C++实现推理, 基于android、ncnn、nano、nx、Xilinx等嵌入式平台
kirin 980 CPU
Jetson Nano
Jetson Xavier NX
Jetson TX2
Xilinx ZCU104
ncnn




Xilinx ZCU104 
1: Onnx-simplifier
https://github.com/daquexian/onnx-simplifier
Our solution
ONNX Simplifier is presented to simplify the ONNX model. It infers the whole computation graph and then replaces the redundant operators with their constant outputs.
Web version
We have published ONNX Simplifier on https://convertmodel.com. It works out of the box and doesn’t need any installation. Just open the webpage, choose ONNX as the output format, check the onnx simplifier and then select your model to simplify. Note that the web version is in its very early stage, if the web version doesn’t work well for you, you can install the Python version following the instructions below.
Python version
pip3 install -U pip && pip3 install onnx-simplifier
Then
python3 -m onnxsim input_onnx_model output_onnx_model
For more functions like skipping optimization and setting input shape manually (when input shape is dynamic itself), try the following command for help message
python3 -m onnxsim -h
python -m onnxsim ${INPUT_ONNX_MODEL} ${OUTPUT_ONNX_MODEL}
from onnxsim import simplify
onnx_model = onnx.load(output_path) # load onnx model
model_simp, check = simplify(onnx_model)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, output_path)
print('finished exporting onnx ')
使用onnx-simple让更多后处理再trt上进行,或者模型上进行

出现:
ONNX export failure: Your model ir_version is higher than the checker’s.
升级onnx
pip3.7 install --upgrade onnx -i https://mirrors.aliyun.com/pypi/simple
2: NanoDet
thinkpad 940MX 14ms
项目作者选择使用 COCO mAP (0.5:0.95) 作为评估指标,兼顾检测和定位的精度,在 COCO val 5000 张图片上测试,并且没有使用 Testing-Time-Augmentation。
在这种设置下,320 分辨率输入能够达到 20.6 的 mAP,比 tiny-yolov3 高 4 分,只比 yolov4-tiny 低 1 个百分点。
将输入分辨率与 YOLO 保持一致,都使用 416 输入的情况下,NanoDet 与 yolov4-tiny 得分持平。具体结果如下表所示:




判断模型是否时候tensorrt加速,即tensorrt加速原理???
如果用Python跑
原始的模型:
Nano:
可以看到 FPS 大概在 7 左右,模型推理時間為 80 ms,解碼時間為 40 ms, 也可优化解码,利用gpu编程加速
tensorrt加速后的:
Nano
可以看到 FPS 大概在 9 左右,模型推理時間從 78ms 提升至 25ms 左右,可以看到 TensorRT 加速了大概 3
倍左右,可以看到是 decode 的部分大大的影響了 FPS 的數字
Tx2 : 模型推理時間12ms
所以解码部分,最好也用CUDA进行加速


3: YoloV4-tiny
thinkpad 940MX 20ms
顾名思义yolov4-tiny就是yolov4的简化版。在特征提取时没有采用Mish激活函数,并且在特征加强层只采用了一个特征金字塔,没有像yolov4那样再进行下采样。
yolov4的训练参数有64363101个,而yolov4-tiny只有5918006个,比yolov4少了十倍。因此yolov4-tiny加载模型的速度上也是更快的。
yolov4-tiny实测速度大概在22fps左右,在中等点的显卡上速度差不多能达到几百。我看到个在1080ti上的效果是在300fps+。这速度是非常快的。
当然更少的参数以及更快的速度都是用准确率换的。因为yolov4-tiny只选择了两层来送入特征金字塔。所以对于小物体检测,以及两个目标在一起(一个目标将另一个目标遮挡了一部分是很难检测到的)

Yolov4-tiny使用特征金字塔网络提取不同尺度的特征图,进而提高目标检测速度,而不使用Yolov4方法中使用的空间金字塔池和路径聚合网络。同时,Yolov4-tiny使用 13×13和26×26 两种不同比例尺的feature map来预测检测结果


tensorrt 速度测试
环境: thinkpad GTX 940max
int8 yolov4 31ms
fp16 yolov4 52ms
fp32 yolov4 53ms
fp16 yolov4-tiny 19ms(除了nms,其余都是gpu上处理)
不使用 tensorrt 帧率:
16.8 fps
Nano和NX采用了控制变量进行实验,TX2则是采用我们之前测试的数据进行对比和评估。
在NX与Nano相比较之下,NX的识别帧率是Nano的3倍左右,是TX2的1.5倍左右。
这也验证了在相同的条件下(FP16精度)运行了相同的目标检测(37 mAP),Xavier NX的运行频率为74Hz,比TX2快57%。相比于TX2,NX在IO口上进行了升级,例如10 Gbit / s USB 3.1或PCIe Gen4;Xavier NX现在支持INT8量化。

