OpenCV-Python的文本透视矫正与水平矫正
已经感觉一个月没有更博了,最近也是在找工作找实习。最近在看的就是如何使用神经网络去做一个OCR识别,网上的资料多种多样,包括分割单字进行识别的,也有不定长文字识别。网络模型目前看到比较多的是CRNN,检测的模型包括CTPN、YOLO等等。
今天整理的是数据预处理上的文本透视矫正与水平矫正。
一、透视矫正
透视矫正是什么?比如发现了一页纸,写的挺好,你想拍下来,但是拍摄时角度的问题,你拍成了下面左边的样子,但是你本来想的是从纸的正上方去拍,所以你要想办法去把照片矫正成右边的样子,矫正的过程称为透视矫正。


所以呢为了透视矫正,首先需要的就是找到这张纸的轮廓,然后按照从大小的顺序排列,排好之后,找出最大的轮廓,如果判定找到的最大轮廓有四个点,则可以判定我们找到这张纸,然后用四点透视变换获得纸张的俯视图。
写好的函数是这样:
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype = "float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
# 透视矫正
def perspective_transformation(img):
# 读取图像,做灰度化、高斯模糊、膨胀、Canny边缘检测
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
dilate = cv2.dilate(blurred, cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)))
# edged = cv2.Canny(dilate, 75, 200)
edged = cv2.Canny(dilate, 30, 120, 3)
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1] # 判断是OpenCV2还是OpenCV3
docCnt = None
# 确保至少找到一个轮廓
if len(cnts) > 0:
# 按轮廓大小降序排列
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
for c in cnts:
# 近似轮廓
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 如果我们的近似轮廓有四个点,则确定找到了纸
if len(approx) == 4:
docCnt = approx
break
# 对原始图像应用四点透视变换,以获得纸张的俯视图
paper = four_point_transform(img, docCnt.reshape(4, 2))
return paper然后,你找到纸以后,可能会发现上面的字会有一点点倾斜,虽然感觉上是没什么问题,但是在识别的过程中会因为这一点点的倾斜导致识别串行。数据分析的过程就会比较麻烦。所以尽可能在预处理过程中就避免这类问题的发生。
二、文本水平矫正
其实,这也叫做文本的水平矫正。毕竟跟普通的水平矫正还不太一样,普通的水平矫正图像都会带有自己的边缘,根据边缘可以提取出一个mask,然后进行旋转即可。文本图像的背景是白色的,所以我们没有办法像人民币发票那类有明显边界的矩形物体那样,提取出轮廓并旋转矫正。这里我们用基于直线探测的水平矫正。
霍夫变换算法思想:以直线检测为例,每个像素坐标点经过变换都变成都直线特质有贡献的统一度量,一个简单的例子如下:一条直线在图像中是一系列离散点的集合,通过一个直线的离散极坐标公式,可以表达出直线的离散点几何等式如下:
X *cos(theta) + Y * sin(theta) = r 其中角度theta指r与X轴之间的夹角,r为到直线几何垂直距离。任何在直线上点,x, y都可以表达,其中 r, theta是常量。该公式图形表示如下:
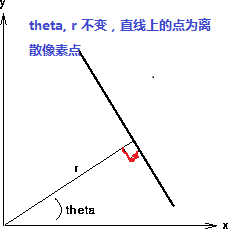
然而在实现的图像处理领域,图像的像素坐标P(x, y)是已知的,而r, theta则是我们要寻找的变量。如果我们能绘制每个(r, theta)值根据像素点坐标P(x, y)值的话,那么就从图像笛卡尔坐标系统转换到极坐标霍夫空间系统,这种从点到曲线的变换称为直线的霍夫变换。变换通过量化霍夫参数空间为有限个值间隔等分或者累加格子。当霍夫变换算法开始,每个像素坐标点P(x, y)被转换到(r, theta)的曲线点上面,累加到对应的格子数据点,当一个波峰出现时候,说明有直线存在。
所以我们的思路是:
- 用霍夫线变换探测出图像中的所有直线
- 计算出每条直线的倾斜角,求他们的平均值
- 根据倾斜角旋转矫正
给出完整代码:
# coding=utf-8
import cv2
import numpy as np
input_img_file = "../test/test.png"
# 度数转换
def DegreeTrans(theta):
res = theta / np.pi * 180
return res
# 逆时针旋转图像degree角度(原尺寸)
def rotateImage(src, degree):
# 旋转中心为图像中心
h, w = src.shape[:2]
# 计算二维旋转的仿射变换矩阵
RotateMatrix = cv2.getRotationMatrix2D((w/2.0, h/2.0), degree, 1)
print(RotateMatrix)
# 仿射变换,背景色填充为白色
rotate = cv2.warpAffine(src, RotateMatrix, (w, h), borderValue=(255, 255, 255))
return rotate
# 通过霍夫变换计算角度
def CalcDegree(srcImage):
midImage = cv2.cvtColor(srcImage, cv2.COLOR_BGR2GRAY)
dstImage = cv2.Canny(midImage, 50, 200, 3)
lineimage = srcImage.copy()
# 通过霍夫变换检测直线
# 第4个参数就是阈值,阈值越大,检测精度越高
lines = cv2.HoughLines(dstImage, 1, np.pi/180, 200)
# 由于图像不同,阈值不好设定,因为阈值设定过高导致无法检测直线,阈值过低直线太多,速度很慢
sum = 0
# 依次画出每条线段
for i in range(len(lines)):
for rho, theta in lines[i]:
# print("theta:", theta, " rho:", rho)
a = np.cos(theta)
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = int(round(x0 + 1000 * (-b)))
y1 = int(round(y0 + 1000 * a))
x2 = int(round(x0 - 1000 * (-b)))
y2 = int(round(y0 - 1000 * a))
# 只选角度最小的作为旋转角度
sum += theta
cv2.line(lineimage, (x1, y1), (x2, y2), (0, 0, 255), 1, cv2.LINE_AA)
cv2.imshow("Imagelines", lineimage)
# 对所有角度求平均,这样做旋转效果会更好
average = sum / len(lines)
angle = DegreeTrans(average) - 90
return angle
if __name__ == '__main__':
image = cv2.imread(input_img_file)
cv2.imshow("Image", image)
# 倾斜角度矫正
degree = CalcDegree(image)
print("调整角度:", degree)
rotate = rotateImage(image, degree)
cv2.imshow("rotate", rotate)
# cv2.imwrite("../test/recified.png", rotate, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
cv2.waitKey(0)
cv2.destroyAllWindows()所以我就从参考的博客中也找的一样的图进行测试,效果还不错~以下图分别是原图,直线检测之后,旋转之后。

