open pose2019 OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields论文翻译与原理理解
highlights:
①证明只有PAFs的优化有助于系统的性能和准确性。(之前的工作认为PAFs和body part location estimation共同作用才能促进系统优化)
②提出第一个组合body 和foot的detector(基于一个内部注释的脚部数据集,已开源)
③本文提出的组合检测器不仅减少了推理时间而且保持了每个部件的准确性
④发布了openpose这一开源系统
Human pose estimation存在的挑战;
first:用于检测的图片中的人的数量是未知的且无规律的
second:人与人之间的相互作用和重叠造成关节之间的关联困难
third:在实时运行时,我画面中的人的数量会变化。这就造成了实时性的困难。
自上而下方法的缺点:
常见的方法是执行 person detector,再对检测到的人进行单人姿态估计。这种自上而下的方法虽然很好理解但是却受检测效果的影响。如果画面内的人体出现遮挡、重合等无法检测的情况,则不会向下执行(缺点1)。此外运行时间与图像中的人数成正比(缺点2)。
自下而上方法的发展历程:
以为自上而下的方法有以上缺点,所以自下而上的方法就变的很有吸引力。
最初的自底向上方法效率不高,因为最终解析需要昂贵的全局推断,每个图像的处理需要几分钟的时间。
(一)Single Person Pose Estimation
传统的关节式人体姿态估计方法是通过对人体各部位的局部观测以及它们之间的空间相关性进行推断。关节姿势的空间模型要么基于树结构的图形模型,这些模型参数化地编码了运动链上相邻部件之间的空间关系,要么基于非树模型它通过附加的边来增强树结构,以捕捉遮挡、对称性和远程关系。(这里不懂(((φ(◎ロ◎;)φ))))
为了获得可靠的body parts局部观测值,卷积神经网络(CNNs)得到了广泛的应用,并显著提高了body pose estimation 的精度。
(二)Multi-Person Pose Estimation
对于多人姿态估计,大多数方法都采用了自上而下的策略。首先检测到人,然后在每个检测区域独立估计每个人的姿势。虽然这种自上而下的方法简单,但过分依赖于前期的检测结果,而且对于人与人之间的遮挡和依赖无法做出很好的判断。
正是以为自上而下的方法有这些缺点,一些方法开始考虑如何人与人之间的依赖性问题。有研究扩展了图像结构,将一组相互作用的人和深度排序考虑在内,但仍然需要一个人检测器来初始化检测假设。提出了一种自底向上的方法,联合标记零件检测候选零件,并将它们与个人关联,从检测零件的空间偏移量中回归成对得分。该方法不依赖于人的检测,但是在全连通图上求解整数线性规划是一个NP难问题,因此单个图像的平均处理时间约为小时。
在早期的研究[3]中,我们提出了部分相似域(PAF),它是由一组流场组成的表示,它对不同数量的人体各部分之间的非结构化成对关系进行编码。可以在不需要额外的训练步骤的情况下有效地从PAFs中获得成对的数值。这些数值足以让贪婪的解析获得高质量的结果,并具有实时性,以便进行多人估计。
论文行文结构:
3.1和3.2:证明了PAF精化对于最大化精度是至关重要的,而身体部位预测精化则不是那么重要。增加了网络深度,但删除了身体部位的细化阶段。
4.2:提出了一个注释脚部数据集,其中包含已公开发布的15K人脚实例。
5.2和5.3:这种改进的网络使速度和精度分别提高了约200%和7%。
5.3:与Mask R-CNN和Alpha Pose的运行进行比较,显示了该自下而上方法的计算优势。
5.5:明可以训练具有身体和脚关键点的组合模型,在保持其准确性的同时保持仅身体模型的速度。
5.6:通过将其应用于车辆关键点估计任务,证明了该方法的通用性。
论文内容:
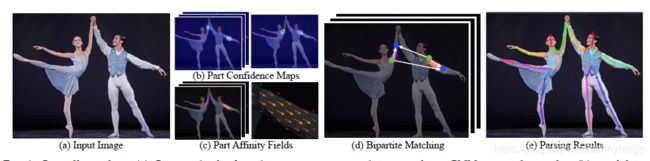
算法输入:w*h的color image
算法输出:color image每个人的解剖关键点的二维位置
首先,输入image到VGG-19(使用前10层)提取出关节点特征。前馈网络预测body parts locations 的一组2D置信图S(图2b)和一组2D vector fieldL(PAFs),这个PAFs编码了body parts之间的关联度(图2c)。通过贪婪推理(图2d)解析置信图和PAFs,输出图像中所有人的2d关键点。
以下是论文的网络框架。

3.1 网络结构
网络的结构其实是很简单的,分为两大块。第一块蓝色部分用于产生输入图片的PAFs,(叫做Lt).图片特征F加上这个Lt成为了第二部分的输入,第二部分橙色部分输出置信图S。其中粉色部分为3层3*3卷积块,每个3×3的卷积之间串联,如虚线框里所示。
3.2 同时检测和关联之PAF和置信图
论文网络的输入是图片特征映射F,这个F由CNN分析原始图像(由VGG-19的前10层初始化并进行微调),生成一组输入到第一级的特征映射。在这个阶段,网络生成一组部件关联字段(PAF)。
![]()
在上一节我们说过,L是什么,这里的L1是CNN在stage1阶段预测出的关联字段PAF(因为网络是不断迭代的,所以会有好多个stage,论文上说有T个)。在随后的每个 stage 中,将前一阶段的预测与原始图像特征F相连接并用于生成精确的预测。公式如下:
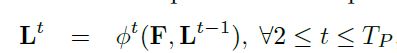
在该部分,PAFs的最大阶数为Tp。
在TP迭代之后,从最新的PAF预测开始,重复置信图检测过程。也就是说,open pose的两大组成是一前一后进行的?
