2022年最新深度学习入门指南

概述
深度学习是用于处理视觉相关任务的强大的方法。
卷积神经网络是一种深度学习模型,我们用它来处理与计算机视觉相关的应用程序。
在本指南中,我们将探索 CNN 的工作原理以及它们如何应用于图像分类任务。我们还将构建一个 CNN 模型,并使用 Keras 从头开始在训练数据集上对其进行训练。
介绍
我一直着迷于深度学习模型的潜力和力量,以及它们如何理解执行图像分类、图像分割、对象检测等任务。我们还遇到了一些分割算法,例如来自 X-的肿瘤/异常检测,他们在这方面的表现甚至优于医生。
在本指南中,我们将全面介绍 CNN 及其在图像分类任务中的应用。我们将首先介绍卷积神经网络 (CNN) 背后的基本理论、它们的工作原理以及它们如何成为用于任何计算机视觉任务的最流行的模型之一。
现在让我们开始吧……
卷积神经网络
CNN 或卷积神经网络是将图像作为输入并通过使用卷积运算学习图像中的局部模式的算法。而密集层/全连接层则从输入中学习全局模式。
CNN 的学习局部模式具有两个特性:
CNN 学习的模式是不变的,即在学习识别图像左下角的特定模式后,CNN 可以识别图像中的任何位置。但是,如果密集连接的网络出现在新位置的任何位置,则必须重新学习该模式。这使得 CNN 在处理和理解图像时具有数据效率。
CNN 可以学习模式的空间层次,即第一个卷积层学习一个小的局部模式,如边缘或线,第二个卷积层学习由第一个卷积层学习的特征组成的更大的模式,依此类推。通过这种方式,CNN 学习和理解了越来越复杂和抽象的视觉概念。
让我们看看下面的猫图,在这里我们可以看到,在第一个卷积层中,学习了边缘、曲线等模式。但在第二层 CNN 中,眼睛、鼻子或耳朵等特征是通过使用第一层的模式来检测的。通过这种方式,CNN了解图像并了解图像中的对象。
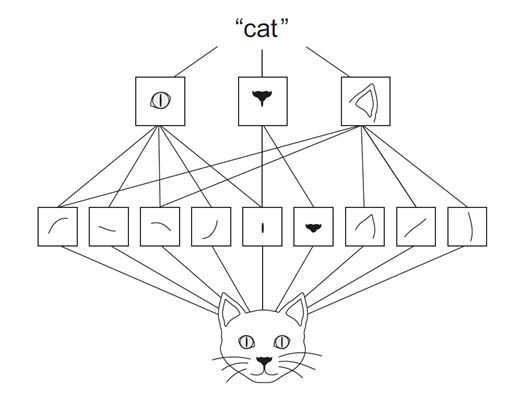
参考特征提取
现在让我们探索并了解它是如何工作的。
卷积运算
卷积是应用于 3D 张量的操作,称为特征图。这些特征图由两个空间轴(高度和宽度)和一个深度轴(或通道轴)组成。
