集成学习:Bagging Boosting&Stacking (二)
集成学习:Bagging Boosting&Stacking
- 5.Python例子
-
- 5.1 Import 库
- 5.2 加载数据,数据处理
-
- 5.2.1 审视数据
- 5.2.2 数据类型字段更改
- 5.2.3 缺失值处理
- 5.2.4 数据转化
- 5.3 划分训练集与测试集
- 5.4 回归模型
-
- 5.4.1 Linear Regression
- 5.4.2 Lasso Regression
- 5.4.3 Elastic Regression
- 5.4.4 KernelRidge Regression
- 5.5 集成模型
-
- 5.5.1 Bagging
- 5.5.2 Boosting
- 5.5.3 Stacking
5.Python例子
这里我们将使用下面这个数据集,使用二手车的12个特征属性,来预测这辆二手车能卖多少w。给把握不住二手车水深的卖家,卖出一个好w。
cars-price

来看下数据的特征名称与特征描述
| 属性 | 描述 |
|---|---|
| Name | 汽车的品牌和型号 |
| Location | 汽车出售或可供购买的地点 |
| Year | 汽车年份 |
| Kilometers_Driven | 前车主在车内行驶的总公里数(单位:KM) |
| Fuel_Type | 燃料类型 |
| Transmission | 变速器类型 |
| Owner_Type | 车子是所属权(是一手还是二手) |
| Mileage | 标准里程,单位为kmpl或km/kg |
| Engine | 发动机的排量(单位:cc) |
| Power | 发动机最大功率 |
| Seats | 车里的座位数 |
| New_Price | 新车的价格 |
| Price | 二手车的价格以10亿卢比为单位 |
5.1 Import 库
MacOs安装lightgbm方法:
#先安装cmake和gcc,安装过的直接跳过前两步
brew install cmake
brew install gcc
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
#在cmake之前有一步添加环境变量
export CXX=g++-7 CC=gcc-7
mkdir build ; cd build
cmake ..
make -j4
cd ../python-package
sudo python setup.py install
import warnings
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.linear_model import LinearRegression, Lasso, ElasticNet
from sklearn.kernel_ridge import KernelRidge
from sklearn.ensemble import BaggingRegressor
from sklearn.ensemble import GradientBoostingRegressor
import xgboost as xgb
import lightgbm as lgb
from sklearn.ensemble import StackingRegressor
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import mean_squared_error
warnings.filterwarnings("ignore")
n_jobs=-1
random_state=42
5.2 加载数据,数据处理
data =pd.read_csv('train.csv')

按照之前文章的数据处理方式:
数据处理汇总
5.2.1 审视数据
data.info()
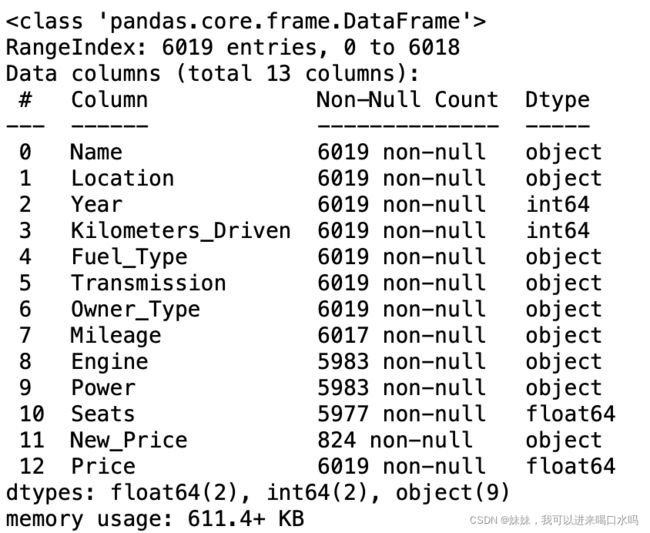
data.isnull().sum()

5.2.2 数据类型字段更改
- 去除字段里的单位字符
- 将字符为类别的字段转化为category
- 将汽车的发行年份Year,转化成汽车的年龄Car_Age
- 将汽车Name拆分成公司Company和汽车车型model
data['Mileage']=data['Mileage'].str.rstrip(' kmpl')
data['Mileage']=data['Mileage'].str.rstrip(' km/g')
data['Engine']=data['Engine'].str.rstrip(' CC')
data["Power"]=data['Power'].str.rstrip(' bhp')
data['Power']=data["Power"].replace(regex='null',value=np.nan)
data["Fuel_Type"]=data["Fuel_Type"].astype("category")
data["Transmission"]=data["Transmission"].astype("category")
data["Owner_Type"]=data["Owner_Type"].astype("category")
data["Mileage"]=data["Mileage"].astype("float")
data["Power"]=data["Power"].astype("float")
data["Engine"]=data["Engine"].astype("float")
data['Current_Year']=2022
data['Car_Age']=data['Current_Year']-data['Year']
data['Company']=data['Name'].str.split(' ').str[0]
data['Model']=data['Name'].str.split(' ').str[1]+data['Name'].str.split(' ').str[2]
del data['Current_Year']
del data['Name']
del data['Year']
del data['New_Price']
5.2.3 缺失值处理
mode=data.Mileage.mode()
data['Mileage'].fillna(value=mode[0],inplace=True)
newdata = data.dropna(axis=0)
newdata.info()
5.2.4 数据转化
将特征类型为category,转化成ensemble类型
newdata=pd.get_dummies(newdata)