在得出较为准确的PAFs之后才进行置信图的预测。下面开始执行这一部分:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iQb52loD-1599696443490)(C:\Users\sxj96\AppData\Roaming\Typora\typora-user-images\1599635140224.png)]](http://img.e-com-net.com/image/info8/834bad6c4a864396bccfd2fa054bd6e0.jpg)
ρt是CNN预测置信图过程,Tc表示置信图迭代最大阶数。
那么为什么open pose要把网络图设置成前后进行的呢?(我的猜测)
论文中提到,之前的工作是在每一stage都把PAFs和置信图进行细化,而在本论文中是先得出较为精确的PAFs再进行置信图的预测(计算量小了一半)。论文作者在第5.2节经验性地观察到,改进的亲和力场的预测(这里的亲和力场是PAFs吧)会直接改善了置信图结果,而反之则不成立。直观地说,如果有精确的PAF通道输出,身体部位的位置就可以猜出来了。然而,如果我们看到一堆没有其他信息的身体部位,我们就不能把它们解析成不同的人。
置信图结果是在最新和最精确的PAF预测的基础上进行预测的
同时检测和关联之损失函数
这时我们再来回顾一下本论文的网络结构,在每一个分支的尾部都加了一个损失函数。使用的损失函数是我们很熟悉的L2损失函数。是的,在两个分支都是使用的L2。
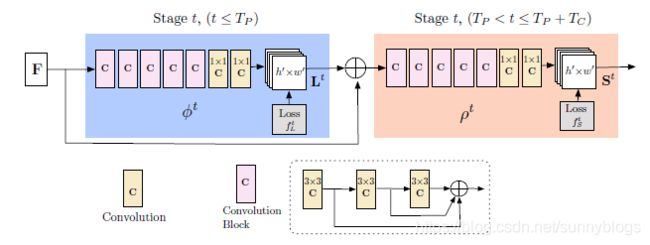
为了引导网络迭代地预测第一个分支中身体部位的PAF和第二个分支中的置信图,在每个阶段的末尾应用了一个损失函数。
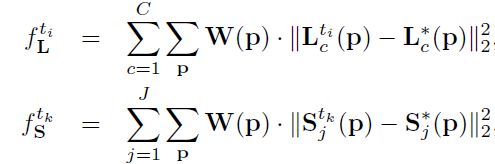
其中![]()
是PAF的groundtruth,![]() 是置信图ground truth。当像素P缺少注释时,W是一个二进制掩码,W(p)=0。
是置信图ground truth。当像素P缺少注释时,W是一个二进制掩码,W(p)=0。
mask是用来避免在训练中惩罚真正的积极预测。每个阶段的中间监督通过定期补充梯度来解决梯度消失问题。
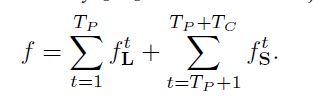
3.3 Part Detection的置信图
为了在训练期间评估上面公式中的fS,我们从带注释的2D关键点生成基础真相置信图S*。每个置信图都是一个二维表示,即某个特定的身体部位可以定位在任何给定的像素中。理想情况下,如果一个人出现在图像中,如果对应的部分可见,则每个置信图中应该存在一个峰值;如果图像中有多个人,则每个人k对应每个可见部分j对应一个峰值。Sj,k为每个人k生成的个体置信图。Xj,k是图像中人物k的身体j 部分的真实位置。控制了峰值的传播。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NsNp0Lrb-1599696443495)(C:\Users\sxj96\AppData\Roaming\Typora\typora-user-images\1599640294230.png)]](http://img.e-com-net.com/image/info8/48a1175ee73c4cdea68b8dc1e9fe13c2.jpg)
网络预测的地面真实度置信图是个体置信度图通过max算子的集合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LX8qlIn1-1599696443496)(C:\Users\sxj96\AppData\Roaming\Typora\typora-user-images\1599640851142.png)]](http://img.e-com-net.com/image/info8/813e35b3de8049c1a2bdaca224af2df2.jpg)
取置信图的最大值,而不是平均值,这样附近峰值的精度仍然是不同的,如右图所示。在测试时,我们预测置信图,并通过执行非最大值抑制来获得候选身体部位。
3.4 部件关联PAFs
这部分我认为是本篇论文最值得好好研读的地方,毕竟自下而上的方法最核心便是人体物理的设计。
这一part来看看PAF是怎么计算的。

给定一组检测到的身体部位(如图5a中的红蓝点所示),我们如何将它们组合起来,形成未知数量的人的全身姿势?我们需要对每对身体部位检测的关联度进行置信度度量,即给一个公式用来衡量它们是否属于同一个人。测量关联的一种可能方法是检测肢体上每对零件之间的附加中点,并检查候选零件检测之间的关联度,如图5b所示,当人们聚集在一起,因为他们倾向于这样做,这些中点很可能支持错误的联想(如图5b中的绿线所示)。这种错误的关联产生于两个方面的限制:(1)它只编码每个肢体的位置,而不是方向;(2)它将肢体的支撑区域缩小到一个点。