如果我们考虑 RGB 图像的示例,高度和宽度构成空间轴,3 个颜色通道表示深度轴。类似地,对于黑白图像,深度为 1。但在其他层的输出中,深度不是由颜色通道表示,而是代表过滤器。
过滤器对输入数据的特定方面进行编码,即过滤器可以对“面部存在”或“汽车结构”等概念进行编码。
卷积运算由两个关键参数组成,
内核大小:应用于图像的过滤器的大小。这些是典型的 3×3 或 5×5。
输出特征图的深度:这是卷积计算的输出滤波器的数量。
卷积操作只是在输入特征图上乘加加权滤波器,以生成另一个具有不同宽度、高度和深度的 3D 张量。卷积操作通过在 3D 输入特征图上滑动这些大小为 3×3 或 5×5 过滤器的窗口,在每个可能的位置停止,然后计算特征。
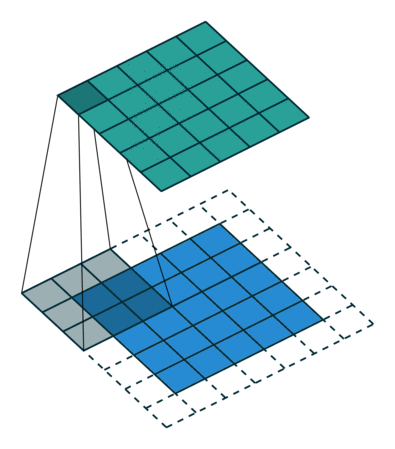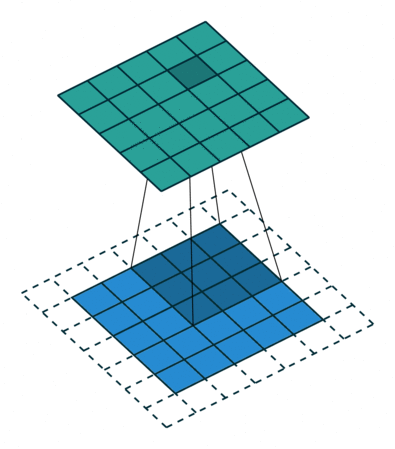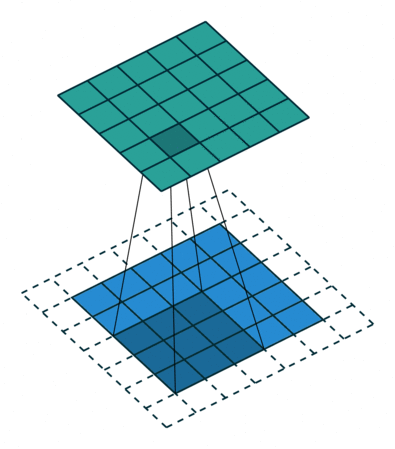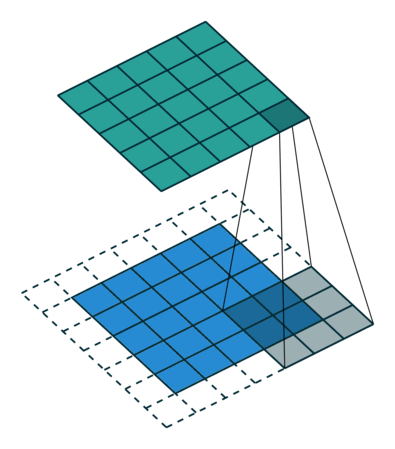
我们可以在下面的 gif 中看到操作,3×3 内核在 5×5 输入特征图上运行以生成 3×3 输出。

参考卷积
重要的是要注意网络从给定数据中学习所需的最佳过滤器。CNN 模型的权重是过滤器。
现在让我们看看边框效果、填充和步幅。
了解边框效果和填充
现在再次让我们考虑 5×5 特征图(参考上面的 gif)。过滤器的大小为 3×3,因此有 9 个图块。
现在在卷积操作期间,3×3 滤波器只能通过 5×5 特征图 9 次,因此我们的输出大小为 3×3。所以输出在这里从 5×5 缩小到 3×3,也就是说,在每个维度旁边缩小了两个图块。这里没有对输入特征图应用填充,因此称为有效填充。
如果我们希望输出特征图与输入特征图的大小相同,我们需要使用填充。填充包括在输入特征图的每一侧添加适当数量的行和列,以使每个输入图块周围的中心卷积窗口成为可能。这种类型的填充称为相同的填充。以下 GIF 表示相同的填充。
 源边框效果和填充
源边框效果和填充
现在我们可以看到,当我们向 5×5 特征图添加额外的填充并应用 3×3 过滤器时,我们将能够获得与输入特征图大小相同的输出特征图。
如何找到要添加到给定过滤器大小和特征图的填充?
