虎年到,新年用Python与人工智能一起写春节对联 python+pytorch+Transformer+BiLSTM+ATTN+CNN
艾薇巴迪大家好,虎年春节就要到了,首先在此祝大家新春快乐、虎年大吉。
用Python与人工智能一起写春联
- 前言
- 1、分析
- 2、配置对联项目
-
- 2.1、配置下载
- 2.2、数据预处理
- 2.3、训练
- 2.4、运行
- 3、训练样例
- 4、与AI一起写虎年春联
- 5、资源下载
前言
众所周知,每到春节,家家户户都会在门口精心贴上漂亮的春联,辞旧迎新、辟邪除灾、迎祥纳福,增加喜庆的节日气氛。


春联,是我们中国特有的文学形式,是华夏民族过年的重要习俗,春联讲究的是对仗工整、简洁精巧。古往今来,有很多很多千古绝对妙对,无奈我是文化荒漠不会写对联,不如找一个人工智能(障)来帮我一起写写对联吧!
1、分析
要让人工智能会对对联,首先要给他准备大量的对联数据给他学,让他先看看别人的对联是怎么对的。
为他分开准备上联和下联,下载数据集

一般来讲,对对联就是给定一句话生成另一句话,这是序列生成问题,本项目根据上下联字数相等的特点将其转化为序列标注问题,即用下联去标注上联。
**模型使用了Transformer+BiLSTM+ATTN+CNN,**模型核心代码为:
class Transformer(nn.Module):
def __init__(self, vocab_size: int, max_seq_len: int, embed_dim: int, hidden_dim: int, n_layer: int, n_head: int, ff_dim: int, embed_drop: float, hidden_drop: float):
super().__init__()
self.tok_embedding = nn.Embedding(vocab_size, embed_dim)
self.pos_embedding = nn.Embedding(max_seq_len, embed_dim)
layer = nn.TransformerEncoderLayer(
d_model=hidden_dim, nhead=n_head, dim_feedforward=ff_dim, dropout=hidden_drop)
self.encoder = nn.TransformerEncoder(layer, num_layers=n_layer)
self.embed_dropout = nn.Dropout(embed_drop)
self.linear1 = nn.Linear(embed_dim, hidden_dim)
self.linear2 = nn.Linear(hidden_dim, embed_dim)
def encode(self, x, mask):
x = x.transpose(0, 1)
x = self.encoder(x, src_key_padding_mask=mask)
x = x.transpose(0, 1)
return x
def forward(self, x, *args):
# (batch_size, max_seq_len, embed_dim)
mask = args[0] if len(args) > 0 else None
tok_emb = self.tok_embedding(x)
max_seq_len = x.shape[-1]
pos_emb = self.pos_embedding(torch.arange(max_seq_len).to(x.device))
x = tok_emb + pos_emb.unsqueeze(0)
x = self.embed_dropout(x)
x = self.linear1(x)
x = self.encode(x, mask)
x = self.linear2(x)
probs = torch.matmul(x, self.tok_embedding.weight.t())
return probs
class BiLSTM(nn.Module):
def __init__(self, vocab_size: int, embed_dim: int, hidden_dim: int, n_layer: int, embed_drop: float, rnn_drop: float):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.bilstm = nn.LSTM(embed_dim, hidden_dim // 2, num_layers=n_layer,
dropout=rnn_drop if n_layer > 1 else 0, batch_first=True, bidirectional=True)
self.embed_dropout = nn.Dropout(embed_drop)
self.linear = nn.Linear(hidden_dim, embed_dim)
def encode(self, x):
x = self.embedding(x)
x = self.embed_dropout(x)
x, _ = self.bilstm(x)
return x
def predict(self, x):
x = self.linear(x)
probs = torch.matmul(x, self.embedding.weight.t())
return probs
def forward(self, x, *args):
x = self.encode(x)
return self.predict(x)