以上的方法有问题?没有关系!本文的PAFs解决了以上限制。它们保存了四肢支撑区域的位置和方向信息(如图5c所示)。 每个PAF是每个肢体的2D向量场,如图1d所示。对于属于特定肢体的区域中的每个像素,2D向量编码从肢体的一部分指向另一部分的方向。每种类型的肢体都有一个相应的PAF连接其两个相关的身体部分。


贴一下别人讲的吧,懒得打了。

这篇论文最核心的思想就是提出了PAFs,我的理解是这个PAF就是衡量两个关键点能连成肢体的可靠度。比如,上图给出的小臂的例子,VGG检测出了图中人k的两个关键点dj1与dj2。在这两个关键点位置之间存在许许多多的像素点P,采用间隔采样的方法选出了两个位置之间的若干个P。对于这些P进行判断。如果v*(P-dj1)![]() 则认为P点在躯干上。
则认为P点在躯干上。
相信很多人都看过2017版的open pose,这篇论文是2019年作者团队改进的。主要是网络改了,而且卷积核采用了3*3的小卷积核。
这里留个坑,写一下两篇论文网络的对比,以及2019版网络的改进。
Single Person Pose Estimation参考文献
[7] P. F. Felzenszwalb and D. P. Huttenlocher, “Pictorial structures for object recognition,” in IJCV, 2005.
[8] D. Ramanan, D. A. Forsyth, and A. Zisserman, “Strike a Pose: Tracking people by finding stylized poses,” in CVPR, 2005.
[9] M. Andriluka, S. Roth, and B. Schiele, “Monocular 3D pose estimation and tracking by detection,” in CVPR, 2010.
[10] ——, “Pictorial structures revisited: People detection and articulated pose estimation,” in CVPR, 2009.
[11] L. Pishchulin, M. Andriluka, P. Gehler, and B. Schiele, “Poselet conditioned pictorial structures,” in CVPR, 2013.
[12] Y. Yang and D. Ramanan, “Articulated human detection with flexible mixtures of parts,” in TPAMI, 2013.
[13] S. Johnson and M. Everingham, “Clustered pose and nonlinear appearance models for human pose estimation,” in BMVC, 2010.
[14] Y. Wang and G. Mori, “Multiple tree models for occlusion and spatial constraints in human pose estimation,” in ECCV, 2008.
[15] L. Sigal and M. J. Black, “Measure locally, reason globally: Occlusion-sensitive articulated pose estimation,” in CVPR, 2006.
[16] X. Lan and D. P. Huttenlocher, “Beyond trees: Common-factor models for 2d human pose recovery,” in ICCV, 2005.
[17] L. Karlinsky and S. Ullman, “Using linking features in learning non-parametric part models,” in ECCV, 2012.
[18] M. Dantone, J. Gall, C. Leistner, and L. Van Gool, “Human pose estimation using body parts dependent joint regressors,” in CVPR,2013.
[19] A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” in ECCV, 2016.
[20] S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh, “Convolutional pose machines,” in CVPR, 2016.
