论文阅读《Representation learning with contrastive predictive coding 》(CPC)对比预测编码
论文地址:Representation Learning with Contrastive Predictive Coding
目录
一、Background(背景)
二、Motivation and Intuitions(动机)
三、Constrastive Predictive Coding(对比预测编码)
1、网络整体架构
2、对比学习核心思想
四、Mutual Informatica&Info NCE(互信息和信息熵损失)
1、互信息
2、InfoNCE
五、result(实验结果)
论文地址:https://arxiv.org/pdf/1807.03748.pdf
一、Background(背景)
虽然监督学习在许多应用中取得了巨大的进展,但无监督学习尚未得到如此广泛的采用,仍然是人工智能领域的一个重要和具有挑战性的工作。这篇文章是自监督学习领域的一篇挺不错的文章,非常值得阅读。
这篇文章基于对比学习的思想,在视频序列上做自监督学习。在文章中,作者提出一种通用的无监督学习框架,其目的是从高维序列数据中提取有用的表征信息(Representation),将在上下文中提取到的表征信息和未来时刻样本的表征信息进行对比学习,获得最能预测未来的关键表征信息,称之为CPC (Contrastive Predictive Coding)
算法核心:1、通过自回归模型来预测未来的隐变量表示。2、通过优化InfoNCE Loss来最大化上下文信息和预测时刻序列的互信息,提取历史信息和未来信息互相依赖的部分,这样的表征能贯穿整个序列,具有较强的语义性和全局鲁棒性。
在文中证明了该方法能够学习有用的特征表示,并在语音、图像、文本和3D环境中的强化学习中都取得不错的效果。
二、Motivation and Intuitions(动机)
从信息瓶颈理论的角度来讲,CPC是为了保留任务相关的有用信息,目的是丢弃底层噪声和任务无关的无用信息。这样的任务往往很难实现,因为通常任务相关的信息和噪声很难解耦,想要从信息中分离出有用信息,剔除任务无关的噪声信息,也是本文最主要的目的。
在模型学习中,如果直接预测未来样本的全部信息,用一个强大的生成模型对未来预测样本的的每个细节进行重建,需要很大的计算量,往往也会忽略样本中上下文关系,这样的做法也是没必要的,因为要识别一张钞票是不是一张钞票,并不需要我们可以完全画出一张一模一样的钞票,我们只需要记住钞票的一些关键性特征就可以识别一张钞票。
因此,只是为了提取x与c之间的共享信息,直接建模p(x|c)并不是最优的,直接建模会导致计算量过大,模型过多关注于噪声信息和任务无关信息,比如图片的背景。在文章中,用当前的信息预测未来信息时,将预测目标x和上下文c编码成一个紧凑的分布向量表示,最大化x与上下文c之间的互信息(mutual Information)。下面是互信息的表达式:

互信息可以表示两个随机变量之间的相互依赖程度,从下面的公式中可以看出,X与Y的互信息就是观察到Y之后,X的不确定性的减少,也就是给定Y之后X信息量的减少,互信息可以描述随机变量之间高阶的相关程度。
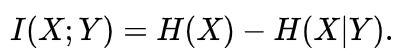
三、Constrastive Predictive Coding(对比预测编码)
网络整体架构

上图是本文最重要的结构图,首先将视频或者音频序列切分为合适的序列片段(下面用视频序列为例讲解),首先将视频片段用非线性编码器Auto Encoder或CNN映射到隐空间z中。
![]()
得到历史片段的编码之后,使用自回归模型GRU或者LSTM来融合历史时序信息z,得到历史信息的特征融合向量c
![]()
仔细观察互信息的表达式,可以发现互信息的表达式中含有x和c的联合分布,实际上预测样本和上下文信息c的联合分布无法获得,作者用神经网络来拟合互信息函数,具体的讲解在后面。

最后作者使用InfoNCE作为损失函数,来优化模型,使得x与c之间的互信息最大。
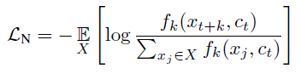
对比学习核心思想
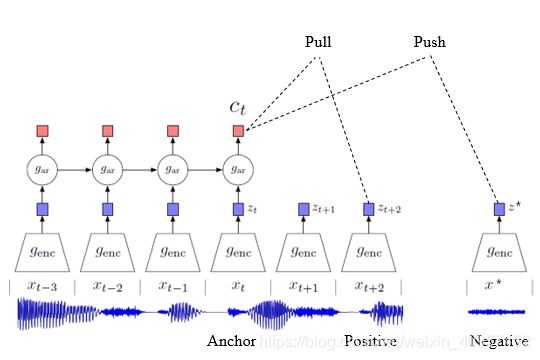
这篇文章是基于对比学习的思想来做时序预测,对比学习的核心就是找到一个合适的编码,将原始特征编码到隐藏空间,使得正样本对之间的距离近,负样本对之间的距离远。对比学习会选用一个anchor,一个正样本和anchor形成正样本对,一个负样本和anchor形成负样本对。在这篇文章中,anchor为历史的时序编码经过自回归模型的输出c,正样本为该视频的未来一个采样序列的编码![]() ,负样本为随机从其他视频采样的一个序列片段的编码
,负样本为随机从其他视频采样的一个序列片段的编码![]() 。
。
模型的目标是拉进c与![]() 的距离,推远c与
的距离,推远c与![]() 的距离,为何通过这样的做法就等价于最大化c 与
的距离,为何通过这样的做法就等价于最大化c 与![]() 之间的互信息呢,后面会有讲解,这里先记住这个概念。
之间的互信息呢,后面会有讲解,这里先记住这个概念。
四、Mutual Informatica&Info NCE(互信息和信息熵损失)
互信息
互信息(mutual information)就是表示两个变量之间的相关性,I(X;Y)表示X与Y的互信息。