class BiLSTMAttn(BiLSTM):
def __init__(self, vocab_size: int, embed_dim: int, hidden_dim: int, n_layer: int, embed_drop: float, rnn_drop: float, n_head: int):
super().__init__(vocab_size, embed_dim, hidden_dim, n_layer, embed_drop, rnn_drop)
self.attn = nn.MultiheadAttention(hidden_dim, n_head)
def forward(self, x, *args):
mask = args[0] if len(args) > 0 else None
x = self.encode(x)
x = x.transpose(0, 1)
x = self.attn(x, x, x, key_padding_mask=mask)[0].transpose(0, 1)
return self.predict(x)
class BiLSTMCNN(BiLSTM):
def __init__(self, vocab_size: int, embed_dim: int, hidden_dim: int, n_layer: int, embed_drop: float, rnn_drop: float):
super().__init__(vocab_size, embed_dim, hidden_dim, n_layer, embed_drop, rnn_drop)
self.conv = nn.Conv1d(in_channels=hidden_dim,
out_channels=hidden_dim, kernel_size=3, padding=1)
def forward(self, x, *args):
x = self.encode(x)
x = x.transpose(1, 2)
x = self.conv(x).transpose(1, 2).relu()
return self.predict(x)
class BiLSTMConvAttRes(BiLSTM):
def __init__(self, vocab_size: int, max_seq_len: int, embed_dim: int, hidden_dim: int, n_layer: int, embed_drop: float, rnn_drop: float, n_head: int):
super().__init__(vocab_size, embed_dim, hidden_dim, n_layer, embed_drop, rnn_drop)
self.attn = nn.MultiheadAttention(hidden_dim, n_head)
self.conv = nn.Conv1d(in_channels=hidden_dim,
out_channels=hidden_dim, kernel_size=3, padding=1)
self.norm = nn.LayerNorm(hidden_dim)
def forward(self, x, *args):
mask = args[0] if len(args) > 0 else None
x = self.encode(x)
res = x
x = self.conv(x.transpose(1, 2)).relu()
x = x.permute(2, 0, 1)
x = self.attn(x, x, x, key_padding_mask=mask)[0].transpose(0, 1)
x = self.norm(res + x)
return self.predict(x)
class CNN(nn.Module):
def __init__(self, vocab_size: int, embed_dim: int, hidden_dim: int, embed_drop: float):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.conv = nn.Conv1d(in_channels=embed_dim,
out_channels=hidden_dim, kernel_size=3, padding=1)
self.embed_dropout = nn.Dropout(embed_drop)
self.linear = nn.Linear(hidden_dim, embed_dim)
def forward(self, x, *args):
x = self.embedding(x)
x = self.embed_dropout(x)
x = x.transpose(1, 2)
x = self.conv(x).transpose(1, 2).relu()
x = self.linear(x)
probs = torch.matmul(x, self.embedding.weight.t())
return probs
2、配置对联项目
2.1、配置下载
首先下载对对联代码到本机或者云服务器,我用的是colab进行实验,用本地的pycharm或者其他IDE同样也可以。
并将1中下载到的数据集解压到当前目录(解压后的文件夹名称为couplet)
2.2、数据预处理
运行 preprocess.py 进行数据预处理
preprocess.py核心代码
def read_examples(fdir: Path):
seqs = []
tags = []
with open(fdir / "in.txt", 'r', encoding='utf-8') as f:
