MMDetection框架入门教程(二):快速上手教程

本人是从Tensorflow过来的,刚开始接触到MMDetection框架是有点懵的,因为这个框架在Pytorch基础上封装了好几层,这么做的好处是模块之间的耦合度很低,改动起来非常方便,但坏处是对于我这样的新手(对Pytorch也不甚了解),乍一看很难理解整个框架的运行流程,甚至都不知道如何查看对应的源码,更别说是从头搭建自己的网络了。
在网上搜罗了很大一圈,强力推荐B站西安交大的这个讲解视频,对于新手十分友好,把MMDetection如何使用讲的很清楚。本文结合OpenMMLab官方公众号的教程,对视频内容进行了归纳和扩展,希望能帮助到和我一样迷茫的初学者。
- B站 - mmdetection使用教程
- 知乎 - 轻松掌握MMDetection整体构建流程(一)
- 知乎 - 轻松掌握 MMDetection整体构建流程(二)
- 知乎 - 轻松掌握MMDetection中常用算法(一):RetinaNet及配置详解
- 官方说明文档 - MMDetection Tutorial
1. MMDetection是什么
MMDetection是OpenMMLab家族中的一员,主要负责2D目标检测领域(比如MMDetection3D则负责3D目标检测)。首先我们需要知道为什么会出现MMDetection这个框架。当前目标检测算法众多,方法复杂,细节较多,个人复现起来难度很大,而且由于缺少共享平台和统一规范,就算有人成功实现了某一个算法,也很难被其他人复用。
于是商汤和港中文大学集中了一批人,使用统一的代码规范复现了当前大部分主流和前沿的模型,比如Faster R-CNN系列、YOLO系列,以及较新的DETR等(如下图所示),并提供了预训练模型。其他人只需要遵循这个规范,就能直接“白嫖”,不需要自己再重新实现一遍,而这个规范就是MMDetection。在丰富模型的基础上,MMDetection还支持自定义的扩展,可以在已有模型上进行修改,也可以自己从头搭建一个全新的模型,基本可以满足学术研究和工业落地的需求。

2. 整体算法流程
所有的目标检测算法都可以按照训练和测试流程抽象成若干个模块,对于初学者来说只要理解各个模块的输入输出以及实现的功能即可,本篇博客不会进行展开,模块内部的实现逻辑之后会单独开博客分析。这个流程也对应框架的代码构建流程,所以理解这副图很重要。
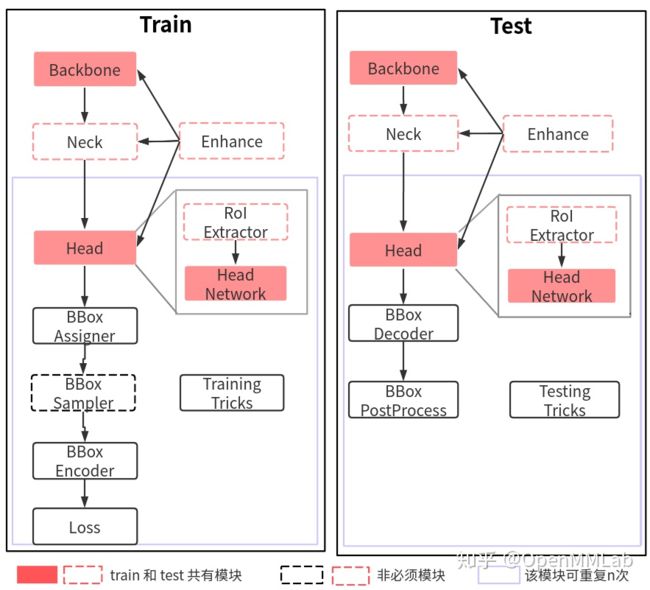
2.1 训练流程
训练流程包含9个核心组件,但不是每个算法都需要,具体如下表所示。
| 模块名称 | 必需 | 功能 |
|---|---|---|
| Backbone | 是 | 【特征提取】比如ResNet系列 |
| Neck | 否 | 【特征增强】对Backbone的特征进行融合和增强,比如FPN |
| Head | 是 | 【特征解码】目标检测网络最重要的部分,Head对特征图进行解码,得到算法期望的输出,比如目标框的类别和坐标,按照one-stage和two-stage可以分为DenseHead和RoIHead |
| BBox Assigner | 是 | 【正负样本分配】由于检测网络输出的目标个数和真值目标大多数情况下是不匹配的,因此首先要进行正负样本分配,不同的正负样本分配策略会带来显著的性能差异,该模块至关重要 |
| BBox Sampler | 否 | 【正负样本平衡】一般目标检测中真值目标个数都是非常少的,正负样本比远小于1,为了避免数据极度不平衡引起的过拟合,需要适当对正负样本进行采样,平衡正负样本的数量 |
| BBox Encoder | 是 | 【编码变换】为了更好的收敛和平衡过个loss,将网络输出结果进行特定的编码变换,比如归一化,Encoder的输出可以认为是模型前向过程的最终输出 |
| Loss | 是 | 【Loss计算】检测网络一般分为分类loss和回归loss,提供模型迭代优化的依据 |
| Enhance | 否 | 【特征增强】一般指即插即用、能够对特征进行增强的模块,比如Dropout、Dropblock等 |
| Training Tricks | 否 | 【训练技巧】即我们熟知的模型调参方法,比如早停、学习率调整等 |
2.2 测试流程
相较于训练流程,测试时只有模型的前向推理过程,因此不需要正负样本分配、平衡、计算loss等操作,流程会更简单一些。下表是测试流程特有的模块。
| 模块名称 | 必需 | 功能 |
|---|---|---|
| BBox Decoder | 是 | 【解码变换】对应测试流程中的BBox Encoder模块,训练时怎么对目标进行编码,测试时就怎么进行解码 |
| BBox PostProcess | 是 | 【后处理】得到目标框后,可能会出现重叠情况,所以一般需要根据IOU或置信度对输出目标进行处理,最常用到的是NMS方法 |
| Training Tricks | 否 | 【测试技巧】比如模型集成、多尺度测试等 |
3. 算法搭建流程
以训练流程为例,对于Tensorflow和Pytorch,我们需要编写数据读取、数据预处理、数据增强、算法模型、loss函数、训练策略的代码,最后将其整合进train()函数中开始训练,过程十分繁琐。由于MMDetection已经实现了上述步骤中的绝大部分方法,我们只需要调用现成的函数即可,具体是在Config文件中配置好相应方法的参数,并将Config文件传给MMDetection自带的train()函数,然后框架就会解析Config文件,自动调用配置好的方法,完成训练流程。所以在MMDetection上搭建一个算法,我们要做的事情只有3件:准备数据集、编写Config文件、调用框架自带的train.py开始训练。

