为什么需要知道掩盖技术?因为这是一种匿名化数据的方法,这样就可以使用包含敏感或个人信息的数据进行测试或开发。 即使你负责的数据库具有完全的访问控制和安全性,你也可能需要多种数据脱敏技术来支持应用程序。
例如,你可能需要动态脱敏数据以确保应用程序不会暴露不必要的敏感信息。或者,如果您需要对实际生产数据运行测试或开发,而实际生产数据包含个人或敏感信息,则可能需要脱敏真实数据。
如果你需要将生产数据推到一个安全性较低的环境,你也需要进行数据脱敏技术,为了分发报告或者分析相应的数据,并且必须保留报告所需要的基础数据。
出于培训或用户测试的目的,常见的做法是生成看起来像真实数据的假数据。这是一个不同的过程,需要不同的技能。
为什么需要脱敏数据?
关于数据的各种规则适用于任何数据库、文件或电子表格。从法律的角度来看,在哪里保存数据并不重要。如果你是组织的一部分,你应该只能访问适合你在组织中角色的信息。如果你没有合法的理由访问该数据,那么你必须无法访问该数据。
总结:
所有数据都必须以可靠的方式进行管理,无论它在哪里保存。法律并不关心你用什么方法存储数据,只要你这样做了。
如果包含可能获取个人的数据(PII数据),它必须在任何时候都具有访问限制。此外,法律提供了就如何匿名或伪匿名数据给出指示性建议。它只是要求在适当的时候这样做。
法律要求不能在匿名数据中识别任何个人或团体,即使它与其他数据源结合在一起。如何让数据实现这一目标是我们所关心的,而实现这一目标的技术在当前的法律中没有明确的定义。
如果可以通过重新识别或去匿名化来识别个人,那么数据就没有正确地匿名化。这种重新识别技术多年来被执法机构和情报机构用于破解犯罪网络,可以肯定的是,暗网也有同样的技术。
脱敏与MongoDB
因为你保存和处理数据的方式与法律无关,MongoDB和其他任何数据格式一样面临同样的挑战。
由于MongoDB在默认情况下不启用访问控制,所以第一个明显的步骤是提供基于角色的访问控制和数据库及服务器的安全性。
相关的阅读:MongoDB安全提示,以确保远离黑客
然而,任何文档数据,无论是非结构化文本、YAML、JSON或XML,对于负责将其匿名化的任何人来说都有特定的问题。除非包含模式和规范的方法,否则敏感数据可能存在于任何地方,并且可以在多个地方重复。
在具有“非规范化”或包含XML或JSON列的关系型结构数据中,可能会遇到同样的问题。如果进行检查,通常会发现相同的数据存在于多个位置,并且其中两个数据具有相同的名称,而忽略对它们进行脱敏,那么就存在潜在的漏洞。
MongoDB基于集合的概念。一个集合,就像一个关系数据库表,包含一个或多个文档。每个文档都是一组键值对。
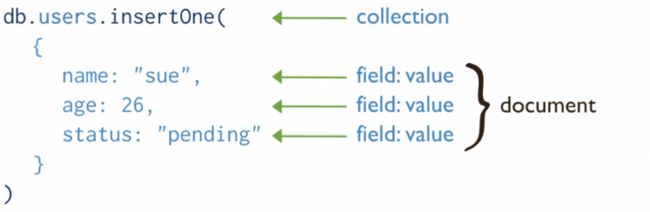
图片地址:
https://studio3t.com/wp-conte...
MongoDB使用集合、文档和键值对来构造数据
由于同一个集合中的文档不需要具有相同的字段集或结构,因此集合文档中具有相同名称的字段可能包含不同类型的数据。它们可以保存数组,其中可以包含各种类型的数据。
基本上,MongoDB很少强制执行模式。这使得制作一个系统的自动化脱敏程序变得更加困难。
事实上,如果没有一致的模式,那么定义掩码的过程会变得非常冗长。要实现屏蔽,可以使用MongoDB的只读非物化视图、字段级密文或字段级加密等技术。
视图是最简单的方法,因为它们基于聚合管道,因此可以创建相当复杂的集合筛选器。您需要将这些数据托管到生产数据库中,并使用它们导出脱敏后的数据。
然而,尽管这些方法可以实现假名化,但它们需要大量的编程,假设对模式进行合理的强制执行,并且不能满足所有的需求。
假名化、匿名化、聚合、屏蔽和数据生成
有很多技术可以使数据匿名。最合适的选择取决于您需要匿名化数据的原因。
如果为了开发工作的需要,那么任何敏感数据必须被脱敏。为了培训或用户测试,数据也必须是需要脱敏。为了测试数据的弹性和可伸缩性,数据生成来提供必要的方法。
聚合
如果数据是用于报告的,那么仅仅通过在报告所需的最低级别上,提供一个聚合就可以实现很大的效果。
例如,如果它是用于报告交易,而最详细的报告是关于一天的交易,那么数据只能提供每天的数据。
如果某些群体的人数较少,聚合的个人数据可以被重新识别。这发生在开放数据医疗信息和犯罪记录上。
屏蔽
