Java泛型、集合、IO
泛型
泛型语法机制,只是在程序编译阶段起作用,只是给编译器参考的。(运行阶段泛型没用)。
泛型的好处:
a.集合中存储的元素类型统一了。
b.从集合中取出的元素类型是泛型指定的类型,不需要进行大量的"向下转型"!
泛型的缺点:
导致集合中存储的元素缺乏多样性!
大多数业务中,集合中元素的类型还是统一的。
JDK5.0新特性
注意:
在使用含有泛型的类,接口,方法时,需要确定该数据类型,如果不确定,JVM自动帮其确定为Object类型
创建集合对象时需要确定泛型的格式:
JDK5.0格式:
集合类名<元素的数据类型> 集合对象名 = new 集合类名<元素的数据类型>();
注意:
前后<>中元素的数据类型必须一致
JDK8.0格式:(自动类型推断,钻石表达式)
集合类名<元素的数据类型> 集合对象名 = new 集合类名<>();
自定义泛型
自定义泛型的时候,<> 尖括号中的使用个标识符,随便写
java源代码中经常出现的是:
E是Element单词首字母
T是Type单词首字母
含有泛型的接口:
public interface 接口名<泛型类型> {}
确认的时机:
创建接口的实现类对象时
例如:
Collection
含有泛型的类
public class 类名<泛型类型> {
}
确认泛型类型时机:
创建该类的对象时
例如:
ArrayList
含有泛型的方法
修饰符 <泛型类型>返回值类型 方法名 () {}
确认泛型类型时机:
传递实参的时候进行确认
例如:
public
泛型的高级使用:
泛型的通配符:
如果含有泛型的方法的形参列表是含有该声明存储泛型的集合,可以用泛型的通配符进行简化
原格式:
public
简化后:
public void method (Collection coll) {}
泛型通配符的受限:
针对实参传递过来的集合中元素的数据类型进行限制
泛型通配符的上限
接收的集合元素类型必须是该类型本身或者及其子类类型
泛型通配符的下限
接收的集合元素类型必须是该类型本身或者及其父类类型
集合
集合概述
集合实际上就是一个容器。可以容纳其他类型的数据
数组其实就是一个集合
集合是一个容器,是一个载体,可以一次容纳多个对象
例如:
实际开发中,假设连接数据库,数据库当中有10条记录,那么假设吧这10条记录查询出来,在java程序中会将10条数据封装成10个java对象,然后将10个java对选哪个放到某一个集合当中,将集合传到前端,然后遍历集合,将一个数据一个数据展现出来
集合不能直接存储基本数据类型,另外集合也不能直接存储java对象
集合当中存储的都是java对象的内存地址(或者说集合当中存储的是引用)
list.add(100); // 自动装箱Integer
注意:
集合在java中本身是一个容器,是一个对象
集合中任何时候存储的都是"引用"
在java中每一个不同的集合,底层会对应不同的数据结构,往不同的集合中存储元素,等于将数据放到了不同的数据结构当中。
不同的数据结构,数据存储的方式不同
数组、二叉树、链表、哈希表...
所有的集合类和集合接口都在java.util包下
java集合中集合分为两大类
一类是单个方式存储元素:
单个方式存储元素,这一类集合中超级父接口:java.util.Collection
一类是以键值对儿的方式存储元素
以键值对的方式存储元素,这一类集合中超级父接口:java.util.Map
Collection:
1.Iterable:可迭代的,可遍历的,所有集合元素都是可迭代的,可遍历的。
2.Iterator:集合的迭代器对象
3.List集合存储元素特点:有序可重复,存储元素有下标(有序是存进去顺序,取出来还是这个顺序)
4.Set集合存储元素特点:无序不可重复的(无序表示存进去是这个顺序,取出来就不一定是这个顺序了。set集合中元素没有下标。set集合元素不能重复)
5.ArrayList集合底层采用了数组数据结构(非线程安全)
6.LinkedList集合底层采用了双向链表数据结构
7.Vector集合底层采用了数组结构(线程安全,效率较低,使用较少)
8.HashSet集合底层实际上new了一个HashMap集合,向HashSet集合中存储元素,实际上存储到了HashMap集合中了
a.HashSet中元素等同于放到HashMap集合Key部分
9.SortedSet集合存储元素无序不可重复,但是放在SortedSet集合中的元素可以自动排序
10.TreeSet集合底层实际上new了一个TreeMap集合,向HashSet集合中存储元素,实际上存储到了TreeMap集合中了
a.TreeSet中元素等同于放到TreeMap集合Key部分
Iterable(接口)--继承-->Collection(接口)
Collection(接口)--继承-->List(接口)
Collection(接口)--继承-->Set(接口)
常用集合:
List(接口)--实现-->ArrayList(类)
List(接口)--实现-->LinkedList(类)
List(接口)--实现-->Vector(类)
Set(接口)--实现-->HashSet(类)
Set(接口)--继承-->SortedSet(接口)--实现-->TreeSet(类)
Map:
1.Map集合和Collection集合没有关系,Map集合以Key和Value这种键值对存储元素。
a.Key和Value都是存储java对象的内存地址。
b.所有Map集合key是无序不可重复的
c.Map集合的key存储和Set集合存储元素特点相同
2.HashMap集合底层是哈希表数据结构,是非线程安全的
3.HashTable集合底层是哈希表数据结构,是线程安全的,其中所有的方法都带有synchronized关键字,效率较低,使用较少。因为控制线程安全有其他更好的方案。
4.SortedMap集合的Key是无序不可重复的,放在SortedMap集合key部分的元素和自动按照大小顺序排序,称为可排序集合
5.TreeMap集合底层的数据结构是一个二叉树,key自动按照大小排序
6.Properties被称为属性类,是线程安全的,存储元素的时候也是采用Key和Value的形式存储,并且Key和Value只支持String类型,不支持其它类型
常用集合
Map(接口)--实现-->HashMap(类)
Map(接口)--实现-->HashTable(类)
Map(接口)--实现-->SortedMap(接口)
SortedMap(接口)--实现-->TreeMap(类)
HashTable(类)--继承-->Properties(类)
List集合存储元素的特点
a.有序可重复
b.有序:存进去的顺序和取出的顺序相同,每一个元素都有下标
c.存进去1,可以再存进一个1
Set(Map)集合存储元素的特点
a.无序不可重复
b.无序:存进去的顺序和取出的顺序不一定相同,Set集合元素没有下标
c.存进去1,不可以再存进一个1
SortedSet(SortMap)集合存储元素的特点
a.无序不可重复,但是SortedSet集合中的元素是可排序的
b.无序:存进去的顺序和取出的顺序不一定相同,Set集合元素没有下标
c.存进去1,不可以再存进一个1
d.可排序,可以按照大小顺序排列
Map集合的Key就是一个Set集合
往Set集合中放数据,实际上放到Map集合的Key部分

import java.util.ArrayList;
import java.util.Collection;
/*
1.Collection中能存放什么元素
没有使用"泛型"之前,Collection中可以存储Object的所有子类型
使用了"泛型"之后,Collection中只能存储某个具体的类型。
集合中不能直接存储基本数据类型,也不能存储java对象,只是存储java对象的内存地址
2.Collection中常用方法
boolean add(Object e) 向集合中添加元素
int size() 返回此集合中的元素的数目
void clear() 清空集合
boolean contains(Object o) 判断集合中是否包含元素
boolean remove(Object o) 删除集合中一个元素
boolean isEmpty() 判断集合中是否为空
Object[] toArray() 返回包含此集合中所有元素的数组
*/
public class CollectionTest01 {
public static void main(String[] args) {
// 创建一个集合对象
Collection c = new ArrayList();
// 向集合中添加元素
c.add(1); // 自动装箱,实际上放进去一个对象内存地址。
c.add(3.14); // 自动装箱
c.add(true);// 自动装箱
c.add("hello");
c.add(new Student());
// 获取集合中元素个数
int num = c.size();
System.out.println(num); // 5
// 判断集合是否包含元素
System.out.println(c.contains("hello")); // true
System.out.println(c.contains(2)); // false
// 将集合转换成数组
Object[] o = c.toArray();
// 删除集合中一个元素
c.remove(1);
// 判断集合中是否存在元素
System.out.println(c.isEmpty()); // false
// 清空集合
c.clear();
System.out.println(c.size()); // 0