我们先从MMDetection自带的RetinaNet开始,在COCO数据集上打通训练和测试流程。
3.1 准备数据集
MMDetection已经实现了COCO数据集的处理,我们这里就直接使用COCO 2014数据集。下载好的数据集目录结构如下图所示,annotations文件夹中以json文件格式存放了标注数据,其中目标框的标注信息在instances文件中。

3.2 编写Config文件
RetinaNet的配置文件位于MMDetection源码的./configs/retinanet路径下,打开目录会发现里面有很多Config文件,文件命名规则遵循:
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
其中大括号表示必选,大括号表示可选。比如我们接下来要使用的配置文件retinanet_r50_fpn_1x_coco.py含义就是:模型名称是RetinaNet,主干是ResNet50,Neck是FPN,训练12个Epoch(1个x是12,2个x就是24),使用COCO数据集。更详细的字段说明可以在官方说明文档中查阅。
但当我们打开配置文件retinanet_r50_fpn_1x_coco.py时,发现里面只有几行代码:
_base_ = [
'../_base_/models/retinanet_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
其实MMDetection中配置文件是通过继承 + 修改的方式完成用户自定义配置文件的。配置文件开头的_base_ = list()表示你需要继承的配置文件,然后通过重写的方式完成对应属性的修改。如果想要查看完整的配置文件信息,不需要依据_base_一级一级往上查找,可以通过官方给定的工具./tools/misc/print_config.py来打印配置文件:
python ./tools/misc/print_config.py ./configs/retinanet/retinanet_r50_fpn_1x_coco.py
然后就可以看到retinanet_r50_fpn_1x_coco.py对应的完整的配置文件内容,第二节提到的各个模块都可以在配置文件中找到对应的定义。配置文件由一串字典dict和变量的定义组成,经由Config.fromfile(filepath)函数加载后会返回一个Config类型的变量(MMCV的一个数据结构),然后MMDetection框架就能根据这个Config调用相关的build_detector()方法构建对应的模块。
具体地,build_detector()方法首先会根据字典中的type找到对应的类(Class),这个类的类名就是type字符串的值,且这个类一定是事先注册(Registry) 好的,MMDetection能够根据type值查询到具体的类,否则就会报错。比如在下面配置文件中,model的type值为RetinaNet,我们可以在./mmdet/models/detectors/retinanet.py中找到定义。
@DETECTORS.register_module() # 表示这个类已经注册
class RetinaNet(SingleStageDetector):
"""Implementation of `RetinaNet `_"""
def __init__(self,
backbone,
neck,
bbox_head,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(RetinaNet, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained, init_cfg)
我们可以发现RetinaNet类构造函数的参数刚好和配置文件中type='RetinaNet'的字典的其他键值对应。所以build_detector()函数的作用就是根据dict中的type找到对应的类,然后使用dict中传入的参数来对类进行初始化操作,并返回这个类的句柄。
# 下面两行调用是等价的
model = build_detector(Config{type='RetinaNet', backbone=xxx, neck=xxx, bbox_head=xxx})
model = RetinaNet(backbone=xxx, neck=xxx, bbox_head=xxx)
然后配置文件中的dict是可以嵌套的,比如说model的backbone属性是type='ResNet'一个字典,同理我们也可以在./mmdet/models/backbones/resnet.py中找到ResNet类的定义,并且字典的键值和构造函数匹配。
@BACKBONES.register_module()
class ResNet(BaseModule):
"""ResNet backbone."""
def __init__(self,
depth,
in_channels=3,
stem_channels=None,
