JAVA 基础之集合专题
JAVA集合类是一个特别有用的工具类,可用于存储数量不确定的对象,并可以实现常用的数据结构,如栈,队列等。除此之外集合还可用于存储具有映射关系的关联数组。
JAVA集合大致可以分为Set,List,Map,Queue四种体系,其中Set代表无序不可重复的集合;List代表有序可重复的集合,Map代表具有映射关系的集合,java5又新增了Queue,代表一种队列集合实现。如果想要访问List集合的元素,可以通过索引来访问,访问Map集合的元素,通过key值来访问value值,访问Set集合元素,只能通过元素本身来访问这也是Set集合元素不可重复的原因。
集合和数组的主要区别:
1>数组是定长的,而集合的长度可变
2>数组可以存储基本数据类型和对象,而集合只能存储对象(实际上是对象的引用,习惯上称为对象)
Collection接口和Iterator接口:
Collection接口是Set,List,Queue接口的父接口,该接口里定义的方法同样可用于操作Set,List,Queue集合。下面是一些常用的方法,更多详细的方法请参见java的API
Iterator iterator() 返回一个Iterator对象,用于遍历集合
boolean add(Object o) 向集合中添加一个元素,如果集合别添加操作改变了,则返回true
boolean addAll(Collection c) 把集合中所有元素都添加到指定集合中,如果集合被添加操作改变了,则返回true
void clear() 清除集合中的所有元素,是的集合的长度变为0
boolean remove(Object o) ; 删除集合中指定的元素,如果集合中包含多个指定元素,则只删除第一个符合条件的
boolean contains(Object o) ; 判断集合中是否包含指定元素,包含则返回true
boolean isEmpty(); 判断集合是否为空,若为空则返回true
int size() ; 返回集合元素的个数
Object[] toArray() ; 把集合转换为数组,所有的集合元素变成对应的数组元素
import java.util.*;
public class CollectionTest
{
public static void main(String[] args)
{
Collection c1 = new ArrayList();
c1.add("孙悟空");
c1.add("猪八戒");
c1.add(6); //虽然集合不能存储基本数据类型,但java支持自动装箱
System.out.println(c1.size()); //3
System.out.println(c1); //[孙悟空, 猪八戒, 6],集合都实现了toString()方法
c1.remove("猪八戒");
System.out.println(c1.size()); //2
Collection c2 = new HashSet();
c2.add("孙悟空");
c2.add(66);
c1.addAll(c2);
System.out.println(c1); //[孙悟空, 6, 66, 孙悟空] ,元素可以重复
c2.addAll(c1);
System.out.println(c2); //[6, 66, 孙悟空] ,元素不重复
System.out.println(c1.contains("猪八戒")); //false
c1.removeAll(c2);
System.out.println(c1); //[] 两个孙悟空都会被删除
Object[] obj = c2.toArray();
//obj.add("张三"); 变成定长数组,不能再添加元素
c2.clear();
System.out.println(c2); //[] 数组被清空
}
}
虽然两个集合的实现类不同,但是当作Collection来操作时使用上面的方法并没有任何区别
Lambda表达式遍历集合:
import java.util.*;
public class Iterator
{
public static void main(String[] args)
{
Collection c = new HashSet();
c.add("孙悟空");
c.add("猪八戒");
c.add("唐僧");
c.forEach(obj->System.out.println(obj));
}
}
java8为Iterable接口增加了一个forEach(Consumer action)方法遍历集合,该方法的参数是一个函数式接口,所以可以使用lambda表达式。Iterable接口是Collection的父接口,所以Collection对象可以直接调用该方法
Iterator迭代器
import java.util.*;
public class Iterat
{
public static void main(String[] args)
{
Collection c = new HashSet();
c.add("孙悟空");
c.add("猪八戒");
c.add("唐僧");
Iterator it = c.iterator(); //获得集合的迭代器对象
it.forEachRemaining(obj->System.out.println(obj)); //直接用java8新增的方法遍历集合元素
while(it.hasNext())
{
String p = (String) it.next();
System.out.println(p);
if(p == "猪八戒")
{
//c.remove(p); 1...将会产生异常
p = "沙和尚"; //2... 不会改变集合元素
it.remove();
}
}
System.out.println(c);
}
}
Iterator接口也是集合框架中的重要成员,它主要用于迭代访问Collection中的元素,所以Iterator的对象也被称为迭代器。Iterator依附于Collection集合,若没有Collection,Iterator将没有存在的意义
由上面的代码看出,Iterator接口提供了两种方法遍历Collection中的元素,还可以使用remove()删除迭代指针指向的元素。这里需要注意,在迭代器迭代Collection集合时,集合的元素不能被改变,只能通过迭代器的remove()方法删除元素,因为迭代器本身对这种改变是可预知的,否则将会产生运行时异常,如1....处的测试代码