System.out.println(c.isEmpty()); // true
}
}
class Student {
}import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
/*
集合的遍历/迭代专题
所有Collection通用的一种方式,只有在Collection以及子类中使用
Iterator对象方法
boolean hasNext() 如果仍有元素可以跌代,返回true
Object next() 返回跌代的下一个元素
*/
public class CollectionTest02 {
public static void main(String[] args) {
Collection c = new HashSet();
// 添加元素
c.add(11);
c.add("abd");
c.add("hello");
c.add(new Object());
c.add(true);
// 对集合进行遍历/迭代
// 第一步:获取集合对象的迭代器对象Iterator
Iterator it = c.iterator();
// 第二步:通过以上获取的迭代器对象开始迭代/遍历集合
while (it.hasNext()) {
Object next = it.next();
System.out.println(next);
}
}
}
import java.util.ArrayList;
import java.util.Collection;
/*
contains 方法底层调用了equals方法
存放在集合中的类型 一定要重写equals方法
*/
public class CollectionTest03 {
public static void main(String[] args) {
Collection c = new ArrayList();
// 向集合中存储元素
String s1 = new String("abc");
c.add(s1);
String s2 = new String("def");
c.add(s2);
String x = new String("abc");
System.out.println(x.equals(s1)); // true
// contains 底层实际上调用的还是equals x.equals(s1)
System.out.println(c.contains(x)); // true
User u1 = new User("Tom", 111);
User u2 = new User("Tom", 111);
c.add(u1);
System.out.println(c.contains(u2)); // true
}
}
class User{
String name;
int id;
public User() {
}
public User(String name, int id) {
this.name = name;
this.id = id;
}
@Override
public boolean equals(Object o) {
if (o == null || !(o instanceof User)) return false;
if (this == o) return true;
User u = (User)o;
if (this.name.equals(u.name) && this.id == u.id) return true;
return false;
}
}

import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
迭代器遍历集合时候
删除集合中的元素用迭代器remove方法
*/
public class CollectionTest04 {
public static void main(String[] args) {
Collection c = new ArrayList();
// 注意:此时获取的迭代器,指向的是那个集合中没有元素
// 集合结构只要发生改变,迭代器必须重新获取
// 当集合结构发生了改变,迭代器没有重新获取时,调用next()方法时:java.util.ConcurrentModificationException
Iterator it = c.iterator();
// 添加元素
c.add(1);
c.add(2);
c.add(3);
while(it.hasNext()) {
Object next = it.next();
// 删除元素
// 删除元素之后,集合的结构发生率变化,应该重新去获取迭代器
// 但是,循环下一次的时候并没有重新获取迭代器,所以会出现异常。
// 出异常根本原因:集合中元素删除了,但是没有更新迭代器
//c.remove(next);
// 使用迭代器来删除
// 迭代器去删除时,会自动更新迭代器,并且更新集合
it.remove(); // 删除的一定是迭代器指向的当前元素
System.out.println(next);
}
}
}ArrayList
a.集合默认初始化容量是10(底层先创建了一个长度为0的数组,当添加第一个元素的时候,初始化容量10)
b.集合底层是一个Object类型的数组,可以指定初始化长度
List list = new ArrayList(20);
// 获取的是集合元素的个数
System.out.println(list.size()); // 0
c.ArrayList集合扩容是原容量的1.5倍。
d.ArrayList集合底层是数组,尽可能少的扩容。因为数组扩容的效率比较低,建议在使用ArrayList集合的时候预估元素的个数,给定一个初始化容量。
e.ArrayList集合平时用的比较多,因为往数组添加元素,效率不受影响。另外我们检索/查找某个元素操作比较多
数组优点:检索效率比较高
数组缺点:随机增增删元素效率比较低,另外数组无法存储大数据量(非常难找到很大的连续内幕才能空间)
向数组末尾添加元素,效率很高,不受影响
import java.util.ArrayList;
import java.util.Iterator;
/*
计算机英语
增:add、save、new
删:delete、drop、remove
改:update、set、modify
查:find、get、query、select
*/
/*
测试List接口常用方法
1.List集合存储元素特点:有序可重复
有序:List集合中的元素有下标
从0开始,以1递增
可重复:存储一个1,还可以再存储1
2.List集合的特色方法
void add(int index, E element)
E get(int index)
int indexOf(Object o)
int lastIndexOf(Object o)
Object remove(int index)
Object set(int index, E element)
*/
public class ListTest01 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
// add(E e) 向列表的尾部添加指定元素
list.add("a");
list.add("b");
list.add("c");
list.add("d");
// add(int index, E element) 向列表的指定位置插入指定元素
list.add(1,"king");
// 迭代
Iterator it = list.iterator();
while (it.hasNext()) {
Object next = it.next();
System.out.println(next);
} // a king b c d
Object o = list.get(0);
System.out.println(o); // a
// 因为有下标,所以list集合有自己比较特殊的遍历方式
// list集合特有 set没有
for (int i = 0; i < list.size(); i++) {
Object obj = list.get(i);
System.out.println(obj);
}
// 获取对象第一次出现处的索引
System.out.println(list.indexOf("king")); // 1
// 获取指定对象最后一次出现处的索引
System.out.println(list.lastIndexOf("c")); // 3
// 删除指定下标位置的元素
list.remove(1);
// 修改指定位置的元素
list.set(0,"A");
}
}
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
/*
ArrayList的构造方法
*/
public class ArrayListTest02 {
public static void main(String[] args) {
// 初始化一个默认的list数组
ArrayList list = new ArrayList();
// 自定义容量的list数组
ArrayList list2 = new ArrayList(100);
// 创建一个HashSet集合
Collection c = new HashSet();
// 添加元素到set集合
c.add(100);
c.add(200);
c.add(11);
// 通过构造方法将HashSet集合转换成list集合
