深度学习实践Tensorflow搭建卷积神经网络图像识别笔记
目录
- DeepLearning Practise of building CNN with TensorFlow-slim
-
- 概述
-
-
-
-
- 1.必要的:
- 2.我的硬件:
- 3.详细
-
-
-
- TensorFlow-slim
- 爬虫
- CNN模型搭建
-
- what is CNN?
-
-
- ‘c’ means Convolutional
- 'NN' means neural network
- 概念
-
- tensorflow架构
- TensorflowBoard
- 训练与测试
-
- 训练
-
- loss曲线
- 测试
- “坏”的测试集
-
- 现象
- 分析
- 加入SVM的决策树
- 总结
DeepLearning Practise of building CNN with TensorFlow-slim
张天天
[email protected]
https://github.com/piglaker
概述
小数据集下,使用tensorflow-slim搭建卷积神经网络实现服装分类,并用SVM优化结果
代码in github
- TensorFlow-slim :https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/slim
- 爬虫,训练集数据的获得
- 模型搭建:浅层卷积神经网络
- TensorBoard;
- 训练&测试和代码详解,loss曲线
- 坏测试集
- 加入SVM的决策树
- 总结
1.必要的:
python3.5: anaconda自带python3.6不支持tensorflow,
opencv
tensorflow-gpu
numpy
pillow
models:https://github.com/tensorflow/models
2.我的硬件:
gtx1080
i7
3.详细
训练集规模:8000 .jpg( 爬取自 京东 百度)
测试集规模:3000. jpg(爬取自 )
STEPS=20000
Learning_rate=0.005
accuracy=0.84
TensorFlow-slim
略(but important!)
见 tensorflow-slim
poor English? here
爬虫
request&正则表达式
略,懒得写
CNN模型搭建
what is CNN?
‘c’ means Convolutional
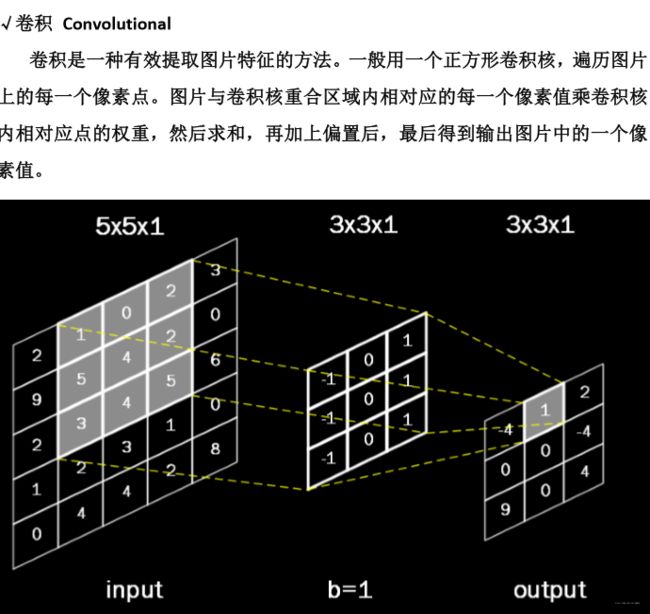
‘NN’ means neural network
常识:
cs231n: http://cs231n.github.io/understanding-cnn/
这个人写的也不错:https://www.cnblogs.com/alexcai/p/5506806.html
吴恩达:https://blog.csdn.net/ice_actor/article/details/78648780
关于图像识别常识(matlab):https://www.cnblogs.com/kkyyhh96/p/6505473.html
numpy常识
理解:
图文并茂: 【深度学习】卷积神经网络的实现与理解
比较偏理论深度神经网络结构以及Pre-Training的理解
实例:
matlab车牌识别
tf普通神经网络
工程级
概念
filter 卷积核
pooling 池化
fc 全连接
bias 偏置
backpropagation 反向传播
loss 损失
optimizer 优化器
Momentum动量随机梯度下降法
Learningrate 学习率
relu 激活函数
tensorflow架构
一张图了解tensorflow搭建神经网络模型结构: 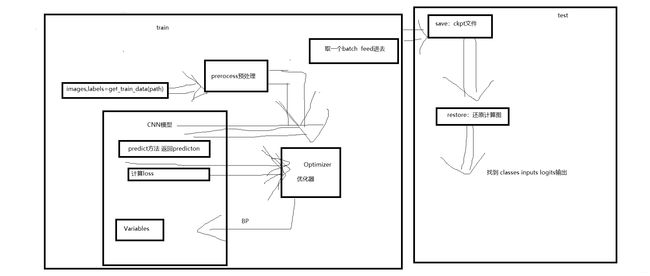
CNN的实现:(conv-pool)*n ->dropout-> flatten->(fullconnected)*n->outputs
NN算法的前向传播过程(forward)我理解为 矩阵乘,
//
import tensorflow as tf
slim = tf.contrib.slim
class Model(object):
def __init__(self,
is_training,
num_classes):
self._num_classes = num_classes
self._is_training = is_training
@property
def num_classes(self):
return self._num_classes
def preprocess(self, inputs):
preprocessed_inputs = tf.to_float(inputs)
preprocessed_inputs = tf.subtract(preprocessed_inputs, 128.0)
preprocessed_inputs = tf.div(preprocessed_inputs, 128.0)
#使图片灰度值归一化到-1~1之间,小数据集的preprocessing中使用rotate,crop&border_expend是有用的,这次时间紧懒得搞了
return preprocessed_inputs
def predict(self, preprocessed_inputs):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu):
net = preprocessed_inputs
net = slim.repeat(net, 2, slim.conv2d, 32, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 64, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv3')
net = slim.flatten(net, scope='flatten')
net = slim.dropout(net, keep_prob=0.5,
is_training=self._is_training)
net = slim.fully_connected(net, 512, scope='fc1')
net = slim.fully_connected(net, self.num_classes,
activation_fn=None, scope='fc2')
#net=slim.resnet_v1.predict()
#调用slim搭建网络,3个conv,2个fc,logits是形如[x,y].后面训练SVM会用到
prediction_dict = {'logits': net}
return prediction_dict
def postprocess_logits(self, prediction_dict):
logits = prediction_dict['logits']
logits = tf.cast(logits, dtype=tf.float32)
logits_dict = {'logits': logits}
return logits_dict#有用,但是懒得解释
def postprocess_classes(self, prediction_dict):
logits = prediction_dict['logits']