base_channels=64,
num_stages=4,
strides=(1, 2, 2, 2),
dilations=(1, 1, 1, 1),
out_indices=(0, 1, 2, 3),
style='pytorch',
deep_stem=False,
avg_down=False,
frozen_stages=-1,
conv_cfg=None,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
dcn=None,
stage_with_dcn=(False, False, False, False),
plugins=None,
with_cp=False,
zero_init_residual=True,
pretrained=None,
init_cfg=None):
super(ResNet, self).__init__(init_cfg)
self.zero_init_residual = zero_init_residual
if depth not in self.arch_settings:
raise KeyError(f'invalid depth {depth} for resnet')
下面是retinanet_r50_fpn_1x_coco.py完整的配置文件信息。
Config:
# 1. 模型配置
model = dict(
type='RetinaNet', # 模型名称
# 1.1 Backbone配置
backbone=dict(
type='ResNet', # Backbone使用ResNet50(4阶段,50层)
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3), # 输出ResNet50第1~4阶段的feature map,供后续FPN做多尺度特征融合
frozen_stages=1, # 由于使用了预训练模型,冻结ResNet50第一阶段的网络参数,不参与训练过程
norm_cfg=dict(type='BN', requires_grad=True), # 归一化层配置
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')), # 使用pytorch提供的ResNet50在ImageNet上的预训练模型
# 1.2 Neck配置
neck=dict(
type='FPN', # Neck使用FPN
in_channels=[256, 512, 1024, 2048], # 输入通道数对应resnet50四个阶段feature map的维度
out_channels=256, # 输出特征维度为256
start_level=1, # 从Backbone的第一阶段特征图开始
add_extra_convs='on_input',
num_outs=5),
# 1.3 Head配置
bbox_head=dict(
type='RetinaHead', # Head使用RetinaHead
num_classes=80, # COCO数据集包含80类目标
in_channels=256, # FPN层输出特征维度为256
stacked_convs=4,
feat_channels=256,
# 1.3.1 Retina是Anchor-Based方法, 需要生成Anchor
anchor_generator=dict(
type='AnchorGenerator',
octave_base_scale=4,
scales_per_octave=3,
ratios=[0.5, 1.0, 2.0],
strides=[8, 16, 32, 64, 128]),
# 1.3.2 BBox Encoder配置
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
# 1.3.3 分类Loss函数
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
# 1.3.4 回归Loss函数
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
# 1.4 训练配置
train_cfg=dict(
# 1.4.1 BBox Assigner
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
allowed_border=-1,
pos_weight=-1,
debug=False),
# 1.5 测试配置
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100))
# 2. 数据配置
data = dict(
samples_per_gpu=2, # batch_size大小
workers_per_gpu=2, # 训练GPU数量
# 2.1 训练集配置
train=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_train2017.json',
img_prefix='data/coco/train2017/',
# 数据预处理步骤
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]),
