1. 前言
什么是 Beautiful Soup 4 ?
Beautiful Soup 4(简称 BS4,后面的 4 表示最新版本)是一个 Python 第三方库,具有解析 HTML 页面的功能,爬虫程序可以使用 BS4 分析页面无素、精准查找出所需要的页面数据。有 BS4 的爬虫程序爬行过程惬意且轻快。
BS4 特点是功能强大、使用简单。相比较只使用正则表达式的费心费力,BS4 有着弹指一挥间的豪迈和潇洒。
2. 安装 Beautiful Soup 4
BS4 是 Python 第三库,使用之前需要安装。
pip install beautifulsoup4
2.1 BS4 的工作原理
要真正认识、掌握 BS4 ,则需要对其底层工作机制有所了解。
BS4 查找页面数据之前,需要加载 HTML 文件 或 HTML 片段,并在内存中构建一棵与 HTML 文档完全一一映射的树形对象(类似于 W3C 的 DOM 解析。为了方便,后面简称 BS 树),这个过程称为解析。
BS4 自身并没有提供解析的实现,而是提供了接口,用来对接第三方的解析器(这点是很牛逼的,BS4 具有很好的扩展性和开发性)。无论使用何种解析器,BS4 屏蔽了底层的差异性,对外提供了统一的操作方法(查询、遍历、修改、添加……)。

认识 BS4 先从构造 BeautifulSoup 对象开始。BeautifulSoup 是对整个文档树的引用,或是进入文档树的入口对象。
分析 BeautifulSoup 构造方法,可发现在构造 BeautifulSoup 对象时,可以传递很多参数。但一般只需要考虑前 2 个参数。其它参数采用默认值,BS4 就能工作很好(约定大于配置的典范)。
def __init__(self, markup="", features=None, builder=None,
parse_only=None, from_encoding=None, exclude_encodings=None,element_classes=None, **kwargs):
- markup: HTML 文档。可以是字符串格式的 HTML 片段、也可以是一个文件对象。
from bs4 import BeautifulSoup
# 使用 HTML 代码片段
html_code = "BeautifulSoup 4 简介
"
bs = BeautifulSoup(html_code, "lxml")
print(bs)
以下使用文件对象做为参数。
from bs4 import BeautifulSoup
file = open("d:/hello.html", encoding="utf-8")
bs = BeautifulSoup(file, "lxml")
print(bs)
Tip: 使用文件对象时,编码方式请选择 unicode 编码(utf-8 是 unicode 的具体实现)。
-
features: 指定解析器程序。解析器是 BS4 的灵魂所在,否则 BS4 就是一个无本之源的空壳子。
BS4 支持 Python 内置的 HTML 解析器 ,还支持第三方解析器:lxml、 html5lib……
Tip: 任何人都可以定制一个自己的解析器,但请务必遵循 BS4 的接口规范。
所以说即使谷歌浏览器的解析引擎很牛逼,但因和 BS4 接口不吻合,彼此之间也只能惺惺相惜一番。
如果要使用是第三方解析器,使用之前请提前安装:
安装 lxml :
pip install lxml
安装 html5lib:
pip install html5lib
几种解析器的纵横比较:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") | 执行速度适中 文档容错能力强 |