ArrayList list3 = new ArrayList(c);
}
}单链表
节点是单向链表中基本的单元。
每一个节点Node都有两个属性:
一个属性:是存储的数据
另一个属性:是下一个节点的内存地址。
链表的优点:
随机增删元素效率较高。(因为增删元素不涉及到大量元素位移)
由于链表上的元素在空间存储上内存地址不连续。
所以随机增删元素的时候不会有大量元素位移,因此随机增删效率较高。
在以后开发中,如果遇到随机增删集合中元素的业务比较多时。建议使用LinkedList
链表的缺点:
查询效率较低,每一次查找某个元素的时候都要从头结点开始往下遍历
不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头结点开始遍历,知道找到为止。所以LinkedList集合检索/查找的效率比较低。

双向链表
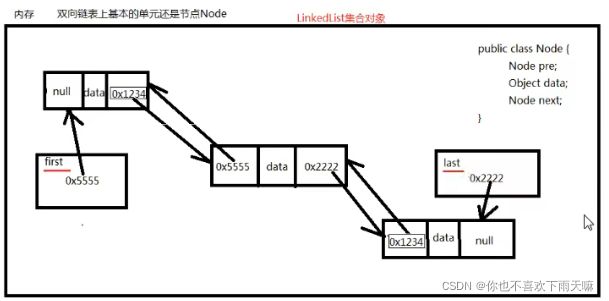
LinkedList
LinkedList集合没有初始化容量,底层采用双向链表数据结构
最初这个链表中没有任何元素。first和last引用都是null。
不管是LinkedList还是ArrayList,后携带码时不需要关心具体是哪个集合。
因为面向接口编程,调用的都是接口中的方法
链表中的元素在空间存储上,内存地址不连续。
List list1 = new ArrayList(); // 这样写表示底层用了数组
List list2 = new LinkedList(); // 这样写表示底层用了双向链表
// 以下这些方法面向的都是接口编程
list2.add("123");
list2.add("456");
list2.add("789");
for(int i = 0; i < list2.size(); i++) {
System.out.println(list2.get(i));
}ArrayList:把检索发挥到极致。
LinkedList:把随机增删发挥到极致。
加元素都是往末尾添加,所以ArrayList用的比LinkedList多
/*
模拟单链表的结点
*/
public Node {
// 存储数据
Object element;
// 下一个节点的内存地址
Node next;
public Node() {
}
public Node(Object element, Node next) {
this.element = element;
this.next = next;
}
}
/*
模拟链表
*/
public class link {
// 头结点
Node header = null;
// 向链表末尾中添加元素的方法
public void add(Object date) {
// 创建一个新的节点对象
// 让之前单链表的末尾结点next指向新结点对象
// 有可能这个元素是第一个,也可能是第二个,也可能是第三个
if(header == null) {
// 说明还没有结点
// new 一个新的结点对象,作为头结点
} else {
// 说明头不是空!
// 头结点已经存在了!
// 找出当前末尾结点,让当前某尾结点的next是新结点
Node currentLastNode = findLast(header);
currentLastNode.next = new Node(data, null);
}
}
public void remove(Object obj) {
}
// 修改链表中某个数据方法
public void modify(object newObj) {
}
// 查找链表中某个元素
public int find(Object obj) {
return 1;
}
private Node findLast(Node node) {
if(node.next == null) {
// 如果一个结点的next是null;
// 说明这个结点就是某尾节点
return node;
}
// 程序能运行到这里说明:node不是末尾节点
return findlast(node.next);
}
}
Vector
底层也是一个数组
初始化容量:10
满了之后扩容为原容量的2倍
Vector中所有的方法都是线程同步的,都代用synchronized关键字,是线程安全的。
因为效率比较低,所以使用的较少
import java.util.*;
public class VectorTest {
public static void main(String[] args) {
// 创建一个Vector集合
Vector vector = new Vector();
// 添加元素
vector.add(1);
vector.add(2);
vector.add(3);
vector.add(4);
Iterator it = vector.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
// 这个可能以后要使用
List list = new ArrayList();
// 变成线程安全的
Collections.synchronizedList(list);
list.add("111");
list.add("222");
list.add("333");
list.add("444");
}
}foreach
JDK5.0之后推出了一个新特性:叫做增强for循环,或者叫做foreach
foreach有个缺点是:没有下标
for(元素类型 变量名 : 数组或集合){
System.out.println(变量名);
}
int[] arr = {344, 44, 22, 11, 333};
// 增强for遍历数组
for(int data : arr){
// data代表的是数组中的每个元素
System.out.println(data);
}
List list = new ArrayList<>()
list.add("a");
list.add("b");
list.add("c");
list.add("d");
for(String s : list) {
System.out.println(s);
}
import java.util.HashSet;
import java.util.Set;
/*
HashSet集合
*/
public class HashSetTest01 {
public static void main(String[] args) {
Set hashSet = new HashSet<>();
hashSet.add("hello01");
hashSet.add("hello02");
hashSet.add("hello03");
hashSet.add("hello04");
hashSet.add("hello05");
hashSet.add("hello06");
// 存储时顺序和取出的顺序不同
// 不可重复
// 放到HashSet集合中的元素实际上是放到HashMap集合的Key部分了
for (String s : hashSet) {
System.out.println(s);
}
}
}
import java.util.TreeSet;
/*
TreeSet集合
*/
public class TreeSetTest01 {
public static void main(String[] args) {
// 创建集合对象
TreeSet str = new TreeSet<>();
// 添加元素
str.add("a");
str.add("e");
str.add("h");
str.add("b");
str.add("d");
// 遍历
for (String s : str) {
// TreeSet集合自动排序
System.out.print(s); // abdeh
}
}
} Map
java.util.Map接口中常用的方法:
1.Map和Collection没有继承关系。
2.Map集合以Key和Value的方式存储数据:键值对
Key和Value都是引用数据类型。
Key和Value都是存储对象的内存地址。
Key起到主导的地位,Value是Key的一个附属品。
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/*
Map接口的常用方法:
void clear() 清空Map集合
boolean containsKey(Object key) 判断Map中是否包含某个key
boolean containsValue(Object value) 判断Map中是否包含某个value
V get(Object key) 通过key获取value
boolean isEmpty() 判断Map集合中元素个数是否为0
Set keySet() 获取Map集合所有的Key(所有的键是一个set集合)
V put(K key, V value) 向Map集合中添加键值对
V remove(Object key) 通过Key删除 对应的键值对
int size() 获取Map集合中键值对的个数
Collection values() 获取Map集合中所有的value,返回一个Collection
Set> entrySet() 将Map集合转换成Set集合
将Map集合转换成Set集合
假设有如下集合map
key value
----------------
1 zhangsan
2 lisi
3 wangwu
4 zhaoliu