其中yolov4-tiny还可以优化
从FLOPs计算考虑:


4: Jetpack
https://www.cnblogs.com/cumtchw/p/12800910.html
我的 Jetson Nano 是安裝 Jetpack 4.4.1 所以 Cuda 版本是 10.2,
https://blog.csdn.net/zbb297918657/article/details/106390209/
5: YOLO 尺寸,剪枝
例1:
我做了以下設定
subdivisions=16 width, height=288 (input_size) max_batches=4000
(classes2000,不得低於4000) steps=3200, 3600 (max_batches0.8,
max_batches*0.9) filters=18 ((classes+Bbox)*anchors=(1+5)*3=18)
classes=1 Image for post 使用 k-means 來計算資料集中出適合的 anchors,結果會輸出成
anchors.txt Image for post 到 yolov4-tiny-obj.cfg 的第 219, 268 行修改
anchors 成 21, 34, 29, 62, 56, 46, 45, 89, 68,124, 100,191
例2:又如:
主要从三个方面来说明,网络的输入、结构、输出。
(1)网络输入:原论文中提到的大小320320,416416,608*608。这个大小必须是32的整数倍数,yolo_v3有5次下采样,每次采样步长为2,所以网络的最大步幅(步幅指层的输入大小除以输出)为2^5=32。
(2)网络结构:作者首先训练了一个darknet-53,训练这个主要是为了主要有两个目的:a.这个网路结构能在ImageNet有好的分类结果,从而说明这个网路能学习到好的特征(设计新的网络结构,这个相当于调参,具体参数怎么调,就是炼丹了),b.为后续检测模型做初始化。作者在ImageNet上实验发现这个darknet-53,的确很强,相对于ResNet-152和ResNet-101,darknet-53不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比他们少。
网络降低32倍,16倍,8倍下采样
(3)网络输出:a.首先先确定网络输出特征层的大小。比如输入为320320时,则输出为320/32=10,因此输出为1010大小的特征层(feature
map),此时有1010=100个cell;同理当输入为416416时输出的特征层为1313大小的特征层,1313=169个cell;输入为608608时,输出的feature
map大小为1919,cell有19*19=361个。进行每进行一次up-sample时,输出特征层扩大一倍。
如:
yoloV3,yoloV5剪枝:
yolov5-pruning
6: EfficientNet-lite

7: RepVGG
更强基础网络选择
https://blog.csdn.net/wzz18191171661/article/details/112691604
对于基准分类网络而言,一般都会包含多个具有不同配置的网络架构,具有代表性的就是MobileNet和ShuffleNet网络,小模型可以进行轻量化部署,适合应用于一个算力较弱的嵌入式设备中,如rk3399、rk3288和Rapi3等;大模型用来进行服务端部署,适合应用到带有显卡的服务器上面,如GTX1080Ti、GTX2080Ti等,由于该设备的算力比较充足,即使是利用大模型也能获得实时的运行速度。
RepVGG也提供两大类型的网络配置,具体的细节如上表所示,RepVGG-A表示的是一种比较轻量型的网络,整个网络的层数会少一些,当前分类性能也会差一些;RepVGG-B表示的是一种高精度类型的网络,整个网路会更深一些,分类精度更高一些,适用于服务端部署。整个RepVGG网络包含5个Stage,Stage1仅仅包含一个残差块,输出的特征映射大小为112112,残差块的通道个数取min(64,64a);Stage2包含2个残差块,输出的特征映射大小为5656,残差块的通道个数为64a个;Stage3包含4个残差块,输出的特征映射大小为2828,残差块的通道个数为128a个;Stage4包含14个残差块,输出的特征映射大小为1414,残差块的通道个数为256a个;Stage5包含1个残差块,输出的特征映射大小为7*7,残差块的通道个数为512b个。整个网络通过参数a和参数b来形成不同版本的变种,具体的变种如下表所示,参数a和参数b用来控制残差块的通道个数,参数a用来控制stage1-stage4阶段的通道个数,参数b用来控制stage5阶段的通道个数,一般情况下a < b,主要的原因是Stage5中需要具有更多的通道个数,从而获得一些更鲁邦的特征表示,有利于后续的头网络输出更准确的预测结果。