Python 2.7.3 or 3.2.2 前的版本文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快 文档容错能力强 |
需要 C 语言库的支持 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") | 速度快 唯一支持 XML 的解析器 |
需要 C 语言库的支持 |
| html5lib | BeautifulSoup(markup, "html5lib") | 最好的容错性 以浏览器的方式解析文档 生成HTML5格式的文档 |
速度慢 不依赖外部扩展 |
每一种解析器都有自己的优点,如 html5lib 的容错性就非常好,但一般优先使用 lxml 解析器,更多时候速度更重要。
2.2 解析器的差异性
解析器的功能是加载 HTML(XML) 代码,在内存中构建一棵层次分明的对象树(后面简称 BS 树)。虽然 BS4 从应用层面统一了各种解析器的使用规范,但各有自己的底层实现逻辑。
当然,解析器在解析格式正确、完全符合 HTML 语法规范的文档时,除了速度上的差异性,大家表现的还是可圈可点的。想想,这也是它们应该提供的最基础功能。
但是,当文档格式不标准时,不同的解析器在解析时会遵循自己的底层设计,会弱显出差异性。
看来, BS4 也无法掌管人家底层逻辑的差异性。
2.2.1 lxml
使用 lxml 解析HTML代码段。
from bs4 import BeautifulSoup
html_code = ""
bs = BeautifulSoup(html_code, "lxml")
print(bs)
'''
输出结果
'''
lxml 在解析时,会自动添加上 html、body 标签。并自动补全没有结束语法结构的标签。 如上 a 标签是后面 2 个标签的父标签,第一个 p 标签是第二 p 标签的为兄弟关系。
使用 lxml 解析如下HTML 代码段。
from bs4 import BeautifulSoup
html_code = ""
bs = BeautifulSoup(html_code, "lxml")
print(bs)
'''
输出结果
'''
lxml 会认定只有结束语法没有开始语法的标签结构是非法的,拒绝解析(也是挺刚的)。即使是非法,丢弃是理所当然的。
2.2.2 html5lib
使用 html5lib 解析不完整的HTML代码段。
from bs4 import BeautifulSoup
html_code = ""
bs = BeautifulSoup(html_code, "html5lib")
print(bs)
'''
输出结果
'''
html5lib 在解析j时,会自动加上 html、head、body 标签。 除此之外如上解析结果和 lxml 没有太大区别,在没有结束标签语法上,大家还是英雄所见略同的。
使用 html5lib 解析下面的HTML 代码段。
from bs4 import BeautifulSoup
html_code = ""
bs = BeautifulSoup(html_code, "html5lib")
print(bs)
'''
输出结果:
'''
html5lib 对于没有结束语法结构的标签,会为其补上开始语法结构,html5lib 遵循的是 HTML5 的部分标准。意思是既然都来了,也就不要走了,html5lib 都会尽可能补全。
2.2.3 pyhton 内置解析器
from bs4 import BeautifulSoup
html_code = ""
bs = BeautifulSoup(html_code, "html.parser")
print(bs)
'''
输出结果
'''