Set set = map.entrySet();
set集合对象
1=zhangsan
2=lisi
3=wangwu
4=zhaoliu
[注意:Map集合通过entrySet()方法转换成的这个Set集合,Set集合中元素的类型是Map.Entry]
Map.Entry是静态内部类,是Map中的静态内部类
*/
public class MapTest01 {
public static void main(String[] args) {
// 创建Map集合对象
Map map = new HashMap();
// 向Map集合中添加键值对
map.put(1,"zhangshan"); // 自动装箱
map.put(2,"lisi");
map.put(3,"wangwu");
map.put(4,"zhaoliu");
// 通过key获取value
String value = map.get(2);
System.out.println(value);
// 通过key删除key-value
map.remove(1);
// 遍历Map集合
// 第一种方式
// 获取所有的key,通过key获取value
// 获取所有的key,所有的key是一个set集合
Set keys = map.keySet();
// 遍历所有key,通过key获取value
Iterator it = keys.iterator();
while (it.hasNext()) {
Integer key = it.next();
String s = map.get(key);
System.out.println(s);
}
// 使用增强for
for (Integer key : keys) {
System.out.println(map.get(key));
}
// 第二种方式:Set> entrySet()
// 把Map集合直接全部转化成Set集合
// Set集合中元素类型是:Map.Entry
Set> entries = map.entrySet();
// 遍历Set集合,每次取出一个Node
Iterator> iterator = entries.iterator();
while (iterator.hasNext()) {
Map.Entry entry = iterator.next();
Integer key = entry.getKey();
String value1 = entry.getValue();
System.out.println(key + "=" + value1);
}
// 增强for
// 这种方式效率比较高,因为获取key和value都是直接从node对象中获取的属性值
// 这种方式比较适合大数据量
for (Map.Entry node : entries) {
System.out.println(node.getKey() + "=" + node.getValue());
}
}
} 
HashMap集合
HashMap集合底层哈希表/散列表的数据结构
哈希表是一个怎样的数据结构
哈希表是一个数组和单向链表的结合体
数组:在插叙方面效率很高,随机增删方面效率很低
单向链表:在随机增删方面效率较高,在插叙方面效率很低
哈希表将以上两种数据结构融合在一起,充分发挥他们各自的优点
哈希表/散列表:以为数组,这个数组中给每一个元素是一个单向链表。(数组和链表的结合体)
HashMap集合底层实际上就是一个一维数组
Node
// 静态内部类HashMap.Node
static class Node implements Entry {
final int hash; // 哈希值
final K key; // 存储到Map集合中的key
V value; // 存储到Map集合的value
HashMap.Node next; // 下一个节点的内存地址
} 哈希值(哈希值是key的hashCode()方法执行结构。H哈希值通过哈希函数/算法,可以转换存储成数组的下标。)
主要掌握
map.put(key,value)和map.get(key)的原理
HashMap集合的key部分特点
无序,不可重复
以为不一定放在了哪个单向链表上
equals方法来保证HashMap集合key不可重复
如果key重复value会覆盖
HashMap可以允许使用 null 值和 null 键,key的null值只能有一个
放在HashMap集合key部分的元素其实就是放到HashSet集合中
使用HashSet集合中的元素也需要同重写hashCode()+equals()方法
哈希表HashMap使用不当时无法发挥性能
假设将所有hashCode()方法返回值固定为某个值,那么会导致底层哈希表变成了纯单向链表。这种情况我们称为:散列分布不均匀
假设将所有的hashCode()方法返回值都设定为不一样的值,这样就会导致底层哈希表就成为了以为数组,没有链表的概念了。也是散列分布不均匀
散列分布均匀需要重写hashCode()方法时有一定的技巧
放在HashMap集合key部分的元素,以及放在HashSet集合中的元素,需要同时重写hashCode和equals方法
HashMap集合的默认初始化容量是16,默认加载因子是0.75
默认加载因子:当HashMap集合底层数组容量达到75%,数组开始自动扩容
HashMap集合的默认初始化容量必须是2的倍数,这也是官方推荐的,
这是因为达到散列均匀,为了提高HashMap集合的存储效率,所必须的
向Map集合中存,以及Map集合中取,都是先调用key的hashCode方法,然后再调用equals方法
equals方法有可能调用,也有可能不调用。
拿put(K,V)举例,什么时候equals不调用
k.hashCode()方法返回哈希值
哈希值经过哈希算法转换成数组下标。
素组小标位置上如果是null,equals不会调用
注意:
如果一个类的equals方法重写了,那么hashCode()方法必须重写。
并且equals方法返回如果是true,hashCode()方法返回的值必须一样。
equals方法返回true表示两个对象相同,在同一个单向链表上比较。
那么对于同一个单向链表上的结点来说,他们的哈希值都是相同的
使用hashCode()方法返回值也应该相同。
可以用idea使用ALT+Insert生成
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class HashMapTest {
public static void main(String[] args) {
// Integer是key,它的hashCode()和equals都重写了
HashMap hashMap = new HashMap<>();
hashMap.put(1111,"zhangsan");
hashMap.put(2222,"lisi");
hashMap.put(4444,"wangwu");
hashMap.put(4444,"xiaoming");
hashMap.put(null,null);
System.out.println(hashMap.size());
// 遍历集合
Set> entries = hashMap.entrySet();
for (Map.Entry entry : entries) {
System.out.println(entry.getValue());
}
}
}
Hashtable
Hashtable的key和value都不能为null
HashMap集合的key和value都是可以为null的
Hashtable方法都带有synchronized:线程安全的。
线程安全有其它的方案,这个Hashtable对线程的处理导致效率较低,使用较少了
HashTable底层是哈希表数据结构
HashTable的初始化容量是11,默认加载因子是:0.75f
HashTable扩容是:原容量的2倍再加1
Properties
Properties是一个Map集合继承Hashtable,Properties的key和value都是String类型
import java.util.Properties;
public class PropertiesTest {
public static void main(String[] args) {
Properties pro = new Properties();
// 存
pro.setProperty("url","https://www.bilibili.com");
pro.setProperty("username","root");
pro.setProperty("password","123456");
// 取
String url = pro.getProperty("url");
String name = pro.getProperty("username");
String password = pro.getProperty("password");
}
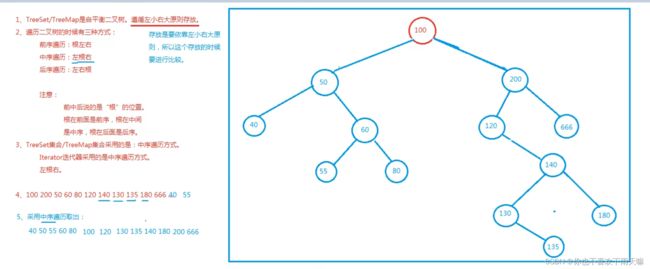
}TreeSet和TreeMap
1.TreeSet集合底层实际上是一个TreeMap
2.TreeMap集合底层是一个二叉树
3.放到TreeSet集合中的元素,等同与放到TreeMap集合key部分了
4.TreeSet集合中的元素:无序不可重复,但是可以按照元素的大小顺序自动排序。称为:可排序集合
TreeSet集合元素可排序的两种方式
1.放在集合中的元素实现java.lang.Comparable接口