X与Y的互信息表示由于Y的引入而导致X熵的减小,也就是X的不确定度的减小的量。在论文中,作者通过最大化I(x|c)来使得模型充分学习现在上下文c的信息来使得未来x的不确定性减小,从而起到预测效果。

如果用当前的c去预测k个时刻之后的![]() ,作者没有采用生成模型
,作者没有采用生成模型![]() 来预测未来的样本,而是最大化
来预测未来的样本,而是最大化![]() 与c之间的互信息,从而使得预测的
与c之间的互信息,从而使得预测的![]() 与真实值
与真实值![]() 尽可能相似。
尽可能相似。

从互信息的表达式中可以看出,计算互信息需要得到x与c之间的联合分布概率,实际中很难计算这个联合分布,为此,将互信息看作是关于联合分布![]() 求
求![]() 的期望,最大化互信息,也就是最大化
的期望,最大化互信息,也就是最大化![]() 关于联合分布
关于联合分布![]() 的期望值。
的期望值。
为何对比学习的做法可以等价于优化互信息(噪声对比估计(NCE)):

可以这样理解:通过对比学习的方式来训练,这个模型现在做的事是,给定一个batch为N个样本,其中只有第i个样本为正样本,其余N-1个都为负样本,模型能分辨出哪个样本是正样本,也就是公式左边的给定X和![]() ,模型能正确将第i个样本是正样本,我们要使得这个概率最大化。右式分子代表采样N个样本,其中第i个为正样本,其余为负样本的概率。右式分母表示随机一个为正样本的概率之和。为此,右式的分子就是互信息中的
,模型能正确将第i个样本是正样本,我们要使得这个概率最大化。右式分子代表采样N个样本,其中第i个为正样本,其余为负样本的概率。右式分母表示随机一个为正样本的概率之和。为此,右式的分子就是互信息中的![]() 项。为此模型能正确分辨出第i个样本是正样本,就是在最大化分子,也就是最大化互信息。
项。为此模型能正确分辨出第i个样本是正样本,就是在最大化分子,也就是最大化互信息。
为此,只要找到一个函数来衡量 ![]() 的大小,就可以间接衡量了x和c之间的互信息的大小,直观上,x与c之间的互信息越大,代表从
的大小,就可以间接衡量了x和c之间的互信息的大小,直观上,x与c之间的互信息越大,代表从![]() 采样得到
采样得到![]() 的概率大于从一个随机分布
的概率大于从一个随机分布![]() 中采样
中采样![]() 的概率,在文章中作者采用线性矩阵W乘以
的概率,在文章中作者采用线性矩阵W乘以![]() 作为预测值,而
作为预测值,而 ![]() 为真实值,即用以下式子来衡量相似度,代码实现中是采用神经网络来拟合互信息函数。
为真实值,即用以下式子来衡量相似度,代码实现中是采用神经网络来拟合互信息函数。


InfoNCE
通过上面的分析,已经建立了最大化互信息,就可以使得样本正确识别出正样本,如何证明优化损失函数InfoNCE就是在优化互信息。
作者对互信息的公式进行分析,得到了互信息的下界,互信息的下界的相反数为InfoNCE Loss,也就是最小化InfoNCE Loss来最大化互信息的下界,从而使得互信息最大。从下面式子中也可以看出,想要得到更好的优化效果,需要N的值尽量大,也就是batch_szie尽量大。


![]()

五、result(实验结果)
将CPC网络应用于语音、文本,通过不同的步长来采样正样本,负样本从不同的序列中随机采样得到。图二表示的是CPC经过学习之后得到的特征分布,能够很好地将不同类样本分开,图三表示预测不同步长的语音结果,从图中可以看出预测的值越远,准确率越低。


从表格1可以看出,CPC的性能,在不同数据集上可以很接近有监督学习的效果。

将CPC应用于图像任务中,采用overlap的形式对图像进行切分,然后用前面几个patch来预测后面几个patch的信息,相对视频和语音数据集而言,图片预测的效果并没有那么好,个人觉得可能是图片切分之后,有些patch含有的噪声过多,而前面patch和后面patch之间的互信息很难最大化。


以上就是这篇CPC的分享内容,第一次写博客,如果有错误的地方,烦请大家指正,谢谢。