与前面 2 类解析器相比较,没有添加 、、 任一标签,会自动补全结束标签结构。但最终结构与前 2 类解析器不同。a 标签是后 2 个标签的父亲,第一个 p 标签是第二个 p 标签的父亲,而不是兄弟关系。
归纳可知:对于 lxml、html5lib、html.parser 而言,对于没有结束语法结构的标签都认为是可以识别的。
from bs4 import BeautifulSoup
html_code = ""
bs = BeautifulSoup(html_code, "html.parser")
print(bs)
'''
输出结果
'''
对于没有开始语法结构的标签的处理和 lxml 解析器相似,会丢弃掉。
从上面的代码的运行结果可知,html5lib 的容错能力是最强的,在对于文档要求不高的场景下,可考虑使用 html5lib。在对文档格式要求高的应用场景下,可选择 lxml 。
3. BS4 树对象
BS4 内存树是对 HTML 文档或代码段的内存映射,内存树由 4 种类型的 python 对象组成。分别是 BeautifulSoup、Tag、NavigableString 和 Comment。
-
BeautifulSoup对象 是对整个 html 文档结构的映射,提供对整个 BS4 树操作的全局方法和属性。也是入口对象。
class BeautifulSoup(Tag): pass -
Tag对象(标签对象) 是对 HTML 文档中标签的映射,或称其为节点(对象名与标签名一样)对象,提供对页面标签操作的方法和属性。本质上 BeautifulSoup 对象也 Tag 对象。
Tip: 解析页面数据的关键,便是找到包含内容的标签对象(Tag)。BS4 提供了很多灵活、简洁的方法。
使用 BS4 就是以 BeautifulSoup 对象开始,逐步查找目标标签对象的过程。
-
NavigableString对象 是对 HTML 标签中所包含的内容体的映射,提供有对文本信息操作的方法和属性。
Tip: 对于开发者而言,分析页面,最终就要要获取数据,所以,掌握此对象的方法和属性尤为重要。
使用 标签对象的 string 属性就可以获取。
-
Comment 是对文档注释内容的映射对象。此对象用的不多。
再总结一下:使用 BS4 的的关键就是如何以一个 Tag 对象(节点对象)为参考,找到与其关联的其它 Tag 对象。刚开始出场时就一个 BeautifulSoup 对象。

为了更好的以一个节点找到其它节点,需要理解节点与节点的关系:主要有父子关系、兄弟关系。
现以一个案例逐一理解每一个对象的作用。
案例描述:爬取豆瓣电影排行榜上的最新电影信息。(https://movie.douban.com/chart),并以CSV 文档格式保存电影信息。
3.1 查找目标 Tag
获取所需数据的关键就是要找到目标 Tag。BS4 提供有丰富多变的方法能帮助开发者快速、灵活找到所需 Tag 对象。通过下面的案例,让我们感受到它的富裕变化多端的魔力。
先获取豆瓣电影排行榜的入口页面路径 https://movie.douban.com/chart 。
使用谷歌浏览器浏览页面,使用浏览器提供的开发者工具分析一下页面中电影信息的 HTML 代码片段。 由简入深,从下载第一部电影的信息开始。
Tip: 这个排行榜随时变化,大家所看到的第一部电影和下图可能不一样。
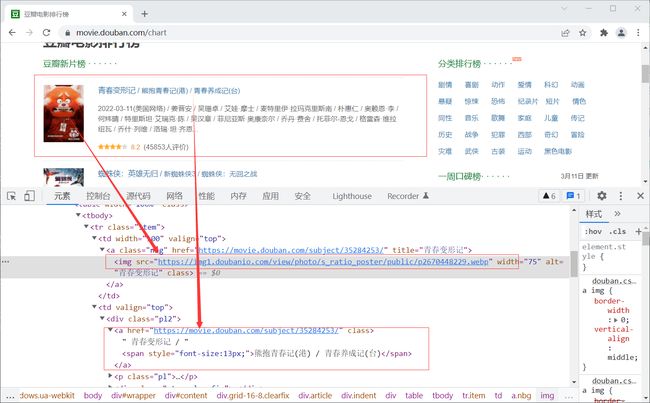
居然使用的是表格布局。表格布局非常有规则,这对于分析结构非常有利。
先下载第一部电影的图片和电影名。图片当然使用的是 img 标签,使用 BS4 解析后, BS4 树上会有一个对应的 img Tag 对象。
树上的 img Tag 对象有很多,怎么找到第一部电影的图片标签?