2.在构造TreeSet或者TreeMap集合的时候给它传入一个比较器对象
Comparable和Comparator怎么选择
当比较规则不会发生改变的时候,或者说当比较规则只有1个的时候,建议实现Comparable接口
如果比较规则有多个,并且需要多个比较规则之间频繁切换,建议使用Comparator接口
Comparator接口的设计符合OCP原则
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet ts = new TreeSet<>();
// 添加String
ts.add("e");
ts.add("z");
ts.add("f");
ts.add("a");
ts.add("c");
// 遍历集合
for (String e : ts) {
System.out.print(e); // acefz
}
Customer c1 = new Customer(88);
Customer c2 = new Customer(22);
Customer c3 = new Customer(99);
Customer c4 = new Customer(11);
// 创建TreeSet集合
TreeSet customers = new TreeSet<>();
// 添加元素
customers.add(c1);
customers.add(c2);
customers.add(c3);
customers.add(c4);
// 要想实现自定义类型自动排序
// 自定义类型需要实现Comparable接口重写compareTo方法
for (Customer e : customers) {
System.out.println(e);
}
}
}
/*
重写比较方法
需要实现Comparable接口
重写compareTo方法
*/
class Customer implements Comparable{
int age;
String name;
public Customer(int age) {
this.age = age;
}
@Override
// 在这个方法中编写比较的逻辑
// 比较规则按照年龄升序
public int compareTo(Customer c) {
/*
if(this.age > c.age) {
return 1;
} else if(this.age < c.age) {
return -1;
} else {
return 0;
}
*/
return this.age - c.age;
}
@Override
public String toString() {
return "Customer[age" + age + "]";
}
}
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetTest02 {
public static void main(String[] args) {
// 创建TreeSet集合时候 用构造方法将比较器传入
TreeSet wuGuis = new TreeSet<>(new WuGuiComparator());
wuGuis.add(new WuGui(1111111));
wuGuis.add(new WuGui(22));
wuGuis.add(new WuGui(333));
wuGuis.add(new WuGui(7777));
wuGuis.add(new WuGui(1));
for (WuGui gui : wuGuis) {
System.out.println(gui);
}
}
}
class WuGui {
int age;
public WuGui(int age) {
this.age = age;
}
@Override
public String toString() {
return "小乌龟[" +
"age" + age +
"]";
}
}
// 单独在这里编写一个比较器
// 比较器实现java.util.Comparator接口。(Comparable是java.lang包下的。Comparator是java.util下D)
class WuGuiComparator implements Comparator {
@Override
public int compare(WuGui w1, WuGui w2) {
// 指定比较规则
// 按照年龄排序
return w1.age - w2.age;
}
} 
import java.util.ArrayList;
import java.util.Collections;
/*
集合工具类 Collections
java.util.Collection接口
java.util.Collections集合工具类
*/
public class CollectionsTest {
public static void main(String[] args) {
// ArrayList集合是线程不安全的
ArrayList str = new ArrayList<>();
// 使用集合工具类编程线程安全的
Collections.synchronizedList(str);
// 排序 必须是list集合 需要保证集合中的元素实现了:Comparable接口
// Collections.sort(list集合, 比较器对象);
Collections.sort(str);
}
} IO流
I:input
O:Output
通过IO可以完成磁盘文件的读和写
IO流分类
一种方式是按照方向进行分类
以内存作为参照物
往内存去,叫做输入(Input)。或者叫做读。
从内存出来,叫做输出(Output)。或者叫做写
另一种方式按照读取数据方式不同进行分类
有的留是按照字节的方式读取数据,一次读取1个byte,等同于一次读取8个二进制位。
这种流是万能的,什么类型的文件都可以读取,包括图片、声音、视频等文件
有的留是按照字符的方式读取数据,一次读取一个字符,这种流是为了方便读取普通文本文件而存在的。
这种留不能读取:图片、声音、视频等文件。只能读取纯文本文件,连word文件都无法读取
a中国bc张三zz
'a'字符在window系统中占用一个字节
'中'字符在window系统中占用两个字节
char在java中是2个字节,'a'字符在java中占用2个字节
综上所述:流的分类
输入流、输出流
字节流、字符流
java IO流4大类
java.io.InputStream 字节输入流
java.io.OutputStream 字节输出流
java.io.Reader 字符输入流
java.io.Write 字符输出流
以Stream结尾的都是字节流
以Reader/Writer结尾的都是字符流
所有流都实现了
java.io.AutoCloseable接口,都是可关闭的,都有close()方法
流毕竟是一个管道,这个是内存和硬盘之间的通道,用完之后一定要关闭,不然会耗费(Z占用)很多资源
所有的输出流都实现了
java.io.Flushable接口,都是可刷新的,都有flush()方法
养成好习惯,输出流在最终输出之后,一定要flush(),这个刷新表示将通道/管道中剩余未输出的数据强行输出完(清空管道!),刷新作用就是清空管道
java.io包下需要掌握的流有16个
文件专属流
java.io.FileInputStream
java.io.FileOutputStream
java.io.FileReader
java.io.FileWriter
转换流(将字节流转换成字符流)
java.io.InputStreamReader
java.io.OutputStreamWriter
缓冲流
java.io.BufferedReader
java.io.BufferedWriter
java.io.BufferedInputStream
java.io.BufferedOutputStream
数据流
java.io.DataInputStream
java.io.DataOutputStream
对象流
java.io.ObjectInputStream
java.io.ObjectOutputStream
标准输出流
java.io.PrintWriter
java.io.PrintStream

/*
read()
一次读取一个字节,内存和硬盘交互太频繁,基本上时间/资源都耗费在交互方面
*/
FileInputStream fs = null;
// 创建文件字节流输入对象
// 以下采用的是绝对路径
// 文件路径D:\input\aaaa\bbb.txt 单个 / 表示转义 idea自动将\转换成\\
// 也可以写成 D:/input/aaaa/bbb.txt
try {
fs = new FileInputStream("D:\\input\\aaaa\\bbb.txt");
// 读取文件第一个字节为 a
int read = fs.read();
System.out.println(read);// 97
// 读取剩余所有内容
int readDate =0;
while((readDate = fs.read()) != -1) {
System.out.println(readDate);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流的前提不是空
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}/*
read(byte[] b)