动态屏蔽不同于静态屏蔽,因为它是对数据查询的结果进行屏蔽。它只在目的地具有访问控制以防止临时查找/连接的情况下有效。不同的数据库系统以不同的方式进行动态屏蔽,但MongoDB使用视图和编校投影技术。动态屏蔽的优点是它避免破坏约束数据的应用程序逻辑。
如果将放入实际的数字数据中,它可能会在JSON Schema中失败,因为它不再看起来像一个数字。
如果你有一个电话号码、邮政编码或卡号,情况就更复杂了,因为如果违反了校验和或特殊的验证规则,那么用数字掩盖的数字的验证可能会失败。
假名化
假名化是一种数据掩盖技术,其中个人可能需要重新识别。
例如,如果一家医院需要根据病史对某些病理或最佳治疗的可能性进行分析,则报告必须掩盖个人细节,以便重新识别。
最明显的是,在必要的医疗信息中留下一个“替代”键,以取代个人(PII)信息,然后可用于从随后的报告中重新识别个别患者。
如果个人信息“泄露”到医疗信息中,并且在法律上不认为这等同于匿名化,那么这种安全性就会被打破。
数据生成
数据生成用于应用程序测试和培训:对于尚未发布的应用程序,它是唯一的方法。它可能看起来很简单,而且它可能只是字段中的信息可能是相关的。客户将得到逻辑一致的信息,可能是与性别相关的,约会可能需要在其他约会之前或之后,并将需要一个真实的跨度。
Studio 3T中的数据屏蔽
Studio 3T中的数据屏蔽是对其编辑和操作MongoDB数据能力的一个明显的扩展,它与它的“Reschema”功能有效地结合在一起。这将告诉你许多关于数据位置的信息。
数据屏蔽由“任务”以与任何其他可重复作业相同的方式完成,可以保存、调度和编辑。访问屏蔽数据,右键单击要屏蔽的集合,然后在出现的上下文菜单中单击“屏蔽集合”。

图片地址:
https://studio3t.com/wp-conte...
在Studio 3T的任意集合上单击右键,选择屏蔽集合一个任务由一个或多个“单元”组成,每个单元管理一个集合的屏蔽。一个“单元”允许您屏蔽整个集合,并决定哪些字段应该混淆。您可以屏蔽原始集合,也可以将其保存为新集合。
在它的第一个版本中,集中讨论了通常用于动态数据屏蔽的“屏蔽”技术。你还不能做混排,同步或替换。屏蔽的类型取决于字段的数据类型。

图片地址:
https://studio3t.com/wp-conte...
Studio 3T中的“数据屏蔽单元”
可以从20种不同的数据类型中选择一种,屏蔽或混淆的类型取决于数据类型。
例如,数组可以被排除、空值或空对象。字符串部分或全部替换为散列(#)或星号(*)字符。整数可以与原始值不同,可以是原始值的一个变化百分比,也可以是原始值的一个固定百分比,或者可以用一个固定的值替换它们。
日期可以在您可以定义的范围内给出一个随机值。
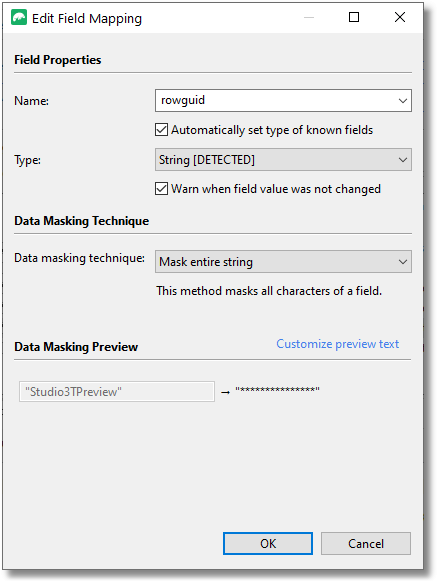
图片地址:
https://studio3t.com/wp-conte...
编辑字段映射并选择数据屏蔽技术
这只有简单几个符合模式的集合的数据库,因为每个字段是完全独立完成的,并没有为用户自行设定默认值,你需要选择相关的方法,(例如,一个整数的方差)这不是快速的大型数据库。
这种屏蔽的第一次迭代对于大多数目的来说已经足够了,但是如果它有效地执行了,您的数据看起来就不会那么漂亮,而且可能不会有相同的分布。然而,它是有效的。
对于我们这些对数据混淆感兴趣的人来说,他们对混淆文本的方式感到自豪,这种方式使文本看起来像真实的数据,甚至通过约束和模式验证规则。实际上,这只在培训、用户验收或性能测试中使用。
Studio 3T提供的屏蔽功能在第一次迭代中提供了足够的功能,允许在普通开发工作和“下游”报告中屏蔽数据。
结论
当你开发、维护或测试一个数据驱动的应用程序时,如果有大量的数据,就会容易得多。许多问题,尤其是性能问题,只有在有大量数据的情况下才会浮出水面。通过在大型数据集上尝试各种想法,应用程序设计很快就得到了完善。
如果你有一个现有的应用程序,那么使用实时数据总是很诱人的,有时也是必要的。
屏蔽数据的功能必须是任何处理数据的开发人员的工具包的一部分。这有助于确保您负责任地处理实时数据。然而,它只是数据库开发人员的一个基本工具,用于满足业务依赖于数据的组织的需求。
为了满足社会的需求,它必须与数据生成、加密、聚合、访问控制一起使用,以保护敏感和个人信息。
关于作者:管祥青
湖南大学研究生毕业,毕业后在海康威视研究院从事大数据研发及机器学习相关工作,现在就职于一家大数据金融公司。
参考网址: