【论文阅读】R3Det
论文地址:https://arxiv.org/abs/1908.05612
目录
摘要
1. 介绍
2. 相关工作
3. 提出的方法
3.1. 旋转RetinaNet
3.2. 精细旋转RetinaNet
4. 实验
4.1. 数据和规范
4.2. 健壮的基线的方法
4.3. 消融研究
4.4. 与最先进技术的比较
5. 结论
6. 补充材料
摘要
旋转检测是一项具有挑战性的任务,因为它难以定位多角度目标并将其有效地从背景中分离出来。虽然已经取得了相当大的进展,但在实际设置中,旋转物体的宽高比大、分布密集、类别极不平衡仍然存在挑战。在本文中,我们提出了一个端到端精细化的单级旋转检测器,通过使用从粗粒度到细粒度的逐步回归方法来快速和准确地检测目标。针对现有精细化单级检测器存在的特征不匹配的缺点,设计了特征精细化模块,通过获取更准确的特征来提高检测性能。特征细化模块的核心思想是通过逐像素的特征插值,将当前细化边界框的位置信息重新编码到对应的特征点,实现特征重构和对齐。为了更精确的旋转估计,提出了一种近似的SkewIoU损耗来解决SkewIoU的计算无法导出的问题。在DOTA、HRSC2016、UCAS-AOD三个热门遥感公共数据集以及ICDAR2015场景文本数据集上的实验验证了本文方法的有效性。Tensorflow和Pytorch版本代码可通过以下网址获取://github.com/Thinklab- SJTU/ R3Det_Tensorflow 和 https://github.com/ SJTU- thinklab - det / R3Det -on-mmdetection, R3Det也集成在我们的开源旋转检测基准中:https://github.com/ yangxue0827/RotationDetection。
1. 介绍
目标检测是计算机视觉的基础任务之一,许多高性能的通用目标检测器已经被提出。目前流行的检测方法大致可分为两类:两级目标检测器[14,13,40,8,27]和单级目标检测器[31,38,28]。两阶段方法在各种基准测试中取得了很好的结果,而单阶段方法保持了更快的检测速度。然而,目前通用的水平检测器在许多实际应用中有基本的局限性。例如场景文本检测、零售场景检测、遥感物体检测,物体可以以不同的方向出现。因此,在上述领域提出了许多基于通用检测框架的旋转检测器。特别突出的三个挑战,分析如下:
1)大纵横比。大纵横比物体之间的斜交联合(SkewIoU)评分对角度的变化很敏感,如图3(b)所示。
2)密集的安排。如图6所示,许多物体通常以密集排列的形式出现。
3)任意方向。图像中的物体可以以不同的方向出现,这就要求探测器具有准确的方向估计能力。
本文致力于设计一种精确、快速的旋转检测器。为了对大纵横比物体保持较高的检测精度和速度,我们采用了改进的单级旋转检测器。首先,我们发现旋转锚可以在密集场景中表现得更好,而水平锚可以在更少的数量下实现更高的召回。因此,细化的单级检测器采用由粗到细的逐步回归形式,即在第一阶段采用水平锚点,提高查全率和速度。然后在后续的细化阶段使用细化后的旋转锚,以适应密集场景。其次,我们也注意到现有的精细化单级探测器[57,7]存在特征不对齐问题,这极大地限制了精细化阶段分类回归的可靠性。我们设计了一个特征细化模块FRM,该模块利用特征插值获得细化锚点对应的位置信息,并以逐像素的方式重构整个特征地图,实现特征对齐。FRM还可以减少第一阶段后的精炼包围盒的数量,从而加快模型的速度。实验结果表明,特征细化对定位非常敏感,对检测结果的改善非常明显。最后,设计了一个近似的SkewIoU损耗来解决SkewIoU计算的不可微问题,从而实现更精确的旋转估计。结合这三种技术,我们的方法在四个公共旋转敏感数据集(包括DOTA、HRSC2016、UCAS-AOD和ICDAR2015)上实现了最先进的性能和相当大的速度。具体来说,这项工作作出了以下贡献:
1)针对大纵横比目标检测,精心设计高精度、快速旋转的单级检测器,实现高精度检测。相对于最近的基于学习的特征对齐方法[5,19,56],它缺乏一个明确的机制来补偿错位,我们提出了一种直接和有效的基于纯计算的方法,并进一步扩展到处理旋转情况。据我们所知,这是解决旋转检测中特征不对齐问题的第一步。
2)对于密集排列的物体,我们开发了一种高效的从粗到细的渐进回归方法,以更灵活的方式更好地探索两种锚的形式,为每个检测阶段量身定制。与以往采用单锚形式的方法[35,53,12,52,51]相比,我们的方法更加灵活和高效。
3)对于任意旋转的物体,设计了一个可推导的近似SkewIoU损失,以实现更精确的旋转估计。与最近[6]工作中对SkewIoU损耗的过近似相比,我们的方法保留了准确的SkewIoU振幅,只近似了SkewIoU损耗的梯度方向。