再看2...处的测试代码,最终的集合输出结果并没有得到“沙和尚”这个字符串,这可以得出结论,当使用Iterator迭代访问Collection时,并不把几何元素本身传递给迭代变量,而是把集合元素的值传递给迭代变量,所以修改迭代变量的值并不会对改变集合
使用foreach遍历集合:
for (Object object : c)
{
System.out.println(object); //会引发异常
c.remove(object);
}这种方法更加的便捷,迭代变量得到的同样不是集合元素本身,所以修改迭代变量的值没有任何意义。在迭代集合时集合也不能被改变,否则会引发异常。
使用Predicate操作集合:
public class Predica
{
public static void main(String[] args)
{
Collection books = new ArrayList();
books.add("操作系统");
books.add("剑指offer");
books.add("疯狂java讲义");
books.add("java从入门到精通");
books.removeIf(book->((String) book).length()<10); //将满足条件的都删除
System.out.println(books);
}
}因为Predicate是函数式接口,所以可以使用lambda表达式,removeIf()中的Predicate参数作为筛选条件,将长度小于10的书删掉
Predicate的主要作用是筛选符合要求的集合元素。例如需要统计书名中包含“java”的书籍;统计长度不小于10的书;统计出现“疯狂”字样的书。如果按照之前的方法去做,则要用到循环,若是分别统计三种情况,则需三次循环,很麻烦。但是使用Predicate则要方便很多
import java.util.*;
import java.util.function.Predicate;
public class Predica
{
@SuppressWarnings("all")
public static void main(String[] args)
{
Collection books = new HashSet();
books.add(new String("操作系统"));
books.add(new String("剑指offer"));
books.add(new String("疯狂java讲义"));
books.add(new String("java从入门到精通"));
System.out.println(total(books,ele->((String) ele).length()<10)); //3
System.out.println(total(books, ele->((String) ele).contains("java"))); //2
System.out.println(total(books, ele->((String) ele).contains("疯狂"))); //1
}
public static int total(Collection c , Predicate p)
{
int cnt = 0;
for (Object object : c)
{
if(p.test(object)) //满足筛选条件
cnt++;
}
return cnt;
}
}
结合 Stream改进上述代码:
import java.util.*;
import java.util.function.Predicate;
public class Predica
{
@SuppressWarnings("all")
public static void main(String[] args)
{
Collection books = new HashSet();
books.add(new String("操作系统"));
books.add(new String("剑指offer"));
books.add(new String("疯狂java讲义"));
books.add(new String("java从入门到精通"));
System.out.println(books.stream().filter(ele->((String) ele).length()<10).count());
System.out.println(books.stream().filter(ele->((String) ele).contains("java")).count());
System.out.println(books.stream().filter(ele->((String) ele).contains("疯狂")).count());
//附加代码用于进一步了解Stream对集合的操作
books.stream().mapToInt(ele->((String) ele).length()).forEach(obj->System.out.println(obj));
//获得集合的Stream之后,可以对集合整体进行操作
System.out.println(books.stream().count());
}
}
使用Stream省去了对集合的遍历操作来判断集合元素是否满足条件,由于Stream使用较少,更多Stream的用法参考API文档。
Set集合:
Set集合就像一个罐子,不能记住元素添加的顺序,也不允许元素重复,若添加重复元素,add()方法会返回false
HashSet类:
HashSet类是Set接口典型的实现类,也是我们经常使用到的类,线程不安全,元素值可以为空,通过hash算法决定元素的存储位置,因此具有较好的存取和查找性能
下面我们来看一看HashSet判断集合元素相等的标准
import java.util.Collection;
import java.util.HashSet;
//A类只重写equals方法,总是返回true
class A
{
public boolean equals(Object obj)
{
return true;
}
}
//B类重写hashCode方法,总是返回相同的值
class B