5.3 划分训练集与测试集
y=newdata[['Price']]
del train['Price']
x=train
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size= 0.2, random_state = random_state)
print(f'Training set--> X_train shape= {X_train.shape}, y_train shape= {y_train.shape}')
print(f'Holdout set--> X_test shape= {X_test.shape}, y_test shape= {y_test.shape}')
![]()
我们将使用均方根误差(RMSE)度量来比较分数。由于这个指标不是现成的,我们将为它创建一个函数。
注:RMSE公制用于以与标签价值相同的计量单位表示损失
models_scores = [] # To store model scores
def rmse(model):
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
return mean_squared_error(y_test, y_pred, squared= False)
5.4 回归模型
5.4.1 Linear Regression
linear_regression = make_pipeline(LinearRegression())
score = rmse(linear_regression)
models_scores.append(['LinearRegression', score])
print(f'LinearRegression Score= {score}')

5.4.2 Lasso Regression
lasso = make_pipeline(RobustScaler(), Lasso(alpha=0.0005, random_state= random_state))
score = rmse(lasso)
models_scores.append(['Lasso', score])
print(f'Lasso Score= {score}')

5.4.3 Elastic Regression
elastic_net = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio= .9, random_state= random_state))
score = rmse(elastic_net)
models_scores.append(['ElasticNet', score])
print(f'ElasticNet Score= {score}')

5.4.4 KernelRidge Regression
kernel_ridge= KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
score = rmse(kernel_ridge)
models_scores.append(['KernelRidge', score])
print(f'KernelRidge Score= {score}')

5.5 集成模型
5.5.1 Bagging
def bagging_predictions(estimator):
"""
I/P
estimator: The base estimator from which the ensemble is grown.
O/P
br_y_pred: Predictions on test data for the base estimator.
"""
regr = BaggingRegressor(base_estimator=estimator,
n_estimators=10,
max_samples=1.0,
bootstrap=True, # Samples are drawn with replacement
n_jobs= n_jobs,
random_state=random_state).fit(X_train, y_train)
br_y_pred = regr.predict(X_test)
rmse_val = mean_squared_error(y_test, br_y_pred, squared= False) # squared= False > returns Root Mean Square Error
print(f'RMSE for base estimator {regr.base_estimator_} = {rmse_val}\n')
return br_y_pred
predictions = np.column_stack((bagging_predictions(linear_regression),
bagging_predictions(lasso),
bagging_predictions(elastic_net),
bagging_predictions(kernel_ridge)))
print(f"Bagged predictions shape: {predictions.shape}")
y_pred = np.mean(predictions, axis=1)
print("Aggregated predictions (y_pred) shape", y_pred.shape)
rmse_val = mean_squared_error(y_test, y_pred, squared= False) # squared= False > returns Root Mean Square Error
models_scores.append(['Bagging', rmse_val])
print(f'\nBagging RMSE= {rmse_val}')
![]()
5.5.2 Boosting
GradientBoostingRegressor
gradient_boosting_regressor= GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state = random_state)
score = rmse(gradient_boosting_regressor)
models_scores.append(['GradientBoostingRegressor', score])
print(f'GradientBoostingRegressor Score= {score}')
![]()
XGBRegressor
xgb_regressor= xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213,verbosity=0, nthread = -1, random_state = random_state)
score = rmse(xgb_regressor)
models_scores.append(['XGBRegressor', score])
print(f'XGBRegressor Score= {score}')

LGBMRegressor
lgbm_regressor= lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11,random_state = random_state)
score = rmse(lgbm_regressor)
models_scores.append(['LGBMRegressor', score])
print(f'LGBMRegressor Score= {score}')
5.5.3 Stacking
estimators = [ ('elastic_net', elastic_net), ('kernel_ridge', kernel_ridge),('xgb_regressor', xgb_regressor) ]
stack = StackingRegressor(estimators=estimators, final_estimator= lasso, cv= 5, n_jobs= n_jobs, passthrough = True)
stack.fit(X_train, y_train)
pred = stack.predict(X_test)
rmse_val = mean_squared_error(y_test, pred, squared= False) # squared= False > returns Root Mean Square Error
models_scores.append(['Stacking', rmse_val])
print(f'rmse= {rmse_val}')

汇总一下
pd.DataFrame(models_scores).sort_values(by=[1], ascending=True)