上表给出了RepVGG与不同计算量的ResNe及其变种在精度、速度、参数量等方面的对比。可以看到:RepVGG表现出了更好的精度-速度均衡,比如
RepVGG-A0比ResNet18精度高1.25%,推理速度快33%;
RepVGG-A1比Resnet34精度高0.29%,推理速度快64%;
RepVGG-A2比ResNet50精度高0.17%,推理速度快83%;
RepVGG-B1g4比ResNet101精度高0.37%,推理速度快101%;
RepVGG-B1g2比ResNet152精度相当,推理速度快2.66倍。


RepVGG算法实现步骤
步骤1-获取并划分训练数据集,并对训练集执行数据增强操作;
步骤2-搭建RepVGG训练网络,训练分类网络,直到网络收敛为止;
步骤3-加载训练好的网络,对该网络执行重参数化操作,具体的细节如上节所述; 步骤4-加载重参数化后的模型,执行模型推理。
对比:

从某种程度上讲,RepVGG应该是ACNet的的一种极致精简,比如上图给出了ACNet的结构示意图,它采用了 三种卷积设计;而RepVGG则是仅仅采用了 三个分支设计。ACNet与RepVGG的另外一点区别在于:ACNet是将上述模块用于替换ResBlock或者Inception中的卷积,而RepVGG则是采用所设计的模块用于替换VGG中的卷积。
8: YoloV5
thinkpad 940mx 51ms (yolov5s.pt - trt_model)
prepareImage 7.39 8.36
execute 61.17 63.39
postProcess 9.31 10.65
Total time 77.87 82.40 (164)
1050ti 31ms (yolov5s.pt - trt_model)
1050ti 53ms (yolov5smpt - trt_model)
1050ti 112ms (yolov5l.pt - trt_model)
YOLOv5s.pt模型测试:
在TX2平台的测试速度,TX2平台平均耗约42ms,相较于RTX2080Ti速度慢了7倍(42ms/6ms)。
在Nano平台的测试速度,Nano平台平均耗时约120ms
其他测试82ms速度,前后处理,推理
,相较于RTX2080Ti速度慢了20倍(120ms/6ms)。
在NX平台的测试速度,NX平台推理部分平均耗时约30ms,相较于RTX2080Ti速度慢了2.5倍(15ms/6ms)。
NX有6核 CPU,使用数量也会响应速度,基本上可用满足50ms,20fps
前期跑几帧的情况,需要测试30s以后的运行情况:
nx的cpu和gpu,t470p的940mx和i7 cpu:
size:640
940mx nx
前处理: 7.49 11.43
推理: 58.47 27.25
后处理: 8.92 26.36
单帧耗时: 75.88 65.03(前后处理没有cuda编程)
size:512
940mx nx
前处理: 5.76 7.43
推理: 58.47 22.65
后处理: 6.02 20.20
稳定后,持续跑的耗时:
size:640
940mx nx
前处理: 5.04 ms 5.1 ms
推理: 52ms 19ms
后处理: 5.7ms 8.6ms
单帧耗时: 62.74ms 32.7ms(前后处理没有cuda编程)
https://github.com/ultralytics/yolov5
解读yolo
https://zhuanlan.zhihu.com/p/172121380/



tensort 推理,也可使用Onnx-simplifier简化的onnx生成trt
简化后:

简化前:

此外,需要注意的是YOLOV5:
在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
a.yoloV4这里填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一样的效果。
b.yolov5训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
yoloV5切片方式:

Fcos作用
普通下采样:即将一张640 × 640 × 3的图片输入3 × 3的卷积中,步长为2,输出通道32,下采样后得到320 × 320 × 32的特征图,那么普通卷积下采样理论的计算量为:
FLOPs(conv) = 3 × 3 × 3 × 32 × 320 × 320 = 88473600
Focus:将640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过1 × 1的卷积操作,输出通道32,最终变成320 × 320 × 32的特征图,那么Focus理论的计算量为:
FLOPs(Focus) = 1 × 1 × 12 × 32 × 320 × 320 = 39321600
可以明显的看到,Focus的计算量比普通卷积要少许多,是普通卷积的4/9倍,并且是在没有信息丢失的情况下。
综上所述,其实就可以得出结论,Focus的作用无非是使图片在下采样的过程中,可以一定程度上减少了模型的计算量,并且不会带来信息丢失,为后续的特征提取保留了更完整的图片下采样信息。
Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。
而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。