[21] W. Ouyang, X. Chu, and X. Wang, “Multi-source deep learning for human pose estimation,” in CVPR, 2014.
[22] J. Tompson, R. Goroshin, A. Jain, Y. LeCun, and C. Bregler, “Efficient object localization using convolutional networks,” in CVPR, 2015.
[23] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler, “Joint training of a convolutional network and a graphical model for human pose estimation,” in NIPS, 2014.
[24] X. Chen and A. Yuille, “Articulated pose estimation by a graphical model with image dependent pairwise relations,” in NIPS, 2014.
[25] A. Toshev and C. Szegedy, “Deeppose: Human pose estimation via deep neural networks,” in CVPR, 2014.
[26] V. Belagiannis and A. Zisserman, “Recurrent human pose estimation,” in IEEE FG, 2017.
[27] A. Bulat and G. Tzimiropoulos, “Human pose estimation via convolutional part heatmap regression,” in ECCV, 2016.
[28] X. Chu, W. Yang, W. Ouyang, C. Ma, A. L. Yuille, and X. Wang, “Multi-context attention for human pose estimation,” in CVPR, 2017.
[29] W. Yang, S. Li, W. Ouyang, H. Li, and X. Wang, “Learning feature pyramids for human pose estimation,” in ICCV, 2017.
[30] Y. Chen, C. Shen, X.-S. Wei, L. Liu, and J. Yang, “Adversarial posenet: A structure-aware convolutional network for human pose
estimation,” in ICCV, 2017.
[31] W. Tang, P. Yu, and Y. Wu, “Deeply learned compositional models for human pose estimation,” in ECCV, 2018.
[32] L. Ke, M.-C. Chang, H. Qi, and S. Lyu, “Multi-scale structureaware network for human pose estimation,” in ECCV, 2018.
[33] T. Pfister, J. Charles, and A. Zisserman, “Flowing convnets for human pose estimation in videos,” in ICCV, 2015.
[34] V. Ramakrishna, D. Munoz, M. Hebert, J. A. Bagnell, and Y. Sheikh, “Pose machines: Articulated pose estimation via inference machines,” in ECCV, 2014.
[35] S. Hochreiter, Y. Bengio, and P. Frasconi, “Gradient flow in recurrent nets: the difficulty of learning long-term dependencies,” in Field Guide to Dynamical Recurrent Networks, J. Kolen and S. Kremer, Eds. IEEE Press, 2001.
[36] X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in AISTATS, 2010.
Multi-Person Pose Estimation参考文献
L. Pishchulin, A. Jain, M. Andriluka, T. Thorm¨ahlen, and B. Schiele, “Articulated people detection and pose estimation: Reshaping the future,” in CVPR, 2012.
[39] G. Gkioxari, B. Hariharan, R. Girshick, and J. Malik, “Using kposelets for detecting people and localizing their keypoints,” in CVPR, 2014.
[40] M. Sun and S. Savarese, “Articulated part-based model for joint object detection and pose estimation,” in ICCV, 2011.
[41] U. Iqbal and J. Gall, “Multi-person pose estimation with local jointto- person associations,” in ECCV Workshop, 2016.
[42] G. Papandreou, T. Zhu, N. Kanazawa, A. Toshev, J. Tompson, C. Bregler, and K. Murphy, “Towards accurate multi-person pose estimation in the wild,” in CVPR, 2017.
[43] Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, and J. Sun, “Cascaded pyramid network for multi person pose estimation,” in CVPR, 2018.
[44] B. Xiao, H. Wu, and Y. Wei, “Simple baselines for human pose estimation and tracking,” in ECCV, 2018.
[45] M. Eichner and V. Ferrari, “We are family: Joint pose estimation of multiple persons,” in ECCV, 2010.
[46] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR,2016.
[47] E. Insafutdinov, M. Andriluka, L. Pishchulin, S. Tang, E. Levinkov, B. Andres, and B. Schiele, “Arttrack: Articulated multi-person tracking in the wild,” in CVPR, 2017.
[48] A. Newell, Z. Huang, and J. Deng, “Associative embedding: Endto-end learning for joint detection and grouping,” in NIPS, 2017.
[49] G. Papandreou, T. Zhu, L.-C. Chen, S. Gidaris, J. Tompson, andK. Murphy, “Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding
model,” in ECCV, 2018
[50] M. Kocabas, S. Karagoz, and E. Akbas, “MultiPoseNet: Fast multiperson pose estimation using pose residual network,” in ECCV, 2018.
[51] X. Nie, J. Feng, J. Xing, and S. Yan, “Pose partition networks for multi-person pose estimation,” in ECCV, 2018…