介绍的时候也要抛出需要解决的问题,重在分析问题以及为什么解决方案可以解决这个问题。关注一下表达,自己写的时候也要注意。
贡献:
1)创新性:自己设计了一个单级检测器。针对..缺陷提出什么解决方案用来解决什么问题。
2)两种锚框,与单锚框的优势对比。
3)原创新,损失函数是自己设计的,尽可能从数学角度分析,特别是可导性、振幅?、梯度(收敛速度??)。
(设计了一个可推导的近似SkewIoU损失,以实现更精确的旋转估计。与最近[6]工作中对SkewIoU损耗的过近似相比,我们的方法保留了准确的SkewIoU振幅,只近似了SkewIoU损耗的梯度方向。)
内容小结:
目前,旋转目标检测面临三个主要挑战:
- 待检测目标纵横比较大
- 待检测目标的排列较为密集
- 类别不平衡
关键词: 水平anchor的高召回率 旋转anchor对密集场景
本文讨论了如何设计一个准确和快速的旋转目标检测器。文章提出了一个refined one-stage 旋转检测器,其设计策略结合了水平anchor的高召回率和旋转anchor对密集场景的适应性两方面的优点。
- 在第一个阶段使用水平anchor,从而获得更快的速度和更多的proposals;
- 在refinement stage使用了refined 旋转anchors以适应密集场景;
- 设计了特征精细化模块(FRM),利用特征插值获得refined anchor的位置信息,然后对特征图进行重建以实现特征对齐。(改善定位效果)
- 设计了一个近似的SkewIoU损耗来解决SkewIoU计算的不可微问题,从而实现更精确的旋转估计。
2. 相关工作
两级对象探测器。现有的两阶段方法大多是基于proposals 的。在基于proposals 的框架中,第一阶段从图像中生成类别独立的region proposals ,然后从这些proposals 提取特征,然后在第二阶段使用特定类别的分类器和回归器进行分类和回归。最后,采用非最大抑制(NMS)等后处理方法得到检测结果。Faster-RCNN[40]、R-FCN[8]和FPN[27]是两阶段方法中的经典结构,可以以端到端方式快速准确地检测目标。
单级对象探测器。单级检测方法由于其效率高而受到越来越多的关注。OverFeat[43]是最早基于卷积神经网络的单级探测器之一。它以多尺度滑动窗口的方式通过一个单一的向前CNN进行目标检测。与基于proposals 的方法相比,Redmon等人[38]提出了YOLO,一种统一的检测器,将目标检测作为一个从图像像素到空间分离的边界盒和相关类概率的回归问题。为了在不牺牲太多检测精度的情况下保持实时速度,Liu等人提出了SSD[31]。[28]通过提出带Focal loss的RetinaNet网络解决了类不平衡问题。
单级对象探测器。
OverFeat[43] 最早基于卷积神经网络的单级探测器之一。
以多尺度滑动窗口通过一个单一的向前CNN进行目标检测。
[38]YOLO 一种统一的检测器,将目标检测作为一个从图像像素到空间分离的边界盒和相关类概率的回归问题。 SSD[31] 为了在不牺牲太多检测精度的情况下保持实时速度 RetinaNet[28] 带Focal loss的RetinaNet网络解决了类不平衡问题。
旋转对象检测器。遥感、场景文字和零售场景是旋转检测器的主要应用场景。由于遥感图像场景的复杂性和大量的小的、杂乱的、旋转的物体,两级旋转检测器在鲁棒性方面仍占主导地位。其中,ICN [1], ROITransformer [10], SCRDet[54]和Gliding Vertex[50]是最先进的探测器。然而,它们使用了更复杂的结构,造成了速度瓶颈。对于场景文本检测,有许多高效的旋转检测方法,包括两阶段方法(R2CNN [20], RRPN [35], FOTS[32])和单阶段方法(EAST [61], TextBoxes++[25])。对于零售场景检测,DRN[37]和PIoU [6] Loss是最新的两种用于零售场景检测的旋转检测器,并分别提出了两个旋转零售数据集。
旋转对象检测器
遥感图像场景 两级旋转检测器在鲁棒性占主导地位。ICN [1], ROITransformer [10], SCRDet[54]和Gliding Vertex[50]是最先进的探测器。
更复杂的结构,造成了速度瓶颈。
场景文本检测 两阶段方法(R2CNN [20], RRPN [35], FOTS[32])和单阶段方法(EAST [61], TextBoxes++[25])。 零售场景检测 DRN[37]和PIoU [6] Loss是最新的两种用于零售场景检测的旋转检测器,分别提出了两个旋转零售数据集。
原文这个单词Detectiors是不是拼写错误???