from bs4 import BeautifulSoup
import requests
# 服务器地址
url = "https://movie.douban.com/chart"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 发送请求
resp = requests.get(url, headers=headers)
html_code = resp.text
# 得到 BeautifulSoup 对象。万里长征的第一步。
bs = BeautifulSoup(html_code, "lxml")
# 要获得 BS4 树上的 Tag 对象,最简单的方法就是直接使用标签名。简单的不要不要的。
img_tag = bs.img
# 返回的是 BS4 树上的第一个 img Tag 对象
print(type(img_tag))
print(img_tag)
'''
输出结果
 '''
'''
这里有一个运气成分,bs.img 返回的恰好是第一部电影的图片标签(也意味着第一部电影的图片标签是整个页面的第一个图片标签)。
找到了 img 标签对象,再分析出其图片路径就容易多了,图片路径存储在 img 标签的 src 属性中,现在只需要获取到 img 标签对象的 src 属性值就可以了。
Tag 对象提供有 attrs 属性,可以很容易得到一个 Tag 对象的任一属性值。
使用语法:
Tag["属性名"]或者使用 Tag.attrs 获取到 Tag 对象的所有属性。
下面使用 atts 获取标签对象的所有属性信息,返回的是一个 python 字典对象。
# 省略上面代码段
img_tag_attrs = img_tag.attrs
print(img_tag_attrs)
'''
输出结果:以字典格式返回 img Tag 对象的所有属性
{'src': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2670448229.jpg', 'width': '75', 'alt': '青春变形记', 'class': []}
'''
单值属性返回的是单值,因 class 属性(多值属性)可以设置多个类样式,返回的是一个数组。现在只想得到图片的路径,可以使用如下方式。
img_tag_attrs = img_tag.attrs
# 第一种方案
img_tag_src=img_tag_attrs["src"]
# 第二种方案
img_tag_src = img_tag["src"]
print(img_tag_src)
'''
输出结果
https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2670448229.jpg
'''
上述代码中提供 2 种方案,其本质是一样的。有了图片路径,剩下的事情就好办了。
完整的代码:
from bs4 import BeautifulSoup
import requests
# 服务器地址
url = "https://movie.douban.com/chart"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 发送请求
resp = requests.get(url, headers=headers)
html_code = resp.text
bs = BeautifulSoup(html_code, "lxml")
img_tag = bs.img
# img_tag_attrs = img_tag.attrs
# img_tag_src=img_tag_attrs["src"]
img_tag_src = img_tag["src"]
# 根据图片路径下载图片并保存到本地
img_resp = requests.get(img_tag_src, headers=headers)
with open("D:/movie/movie01.jpg", "wb") as f:
f.write(img_resp.content)

3.2 过滤方法
得到图片后,怎么得到电影的名字,以及其简介。如下为电影名的代码片段。
青春变形记/ 熊抱青春记(港) / 青春养成记(台)
电影名包含在一个 a 标签中。如上所述,当使用 bs.标签名 时,返回的是整个页面代码段中的第一个同名标签对象。
显然,第一部电影名所在的 a 标签不可能是页面中的第一个(否则就是运气爆棚了),无法直接使用 bs.a 获取电影名所在 a 标签,且此 a 标签也无特别明显的可以区分和其它 a 标签不一样的特征。
这里就要想点其它办法。以此 a 标签向上找到其父标签 div。
青春变形记/ 熊抱青春记(港) / 青春养成记(台)
2022-03-11(美国网络) / 姜晋安 / 吴珊卓 / 艾娃·摩士 / 麦特里伊·拉玛克里斯南 / 朴惠仁 / 奥赖恩·李 / 何炜晴 / 特里斯坦·艾瑞克·陈 / 吴汉章 / 菲尼亚斯·奥康奈尔 / 乔丹·费舍 / 托菲尔-恩戈 / 格雷森·维拉纽瓦 / 乔什·列维 / 洛瑞·坦·齐恩...
(45853人评价)
同理,div 标签在整个页面代码中也有很多,又如何获到到电影名所在的 div 标签,分析发现此 div 有一个与其它 div 不同的属性特征。class="pl2"。 可以通过这个属性特征对 div 标签进行过滤。
什么是过滤方法?
