pytorch深度学习实践-RNN高级篇
视频源
《PyTorch深度学习实践》13.循环神经网络(高级篇)
课件下载 提取码 cxe4
practice
Name Classfication
根据名字的拼写进行名字所属国家的分类

传统自然语言处理,字/词one-hot编码->嵌入低维度(embedding)->RNN Cell->Linear(统一维度) ->output

而回到当前问题,由于名字分类并不需要最后一层的输出,故问题可以简化为(机器只需要从头到尾看一遍名字即可)
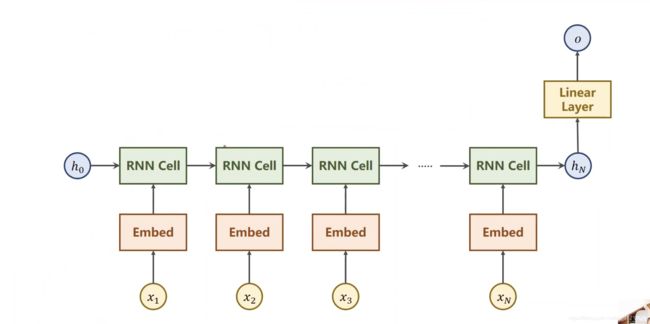
由于RNN容易造成梯度消失/梯度爆炸等问题,而LSTM计算量又偏大,故采用折中的GRU建模如下

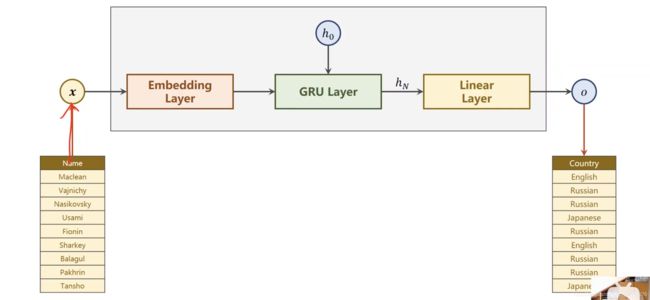
Preparing Data

转成ASCII码之后可以转成one-hot编码,之后进行padding统一长度(方便构成张量(tensor))

国家转分类索引

模型选取 双向RNN/LSTM/GRU


code
import csv
import gzip
import math
from datetime import time
import matplotlib.pyplot as plt
import numpy as np
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2
N_EPOCHS = 100
N_CHARS = 128
USE_GPU = False
class NameDataset(Dataset):
def __init__(self,is_train_set=True):
filename = 'data/names_train.csv.gz' if is_train_set else 'data/names_test.csv.gz'
with gzip.open(filename,'rt') as f:
reader = csv.reader(f)
rows = list(reader)
self.names = [row[0] for row in rows]
self.len = len(self.names)
self.countries = [row[1] for row in rows]
self.country_list = list(sorted(set(self.countries)))
self.country_dict = self.getCountryDict()
self.country_num = len(self.country_list)
def getCountryDict(self):
country_dict = dict()
for idx,country_name in enumerate(self.country_list,0):
country_dict[country_name] = idx
return country_dict
def idx2country(self,index):
return self.country_list[index]
def getCountriesNum(self):
return self.country_num
def __getitem__(self, index):
return self.names[index],self.country_dict[self.countries[index]]
def __len__(self):
return self.len
def time_since(since):
s = time.time() - since
m = math.floor(s/60)
s -= m*60
return '%dm%ds'%(m,s)
def showAcc(acc_list):
epoch = np.arange(1,len(acc_list) + 1 , 1)
acc_list = np.array(acc_list)
plt.plot(epoch,acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
def name2list(name):
arr = [ord(c) for c in name]
return arr,len(arr)
def make_tensors(names,countries):
'''
:param names:
:param countries:
:return:
为了提高运算效率,将batch中的数据按照padding的从短到长排序
'''
sequences_and_lengths = [name2list(name) for name in names]
name_sequences = [s1[0] for s1 in sequences_and_lengths]
seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_lengths])
countries = countries.long()
#make tensor of name , BatchSize x SeqLen
seq_tensor = torch.zeros(len(name_sequences),seq_lengths.max()).long()
for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx,:seq_len] = torch.LongTensor(seq)
#sort by length to use pack_padded_sequence
#sort返回两个值(排序完成后的数据,数据对应的未排序时候的id)
seq_lengths,perm_idx = seq_lengths.sort(dim=0,descending=True)
#得到id之后进行相应排序
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return create_tensor(seq_tensor),create_tensor(seq_lengths),create_tensor(countries)
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
#input of Embedding Layer with shape(input_size):(seqLen,batchSize) output of Embedding Layer with shape(seqLen,batchSize,hiddenSize)
self.embedding = torch.nn.Embedding(input_size,hidden_size)
# Parameters of GRU layer input_size,output_size,num_layers,bidirectional
# The inputs of GRU Layer with shape:
# input:(seqLen,batchSize,hiddenSize)
# hidden:(nLayers*nDirections,batchSize,hiddenSize)
# The outputs of GRU Layer with shape:
# output:(seqLen,batchSize,hiddenSize*nDirections)
# hidden:(nLayers*nDirections,batchSize,hiddenSize)
self.gru = torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size*self.n_directions,output_size)
def _init_hidden(self,batch_size):
hidden = torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden)
def forward(self,input,seq_lengths):
# input shape : BXS -> SXB
input = input.t()#transpose 矩阵转置
batch_size = input.size(1)
#Initial hidden with shape:
# (nLayer*nDirections,batchSize,hiddenSize)
hidden = self._init_hidden(batch_size)
#result of enbedding with shape:
# (seqLen,batchSize,hiddenSize)
embedding = self.embedding(input)
#pack them up
# 为了增加运算速度,因为padding的0实际上是不需要参与运算的
# 返回一个PackedSquence 对象
gru_input = pack_padded_sequence(embedding,seq_lengths)
#the hidden with shape:
# (nLayers*nDirection,batchSize,hiddenSize)
output,hidden = self.gru(gru_input,hidden)
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1],hidden[-2]],dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def trainModel():
total_loss = 0
print("training trained model...")
for i,(names,countries) in enumerate(trainloader,1):
inputs,seq_lengths,target = make_tensors(names,countries)
output = classifier(inputs,seq_lengths)
loss = criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i%10 == 0:
print(f'[{time_since(start)}] Epoch {epoch}',end='')
print(f'[{i*len(inputs)}]/{len(trainset)}',end='')
print(f'loss = {total_loss/(i*len(inputs))}')
return total_loss
def testModel():
correct = 0
total = len(testset)
print("evaluating trained model...")
with torch.no_grad():#不产生计算图,节约算力内存
for i,(names,countries) in enumerate(testloader,1):
inputs,seq_lengths,target = make_tensors(names,countries)
output = classifier(inputs,seq_lengths)
pred = output.max(dim=1,keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
percent = '%.2f'%(100*correct/total)
print(f'Test set: Accuracy {correct}/{total} {percent}%')
return correct/total
if __name__ == '__main__':
#prepare DataSet and DataLoader
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset,batch_size=BATCH_SIZE,shuffle=False)
N_COUNTRY = trainset.getCountriesNum()#output_size of model
classifier = RNNClassifier(N_CHARS,HIDDEN_SIZE,N_COUNTRY,N_LAYER)
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(),lr=0.001)
start = time.time()
print("Training for %d epochs..."%N_EPOCHS)
acc_list = []
for epoch in range(1,N_EPOCHS + 1):
trainModel()
acc = testModel()
acc_list.append(acc)