{
public int hashCode()
{
return 1;
}
}
//C类重写两个方法
class C
{
public boolean equals(Object obj)
{
return true;
}
public int hashCode()
{
return 2; //注意,这里不能再返回1,因为类C的hashCode()返回值为1,不然C的对象都添加失败
}
}
public class HashSetTest
{
@SuppressWarnings("all")
public static void main(String[] args)
{
Collection hs = new HashSet();
hs.add(new A());
hs.add(new A());
hs.add(new B());
hs.add(new B());
System.out.println(hs.add(new C()));
System.out.println(hs.add(new C()));
System.out.println(hs.size());
System.out.println(hs);
}
}
最终的集合中,AB的对象为两个,C类的对象只添加进一个。由此得出结论,HashSet判断元素相等的条件是,equals()方法返回值为true,hashCode()返回值相等。如果 equals()方法返回值为true,而hashCode()返回值不相等,则把相同的元素放在了不同的位置上,这不满足HashSet元素不能重复的要求;如果equals()方法返回值为false,而hashCode()的返回值相等,则把元素放在哈希表的相同位置,用链表链接起来,HashSet访问集合元素是根据hashCode值快速定位的,如果HashSet中有两个元素具有相同的hashCode值,必然导致性能下降。
如果要把某个类的对象保存到HashSet中,在重写类的equals()和hashCode()方法时,要尽量保证两者返回值的一致性,即equals()判断元素相等,则他们的哈希值就相等,通常equals()方法中用于比较元素相等的实例变量,都应该用于计算哈希值
如果集合中包含可变元素,若修改了用于判断相等与计算哈希值的实例变量,将导致无法正确操作集合中被修改的元素。看一个例子:
import java.util.*;
class Q
{
int number;
public Q(int number)
{
this.number = number;
}
public boolean equals(Object obj)
{
if(this == obj)
return true;
if(obj!=null&obj.getClass()==Q.class)
{
Q s = (Q)obj;
return s.number == this.number;
}
return false;
}
public int hashCode()
{
return this.number;
}
public String toString()
{
return "number:"+number;
}
}
public class HashSetTest2
{
public static void main(String[] args)
{
Collection N = new HashSet();
N.add(new Q(-1));
N.add(new Q(0));
N.add(new Q(1));
N.add(new Q(2));
System.out.println(N); //[number:-1, number:0, number:1, number:2]
Iterator it = N.iterator();
Q first = (Q) it.next(); //将对象的引用传给first
first.number=2;//将第一个元素修改成与第二个元素相等的元素,equals,hashCode
System.out.println(N); //[number:2, number:0, number:1, number:2]
N.remove(new Q(2));
System.out.println(N); //[number:2, number:0, number:1]只删除了未被修改过的number为2的对象
System.out.println("集合中是否包含number为2的元素?"+N.contains(new Q(2))); //false
N.remove(new Q(2));
System.out.println(N);//[number:2, number:0, number:1],无法删除被修改过的第一个元素
System.out.println("集合中是否包含number为-1的元素?"+N.contains(new Q(-1))); //false
N.remove(new Q(-1)); //同样无法删除第一个元素
}
}
我们修改了number为-1 的元素的number为2,与最后一个元素的number值相等,这将违背了Set集合元素不能重复的原则。此外,我们无法正确的访问被修改过的第一个元素,因为他的哈希值为-1,而存储的值为2,如果我们用哈希值为-1的对象访问到了哈希表的指定位置,然而经equals方法比较之后返回false,则无法操作该对象,相同情况,用哈希值为2也不能正确访问到被修改的第一个元素。因此不要随意的修改参与计算哈希值与判断相等的实例变量。
LinkedHashSet类:
LInkedHashSet是HashSet的子类,它用链表维护了元素的插入顺序,因此性能略低于HashSet,但也是由于它用链表维护了内部顺序,所以在迭代访问数组元素时,效率较高。依然不允许元素重复
TreeSet类:
TreeSet是SortedSet接口的实现类,正如SortedSet名字所暗示的一样,TreeSet确保集合中的元素处于排序状态,注意是排序状态,而不是有序状态
下面是TreeSet较HashSet多出来的几种常见用法:
public class TreeSetTest
{
public static void main(String[] args)
{
SortedSet c = new TreeSet(); //此处不能再使用Collection接口
c.add(0);