精细对象探测器。为了达到更好的,许多级联或精细化探测器被提出。Cascade RCNN[3]、HTC[4]、FSCascade[22]在第二阶段进行了多重分类和回归,大大提高了检测精度。同样的想法也用于单级探测器,如RefineDet[57]。与使用RoI Pooling[13]或RoI Align[15]进行特征对齐的两级检测器不同。目前改进的单级探测器在这方面还不能很好地解决。改进的单级检测器的一个重要要求是保持全卷积结构,这样可以保持速度优势,但RoI Align等方法不能满足这一要求,必须引入全连接层。虽然有一些著作[5,19,56]使用可变形卷积[9]进行特征对齐,但其偏移参数往往是通过学习预定义锚盒与细化锚之间的偏移来获得的。这些基于变形的特征对齐方法过于隐式,不能保证特征是真正对齐的。特征不对齐仍然限制了改进的单级探测器的性能。与这些方法相比,我们的方法可以通过计算清楚地找到对应的特征proposals ,并通过特征图重建达到特征对齐的目的。
(检测精度)许多级联或精细化探测器被提出 Cascade RCNN[3]、HTC[4]、FSCascade[22]在第二阶段进行了多重分类和回归,大大提高了检测精度。 单级探测器 RefineDet[57] 与使用RoI Pooling[13]或RoI Align[15]进行特征对齐的两级检测器不同。
目前改进的单级探测器在这方面(特征对齐)还不能很好地解决。
改进的单级检测器的一个重要要求是保持全卷积结构,这样可以保持速度优势,但RoI Align等方法不能满足这一要求,必须引入全连接层。(从网络结构方面来分析原因,这个需要代码功底。)
[5,19,56] [5,19,56]使用可变形卷积[9]进行特征对齐。
但其偏移参数往往是通过学习预定义锚盒与细化锚之间的偏移来获得的。这些基于变形的特征对齐方法过于隐式,不能保证特征是真正对齐的。
特征不对齐仍然限制了改进的单级探测器的性能。(相关工作角度来分析需要解决的问题。) 我们的方法可以通过计算清楚地找到对应的特征区域,并通过特征图重建达到特征对齐的目的。
3. 提出的方法
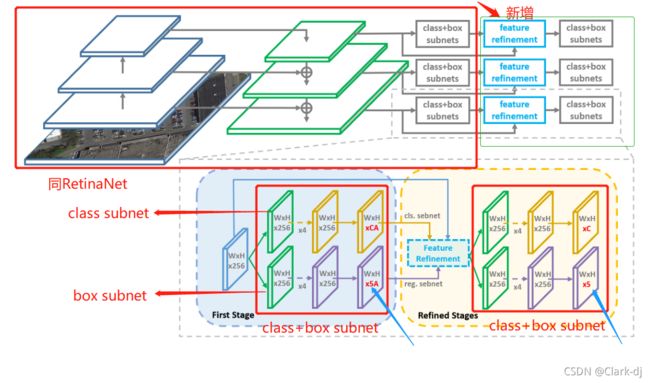
如图1所示,我们概述了我们的方法。实施例是基于RetinaNet[28]的改进的单级旋转检测器,即精细旋转RetinaNet(R3Det)。在网络中加入细化阶段(可添加多次重复)来细化边界框,在细化阶段加入特征细化模块FRM来重构特征图。在单级旋转目标检测任务中,不断细化预测的包围盒可以提高回归精度,而特征细化是实现这一目标的必要过程。
图1:提出的精细化旋转单级检测器((RetinaNet作为实施例)的体系结构。细化阶段可以重复多次。“A”表示每个特征点上锚的数量,“C”表示类别的数量。
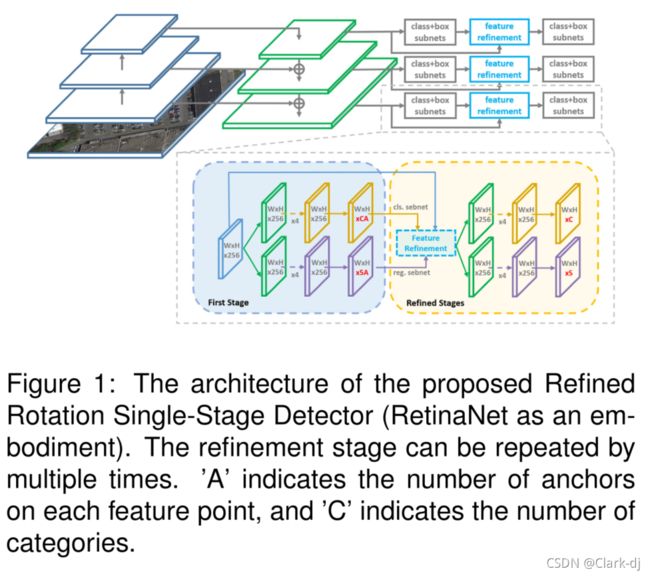
3.1. 旋转RetinaNet
基础设置Base Setting。RetinaNet 是当今最先进的单级探测器之一。它由骨干网、分类网和回归网两部分组成。对于基于RetinaNet的旋转检测,我们使用5个参数(x, y, w, h, θ)来表示任意方向的矩形。在[−π/2,0]范围内,θ表示与x轴的锐角,至于另一边,我们称它为w。因此,需要预测回归子网中一个额外的角偏移,其旋转包围盒为:
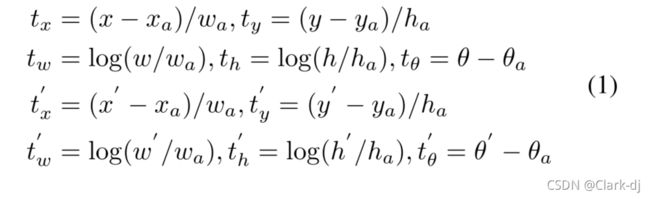
其中x, y, w, h, θ分别表示立方体的中心坐标、宽度、高度和角度。变量x, xa, x'分别代表gt box,锚箱和预测箱(同样适用于y, w, h, θ)。
损失函数。如图2所示,每个框集具有相同的中心点、高度和宽度。两个盒套之间的角度差是相同的,但纵横比是不同的。因此,两组的平滑L1损失值是相同的(主要从角度的差异),但SkewIoU有很大的不同。图3(b)中的红色和橙色箭头表示SkewIoU和平滑L1 Loss之间的不一致。我们可以得出结论,平滑的L1损失函数仍然不适合用于旋转检测,特别是对于大长宽比的物体,这些物体对SkewIoU很敏感。旋转检测的评价指标也以SkewIoU为主。
图2:SkewIoU和Smooth L1 Loss的比较。

IoU相关损失是解决上述问题的有效回归损失函数,已广泛应用于水平检测,如GIoU[41]、DIoU[59]等。但是,两个旋转盒之间的SkewIoU计算函数是不可求的,这意味着我们不能直接使用SkewIoU作为回归损失函数。受SCRDet[54]启发,我们提出了一个可推导的近似SkewIoU损失,多任务损失定义如下:
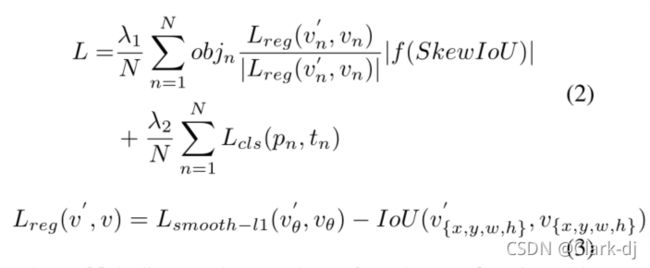
其中N表示锚的数量,objn为二进制值(objn= 1表示前景,dobjn= 0表示背景,没有回归表示背景)。V' 表示预测偏移向量,V表示ground-truth的目标向量。而tn表示对象的标签,pn 表示用sigmoid型函数计算的各类的概率分布。SkewIoU表示预测框与 gt box 的重叠。超参数λ1,λ2控制权衡,默认设置为1。分类损失Lcls使用 focal loss 损失[28]。|.| 用于获取矢量的模,不涉及梯度反向传播,f(.)表示与SkewIoU相关的损失函数,IoU(.)表示水平边界盒IoU计算函数。
与传统的回归损失相比,新的回归损失可以分为两部分: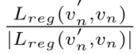 确定梯度传播方向(单位矢量),是保证损失函数可推导的重要组成部分。
确定梯度传播方向(单位矢量),是保证损失函数可推导的重要组成部分。![]() 负责调整损失值(梯度的大小),不需要是可推导的(标量)。考虑到SkewIoU和平滑L1损失之间的不一致性,我们使用方程3作为回归损失的主导梯度函数。通过这样的组合,可以推导出损失函数,而其大小与SkewIoU高度一致。实验表明,基于这种近似SkewIoU损耗的检测器可以获得可观的增益。
负责调整损失值(梯度的大小),不需要是可推导的(标量)。考虑到SkewIoU和平滑L1损失之间的不一致性,我们使用方程3作为回归损失的主导梯度函数。通过这样的组合,可以推导出损失函数,而其大小与SkewIoU高度一致。实验表明,基于这种近似SkewIoU损耗的检测器可以获得可观的增益。
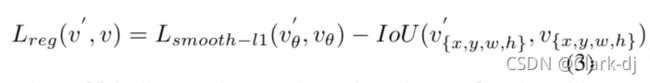
梯度传播方向:保证损失函数可推导的重要组成部分。
调整损失值(梯度的大小),不需要是可推导的(标量)。
3.2. 精细旋转RetinaNet