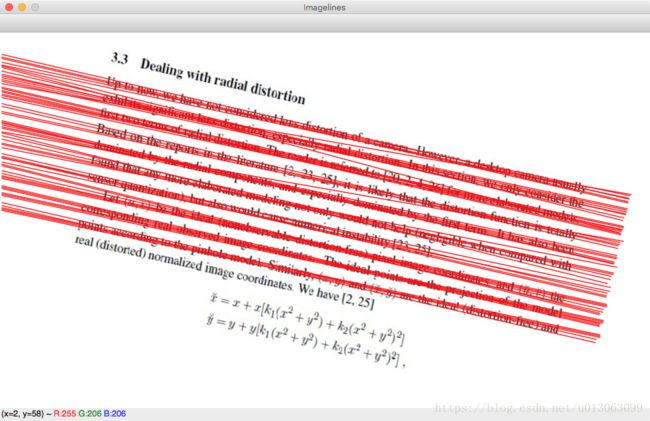

谢谢大佬们提供的思路,后续可以再利用这个方法提取出需要的数据区域等等,未完待续哦~
【参考资料】
http://www.cnblogs.com/skyfsm/p/7324346.html
http://www.cnblogs.com/skyfsm/p/6902524.html
https://blog.csdn.net/jia20003/article/details/7724530