一次最读读取b.length个字节,减少磁盘和内存的交互
*/
FileInputStream fs = null;
// 创建文件字节流输入对象
// 相对路径一定是从当前所在的位置作为七点开始找
// IDEA默认的当前路径是当前project根
try {
fs = new FileInputStream("day03/cccc");
// 一次读取一个byte数组
// 准备一个4个长度的byte数组,一次最多读取4个字节
byte[] bytes = new byte[4];
// 此方法的返回值是方法读取的字节数量
int readCount = fs.read(bytes);
System.out.println(readCount);
// 读取剩余的数据
int readNum = 0;
while ((readNum = fs.read(bytes)) != -1) {
// 通过String的构造器将bytes数组中的字节 转换成字符串
// 读取多少转换多少个字节
System.out.println(new String(bytes,0,readNum));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流的前提不是空
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}/*
FileInputStream常用方法
int available() 返回流当中剩余的没有读到的字节数量
*/
FileInputStream fs = null;
// 创建文件字节流输入对象
// 相对路径一定是从当前所在的位置作为七点开始找
// IDEA默认的当前路径是当前project根
try {
fs = new FileInputStream("day03/cccc");
System.out.println("总字节数量" + fs.available());
// 一次读取一个字节
int read = fs.read();
// 还剩下多少个字节没有读
int available = fs.available();
System.out.println("剩余字节数量" + available);
// 这个方法有什么用
byte[] bytes = new byte[fs.available()];
// 不需要循环了,直接读一次就行了。不适合太大的文件,byte数组不能太大
int readCount = fs.read(bytes);
System.out.println(new String(bytes));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流的前提不是空
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/*
long skip(long n) 跳过几个字节不读
*/
FileInputStream fs = null;
// 创建文件字节流输入对象
// 相对路径一定是从当前所在的位置作为七点开始找
// IDEA默认的当前路径是当前project根
try {
fs = new FileInputStream("day03/cccc");
// 一次读取一个字节
int read = fs.read();
// 跳过3个字节
fs.skip(3);
int read2 = fs.read();
System.out.println(read2);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流的前提不是空
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
FileOutputStream fo = null;
try {
// 这种方式谨慎使用,这种方式会将原文件清空,然后重新写入。
fo = new FileOutputStream("day03/myfile");
//下面这种方式会追加写,不会清空原文件
//fo = new FileOutputStream("day03/myfile",true);
// 开始写
byte[] bytes = {97, 98, 99, 100, 101};
// 将byte数组全部写出
fo.write(bytes);
// 将byte数组一部分写出
fo.write(bytes,0,2);
// 写一个字符串
String s = "刚好让你更好";
byte[] bytes1 = s.getBytes();
fo.write(bytes1);
// 写完之后一定要刷新
fo.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fo != null) {
fo.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/*
文件拷贝
FileInputStream + FileOutputStream
拷贝的过程应该是一边读,一边写
使用字节流拷贝文件,文件类型随意
*/
public class FileCopy {
public static void main(String[] args) {
FileInputStream fs = null;
FileOutputStream fo = null;
try {
// 创建一个输入流对象
fs = new FileInputStream("D:\\input\\aaaa\\bbb");
// 创建一个输出流对象
fo = new FileOutputStream("D:\\input\\cccc\\bbb");
// 准备一个byte数组 1M 一次最多拷贝1M
byte[] bytes = new byte[1024 * 1024];
int readCount = 0;
while ((readCount = fs.read(bytes)) != -1) {
fo.write(bytes);
}
fo.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 一起try可能会影响到另一个的关闭
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fo != null) {
try {
fo.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
/*
文件字符输入流
*/
FileReader fr = null;
try {
// 创建文件字符输入流
fr = new FileReader("D:\\input\\aaaa\\bbb");
// 开始读
char[] chars = new char[4];
int readCount = 0;
while ((readCount = fr.read(chars)) != -1) {
String s = new String(chars, 0, readCount);
System.out.println(s);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fr != null) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/*
文件字符输出流
*/
FileWriter fw = null;
try {
fw = new FileWriter("day03/dddd");
// 下面为追加写
// fw = new FileWriter("day03/dddd",true);
// 开始写
char[] c = {'a', 'b', '我', '最', '大'};
fw.write(c);
fw.write(c,1,5);
// 刷新
fw.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fw != null) {
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}import java.io.BufferedReader;
import java.io.FileReader;
/*
BufferedReader
带有缓冲区的字符输入流
使用这个流的时候不需要自定义char数组,或者说不需要自定义byte数组。自带缓冲
*/
public class BufferedReaderTest01 {
public static void main(String[] args) throws Exception {
FileReader fr = new FileReader("fileCopy");
// 当一个流的构造方法中需要一个流的时候,这个被传进来的流叫做:节点流
// 外部负责包装这个流,叫做:包装流,还有一个名字叫做:处理流
// 像当前这个程序来说:FileReader就是一个节点流。BufferedReader叫做处理流
BufferedReader br = new BufferedReader(fr);
// 读一行
String s = br.readLine();
System.out.println(s);
// 读剩余
String str = null;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
// 其实关闭的是 节点流
fr.close();
}
}