精细检测。SkewIoU评分对角度的变化非常敏感,轻微的角度偏移会导致IoU评分的快速下降,如图3所示。因此,预测框的细化有助于提高旋转检测的召回率。我们用不同的IoU阈值加入多个细化阶段。除去第一阶段使用前景IoU阈值0.5和背景IoU阈值0.4外,第一细化阶段的阈值分别设置为0.6和0.5。如果有多个细化阶段,其余阈值为0.7和0.6。精细化检测仪的总损失定义如下:

式中,为第i个细化阶段的损失值,权衡系数![]() 默认为1。
默认为1。
功能模块细化。许多精细化的检测器仍然使用同一个feature map进行多重分类和回归,没有考虑边界盒位置变化导致的feature错位。图4(c)描述了没有特征细化的框细化过程,导致特征不准确,这对大宽高比或小样本大小的类别不利。我们提出将当前细化边界框(橙色矩形)的位置信息重新编码到对应的特征点(红色point2),从而以逐像素的方式重构整个特征地图,实现特征对齐。整个过程如图4(d)所示。为了准确获取精炼边界盒对应的位置特征信息,我们采用双线性特征插值方法,如图4(b)所示。特征插值可以表示为:
图4:特征错位的根本原因分析和我们提出的特征细化模块的核心思想
(a)原图
(b)插值特性
(c)由于边界框位置变化而导致的不对齐特征优化框。
(d)重构特征图,细化具有对齐特征的方框。

其中a表示图4(b)中的
,
表示特征图上该点的特征向量。

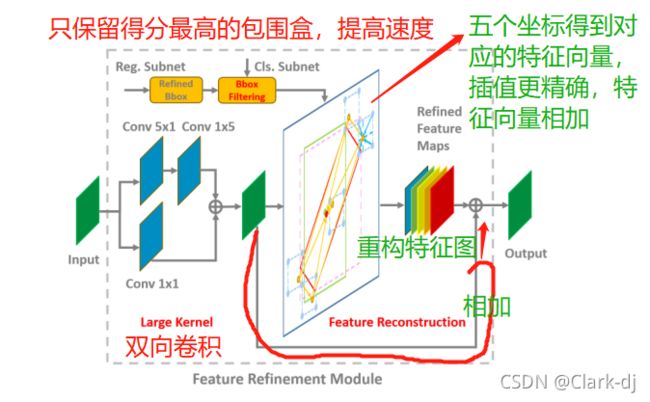
基于上述结果,设计了一个特征细化模块,其结构和伪代码分别如图5和Algorithm3.2所示。具体来说,通过双向卷积来添加feature map,得到一个新的feature (large kernel, LK)。细化阶段只保留每个特征点得分最高的包围盒,以提高速度(框过滤box filtering,BF),同时保证每个特征点只对应一个细化的包围盒。边界盒的滤波是特征重构的必要步骤。对于特征图中的每个特征点,我们根据精炼后的包围盒的五个坐标(一个中心点和四个角点)在特征图上得到对应的特征向量。通过双线性插值得到更精确的特征向量。
我们将这5个特征向量相加,替换当前的特征向量。在遍历特征点后,我们重建整个特征图。最后,将重构后的特征图添加到原始特征图中,完成整个过程。细化阶段可以添加并多次重复。对每个细化阶段的特征重构过程进行仿真如下:
其中
为第i+1阶段的特征图,
分别为第i+1阶段预测的边界框和置信度得分。
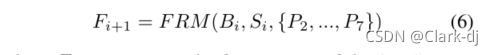
图5:特征细化模块FRM。该算法主要包括精细化边界盒滤波(BF)、大核(LK)和特征重构(FR)三部分。


过程 一步一步的分析问题,一个问题一个问题抛出与解决。
- 通过双向卷积来添加feature map,得到一个新的feature (large kernel, LK)。
- 细化阶段只保留每个特征点得分最高的包围盒,以提高速度(框过滤box filtering,BF),同时保证每个特征点只对应一个细化的包围盒。
- 对于特征图中的每个特征点,我们根据精炼后的包围盒的五个坐标(一个中心点和四个角点)在特征图上得到对应的特征向量。通过双线性插值得到更精确的特征向量。
- 将这5个特征向量相加,替换当前的特征向量。
- 在遍历特征点后,我们重建整个特征图。
- 最后,将重构后的特征图添加到原始特征图中,完成整个过程。细化阶段可以添加并多次重复。