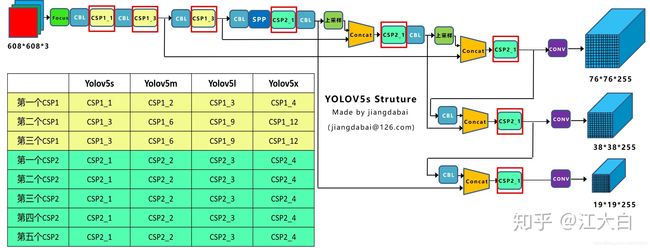
如果移植海思芯片或者赛灵思:
建议把yolov5的focus层替换为conv层(stride为2),upsample层替换为deconv层
则Caffe需要有upsample_param 和permute_param,需要添加相关层,或者直接其他Caffe拿

这个是从右到左的方向,将高分辨率的图片,分成r*r个小的channel,这样输入就变小了
9: YoloX
Anchor-free
YOLOX作者便去掉了anchor box,和FCOS一样,每个grid都只预测一个目标。
去掉了anchor box,也就是去掉了size的先验,故而FPN肯定会出现问题:如何做尺度分配?对于这一问题,YOLOX直接使用FCOS的路子,预先设定一个尺寸范围,根绝每个gt的size来判断应该分配到哪个尺度上去。这个预先设定的size范围。
对于一个给定的gt边界框,首先根据它的size确定所匹配的尺度,然后就和YOLOv3一样了,计算它在这个尺度上的中心点位置,计算中心点偏差 [公式] ,至于宽高 [公式] ,就直接作为回归目标。
 没有用focal loss,cls分支只计算正样本分类loss。简而言之cls用于分类但不用于划分正负样本,正负样本交给obj branch做了。另外使用SimOTA之后,FCOS样本匹配阶段的FPN分层就被取消了,匹配(包括分层)由SimOTA自动完成。
没有用focal loss,cls分支只计算正样本分类loss。简而言之cls用于分类但不用于划分正负样本,正负样本交给obj branch做了。另外使用SimOTA之后,FCOS样本匹配阶段的FPN分层就被取消了,匹配(包括分层)由SimOTA自动完成。
yolox-s net:


稳定后,持续跑的耗时:
size:640
1050ti
yolox_s yolox_m
fp16单帧耗时: 29ms 53ms(前后处理没有cuda编程)
测试来看,速度比yoloV5同档次的快,但是如果不训模型,直接用COCO训的模型进行测试,效果稍微差些。
size:640
940mx
yolox_s
fp16单帧耗时: 87ms(前后处理没有cuda编程)
测试来看,速度比yoloV5同档次的cha

10: Light-Weight RefineNet
重量级的包括
FCN,Segnet,RefineNet,PSPNet,Deeplab v1&v2&v3

改进前 refineNet:


改进后 refineNet即LW-refineNet:
Time:
940 mx (Resnet50) tensorrt fp32 : 187 ms
940 mx (Resnet50) tensorrt fp16: 163 ms
gtx1060 fp32 , 21fps: 47ms
改进的基于1080ti还是比较重

1)替换33卷积为11卷积
虽然理论3*3卷积理论上有更大的感受野有利于语义分割任务,但实际实验证明,对于RefineNet架构的网络其并不是必要的。
2)省略RCU模块
作者尝试去除RefineNet网络中部分及至所有RCU模块,发现并没有任何的精度下降,并进一步发现原来RCU blocks已经完全饱和。
测试发现,1)的改进直接减少了2倍的参数量降低了3倍的浮点计算量,2)的改进则进一步使参数更少浮点计算量更小。
3)使用轻量级骨干网
作者发现即使使用轻量级NASNet-Mobile 、MobileNet-v2骨干网,网络依旧能够达到非常稳健的性能表现,性能不会大幅下降。
实验结果
软硬件平台:8GB RAM, Intel i5-7600 处理器, 一块GT1080Ti GPU,CUDA 9.0 ,CuDNN 7.0。

网络输入,512×512×3
网络输出,128*128×C
最后resize回原图,得到最终分割情况


11: Xilinx FPGA
https://www.xilinx.com/html_docs/vitis_ai/1_3/zmw1606771874842.html