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
public class BufferedReaderTest02 {
public static void main(String[] args) throws Exception {
// 字节流
FileInputStream fs = new FileInputStream("day03/bbb");
// 转换流 字节流转换成字符流
InputStreamReader isr = new InputStreamReader(fs);
// 缓冲流 不能传字符流利用转换流将字节流转换成字符流
BufferedReader br = new BufferedReader(isr);
String line = null;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
// 关闭最外层
br.close();
}
}
import java.io.DataOutputStream;
import java.io.FileOutputStream;
public class DataOutputStreamTest {
public static void main(String[] args) throws Exception {
// 创建数据专属的字节输出流
DataOutputStream ds = new DataOutputStream(new FileOutputStream("day03/dddd"));
// 写数据
byte b = 100;
short s = 200;
int i = 300;
long l = 400L;
float f = 3.0F;
double d = 3.14;
boolean bo = true;
char c = 'a';
ds.writeByte(b);
ds.writeShort(s);
ds.writeInt(i);
ds.writeFloat(f);
ds.writeDouble(d);
ds.writeLong(l);
ds.writeBoolean(bo);
ds.writeChar(c);
// 刷新
ds.flush();
ds.close();
}
}
import java.io.DataInputStream;
import java.io.FileInputStream;
/*
DataInputStream 数据字节输入流
DataOutputStream写的文件,只能使用DataInputStream去读。并且读的时候需要提前知道写的顺序
读的顺序需要和写的顺序一致才可以正常取出数据
*/
public class DataInputStreamTest {
public static void main(String[] args) throws Exception{
DataInputStream ds = new DataInputStream(new FileInputStream("day03/dddd"));
// 开始读
byte b = ds.readByte();
short s = ds.readShort();
int i = ds.readInt();
float f = ds.readFloat();
double d = ds.readDouble();
long l = ds.readLong();
Boolean bo = ds.readBoolean();
char c = ds.readChar();
ds.close();
}
}
import java.io.FileOutputStream;
import java.io.PrintStream;
/*
标准的字节输出流。默认输出到控制台
*/
public class PrintStreamTest {
public static void main(String[] args) throws Exception {
// 联合起来写
System.out.println("hello world");
// 分开写
PrintStream out = System.out;
out.println("hello world");
// 标准输出流不需要手动close()关闭
// 改变标准输出流的输出方向
System.gc();
System.currentTimeMillis();
// 标准输出流不在指向控制台,指向"log"文件
PrintStream printStream = new PrintStream(new FileOutputStream("day03/log"));
// 修改输出方向,将输出方向修改到"log"文件
System.setOut(printStream);
// 此时hello java hello hive输出到 log 文件
System.out.println("hello java");
System.out.println("hello hive");
}
}
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.text.SimpleDateFormat;
import java.util.Date;
/*
记录日志工具的方法
*/
public class Logger {
public static void log(String msg) {
try {
PrintStream out = new PrintStream(new FileOutputStream("log.txt"), true);
System.out.println(out);
Date nowTime = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String strTime = sdf.format(nowTime);
System.out.println(strTime + ":" + msg);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
File类
java.io.File
父类是Object,所以File类不能完成文件的读和写
File对象代表的是文件和目录路径名的抽象表示形式
D:\input\aaaa
D:\input\aaaa\bbbb.txt
一个File对象有可能对应的是目录,也可能是文件。
File只是一个路径名的抽象表现形式
import java.io.File;
import java.io.IOException;
public class FIleTest01 {
public static void main(String[] args) throws IOException {
// 创建一个File对象
File f1 = new File("D:\\input\\aaaa");
// 判断文件是否存在
System.out.println(f1.exists()); // true
File f2 = new File("D:\\input\\file");
// 如果f2不存在,则以文件的形式创建出来
if (!f2.exists()) {
f2.createNewFile();
}
// 如果f2不存在,则以目录的形式创建出来
if (!f2.exists()) {
f2.mkdir();
}
// 获取当前目录下所有子对象
File[] files = f2.listFiles();
File f3 = new File("D:\\input\\a\\b\\c\\d");
// 如果f3不存在,则以多重目录的形式创建出来
if (!f2.exists()) {
f2.mkdirs();
}
File f4 = new File("D:\\input\\aaa\\b.txt");
// 获取文件的父路径
f4.getParent(); // D:\input\aaa'
// 获取父目录对象
File parentFile = f4.getParentFile();
// 获取绝对路径
f4.getAbsolutePath();
// 获取文件名
String name = f4.getName();
// 判断是否是一个目录
boolean directory = f1.isDirectory();
// 判断是否是一个文件
boolean absolute = f1.isFile();
// 获取文件最后一次修改时间
long l = f4.lastModified(); // 这个毫秒是从1970年到现在的总毫秒数
}
}
import java.io.*;
/*
案例:拷贝目录
*/
public class CopyAllFile {
public static void main(String[] args) {
// 拷贝源
File srcFile = new File("D:\\JavaStudy\\note");
// 拷贝目标
File destFile = new File("E:\\");
copyDir(srcFile, destFile);
}
public static void copyDir(File srcFile, File destFile) {
if(srcFile.isFile()) {
// 是文件需要拷贝 一边读一边写
FileInputStream fis = null;
FileOutputStream fos = null;
try {
// 读这个文件