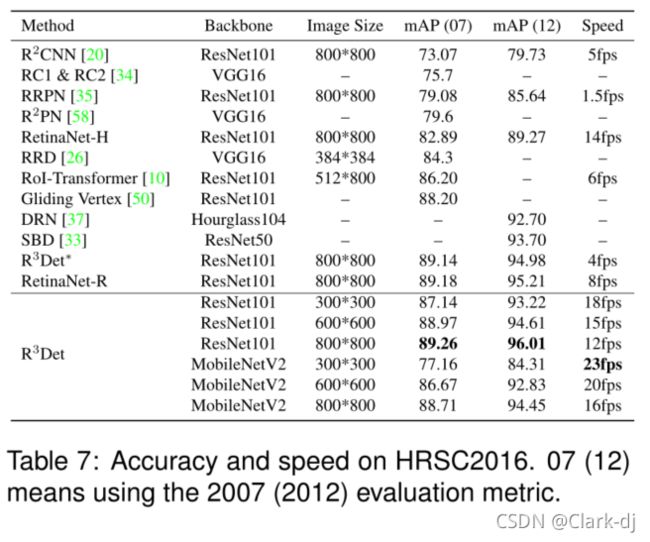
与RoIAlign进行比较讨论。解决FRM中特征不匹配问题的核心是特征重构。FRM与R2CNN、RRPN等许多两级旋转检测器所采用的RoI Align相比,R3Det具有更高的效率,如表7所示。

与其他方法详细对比说明。
1) RoI Align采样点较多(默认值7×7×4 = 196),采样点的减少对探测器性能影响较大。FRM只抽样了五个特征点,大约是RoI Align的四十分之一,这使得FRM具有巨大的速度优势。
2) RoI Align需要在分类和回归之前获取RoI(实例级)对应的特征。FRM首先获取特征点对应的特征,然后重构整个特征图(图像级)。因此,与基于RoI对齐的全连接结构相比,基于FRM的方法可以保持完整的卷积结构,效率更高,参数更少。
第三章提出方法小结
该实例基于RetinaNet(RetinaNet论文理解_JustForYou的博客-CSDN博客_retinanet),网络后增加了refinement stage来对bounding box进行refine,FRM用于重建特征图。
Rotation RetinaNet
该网络为一个先进的one-stage检测器,包括两个部分:backbone网络和分类回归子网络。
- Backbone网络为FPN,FPN通过自上而下的路径和横向连接来增强了卷积网络,从而有效地从单个分辨率的输入图像构建丰富的多尺度特征金字塔,每层金字塔均可以用于不同尺度的目标检测;FPN的每一层均与一个分类回归子网络相连。RetinaNet设计了focal loss来解决类别不平衡问题。
- 分析了平滑的L1损失函数仍然不适合用于旋转检测,特别是对于大长宽比的物体
本文使用(x,y,w,h,theta)五个参数表述旋转矩形,theta表示与x轴的锐角,变化范围为[-90,0),另一侧为w。因此,需要预测子网络中的附加角度偏移:
上式中,x,y,w,h,theta表示box的重心坐标,宽、高和角度;x.x_a.x'分别为ground-truth,anchor box和预测box。可推导的近似SkewIoU损失,多类别的损失函数定义如下:
Refined Rotation RetinaNet
在不同的refinement stage中使用了不同的IoU阈值;在first stage前景(foreground)和背景(background)的阈值分别为0.5和0.4,first refinement stage二者分别使用了0.5和0.4,如果refinement stage重复了多次,剩余的分别为0.7和0.6。Refine detector的总体损失为:
Li为第i个refinement阶段的损失,ai为权衡系数,默认为1.
Feature Refinment Module
许多refined 检测器使用相同的特征映射进行多个分类和回归,没有考虑边界框位置变化引起的特征偏移,对长宽比较大或者样本量小的类别不利。本文提出将refined边界框的位置信息重新编码到响应的特征点,从而重建整个特征映射,实现特征对齐。
- 通过双向卷积来添加feature map,得到一个新的feature (large kernel, LK)。