c.add(6);
c.add(-1);
c.add(4);
System.out.println(c); //[-1, 0, 4, 6] 已排好序
System.out.println(c.first());
System.out.println(c.last());
System.out.println(c.headSet(2)); //[-1,0] 边界可以不是集合中的元素 不包括边界
System.out.println(c.tailSet(4)); //[4,6] 包括边界
System.out.println(c.subSet(0, 4)); //[0] 包括上边界 不包括下边界
System.out.println(((TreeSet) c).lower(0)); //比0小的第一个元素
}
}TreeSet采用红黑树的数据结构来存储元素,它支持两种排序方式,自然排序(默认)和定制排序
自然排序:
java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法用于比较两个元素的大小,obj1.compareTo(Object obj2),若返回值为正数,则obj1大于obj2,若为负数,则obj2大,若返回值为0,则表示相等
若试图把某一对象添加到TreeSet和中,则该对象的类必须实现Comparable接口,并将比较对象强制转换为相同类型,也就是说TreeSet中添加的对象必须为同一个类对象
public class TreeSetTest
{
public static void main(String[] args)
{
SortedSet c = new TreeSet();
c.add(new String());
c.add(new Date()); //引发异常
}
}
TreeSet中判定对象相等的依据:
import java.util.*;
class Person implements Comparable
{
int age;
public Person(int age)
{
this.age = age;
}
public int compareTo(Object o)
{
return 1;
}
public boolean equals(Object obj)
{
return true;
}
public String toString()
{
return "age:"+age;
}
}
public class TreeSetTest
{
public static void main(String[] args)
{
Person p = new Person(22);
TreeSet ts = new TreeSet();
ts.add(p);
ts.add(p); //虽然equals返回true,但是compareTo方法返回1,则会判定对象与本身都会不相等
System.out.println(ts); //[age:22, age:22]添加成功
}
}
由上面代码得出结论,TreeSet判定两个对象是否相等的条件只有compareTo()方法,若方法返回值为0,则两个对象视为相等,无法重复添加。但是如果equals判断对象相等,但compareTo返回值不等于0,则违反了Set集合元素不重复的规则,若equals返回不相等,但compareTo返回值为0,则无法正确添加元素,所以要保证equals与compareTo方法的返回值一致。
与HashSet集合相同,如果修改了集合中保存的可变对象用于判断equals和compareTo的变量,将导致钙元素不可操控,所以为了程序更加健壮,不要轻易修改集合元素的关键实例变量
定制排序:
TreeSet ts = new TreeSet((o1,o2)->
{
stu s1 = (stu)o1;
stu s2 = (stu)o2;
return s1.age>s2.age?-1:s1.age
创建TreeSet时键入Comparator比较器,可以指定排列顺序,判断两个元素是否相等的依据便是compare方法的返回值是否为0。
EnumSet类:
EnumSet是专为枚举类设计的集合类,EnumSet集合元素也是有序的,以EnumSet中枚举值在Enum类中的定义顺序来决定集合元素的顺序。且集合中的元素不能为空,否则会引发异常。
EnumSet类没有任何构造器,创建对象只能使用静态方法
import java.util.*;
enum Season
{
spring,summer,fall,winter;
}
public class EnumSetTest
{
public static void main(String[] args)
{
//创建EnumSet集合,集合元素就是Session枚举类全部枚举值
EnumSet es1 = EnumSet.allOf(Season.class);
System.out.println(es1);
//创建空的EnumSet
EnumSet es2 = EnumSet.noneOf(Season.class);
System.out.println(es2);
//手动添加值
es2.add(Season.spring);
es2.add(Season.winter);
System.out.println(es2);
EnumSet es3 = EnumSet.of(Season.winter, Season.summer);
System.out.println(es3); //自动调整顺序
EnumSet es4 = EnumSet.range(Season.summer, Season.winter); //这里前后顺序不能颠倒
System.out.println(es4);
EnumSet es5 = EnumSet.complementOf(es4); //es4+es5=Season
System.out.println(es5);
}
}
注:同一个EnumSet集合中的元素必须来自同一个enum类,不然会产生异常。
各Set实现类的性能分析:
HashSet的性能总是比TreeSet好,尤其是查询,添加元素等操作,由于TreeSet内部需要额外维护一个红黑树,只有当总是需要保持一个排好序的集合时,才考虑使用TreeSet