for line in f.readlines():
seqs.append(line.split())
with open(fdir / "out.txt", 'r', encoding='utf-8') as f:
for line in f.readlines():
tags.append(line.split())
examples = [CoupletExample(seq, tag) for seq, tag in zip(seqs, tags)]
return examples
def convert_examples_to_features(examples: List[CoupletExample], tokenizer: Tokenizer):
features = []
for example in tqdm(examples, desc="creating features"):
seq_ids = tokenizer.convert_tokens_to_ids(example.seq)
tag_ids = tokenizer.convert_tokens_to_ids(example.tag)
features.append(CoupletFeatures(seq_ids, tag_ids))
return features
def convert_features_to_tensors(features: List[CoupletFeatures], tokenizer: Tokenizer, max_seq_len: int):
total = len(features)
input_ids = torch.full((total, max_seq_len),
tokenizer.pad_id, dtype=torch.long)
target_ids = torch.full((total, max_seq_len),
tokenizer.pad_id, dtype=torch.long)
masks = torch.ones(total, max_seq_len, dtype=torch.bool)
lens = torch.zeros(total, dtype=torch.long)
for i, f in enumerate(tqdm(features, desc="creating tensors")):
real_len = min(len(f.input_ids), max_seq_len)
input_ids[i, :real_len] = torch.tensor(f.input_ids[:real_len])
target_ids[i, :real_len] = torch.tensor(f.target_ids[:real_len])
masks[i, :real_len] = 0
lens[i] = real_len
return input_ids, masks, lens, target_ids
def create_dataset(fdir: Path, tokenizer: Tokenizer, max_seq_len: int):
examples = read_examples(fdir)
features = convert_examples_to_features(examples, tokenizer)
tensors = convert_features_to_tensors(features, tokenizer, max_seq_len)
dataset = TensorDataset(*tensors)
return dataset
运行后显示预训练成功。

2.3、训练
运行 main.py [-m model type] 进行训练
main.py核心代码:
def run():
args = get_args()
fdir = Path(args.dir)
tb = SummaryWriter(args.logdir)
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
output_dir = Path(args.output)
output_dir.mkdir(exist_ok=True, parents=True)
logger.info(args)
logger.info(f"loading vocab...")
tokenizer = Tokenizer.from_pretrained(fdir / 'vocab.pkl')
logger.info(f"loading dataset...")
train_dataset = torch.load(fdir / 'train.pkl')
test_dataset = torch.load(fdir / 'test.pkl')
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=args.batch_size)
logger.info(f"initializing model...")
model = init_model_by_key(args, tokenizer)
model.to(device)
loss_function = nn.CrossEntropyLoss(ignore_index=tokenizer.pad_id)
optimizer = optim.Adam(model.parameters(), lr=args.lr)
if args.fp16:
try:
from apex import amp
amp.register_half_function(torch, 'einsum')