logits = tf.nn.softmax(logits)
classes = tf.cast(tf.argmax(logits, axis=1), dtype=tf.int32)
postprecessed_dict = {'classes': classes}
return postprecessed_dict#softmax使logits=[x,y]->logits[x/(x+y),y/(x+y)]
def loss(self, prediction_dict, groundtruth_lists):
logits = prediction_dict['logits']
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(#计算交叉熵
logits=logits, labels=groundtruth_lists))#这个说起来太麻烦,见(https://blog.csdn.net/qq_22194315/article/details/77991283)
loss_dict = {'loss': loss}
return loss_dictTensorflowBoard
使用:anaconda navigater -> environment -> python3.5 -> open terminal ->(进去你的path) -> tensorboard --logdir=‘yourpath’-> ctrl+c “http”-> open it in your chrome
训练与测试
训练
拟合,观察loss曲线,调参
main中先调用get_train_data导入图片
//
def get_train_data(images_path):
if not os.path.exists(images_path):
raise ValueError('images_path is not exist.')
images = []
labels = []
images_path = os.path.join(images_path, '*.jpg')
count = 0
for image_file in glob.glob(images_path):
count += 1
if count % 100 == 0:
print('Load {} images.'.format(count))
image = cv2.imread(image_file)
image = cv2.resize(image,(220,220),interpolation=cv2.INTER_CUBIC)#resize
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)#灰度图
# Assume the name of each image is imagexxx@label$.jpg
label = int(image_file.split('@')[-1].split('$')[0])#用一个小trick读取标签
images.append(image)
labels.append(label)
images = np.array(images)
labels = np.array(labels)
return images, labels
#np.ndarray [all,length,wideth,channel] labels: np.ndarray one dimension tensor 由于训练时的
//
def next_batch_set(images, labels, batch_size=60):
indices = np.random.choice(len(images), batch_size)
batch_images = images[indices]
batch_labels = labels[indices]
return batch_images, batch_label是随机取的,所以为了保证每一个都被取到的概率,STEPS应远大于len(train_images)
//
def main(_):
inputs = tf.placeholder(tf.float32, shape=[None, 220, 220, 3], name='inputs')
labels = tf.placeholder(tf.int32, shape=[None], name='labels')
cls_model = model2.Model(is_training=True, num_classes=2)
preprocessed_inputs = cls_model.preprocess(inputs)#inputs预处理
prediction_dict = cls_model.predict(preprocessed_inputs)#predict (forward)
postprocessed_logits=cls_model.postprocess_logits(prediction_dict)#后处理
logits=postprocessed_logits['logits']#
logits_ = tf.identity(logits,name='logits')#用于测试(necessary)
loss_dict = cls_model.loss(prediction_dict, labels)
loss = loss_dict['loss']
postprocessed_dict = cls_model.postprocess_classes(prediction_dict)
classes = postprocessed_dict['classes']
classes_ = tf.identity(classes, name='classes')#用于测试(necessary)
acc = tf.reduce_mean(tf.cast(tf.equal(classes, labels), 'float'))
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(Learning_RATE, global_step, 150, 0.99)#指数衰减学习率
optimizer = tf.train.MomentumOptimizer(learning_rate, 0.99)#优化器
train_step = optimizer.minimize(loss, global_step)
saver = tf.train.Saver() #保存
images, targets = get_train_data(images_path)#获取训练images labels (np.ndarray)
init = tf.global_variables_initializer()#
loss_graph=[]
x=[]
with tf.Session() as sess:
sess.run(init)
writer=tf.summary.FileWriter("E:\\zxtdeeplearning\\tensorboard\\3",sess.graph)#tensorboard绘图
#打开tensorboard:anaconda navigator->open terminal ->cd logdir -> tensorboard --logdir=....-> ...