fis = new FileInputStream(srcFile);
String path = (destFile.getAbsolutePath().endsWith("\\") ? destFile.getAbsolutePath() : destFile.getAbsolutePath() + "\\") + srcFile.getAbsolutePath().substring(3);
// 写这个文件
fos = new FileOutputStream("");
// 一次复制1M
byte[] bytes = new byte[1024 * 1024];
int readCount = 0;
while ((readCount = fis.read(bytes)) != -1) {
fos.write(bytes,0,readCount);
}
// 刷新
fos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 如果srcFile是一个文件的话,递归结束
return;
}
// 获取源下面所有的子目录
File[] files = srcFile.listFiles();
for (File file : files) {
// 获取所有文件/目录绝对路径 --测试
// System.out.println(file.getAbsolutePath());
if (file.isDirectory()) {
// 如果file是目录 新建目录
// 获取file目录名
String srcDir = file.getAbsolutePath();
// 截取掉前3位
String substring = srcDir.substring(3);
// 转换成新的文件夹路径名
String destDir = (destFile.getAbsolutePath().endsWith("\\") ? destFile.getAbsolutePath() : destFile.getAbsolutePath() + "\\") + substring;
// 创建新文件夹
File newFile = new File(destDir);
if (!newFile.exists()) {
newFile.mkdir();
}
}
// 递归调用
copyDir(file,destFile);
}
}
}
对象流
java.io.ObjectInputStream
java.io.ObjectOutputStream
序列化
参与序列化的和反序列化的对象必须实现Serializable接口
注意:通过源代码发现,Serializable接口只是一个标志接口
public interface Serializable {
}
这个接口当中什么代码都没有。
起到标识的作用,标志作用,java虚拟机看到这个类实现了这个接口,会为该类自动生成一个序列化版本号
transient关键字,表示游离的,不参与序列化
序列化版本号有什么用?
java语言中是采用什么机制来区分类的
1.首先通过类名进行比对,如果类名不一样,肯定不是同一个类
2.如果类名一样,靠序列化版本号进行区分
A编写了一个类:com.thintime.java.bean.Student implements Serializable
B编写了一个类:com.thintime.java.bean.Student implements Serializable
不同的人编写了同一个类,但是“这两个类确实不是同一个类”
对于java虚拟机来说,java虚拟机是可以区分开这个两个类的,因为两个类实现了Serializable接口
都有默认的序列化版本号,他们的学历恶化版本号不一样。所以区分开了
自动生成的序列化版本号有什么缺陷?
一旦代码确定之后,不能进行后续的修改
如果修改代码重新编译,会自动生成新的序列化版本号,java虚拟机会认为这个应该全新的类
建议:
凡是应该类实现了Serializable接口,建议给该类提供一个固定不变的序列化版本号

import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class ObjectOutputStreamTest01 {
public static void main(String[] args) throws IOException {
Student xiaoming = new Student("xiaoming", 11, 123456);
// 序列化
// 如果存第二个对象对报错 多个对象放入集合
ObjectOutputStream student = new ObjectOutputStream(new FileOutputStream("student"));
ObjectOutputStream students = new ObjectOutputStream(new FileOutputStream("students"));
student.writeObject(xiaoming);
// 可以序列化多个对象,将对象放到集合当中,序列化集合
List list = new ArrayList<>();
Student xiaohong = new Student("xiaohong", 12, 123457);
Student xiaohua = new Student("xiaohua", 13, 123458);
Student xiaobei = new Student("xiaobei", 14, 123459);
list.add(xiaohong);
list.add(xiaohua);
list.add(xiaobei);
students.writeObject(students);
// 刷新
student.flush();
students.flush();
student.close();
students.close();
}
}
class Student implements Serializable {
// IDEA工具自动生成序列化版本号
private static final long serialVersionUID = 2207315488279457137L;
/*
java虚拟机看到Serializable接口之后,会自动生成一个序列化版本号。
这里没有手动写出来,java虚拟机会默认提供这个序列化版本号。
建议将序列化版本号手动的写出来不建议自动生成
private static final long serialVersionUID = 1L // java虚拟机识别
*/
String name;
// 如果不希望这个属性被序列化加上transient关键字
transient int age;
int id;
public Student() {
}
public Student(String name, int age, int id) {
this.name = name;
this.age = age;
this.id = id;
}
@Override
public String toString() {
return name + "=" + age + "=" + id;
}
}
import java.io.FileInputStream;
import java.io.ObjectInputStream;
import java.util.List;
public class ObjectInputStreamTest01 {
public static void main(String[] args) throws Exception {
ObjectInputStream student = new ObjectInputStream(new FileInputStream("student"));
// 开始反序列化
Object object = student.readObject();
// 反序列化回来是一个学生对象,所以会调用学生对象的toString方法
System.out.println(object);
ObjectInputStream students = new ObjectInputStream(new FileInputStream("students"));
List list = (List)student.readObject();
for (Student stu : list) {
System.out.println(stu);
}
student.close();
students.close();
}
}
IO+Properties的联合应用
以后经常改变的数据,可以单独写到一个文件中,使用程序动态读取
将来只需要修改这个文件的内容,java代码不需要改动,不需要重新编译,服务器也不需要重启。就可以拿到动态的信息。
类似于以上机制的这种文件被称为配置文件
并且当配置文件的内容格式是:
key=value
的时候,我们把这种高配置文件叫做属性配置文件
java规范中有要求:属性配置文件建议以properties结尾,但是这不是必须的
以.properties结尾的文件在java中被称为:属性配置文件
其中Properties对象是专门存放属性配置文件内容的一个类。
###############属性配置文件中 # 是注释######################
#属性配置文件的key重复的话,value会自动覆盖#
#key=value中间最好不要有空格#
username=admin
password=1234