当我们遇到不同大小的特征图和过滤器以及我们如何确定对于有效和相同的情况应该使用多少填充时,自然会出现这个问题。所以要回答这个问题,我们有确定填充的公式,即
有效填充:因为有效填充意味着没有填充,所以padding的数量将为0。
相同填充:我们使用相同的填充来保留输入特征图的大小。但是卷积的输出主要取决于过滤器的大小,与输入大小无关。因此,可以根据过滤器大小确定填充,如下所示:
相同填充 =(过滤器大小 - 1)/ 2
现在让我们看看另一个可以影响输出大小的因素,即步幅。
了解步幅
步幅是影响输出特征图大小的因素之一。步幅是应用过滤器的两个连续窗口之间的距离。
在上面的例子中,我们已经看到过滤器作为窗口被应用于输入特征图,并被移动一个单位或步幅。当这种转变大于1时,我们将其定义为跨步的CNN。下面的GIF是一个大步为2的CNN的例子。
我们还可以观察到,当我们使用步幅的值为 2(或大于 1)时,与常规卷积(当 stride 的值 = 1 时)相比,输出特征图的大小减小(下采样因子为 2) .
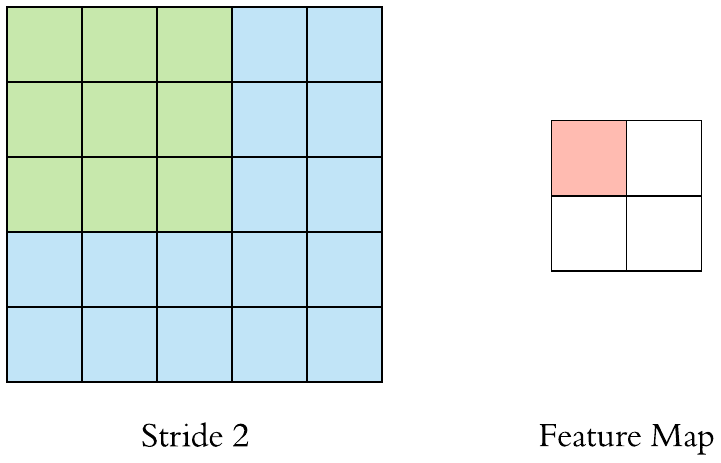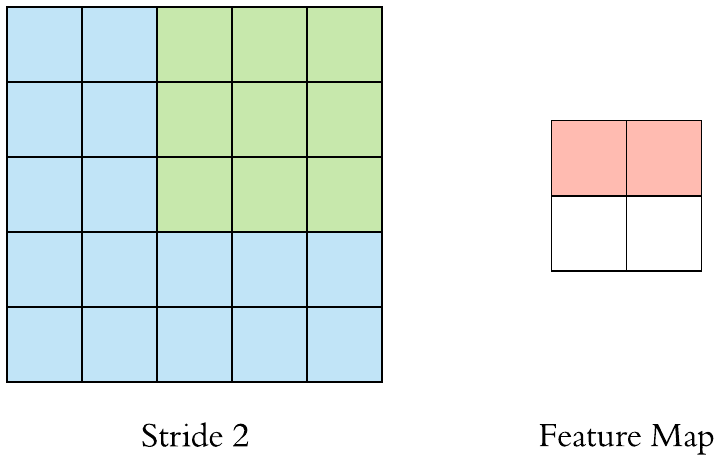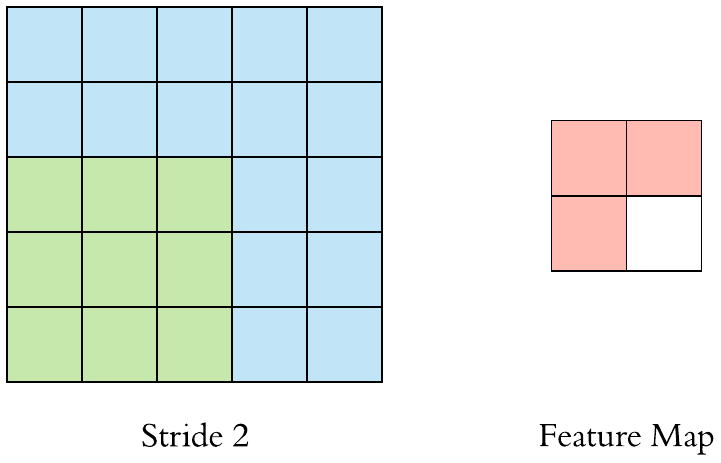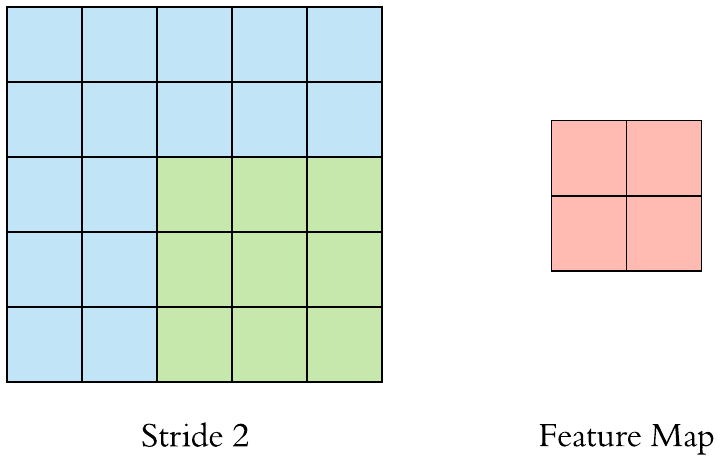
因此我们可以说使用步幅是对输入特征图进行下采样的方法之一。但它们在实践中很少使用,但它仍然是 CNN 的重要概念之一,了解它是很好的。
现在在开始 CNN 的实现之前,让我们看一下用于对输入特征进行下采样的另一个重要概念,即池化。
理解池化
池化操作可以定义为一种通过使用不同的策略(例如取平均值、最大值、总和等)来积极减小/下采样输入特征图的大小的方法。现在让我们看看不同类型的池化
1.最大池化:最大池化是一种广泛使用的池化策略,用于对输入特征图进行下采样。在这一层中,确定大小的窗口通过输入特征图,然后获得最大值并计算为下一层或输出特征图。
我们可以在下面的 GIF 中看到,当我们使用过滤器大小 2 执行最大池化时,输入特征被下采样因子 2 或减半。
我们可以通过以下公式确定使用最大池化后输出的大小:
输出大小=输入大小/(池化过滤器大小)

还有其他类型的池化策略,例如考虑窗口平均值的平均池化和考虑窗口权重总和的求和池化。
但最大池化一直是最流行和最广泛使用的池化策略。这是因为当我们考虑过滤器窗口的最大值时,我们将能够将有关输入特征/当前特征图的大部分可用信息转移到下一个特征图。因此,当我们通过神经网络的层进行传播时,减少了数据的丢失。
既然我们对 CNN 的工作原理有了一些了解,那么现在让我们从头开始实现一个 CNN.
从头开始训练基于 CNN 的图像分类器
现在让我们在 MNIST 数据集上训练一个 CNN 模型。MNIST 数据集由 0 到 9 的手写数字图像组成,即 10 个类。训练集由 60000 张图像组成,测试集由 10000 张图像组成。让我们使用 CNN 从头开始训练图像分类器。我们将在Keras框架中实现代码。