HashSet还有一个子类LinkedHashSet,它的查询和删除等操作等性能都要比HashSet差,因为它额外维护了一个链表,但是对于遍历操作,则会有更好的效率
EnumSet是所有Set实现类中性能最好的,但是它的取值有限。
List集合:
List是个有序,可重复的集合,集合中每个元素都有其对应的顺序索引,所以在Collection集合操作方法的基础上增加了一些使用索引的方法。下面列举一些常用的方法
import java.util.*;
public class ListTest
{
@SuppressWarnings("all")
public static void main(String[] args)
{
List list = new ArrayList();
list.add(new String("孙悟空"));
list.add(new String("猪八戒"));
list.add(new String("沙和尚"));
System.out.println(list); //[孙悟空, 猪八戒, 沙和尚] 有序
list.add(1, new String("唐僧"));
System.out.println(list); //[孙悟空, 唐僧, 猪八戒, 沙和尚]添加到索引为1的位置
System.out.println(list.get(0)); //孙悟空
list.remove(0);
System.out.println(list); //[唐僧, 猪八戒, 沙和尚]
list.set(1, new String("唐僧"));
System.out.println(list); //[唐僧, 唐僧, 沙和尚] 元素可重复
System.out.println(list.indexOf(new String("唐僧")));//0,第一次出现时索引的位置
System.out.println(list.subList(0, 2)); //[唐僧, 唐僧],包括0,不包括2
}
}
注: List集合判断两个元素相等的依据是equals方法的返回值,返回true,则相等。 set()方法的索引不能超过最大索引,add()的索引最大是数组最大索引+1
import java.util.*;
class MyComparator implements Comparator
{
public int compare(Object o1, Object o2)
{
String obj1 = (String)o1;
String obj2 = (String)o2;
return obj1.length()>obj2.length()?1:obj1.length()((String)o2).length()-((String)o1).length()); //1.....
System.out.println(books); //[Linux程序设计, Java编程思想, 鸟哥私房菜],反序输出
books.removeIf(ele->((String)ele).length()<8); //删除符合过滤条件的元素 //2.....
System.out.println(books);
books.replaceAll(ele->((String)ele).length()); //3.....
System.out.println(books);//[9, 8],将元素都替换成其对应长度
}
} 与Set集合只提供了iterator()方法相比,List还提供了listIterator()方法,该方法返回一个ListIterator对象,ListIterator继承Iterator,可以实现反向迭代,并向集合中添加元素(Iterator只能删除)
import java.util.*;
public class ListTest3
{
@SuppressWarnings("all")
public static void main(String[] args)
{
List books = new ArrayList();
books.add(new String("Java编程思想"));
books.add(new String("Linux程序设计"));
books.add(new String("鸟哥私房菜"));
ListIterator it = books.listIterator();
while(it.hasNext())
{
System.out.println(it.next());
it.add("------分隔符-------"); //在迭代指针的位置添加字符串
}
System.out.println("=========开始反向迭代=========");
while(it.hasPrevious())
{
System.out.println(it.previous());
it.remove();
}
System.out.println(books);
}
}更多关于List集合的操作方法请参考相关API文档
ArrayList与Vector
ArrayList和Vector都是List的实现类,Vector是个比较古老的集合,早在jdk1.0的时候就存在,所以包含了很多名称很长的方法,后来让它继承了List集合,所以一些功能会有重复。这两个实现类最主要的区别就是Vector是线程安全的
而ArrayList是线程不安全的,所以ArrayList的效率要高一些。他们都封装了一个动态的,可重新分配的Object[]数组,初始长度为10(也可以指定),Vectory可以设置存储空间增加的数量,而ArrayList不可以。
Vectory还有一个子类stack,用于模拟栈,同样线程安全,性能较差,所以渐渐的被ArrayDeque所取代。
在多线程并发的环境中,可以使用Collections工具类将ArrayList包装成为线程安全的。所以Vectory很少用
固定长度的List集合:
List fixedList = (List) Arrays.asList("孙悟空","猪八戒","沙和尚");
System.out.println(fixedList); //[孙悟空, 猪八戒, 沙和尚],变成数组
fixedList.forEach(ele->System.out.println(ele));
fixedList.add("唐僧"); //异常