过滤方法是 BS4 Tag 标签对象的方法,用来对其子节点进行筛选。
BS4 提供有 find( )、find_all( ) 等过滤方法。此类方法的作用如其名可以在一个群体(所有子节点)中根据个体的特征进行筛选。
Tip: 如果使用 BeautifulSoup对象 调用这类方法,则是对整个 BS4 树上的节点进行筛选。
如果以某一个具体的 Tag 标签对象调用此类方法以,则是对 Tag 标签下的子节点进行筛选。
find()和 find_all( ) 方法的参数是一样的。两者的区别:前者搜索到第一个满足条件就返回,后者会搜索所有满足条件的对象。
find_all( name , attrs , recursive , string , **kwargs )
find( name , attrs , recursive , string , **kwargs )
参数说明
- name: 可以是标签名、正则表达式、列表、布尔值或一个自定义方法。变化多端。
# 标签名:查找页面中的第一个 div 标签对象
div_tag = bs.find("div")
# 正则表达式:搜索所有以 d 开始的标签
div_tag = bs.find_all(re.compile("^d"))
# 列表:查询 div 或 a 标签
div_tag = bs.find_all(["div","a"])
# 布尔值:查找所有子节点
bs.find_all(True)
#自定义方法:搜索有 class 属性而没有 id 属性的标签对象。
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
bs.find_all(has_class_but_no_id)
- attrs: 可以接收一个字典类型。以键、值对的方式描述要搜索的标签对象的属性特征。
# 在整个树结果中查询 class 属性值是 pl2 的标签对象
div_tag = bs.find(attrs={"class": "pl2"})
Tip: 使用此属性时,可以结合 name 参数把范围收窄。
div_tag = bs.find("div",attrs={"class": "pl2"})查找 class 属性值是 pl2 的 div 标签对象。
- string 参数: 此参数可以是 字符串、正则表达式、列表 布尔值。通过标签内容匹配查找。
# 搜索标签内容是'青春' 2 字开头的 span 标签对象
div_tag = bs.find_all("span", string=re.compile(r"青春.*"))
-
limit 参数: 可以使用
limit参数限制返回结果的数量。 -
recursive 参数: 是否递归查询节点下面的子节点,默认 是 True ,设置 False 时,只查询直接子节点。
简单介绍过滤方法后,重新回到问题上来,查询第一部电影的电影名、简介。灵活使用过滤方法,则能很轻松搜索到所需要的标签对象。
from bs4 import BeautifulSoup
import requests
# 服务器地址
url = "https://movie.douban.com/chart"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 发送请求
resp = requests.get(url, headers=headers)
html_code = resp.text
# 使得解析器构建 BeautifulSoup 对象
bs = BeautifulSoup(html_code, "lxml")
# 使用过滤方法在整个树结构中查找 class 属性值为 pl2 的 div 对象。其实有多个,这里查找第一个
div_tag = bs.find("div", class_="pl2")
# 查询 div 标签对象下的第一个 a 标签
div_a = div_tag.find("a")
# 得到 a 标签下所有子节点
name = div_a.contents
# 得到 文本
print(name[0].replace("/", '').strip())
'''
输出结果:
青春变形记
'''
代码分析:
- 使用 bs.find("div", class_="pl2") 方法搜索到包含第一部电影的 div 标签。
- 电影名包含在 div 标签的子标签 a 中,继续使用 div_tag.find("a") 找到 a 标签。
青春变形记/ 熊抱青春记(港) / 青春养成记(台)
- a 标签中的内容就是电影名。BS4 为标签对象提供有 string 属性,可以获取其内容,返回 NavigableString 对象。但是如果标签中既有文本又有子标签时, 则不能使用 string 属性。如上 a 标签的 string 返回为 None。