ckpt=tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path) #断点存续
for i in range(STEPS):
batch_images, batch_labels = next_batch_set(images, targets)
train_dict = {inputs: batch_images, labels: batch_labels}
sess.run(train_step, feed_dict=train_dict)
loss_, acc_ = sess.run([loss, acc], feed_dict=train_dict)
train_text = 'step: {}, loss: {}, acc: {}'.format(
i+1, loss_, acc_)
loss_graph.append(loss_)
x.append(i)
print(train_text)
writer=tf.summary.FileWriter("E:\\zxtdeeplearning\\tensorboard\\1",sess.graph)
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step=global_step)
writer.close()
plt.figure()
plt.plot(x,loss_graph)
plt.show()#画loss曲线,懒得用tensorboard
loss曲线
根据loss曲线判断收敛情况调整learning_rate,(凹凸)
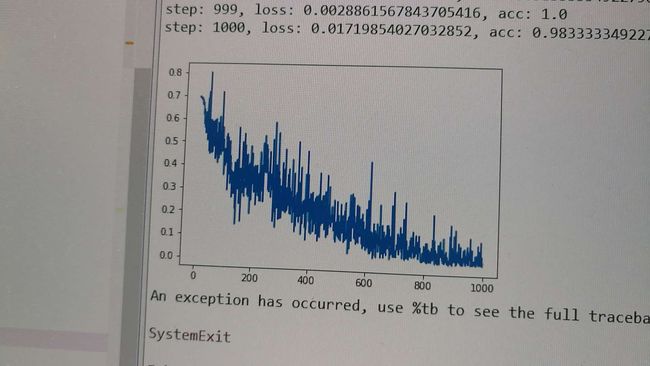
于是加大力度

考虑到网络结构较浅,训练集较少,还可以
测试
from sklearn.preprocessing import StandardScaler
import os
import numpy as np
import tensorflow as tf
import train2
from sklearn.externals import joblib
import datawriter
model_path="E:\\zxtdeeplearning\\outputs-2.3.ckpt\\6-20000"
#img_path='E:\\zxtdeeplearning\\pic_source\\test_pic_1'
#img_path=input('input the path and the img name')
#img_path='E:\\zxtdeeplearning\\test_pic(dirt)'
#img_path='E:\\zxtdeeplearning\\pic_source\\dirty'
img_path='E:\\zxtdeeplearning\\test_pic'
#img_path='E:\\zxtdeeplearning\\test_pic_misty'
#img_path="E:\\zxtdeeplearning\\test_pic_formal"
logits_outputs_path='E:\\zxtdeeplearning\\svm_train_data\\dataset_test.txt'
#我意外发现你的test_pic的string不能包含中文字符,不然会报-215Asseration
#注意,测试集不能太多,否则gtx1080也会炸,batch几十都ok(2353:->oom)
foot=10
--------------------------------------------#随手写的零件,可以忽略
def accuracy(predicted_label,labels):
a=predicted_label-labels
t=0
for i in range(len(a)):
if a[i] !=0:
t+=1
return 1-t/len(a)
def ave(mum):
total=0
for i in range(len(mum)):
total=total+mum[i]
return total/len(mum)
------------------------------
def main(_):
images,labels=train2.get_train_data(img_path)
with tf.Session() as sess:
ckpt_path = model_path
saver = tf.train.import_meta_graph(ckpt_path + '.meta')#取出.meta文件
saver.restore(sess, ckpt_path)#恢复参数
inputs = tf.get_default_graph().get_tensor_by_name('inputs:0')#找到图中变量,建议查这两个api用法
classes = tf.get_default_graph().get_tensor_by_name('classes:0')
logits = tf.get_default_graph().get_tensor_by_name('logits:0')#logits
predicted_label_list=[]
predicted_logits_list=[]
a,b=0,9
for i in range(int(len(images)/foot)):