fixedList.remove("孙悟空"); //异常该List集合是Arrays的内部类ArrayList的实例,固定长度,不能增加或删除元素,但是可以进行修改操作
Queue集合:
Queue用来模拟队列这种数据结构
PriorityQueue实现类:
PriorityQueue是Queue的实现类,它不是一个绝对标准的队列,因为它保存队列中元素的顺序并不是按元素加入的顺序,而是按照元素的大小,所以当我们使用peek()或者poll()方法获取队列中的元素时,并不是取出最先加入跌列中的元素,而是队列中最小的元素,这已经违反了队列的基本规则:先进先出
public class PriorityQueueTest
{
public static void main(String[] args)
{
PriorityQueue q = new PriorityQueue(2);
q.offer(6);
q.offer(-12); //当使用有容量限制的队列时,offer()要比add()好一些
q.add(-13); //[-13, 6, -12]
System.out.println(q); //通常只能保证对头的元素最小,不保证整个队列有序
System.out.println(q.poll());// -13
System.out.println(q.poll());// -12
System.out.println(q.poll());
System.out.println(q.poll()); //当队列为空时,poll()方法返回null,而remove()方法会抛出异常
System.out.println(q.remove());
}
}
执行上面的程序会发现,PriorityQueue并没有严格的按照元素的大小顺序排序,但这只是受到toString()方法的影响,当我们使用poll()方法得到队首元素时将会看到正确的排序结果。
PriorityQueue不允许插入null,与TreeSet一样,同样有两种排序方式:自然排序和定制排序
Deque接口:
Queue还有一Deque接口,该接口代表一个双端队列,可以在对头和对位进行添加和删除操作,即既可以来模拟栈,也可以模拟队列,有两个实现类ArrayDeque和LinkedList
ArrayDeque实现类:
ArrayDeque和ArrayList的实现机制基本相似,底层都采用一个动态的object[]数组来存储集合元素,初始容量为16
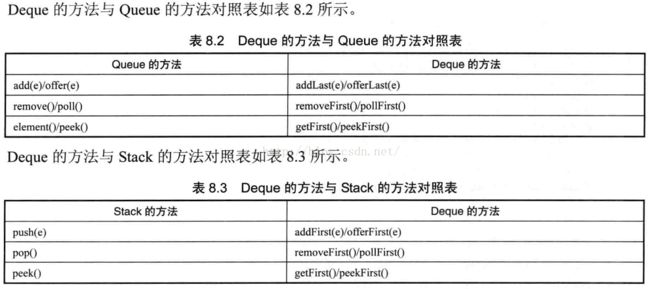
LinkedList实现类:
LinkedList既是List接口的实现类又是Deque接口的实现类,所以既可以通过索引来随机访问又可以将其作为双端队列来使用
public class LinkedListTest
{
public static void main(String[] args)
{
LinkedList books = new LinkedList();
books.push("计算机操作系统"); //作为栈加入栈顶元素
books.offer("java疯狂讲义"); //作为队列加入对尾元素
books.offerFirst("数据结构");//双端队列自身的用法。相当于队首,栈顶
System.out.println(books); //[数据结构, 计算机操作系统, java疯狂讲义]
System.out.println(books.peekFirst());
System.out.println(books.peek());
System.out.println(books.get(0)); //list集合的用法
//上面三种用法获得的同一个元素
}
}由上可见LinkedList是个功能非常强大的集合,其内部以链表的形式来保存集合元素,因此其在随机访问元素时性能较差,但在插入和删除元素时性能很好,只需要改变指针所指的地址即可
关于使用List集合的一些建议:
1>如果需要遍历集合,对弈ArrayList和Vectory来说使用索引随机访问集合效率更高,对于LinkedList采用迭代器遍历集合效率更高
2>如果经常需要进行插入和删除操作来改变拥有大量元素的List集合,则推荐使用LinkedList,使用ArrayList和Vectory可能经常需要重新分配数组的大小,性能较差
3>如果有多个线程同时访问一个List集合,则要考虑使用Collections工具类将集合包装成为线程安全的集合
Map集合:
Map用来保存具有映射关系的数据,key和value之间存在着单向的一对一关系,key值不能重复。 如果把key和value看作两个集合的话,保存key值的集合为Set(无序且不重复),而value值的集合像List(可以重复,通过key值得到value类似于List中的索引)。Map和Set集合关系很密切,他们的实现类以及接口都很相似,如果我们打开java的源码将会看到,先是实现了Map,然后通过包装一个value值都为空的Map实现了Set集合。
public class MapTest
{
public static void main(String[] args)
{
Map map = new HashMap();
map.put("web开发技术",56);
map.put("鸟哥私房菜",76);
map.put("计算接操作系统",100);
System.out.println(map); //Map重写了toString()方法,无序
System.out.println(map.put("web开发技术", 20)); //key相等时。返回被覆盖的value值
System.out.println(map.put(null, 20));
System.out.println(map.put(null, 30)); //只能成功添加一个null,再次添加会发生覆盖
System.out.println(map.containsKey("web开发技术"));
System.out.println(map.containsValue(57));
System.out.println(map.get("鸟哥私房菜"));
//遍历Map的几种方法
//1....
for (Object obj : map.keySet())
{
System.out.println(obj+"->" +map.get(obj));
}
//2...