Keras 是最受欢迎和使用最广泛的深度学习库之一。它是作为高级 API 构建的,可以轻松使用 TensorFlow。
要完成以下代码实现,建议使用带有 GPU 的 Jupyter Notebook。可以通过Google Colaboratory访问相同的内容,该实验室提供基于云的 Jupyter Notebook环境和免费的 Nvidia GPU。
现在让我们开始吧
获取 MNIST 数据集
在下载数据集之前,让我们进行必要的导入,
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import layers
from tensorflow.keras import models
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import pyplot现在让我们下载数据,
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()上面的代码下载数据并缓存。由于我们正在加载预定义的数据集,因此该数据集已经被预处理并以元组的形式打包。
现在让我们探索我们解压出来的这些张量的形状,
int("Shape of training dataset: ",train_images.shape)
print("Shape of test dataset: ",test_images.shape)
print("Shape of training dataset labels: ",train_labels.shape)
print("Shape of test dataset labels: ",test_labels.shape)输出:

从上面的输出我们可以看到,训练数据集有 60000 张图片,每张图片的大小为 28×28。同样,测试数据集有 10000 张图像,图像大小为 28×28。
我们还可以看到标签没有任何形状,即它是一个标量值。让我们看看一些标签,
print(train_labels)
print(type(train_labels))输出:
我们可以看到标签都在一个 NumPy 数组中。
现在让我们看看我们的一些训练图像,
# plot first few images
for i in range(9):
# define subplot
pyplot.subplot(330 + 1 + i)
# plot raw pixel data
pyplot.imshow(train_images[i], cmap=pyplot.get_cmap('gray'))
# show the figure
pyplot.show()输出:

我们可以通过绘制它们来可视化训练样本。
在我们继续模型训练之前,让我们对我们的数据进行一些预处理。
基本预处理
现在让我们将图像从 (60000, 28, 28) 重塑为 (60000, 28, 28, 1) 大小,其中最后一个维度表示图像的深度。我们之前已经看到,每个图像的特征图都有三个维度,即宽度、高度和深度。由于 MNIST 训练集由黑白图像组成,我们可以将深度定义为 1。
