概述
在微服务架构的系统中,请求在各服务之间流转,调用链错综复杂,一旦出现了问题和异常,很难追查定位,这个时候就需要链路追踪来帮忙了。链路追踪系统能追踪并记录请求在系统中的调用顺序,调用时间等一系列关键信息,从而帮助我们定位异常服务和发现性能瓶颈。

微服务的监控主要包含一下三个方面:
- 通过收集日志,对系统和各个服务的运行状态进行监控
- 通过收集量度(Metrics),对系统和各个服务的性能进行监控
- 通过分布式追踪,追踪服务请求是如何在各个分布的组件中进行处理的细节
对于是日志和量度的收集和监控,大家会比较熟悉。常见的日志收集架构包含利用Fluentd对系统日志进行收集,然后利用ELK或者Splunk进行日志分析。而对于性能监控,Prometheus是常见的流行的选择。
分布式链路跟踪主要功能:
- 故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
- 链路性能可视化:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来。
- 链路分析:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景。
基本原理
目前常见的链路追踪系统的原理基本都是根据2010年由谷歌发布的一篇《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》论文为原型实现的。

Trace
指一个请求经过所有服务的路径,每一条局部链路都用一个全局唯一的traceid来标识。
Span
为了表达父子调用关系,引入了span
同一层级parent id相同,span id不同,span id从小到大表示请求的顺序。
总结:通过事先在日志中埋点,找出相同traceId的日志,再加上parent id和span id就可以将一条完整的请求调用链串联起来。
Annotations
Dapper中还定义了annotation的概念,用于用户自定义事件,用来辅助定位问题。
通常包含以下四个Annotaion注解信息,分别对应客户端和服务端相应事件。
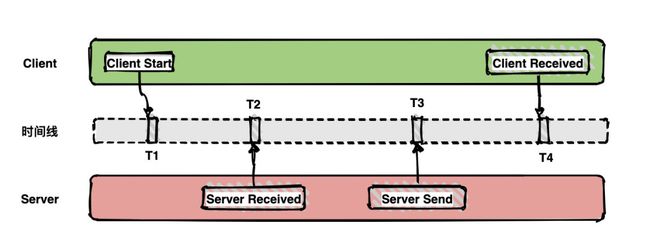
调用耗时可以通过T4-T1得到,客户端发送数据包的网络耗时可以通过T2-T1实现。
链路信息的还原依赖于带内和带外两种数据。
带外数据是各个节点产生的事件,如cs,ss,这些数据可以由节点独立生成,并且需要集中上报到存储端。
带内数据如traceid,spanid,parentid,这些数据需要从链路的起点一直传递到终点。通过带内数据的传递,可以将一个链路的所有过程串起来。
采样和存储
为了减少性能消耗,避免存储资源的浪费,dapper并不会上报所有的span数据,而是使用采样的方式。举个例子,每秒有1000个请求访问系统,如果设置采样率为1/1000,那么只会上报一个请求到存储端。
链路中的span数据经过收集和上报后会集中存储在一个地方,Dapper使用了BigTable数据仓库,常用的存储还有ElasticSearch, HBase, In-memory DB等。
Opentraceing 数据模型
Opentracing 是分布式链路追踪的一种规范标准,是 CNCF(云原生计算基金会)下的项目之一。只要某链路追踪系统实现了 Opentracing 规定的接口(interface),符合Opentracing 定义的表现行为,那么就可以说该应用符合 Opentracing 标准。
它的数据模型和谷歌Dapper论文里的如出一辙。
span
Span 是一条追踪链路中的基本组成要素,一个 Span 表示一个独立的工作单元,比如可以表示一次函数调用,一次 HTTP 请求等等。Span 会记录如下基本要素:
-
服务名称(operation name)
-
服务的开始时间和结束时间
-
K/V形式的Tags
保存用户自定义标签,主要用于链路追踪结果的查询过滤。Span 中的 tag 仅自己可见,不会随着 SpanContext 传递给后续 Span。
-
K/V形式的Logs
与 tags 不同的是,logs 还会记录写入 logs 的时间,因此 logs 主要用于记录某些事件发生的时间。
-
SpanContext
SpanContext携带着一些用于跨服务通信的(跨进程)数据,主要包含:
- 足够在系统中标识该span的信息,比如:
span_id,trace_id。 - Baggage Items,为整条追踪链保存跨服务(跨进程)的K/V格式的用户自定义数据。
- 足够在系统中标识该span的信息,比如:
-
References:该span对一个或多个span的引用(通过引用SpanContext)
trace
Trace表示一次完整的追踪链路,trace由一个或多个span组成。
Inject/Extract
Opentracing 提供了 Inject/Extract 用于在请求中注入 SpanContext 或者从请求中提取出 SpanContext。
客户端通过 Inject 将 SpanContext 注入到载体中,随着请求一起发送到服务端。
服务端则通过 Extract 将 SpanContext 提取出来,进行后续处理。
常见框架
框架对比
Google Dapper论文发出来之后,很多公司基于链路追踪的基本原理给出了各自的解决方案,具体如下:
- Twitter:Zipkin
- Uber:Jaeger
- Elastic Stack:Elastic APM
- Apache:SkyWalking(国内开源爱好者吴晟开源)
- Naver:Pinpoint(韩国公司开发)
- 阿里:鹰眼。
- 大众点评:Cat。
- 京东:Hydra
为了便于各系统间能彼此兼容互通,OpenTracing组织制定了一系列标准,旨在让各系统提供统一的接口。
国内这些基本都没开源,主要的开源框架对比如下:

原理
Zipkin
Zipkin 相对成熟,开源于2012年,同时也比较简单,Java 系大部分都会选择 Zipkin。

在服务运行的过程中会产生很多链路信息,产生数据的地方可以称之为Reporter。将链路信息通过多种传输方式如HTTP,RPC,kafka消息队列等发送到Zipkin的采集器,Zipkin处理后最终将链路信息保存到存储器中。运维人员通过UI界面调用接口即可查询调用链信息。
Jaeger
Jaeger 则是 CNCF 旗下,对 K8s 有较好的兼容性,Go 语言系可能是个不错的选择。

Jaeger的原理和Zipkin二者的架构有些类似。都是由嵌入到代码中的client来收集数据,并传输到Collector端进行存储,然后集中通过UI进行展示。
具体流程如下:
- 1)客户端通过 6831 端口上报数据给 agent
- 2)agent通过 14250 端口将数据发送给 collector
- 3)collector 将数据写入 kafka
- 4)Ingester 从 kafka中读取数据并写入存储后端
- 5)query 从存储后端查询数据并展示
另外近两年基于 ServiceMesh 的 ”无” 侵入式链路追踪也广受欢迎,似乎是一个被看好的方向,其代表作之一 Istio 便是使用 CNCF 出身的 Jaeger,且 Jaeger 还兼容 Zipkin,在这点上 Jaeger 完胜。