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
if torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min')
logger.info(f"num gpu: {torch.cuda.device_count()}")
global_step = 0
for epoch in range(args.epochs):
logger.info(f"***** Epoch {epoch} *****")
model.train()
t1 = time.time()
accu_loss = 0.0
for step, batch in enumerate(train_loader):
optimizer.zero_grad()
batch = tuple(t.to(device) for t in batch)
input_ids, masks, lens, target_ids = batch
logits = model(input_ids, masks)
loss = loss_function(logits.view(-1, tokenizer.vocab_size), target_ids.view(-1))
if torch.cuda.device_count() > 1:
loss = loss.mean()
accu_loss += loss.item()
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
if step % 100 == 0:
tb.add_scalar('loss', loss.item(), global_step)
logger.info(
f"[epoch]: {epoch}, [batch]: {step}, [loss]: {loss.item()}")
global_step += 1
scheduler.step(accu_loss)
t2 = time.time()
logger.info(f"epoch time: {t2-t1:.5}, accumulation loss: {accu_loss:.6}")
if (epoch + 1) % args.test_epoch == 0:
predict_demos(model, tokenizer)
bleu, rl = auto_evaluate(model, test_loader, tokenizer)
logger.info(f"BLEU: {round(bleu, 9)}, Rouge-L: {round(rl, 8)}")
if (epoch + 1) % args.save_epoch == 0:
filename = f"{model.__class__.__name__}_{epoch + 1}.bin"
filename = output_dir / filename
save_model(filename, model, args, tokenizer)
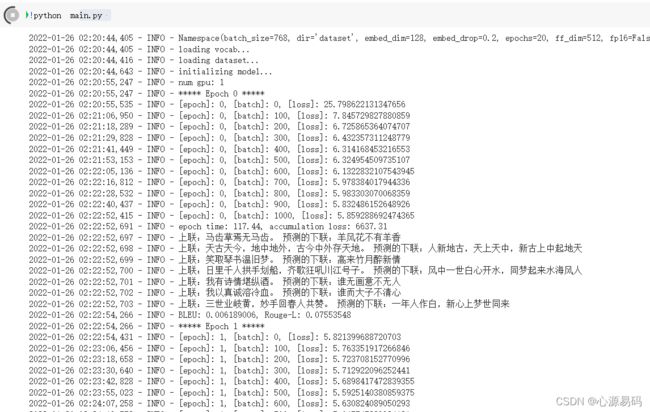
训练结果如下,刚开始模型的损失值在6左右,随着训练的进行,损失值逐渐降低到4,人工智能逐渐具有对对联的能力。

2.4、运行
通过上述20轮epoch的训练,此时AI已经具备对对联的能力,
我们只需要运行 clidemo.py <-p model path> 可在控制台进行AI对对联
或者运行 webdemo.py 可在Web端与AI进行对对联

3、训练样例
经过20个epoch训练,我们得到的训练样例,AI为我们写出的下联是:
> 上联1:马齿草焉无马齿。 预测的下联:牛头花也有牛头
> 上联2:天古天今,地中地外,古今中外存天地。预测的下联:人中古地,天上人中,天地古今在古今
> 上联3:笑取琴书温旧梦。 预测的下联:闲来风月醉新情
> 上联4:日里千人拱手划船,齐歌狂吼川江号子。 预测的下联:江中万里开心破路,共唱长飞天国英人
> 上联5:我有诗情堪纵酒。预测的下联:谁无画意可吟诗
> 上联6:我以真诚溶冷血。 预测的下联:谁因大意荡清心
> 上联7:三世业岐黄,妙手回春人共赞。预测的下联:一年家国白,雄心贺梦客同歌
好像还行(错觉)
4、与AI一起写虎年春联
那么值此新年之际,我们出几个虎年的春联上联来给AI对一对吧:
上联:春满大地福满人间。 预测的下联:秋一新天春一世下
上联:新年捷报虎添翼。 预测的下联:大日高流龙醉春
上联:四海笙歌迎虎岁。 预测的下联:一年水月醉龙春
上联:龙腾虎啸腊尽春回。 预测的下联:凤舞龙生人不秋不
上联:虎踞龙盘今胜昔。 预测的下联:龙生凤水古新春
上联:人民气魄如龙虎。 预测的下联:世国风风似凤人
上联:虎添双翼前程远。 预测的下联:龙有一春后气新
我去,这对了个寂寞啊,我就说是人工智障,那么我们再训练20轮epoch吧。
a few minutes later:
上联:春满大地福满人间。 预测的下联:福盈小天情盈世下
上联:新年捷报虎添翼。 预测的下联:盛岁春歌龙报春
上联:四海笙歌迎虎岁。 预测的下联:九州春舞贺龙年
上联:龙腾虎啸腊尽春回。 预测的下联:蛇舞莺鸣春来福满
上联:虎踞龙盘今胜昔。 预测的下联:龙鸣凤舞古如春
上联:人民气魄如龙虎。 预测的下联:社国精神似凤蛇
上联:虎添双翼前程远。 预测的下联:兔舞一春后业长
个人觉得最佳的一句是:龙腾虎啸腊尽春回,蛇舞莺鸣春来福满!
5、资源下载
虽然还有很多瑕疵,但是总算是有模有样了,训练好的模型我已经打包好了,可以点此链接下载:新年用Python与人工智能一起写春节对联,配置好环境后就可以直接开始对对联。
最后祝大家虎年大吉,祝CSDN越办越好!