image_batch=datawriter.get_batch(images,a,b)
a,b=(a+foot),(b+foot)
predicted_logits=sess.run(logits, feed_dict={inputs: image_batch})
predicted_label = sess.run(classes, feed_dict={inputs: image_batch})
for j in range(len(predicted_label)):
predicted_label_list.append(predicted_label[j])
predicted_logits_list.append(predicted_logits[j])
print(predicted_logits,logits_outputs_path)
for i in range(len(predicted_logits)):
predicted_logits[i][0],predicted_logits[i][1]=predicted_logits[i][0],predicted_logits[i][1]
for i in range(len(labels)):
print("fact:",labels[i],' ',"predict:",predicted_label_list[i],' ','logits:',predicted_logits_list[i])
print(accuracy(predicted_label_list,labels))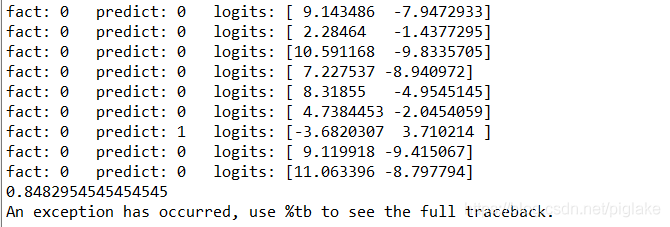
结果:84%
“坏”的测试集
现象
对于pic_test_1,在测试过程中发现准确率很低(66%)->发现是爬取得图片有问题,包含一些脏数据(由于易于爬取得(如京东百度)已经被爬完了),抽样调查脏数据约占到1/3,出于相信模型的可靠度(由于另一测试集pic_test_0准确率在83%,尝试设计方法还原原准确率)
分析
使用数学手段证明了在logits输出层使用聚类算法(无监督学习二分类),聚类算法accura>0.5,则必然比原来更接近原准确率,即能降低脏数据的影响。(再数学证明从略,这是显然的)其实使用训练的svm在logits分类也是可以还原原准确率的(显然),但是性能和聚类算法孰优孰劣?或是重新制作好的测试集进行测试即可得到真实值。
加入SVM的决策树
懒得写了,就是用2000张misty和1000羽绒服1000短袖训练了个SVM,发现效果不好(70%),本来感觉没用不想用了,又发现可以用来搞上面那个问题,略了
// An highlighted block
var foo = 'bar';总结
1.我需要更多的数据!
2.cool idea?服装识别?识别出一个人身上的所有装饰?that is easy I think,甚至堆叠起来就可以!之后做打分?穿搭?或者尝试expand it ,读取一张图片估计它的季节?温度?
3.tensorboard需要熟悉
4.fine-tune在专业领域会更好!
5.下次我应该尝试学习resnet?或许gan是个不错的主意
6.图像识别的算法是很重要的一大块,聚类,追踪,分割都是很有趣的
7.titantitantitan!
8.努力达到比赛级别!
附件:爬虫的代码:
// An highlighted block
import requests
import os
def getPages(keyword, pages):
params = []
for i in range(30, 30 * pages + 30, 30):
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': 0,
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': 1,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1509347955280': ''
})
url = 'http://image.so.com/'
urls = []
for i in params:
urls.append(requests.get(url, params=i).json().get('data'))
return urls
def getImg(dataList, localPath):
if not os.path.exists(localPath):
os.mkdir(localPath)
try:
x = 0
for list in dataList:
for i in list:
if i.get('thumbURL') != None:
print('正在下载:%s' % i.get('thumbURL'))
ir = requests.get(i.get('thumbURL'))
open(localPath + '%d.jpg' % x, 'wb').write(ir.content)
x += 1
print('图片下载完成')
except Exception:
print("图片下载失败")
if __name__ == '__main__':
dataList = getPages('羽绒服',10)
print(dataList)
getImg(dataList, 'D:/大学/大二/python课/项目/pictures/测试集/pic_f_yurong')」
—————————