- 细化阶段只保留每个特征点得分最高的包围盒,以提高速度(框过滤box filtering,BF),同时保证每个特征点只对应一个细化的包围盒。
- 对于特征图中的每个特征点,我们根据精炼后的包围盒的五个坐标(一个中心点和四个角点)在特征图上得到对应的特征向量。通过双线性插值得到更精确的特征向量。
- 将这5个特征向量相加,替换当前的特征向量。
- 在遍历特征点后,我们重建整个特征图。
- 最后,将重构后的特征图添加到原始特征图中,完成整个过程。细化阶段可以添加并多次重复。
特征插值公式为:



4. 实验
4.1. 数据和规范
DOTA[49]公共数据集由来自不同传感器和平台的2806张大型航空图像组成。DOTA中的对象呈现出各种各样的比例、方向和形状。这些图像然后由专家使用15个对象类别进行注释。分类的简称被定义为(缩写-全名):PL-Plane、BD-Baseball diamond、BR-Bridge、GTF-Ground田径场、SV-Small vehicle、LV-Large vehicle、SH-Ship、tc -网球场、BC-Basketball court、ST-Storage tank、sbf - soccer field、RA-Roundabout、HA-Harbor、SPSwimming pool、HC-Helicopter。完全注释的DOTA基准包含188,282个实例,每个实例都用任意四边形标记。DOTA有两个检测任务:水平包围盒(HBB)和方向包围盒(OBB)。随机选取原始图像的一半作为训练集,1/6作为验证集,1/3作为测试集。我们将150像素重叠的图像分割为600×600,并将其缩放为800×800。通过所有这些过程,我们获得大约27,000个patches。
HRSC2016数据集[34]包含两种场景的图像,包括海上船只和近海船只。所有的图片都是从六个著名的港口收集来的。图像大小范围从300×300到1,500×900。训练集、验证集和测试集分别包含436幅图像、181幅图像和444幅图像。
ICDAR2015[21]被用于ICDAR2015稳健阅读竞赛的第四项挑战。总共有1500张图片,其中1000张用于培训,剩下的用于测试。文本区域由四边形的4个顶点标注。
UCAS-AOD[62]包含近似659×1,280像素的1510幅航拍图像,两类共14596个实例。根据[1,49],我们随机抽取1110个进行训练,400人进行测试。
对于所有数据集,模型总共训练了20个epoch, 12个epoch和16个epoch的学习率分别降低了10倍。RetinaNet的初始学习速率是5e-4。DOTA、ICDAR2015、HRSC2016和UCAS-AOD的每历元图像迭代次数分别为54k、10k、5k和5k,如果使用数据增强和多尺度训练,则每历元图像迭代次数增加一倍。本文中的实验除非另有说明,默认使用ResNet50[16]进行初始化。重量衰减为0.0001,动量为0.9。我们在4个GPU上使用Momentum 优化器,每迷你批处理(minibatch)4张图像(每GPU 1张图像)。在P3 ~ P7金字塔层,锚点的面积分别为322 ~ 5122。在每个金字塔级别,我们使用七个宽高比{1,1/2,2,1/3,3,5,1/5}和三个尺度![]() 的锚。我们还添加了6个角度{−90◦,−75◦,−60◦,−45◦,−30◦,−15◦}旋转锚基于方法(RetinaNet-R)。