接下来,我们应该对数据集进行归一化,即将输入的所有值都在 0 和 1 之间。由于图像层的最大值是 255,我们将整个数据集除以 255。
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255现在让我们也对测试集应用相同的预处理。
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255最后,让我们将标签转换为分类格式,即它们目前作为标量,但我们正在执行 One-Hot 编码以将每个标量唯一地映射到向量。
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)train_labels[:10]输出:

我们可以看到训练标签是独热编码。
现在让我们使用 Keras 创建一个基本的 CNN 模型。
使用 Tensorflow-Keras 创建 CNN 模型
现在让我们使用 Keras 库创建一个基本模型,
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))现在我们来分析一下上面的代码,
首先,我们正在创建一个Sequential类型类的对象。Sequential 模型是一种模型,我们可以在其中添加和堆叠层以形成端到端模型。
使用**.add**我们通过根据层指定各种参数来将层添加到我们的模型中。
在上面的模型中,我们添加了一个卷积层(即 Keras 中的 Conv2D),它接受许多过滤器、内核大小和激活函数作为参数。
接下来,添加最大池化层(即 Keras 中的 MaxPool2D)以启用池化操作。
Keras 中提供了不同类型的层。
模型的上述部分负责识别和检测输入数据中存在的模式。(我们上面讨论过的工作)
现在最后让我们通过定义模型的输出数量来初始化头部。
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))现在我们的模型已经准备好了。我们可以使用**.summary()**方法查看模型中所有层的列表 。
model.summary()输出:
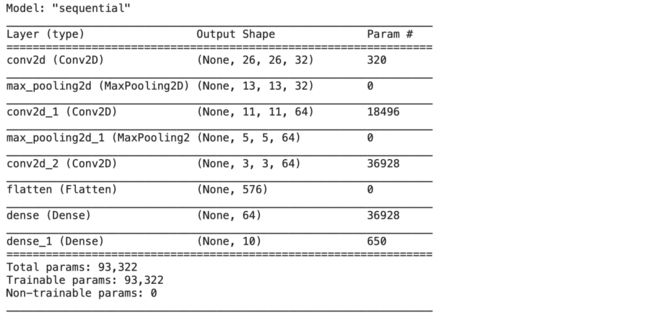
现在让我们通过分配优化器、损失函数和模型训练时使用的指标来编译模型。
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])现在让我们用训练数据和标签拟合模型并训练 5 个 epochs,
model.fit(train_images, train_labels, epochs=5, batch_size=64)结果:

从训练结果中我们可以看出,该模型能够达到高达 99% 的准确率,这真是令人印象深刻!!
结论
我们已经看到了卷积神经网络的底层功能以及它如何从图像中提取特征。因此,我们可以得出结论,卷积神经网络是在计算机视觉应用中产生最先进结果的技术之一。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