Set set = map.entrySet();
Iterator it = set.iterator();
while(it.hasNext())
{
Map.Entry entry = (Entry) it.next();
System.out.println(entry.getKey()+"->"+entry.getValue());
}
//3...
for (Object obj : map.entrySet())
{
Map.Entry entry = (Map.Entry)obj;
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//4..
for (Object object : map.values())
{
System.out.println(object); //只能遍历value值
}
//5...java8新增加的方法
map.forEach((key,value)->System.out.println(key+"->"+value));
}
}
以上重点掌握遍历Map的几种方法
Java8为Map8新增的方法
import java.util.*;
//java8新增的一些方法
public class NewMap
{
public static void main(String[] args)
{
Map map = new HashMap();
map.put("数据库程序设计", null);
map.put("操作系统", null);
map.put("算法入门经典", null);
map.put("疯狂java讲义", 12);
/*
* compute(Object key,BiFunction remappingFunction)
* 根据key-value的值计算value,只要新value不为空,则覆盖;
* 若新的value为null,则删除此key-value对
* 若没有该key值,则遵循上面的规则,新value值为null,不添加新的key-value,否则添加
*/
map.compute("java", (key,value)->12);
System.out.println(map);
/*
* 根据key计算value
* 若value值问null或者不存在时,使用新value替换(添加)
* 若原value与新value同时为null,则不变,若新value为null,原value不存在,则不添加
*/
map.computeIfAbsent("数据库程序设计", key->null);
System.out.println(map);
/*
* 根据key-value计算value
* 若新value不为null,则替换,为null,则删除key-value对(类似compute)
* 若新value与原value都为null,则不变
*/
map.computeIfPresent("算法入门经典",(key,value)->null);
System.out.println(map);
/*
* 根据key计算value,若为null,则直接用新的value替换,若不为空则用计算出来的value替换
* 若计算出来的结果值为null,则删除key-value对
*/
map.merge("疯狂java讲义", 100, (oldVal,param)->null);
System.out.println(map);
}
}
以上列举了java8新增的几个方法,可能比较容易记混,我们完全可以使用的时候参考API文档
HashMap和Hashtable
HashMap与Hashtable的主要区别:
1>Hashtable是一个古老的集合类,它是线程安全的,所以效率较差
2>Hashtable不允许key,value为空,否则会引发空指针异常而Hashtable允许key,value为空
为了成功的在HashMap中存储获取对象,用作key的对象要实现equals()和hashCode()方法,通HashSet判断两个集合元素相等的条件是equals()返回true且hashCode()返回值相等,判断value相等的条件是equals()方法返回true
通HashSet相同,若使用可变对象作为HashSet的key,若修改了该对象,则也可能出现无法正常访问该对象,具体原理见HashSet。
LinkedHashMap实现类:
LinkedHashMap内部维护了一个双向链表,用于维护元素的插入顺序,所以性能低于HashMap的性能,但是遍历时性能较优
Properties实现类:
Properties是HashTable类的子类,在处理属性文件时比较方便,key和value只能是字符串类型。下面是Properties常用的几个方法。
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.*;
public class PropertiesTest
{
public static void main(String[] args)throws Exception
{
Properties pro = new Properties();
pro.setProperty("username", "lee");
pro.setProperty("password", "123");
pro.store(new FileOutputStream("a.text"),"test"); //test写在文件头中的类似与备注
Properties pro1 = new Properties();
pro1.setProperty("name", "张三");
//将a.text中的内容加入到pro1中,但是不保证顺序
pro1.load(new FileInputStream("a.text"));
System.out.println(pro1.get("username"));
}
}
SortedMap接口与TreeMap实现类:
与SortedSet与TreeSet类似,TreeMap同样维护了一个红黑树,(key)有自然排序与定制排序,判断两个可预知相等的条件是compareTo()方法返回值为0,这里不再赘述。
与TreeSet相同,TreeMap同样提供了一些根据顺序访问键值对的方法。
import java.util.*;
public class TreeMapTest
{
public static void main(String[] args)
