单元202'],
['金*鹏', '浙江省温州市温州职业技术学院生活区快递中心'],
['陶*明', '浙江省嘉兴市南溪路桂苑小区23幢603'],
['李*ir', '北京市丰台区南苑乡 德鑫家园9号楼5单元50'],
['姜*杰', '山东省临沂市凤凰岭大街惠民早餐'],
['l*xq', '辽宁省沈阳市卫工南街4-4网点2门瀚辰跆拳道'],
['单*成', '山东省日照市日照职业技术学院'],
['韩*红', '上海市杨浦区隆昌路619号10号楼二楼'],
['魏*琪', '北京市丰台区汉威国际广场4区12号楼'],
['杨*康', '北京市丰台区丰台科技园汉威广场12栋'],
])
三、小小花絮
这里其实还可以通过正则表达式来做地址信息的提取,代码如下:
with open("地址信息.txt", 'r', encoding='utf-8') as f:
for line in f:
content = re.compile(r"\['(?P.*?)', '(?P.*?)'\]", re.S)
result = content.finditer(line)
for i in result:
name = i.group("name")
address = i.group("address")
print(name, address)
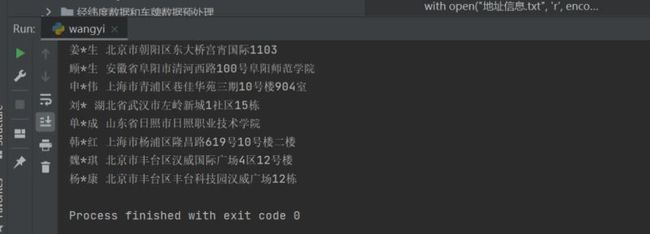
可以得到用户的姓名和地址信息,如下图所示:
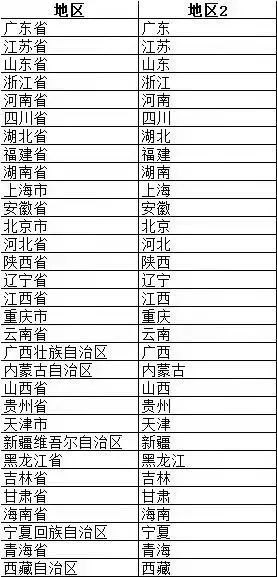
之后将得到的数据可以存excel,之后通过pandas进行提取,这里使用小小明大佬给的指导代码,可以提取省位,真不错!
df['地区2']=df.地区.apply(lambda s: s[:(s in ("黑龙江省", "内蒙古自治区"))+2])
四、总结
我是Python进阶者。本文实际生活中的快递信息,基于Python编程,使用Python基础知识中的列表、字典、函数等,实现了数据信息的提取过程。
以上就是基于Python实现快递信息提取的详细内容,更多关于Python快递信息提取的资料请关注脚本之家其它相关文章!