- 在 BS4 树结构中文本也是节点,可以以子节点的方式获取。标签对象有 contents 和 children 属性获取子节点。前者返回一个列表,后者返回一个迭代器。另有 descendants 可以获取其直接子节点和孙子节点。
- 使用 contents 属性,从返回的列表中获取第一个子节点,即文本节点。文本节点没有 string 属性。
获取电影简介相对而言就简单的多,其内容包含在 div 标签的 p 子标签中。
# 获取电影的简介
div_p = div_tag.find("p")
movie_desc = div_p.string.strip()
print(movie_desc)
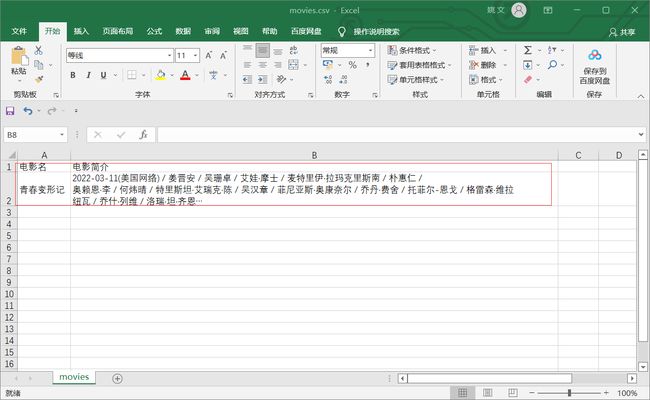
下面可以把电影名和电影简介以 CSV 的方式保存在文件中。完整代码:
from bs4 import BeautifulSoup
import requests
import csv
# 服务器地址
url = "https://movie.douban.com/chart"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 发送请求
resp = requests.get(url, headers=headers)
html_code = resp.text
bs = BeautifulSoup(html_code, "lxml")
div_tag = bs.find("div", class_="pl2")
div_a = div_tag.find("a")
div_a_name = div_a.contents
# 电影名
movie_name = div_a_name[0].replace("/", '').strip()
# 获取电影的简介
div_p = div_tag.find("p")
movie_desc = div_p.string.strip()
with open("d:/movie/movies.csv", "w", newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["电影名", "电影简介"])
csv_writer.writerow([movie_name, movie_desc])
是时候小结了,使用 BS4 的基本流程:
- 通过指定解析器获取到 BS4 对象。
- 指定一个标签名获取到标签对象。如果无法直接获取所需要的标签对象,则使用过滤器方法进行一层一层向下过滤。
- 找到目标标签对象后,可以使用 string 属性获取其中的文本,或使用 atrts 获取属性值。
- 使用获取到的数据。
3.3 遍历所有的目标
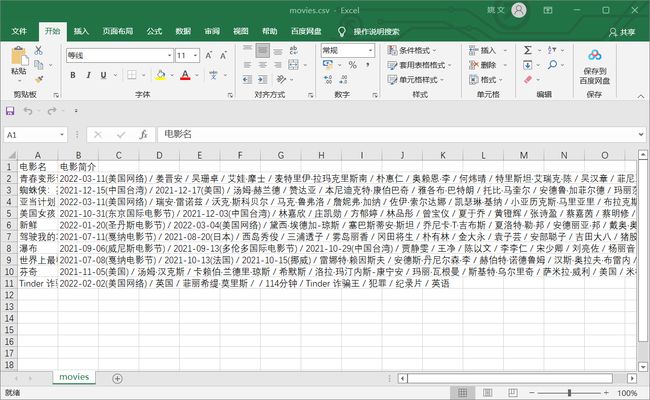
如上仅仅是找到了第一部电影的信息。如果需要查找到所有电影信息,则只需要在上面代码的基础之上添加迭代便可。
from bs4 import BeautifulSoup
import requests
import csv
all_movies = []
# 服务器地址
url = "https://movie.douban.com/chart"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 发送请求
resp = requests.get(url, headers=headers)
html_code = resp.text
bs = BeautifulSoup(html_code, "lxml")
# 查找到所有
div_tag = bs.find_all("div", class_="pl2")
for div in div_tag:
div_a = div.find("a")
div_a_name = div_a.contents
# 电影名
movie_name = div_a_name[0].replace("/", '').strip()
# 获取电影的简介
div_p = div.find("p")
movie_desc = div_p.string.strip()
all_movies.append([movie_name, movie_desc])
with open("d:/movie/movies.csv", "w", newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["电影名", "电影简介"])
for movie in all_movies:
csv_writer.writerow(movie)
本文主要讲解 BS4 的使用,仅爬取了电影排行榜的第一页数据。至于数据到手后,如何使用,则根据应用场景来决定。
4. 总结
BS4 还提供有很多方法,能根据当前节点找到父亲节点、子节点、兄弟节点……但其原理都是一样的。只要找到了内容所在的标签(节点)对象,一切也就OK 了。