# 2.2 验证集配置
val=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
# 2.3 测试集配置
test=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
# evalution hook配置
evaluation = dict(interval=1, metric='bbox')
# 优化器配置
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
# optimizer hook配置
optimizer_config = dict(grad_clip=None)
# 学习率配置
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
# Runner配置
runner = dict(type='EpochBasedRunner', max_epochs=12)
# checkpoint配置
checkpoint_config = dict(interval=1)
# logger hook配置
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
# 自定义hook配置
custom_hooks = [dict(type='NumClassCheckHook')]
# 分布式训练配置
dist_params = dict(backend='nccl')
# 日志级别
log_level = 'INFO'
# 预训练模型路径
load_from = None
# 模型断点
resume_from = None
# Runner的工作流
workflow = [('train', 1)]
从配置文件可以看到,当前默认从pytorch官网下载预训练模型,且数据集的路径以及GPU数目和我当前的不符,而且由于电脑内存有限,我不希望每个epoch都保存一次checkpoint,所以我新建了一个配置文件my_retinanet_r50_fpn.py继承了官方的配置文件,并进行了一些修改:
_base_ = [
'D:/Program Files/OpenSourceLib/mmdetection/configs/retinanet/retinanet_r50_fpn_1x_coco.py'
]
model = dict(
backbone=dict(
init_cfg=None) # 不再直接从官网下载预训练模型,使用我自己下载好的预训练模型
)
data = dict(
samples_per_gpu=2, # batch_size=2
workers_per_gpu=1, # 1个GPU
train=dict(
type='CocoDataset',
ann_file='E:/Dataset/COCO2014/annotations/instances_train2014.json', # 修改数据集路径
img_prefix='E:/Dataset/COCO2014/train2014'),
val=dict(
type='CocoDataset',
ann_file='E:/Dataset/COCO2014/annotations/instances_val2014.json',
img_prefix='E:/Dataset/COCO2014/val2014/'),
test=dict(
type='CocoDataset',
ann_file='E:/Dataset/COCO2014/annotations/instances_val2014.json',
img_prefix='E:/Dataset/COCO2014/val2014/')
)
evaluation = dict(interval=12, metric='bbox') # 12个epoch进行一次评估
checkpoint_config = dict(interval=2) # 2个epoch保存一次checkpoint
load_from = '../ckpts/resnet50-0676ba61.pth' # 自己下载的预训练模型路径
3.3 训练网络
写完配置文件后,就可以直接调用./tools/train.py指定配置文件进行训练。train.py包含了模型配置、数据集配置、训练配置、Hook配置等的解析,以及根据配置信息构造训练,用户的自定义操作可以通过Hook进行配置,一般无需修改train.py文件。
python train.py my_retinanet_r50_fpn.py
成功开始训练:

4. 总结
本文利用MMDetection已经实现的RetinaNet模型在COCO上进行训练作为示例,演示了MMDetection的模型训练流程。总的来说分为三个步骤:
- 准备数据集
- 准备配置文件:配置文件由一系列dict组成,dict中的
type键值代表注册的类别,build函数可以通过识别dict中的type来初始化对应的类。配置文件一般会继承一个通用配置文件,然后在此基础上根据需求调整。 - 开始训练:调用MMDetection自带的
train.py进行训练。
如果需要构建自己的模型,则需要实现一个类然后进行注册,Registry和Hook的机制见下一篇博客。