的锚。我们还添加了6个角度{−90◦,−75◦,−60◦,−45◦,−30◦,−15◦}旋转锚基于方法(RetinaNet-R)。
4.2. 健壮的基线的方法
在本文中,我们使用三个具有不同锚定设置的稳健基线模型。
ReitnaNet-H:水平锚的优点是可以使用较少的锚,但通过用 ground truth 的水平外延矩形计算IoU可以匹配更多的正样本,但引入了大量的非物体或其他物体的区域。对于长宽比较大的物体,其预测旋转包围盒往往不准确,如图6(d)所示。
ReitnaNet-R:相比之下,在图6(e)中,旋转锚通过添加角度参数避免了噪声区域的引入,在密集场景中具有更好的检测性能。然而,在本文中锚的数量增加了6倍左右,使得模型的效率较低。
R3Det∗:这是一个未经改进的精细化检测器。考虑到原始锚的数量决定了模型的速度,我们采用由粗到细的逐步回归形式。具体来说,我们首先在第一阶段使用水平锚来减少锚的数量,提高对象召回率,然后在后续阶段使用旋转精炼锚来克服密集场景带来的问题,如图6(f)所示。
图6:在DOTA上的可视化。这里的“H”和“R”分别表示水平锚和旋转锚。
根据表1,RetinaNet-H 和RetinaNet-R总体mAP相似(62.79% vs 62.76%),但有各自的特点。基于水平锚的方法在速度上具有明显的优势,而基于旋转锚的方法在密集目标场景和大纵横比对象(如小型车辆、大型车辆和船舶)中具有更好的回归能力。R3Det∗达到63.52%的性能,优于RetinaNet-H 和RetinaNet-R。虽然密集和大纵横比的范畴有了很大的改进,但仍然不如RetinaNet-R(如LV和SH)。RetianNet-R在这方面的优势也将反映在表7中。
表7: HRSC2016的准确性和速度。07(12)表示使用2007(2012)评价指标。
4.3. 消融研究
功能模块细化。
细化阶段的数量。
近似SkewIoU损失。
4.4. 与最先进技术的比较
Results on DOTA.
Results on HRSC2016 and UCAS-AOD.
5. 结论
我们提出了一种端到端精细化的单级检测器,用于大纵横比、密集分布和任意方向的旋转物体,这在实际中很常见,如航空、零售和场景文本图像。针对目前精细化的单级检测器存在的特征不匹配的缺点,设计了特征精细化模块来提高检测性能。FRM的核心思想是通过逐像素的特征插值,将当前精细化边界框的位置信息重新编码到相应的特征点,实现特征重构和对齐。为了更精确的旋转估计,提出了一种近似的SkewIoU损耗来解决SkewIoU的计算无法导出的问题。我们在DOTA、HRSC2016、UCASAOD和ICDAR2015等多个旋转检测数据集上进行了细致的消融研究和对比实验,证明了我们的方法能够高效地实现最先进的检测精度。
结论也是针对提出的问题以及解决方案描述,结论会更详细一些,有些表达会有些不同。
6. 补充材料
6.1. Speed Comparison
6.2. Results on ICDAR2015
6.3. FRM is Suitable for Rotation Detection(FRM适用于旋转检测)
6.4. Training Loss Curve
6.5. Visualization on Different Datasets