Caffe Model Directory Structure
├── code # Contains test , training and quantization scripts.
│
│
├── readme.md # Contains the environment requirements, data preprocess and model information.
│ Refer this to know that how to test and train the model with scripts.
│
├── data # Contains the dataset that used for model test and training.
│ When test or training scripts run successfully, dataset will be automatically placed in it.
│ In some cases, you may also need to manually place your own dataset here.
│
├── quantized
│ │
│ ├── deploy.caffemodel # Quantized weights, the output of vai_q_caffe without modification.
│ ├── deploy.prototxt # Quantized prototxt, the output of vai_q_caffe without modification.
│ ├── quantize_test.prototxt # Used to run evaluation with quantize_train_test.caffemodel.
│ │ Some models don't have this file if they are converted from Darknet (Yolov2, Yolov3),
│ │ Pytorch (ReID) or there is no Caffe Test (Densebox).
│ │
│ ├── quantize_train_test.caffemodel # Quantized weights can be used for quantized-point training and evaluation.
│ ├── quantize_train_test.prototxt # Used for quantized-point training and testing with quantize_train_test.caffemodel
│ │ on GPU when datalayer modified to user's data path.
│ └── DNNC
│ └──deploy.prototxt # Quantized prototxt for dnnc. It's the deploy.prototxt without option 'keep fixed neuron'.
│
│
└── float
├── trainval.caffemodel # Trained float-point weights.
├── test.prototxt # Used to run evaluation with python test codes released in near future.
└── trainval.prorotxt # Used for training and testing with caffe train/test command
when datalayer modified to user's data path.Some models don't
have this file if they are converted from Darknet (Yolov2, Yolov3),
Pytorch (ReID) or there is no Caffe Test (Densebox).
Tensorflow Model Directory Structure
├── code # Contains test code which can run demo and evaluate model performance.
│
│
├── readme.md # Contains the environment requirements, data preprocess and model information.
│ Refer this to know that how to test the model with scripts.
│
├── data # Contains the dataset that used for model test and training.
│ When test or training scripts run successfully, dataset will be automatically placed in it.
│
├── quantized
│ ├── deploy.model.pb # Quantized model for the compiler (extended Tensorflow format).
│ └── quantize_eval_model.pb # Quantized model for evaluation.
│
└── float
└── frozen.pb # Float-point frozen model, the input to the `vai_q_tensorflow`.
The pb name of different models may be different.
Pytorch Model Directory Structure
├── code # Contains test and training code.
│
│
├── readme.md # Contains the environment requirements, data preprocess and model information.
│ Refer this to know that how to test and train the model with scripts.
│
├── data # Contains the dataset that used for model test and training.
│ When test or training scripts run successfully, dataset will be automatically placed in it.
│
├── quantized
│ ├── bias_corr.pth # Quantized model.
│ ├── quant_info.json # Quantization steps of tensors got. Please keep it for evaluation of quantized model.
│ ├── _int.py # Converted vai_q_pytorch format model.
│ └── _int.xmodel # Deployed model. The name of different models may be different.
│
│
└── float
└── _int.pth # Trained float-point model. The pth name of different models may be different.
Path and name in test scripts could be modified according to actual situation.
其中ZCU104情况:
基础环境配置
模型运行情况:
https://github.com/Xilinx/Vitis-AI/tree/master/models/AI-Model-Zoo
模型量化测试工具:
https://github.com/Xilinx/Vitis-AI/tree/master/tools
转caffe模型比较舒服:
先量化再部署,工具链DNNK
用decent量化,dnnc编译部署 .sh执行
模型参数和下载链接
https://github.com/Xilinx/Vitis-AI/tree/master/models/AI-Model-Zoo/model-list




测试新闻:
http://xilinx.eetrend.com/content/2019/100044257.html

12: Tips
Caffe
13: ncnn安装及测试
①:下载
git clone https://github.com/Tencent/ncnn.git
②: 配置cmakelist
set(OpenCV_DIR /home/ting/opencv-3.4.3/build/build)
③:对应cmakelist路径:
/home/ting/ncnn/tools/CMakeLists.txt
/home/ting/ncnn/examples/CMakeLists.txt
④:编译
mkdir -p build
cd build
cmake ..
make -j4


⑤:
//验证
//test
cp ../examples/squeezenet_v1.1.bin examples/
cp ../examples/squeezenet_v1.1.param examples/
cd examples
./squeezenet test.jpg
// 验证
根目录下examples/synset_words.txt,看一下类别代表什么
⑥:其他模型bin和param参数
https://github.com/nihui/ncnn-assets/tree/master/models
⑦:
为了更好验证,修改代码
#include