{
TreeMap map = new TreeMap(); //使用上转型对象会失去一些方法
map.put(1, 10);
map.put(2, 20);
map.put(3, 30);
System.out.println(map.firstKey());
System.out.println(map.lastKey());
System.out.println(map.subMap(1, 2)); //包括一不包括2
System.out.println(map.firstEntry());
System.out.println(map.lastEntry());
System.out.println(map.tailMap(2, true)); //第二个参数决定是否包含2
System.out.println(map.lowerEntry(2));
}
}
WeakHashMap实现类:
WeakHashMap实现类的用法与HashMap基本相同,两者不同的是,HashMap的key保存了对对象的强引用,这意味着只要HashMap对象不被销毁,该HashMap所引用的所有对象就不会被垃圾回收,HashMap本身也不会自动清理这些对象;而WeakHashMap的key保存了对对象的弱引用,即如果其中保存的对象没有被其他强引用变量引用,就被被垃圾回收,WeakHashMap也可能自动删除这些key所对应的key-value对
import java.util.*;
public class WeakHashMapTest
{
public static void main(String[] args)
{
WeakHashMap wmap = new WeakHashMap();
wmap.put(new String("英语"), 66);
wmap.put(new String("语文"), 77);
wmap.put("数学", 88);
System.out.println(wmap); //{数学=88, 英语=66, 语文=77}
System.gc();
System.runFinalization();
System.out.println(wmap); //{数学=88}
}
}
IdentityHashMap实现类:
IdentityHashMap的用法与HashMap的用法基本相同,只是它在设计的时候有意违反了判断两个对象相等的条件,规定只有两个对象用==判断为true才是相等的。否则不会覆盖,只会添加新的key-value
EnumMap实现类:
1>EnumMap中所有的key都必须是枚举类中的值
2>key不能为空,但value可以,判断是否包含key的值为空,与删除可以为空的键值对都不会产生异常
3>key的存储顺序与其在枚举类中的顺序一致
4>在内部以数组形式保存
各Map实现类的 性能分析:
对于经常使用的Map实现类,HashMap与HashTable的实现机制几乎一样,但是由于HashTable是一个古老的线程安全的集合类,所以效率要低一些
TreeMap通常要比HashMap HashTable要慢,尤其是在插入和删除的时候更慢。它维护了一个红黑树,每个节点都是一个key-value对。他的优点是key总是处在排序状态,可以获取keySet,然后通过二分查找快速定位
最常用的是HashMap,他就是为快速查询而设计的
LinkedHashMap维护了一个双向链表,用来记录元素的插入顺序,效率比HashMap低一些,但是遍历效率较高
IdentityHashMap没有特别之处,只是判断相等的添加更加严格
Enummap性能最好,但是取值受限制
操作集合的工具类Collections
1>对List集合进行排序操作
public class CollectionTest1
{
public static void main(String[] args)
{
List list = new ArrayList();
list.add(-2);
list.add(9);
list.add(-3);
Collections.reverse(list); //数组元素反向排列
Collections.sort(list); //数组元素排序,也可指定comparetor
Collections.swap(list, 0,1); //交换元素
Collections.shuffle(list); //随机打乱顺序 洗牌
}
}2>查找和替换集合元素
public class CollectionTest1
{
public static void main(String[] args)
{
List list = new ArrayList(); //只能对List进行排序操作
//List list1 = new ArrayList(); //只能对List进行排序操作
//list1.add(-2);
list.add(-2);
list.add(9);
list.add(-3);
System.out.println(Collections.max(list));//最大值
Collections.fill(list, 0); //使用0 填充所有元素
Collections.replaceAll(list, 0, 1); //替换所有的0为1
Collections.sort(list); //排序
System.out.println(Collections.binarySearch(list, 1)); //二分查找,返回索引
// System.out.println(Collections.indexOfSubList(list, list1)); //返回list1在list中第一次出现的位置
}
}3>同步控制:
Collections提供了多个synchronizedXXX方法,将制定集合包装成线程安全的集合
Collection c = Collections.synchronizedCollection(new ArrayList());
List list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
Map map = Collections.synchronizedMap(new HashMap());4>设置不可变集合(略)
集合是java只是体系中非常重要的一部分,更是面试官最爱问的部分,所以我花了很长的时间详细的整理关于集合的知识,希望能起到巩固知识的目的。