dataframe两个表合并_pandas ---处理非数值型的数据 DataFrame篇
1:DataFrame创建
1:DataFrame创建:pd.DataFrame
import numpy as np
t=pd.DataFrame(np.arange(12).reshape((3,4)))

2:DataFrame创建,并指定行列索引
t=pd.DataFrame(np.arange(12).reshape(3,4),index=list('abc'),columns=list('wxyz'))

t
3:通过字典的方式创建DataFrame数组
第一种方式
d1={"name":["xiaoming","xiaogang"],"age":[15,67],"tel":[10086,10010]}
t1=pd.DataFrame(d1)
t1

第二种方式
d2=[{"name":"xiaoming","age":18,"tel":10086},{"name":"xiaogang","tel":10086},{"name":"xiaowang","age":22}]
t2=pd.DataFrame(d2)
t2

2:DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
3:DataFrame基础属性
1:列的索引 行的索引
t2.columns
t2.index

2:对象值
t2.values

3:查看时几行几列的数据,行数 列数
t2.shape

4:查看每一列的数据类型
t2.dtypes

5:查看当前数据的维度 当前时2维的
t2.ndim

4:DataFrame整体情况查询
1:显示前几行的数据,默认5行
t2.head(2)

2:显示后几行的数据,默认5行
t2.tail(1)

3:相关信息的概览:行数 列数,列索引,列非空个数,列类型,内存占用
# t2.info()

4:快速综合统计结果
t2.describe()

5:排序,ascending=False是倒叙 默认是正序
df.sort_values(by="Count_AnimalName",ascending=False)


5:pandas取行或者列的注意点
1:方括号里面写数字,表示取行, 对行进行操作
t2[:2]

2:方括号里面写字符串,表示取列, 对列进行操作
t2["name"]#得到的是Seeies类型数据
type(t2["name"])

3:取行取列同时操作:
t2[:2]["name"]

6:pandas之loc
1: df.loc通过"标签"索引行数据
1:取a行z列的值 得到的是一个数
t3.loc["a","z"]
type(t3.loc["a","z"])

2:取a行的值
t3.loc["a"]

3:取y列的值
t3.loc[:,"y"]
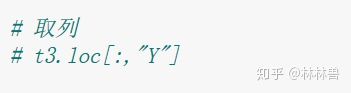
4:取不连续的多行的值
t3.loc[["a","c"],:]
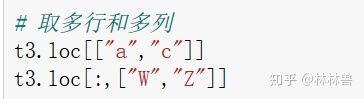
5:取不连续的多列的值
t3.loc[:,["w","z"]]

6:取不连续的行和不连续的列的值
t3.loc[["a","c"],["w","z"]]

7:df.iloc通过"位置"获取行数据
1: 取第二行的值
t3.iloc[1,:]

2: 取第三列的值
t3.iloc[:,2]

3: 取第三列和第二列的数据
t3.iloc[:,[2,1]]

4: 取第一行第三行的数据 和第三列和第二列的数据
t3.iloc[[0,2],[2,1]]

5: 取第一行之后的每一行 第二列之前的每一列
t3.iloc[1:,:2]=30
t3.iloc[1:,:2]

8:pandas 布尔索引
& 表示且 |表示 注意:不同的条件之间需要用()扣起来
1:取狗的名字使用次数大于800 小于1000的数据 & 表示且 |表示 中间需要用()
df[(df['Count_AnimalName']>800)&(df['Count_AnimalName']<1000)]
2:取狗的名字长度大于4 且使用次数大于700的数据 str方法
df[(df["Row_Labels"].str.len()>4)&(df["Count_AnimalName"]>700)]

9:pandas字符串方法:
1: cat:实现元素级的字符串链接操作,可指定分隔符
2: contains:返回表示个字符串是否含有指定模式的布尔型数组
3: count:模式的出现次数
4: endswith,startswith :相当于对各个元素执行x.endswith(pattern)或x.startswith(pattern)
5: findall: 计算各字符串的模式列表
6: get:获取各元素的弟i个字符
7: join:根据指定的分隔符将Series中的各元素字符串链接起来
8: len :计算各字符串的长度
9:lower,upper :转换大小写,相当于对个元素执行x.lower()或x.upper()
10: match :根据指定的正则表达式对各元素执行re.match()
11: pad :在字符串的左边和右边添加空格
12:replace: 用指定的字符串替换找到的模式
13: split: 根据分隔符或正则表达式对字符串进行拆分
10 :pandas缺失值的处理:
t3=pd.DataFrame(np.arange(12).reshape(3,4),index=list('abc'),columns=list('wxyz'))
t3
t3.iloc[1:,:2]=np.nan
t3
1:判断数组中是否有空值--->isnull(),notnull()
pd.isnull(t3)
pd.notnull(t3)

2:处理方式1:
删除nan所在行的行列dropna(axis=0/1,how="any",inplace=False)
how默认是any 表示有一个nan就删除这一整行,all表示 这一行全部为nan的时候 删除一整行,
inplace 默认是false true表示就地赋值给t3,就不用再接收了
t3.dropna(axis=0,how="any",inplace=True)
t3
3:处理方式二:
填充数据:t.fillna(t.mean())
1:#将空值替换为平均值
t2.fillna(t2.mean())
2:# 单独填充一列中nan填充为平均值
t2["age"]=t2["age"].fillna(t2["age"].mean())
t2
4:处理为0的数据
t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会参与

11:pandas 数据合并之join:根据行索引进行合并
df1=pd.DataFrame(np.ones((2,4)),index=["A","B"],columns=list("abcd"))
df1
df2=pd.DataFrame(np.zeros((3,3)),index=["A","B","C"],columns=list("xyz"))
df2
1:df1.join(df2)
a b c d x y z
A 1.0 1.0 1.0 1.0 0.0 0.0 0.0
B 1.0 1.0 1.0 1.0 0.0 0.0 0.0
2:df2.join(df1)
x y z a b c d
A 0.0 0.0 0.0 1.0 1.0 1.0 1.0
B 0.0 0.0 0.0 1.0 1.0 1.0 1.0
C 0.0 0.0 0.0 NaN NaN NaN NaN

12:pandas数据合并之merge 根据列索引进行合并
df3=pd.DataFrame(np.arange(9).reshape((3,3)),columns=list("fax"))
df3
1:内连接,merge方法 默认是内链接:how="inner"
df1.merge(df3,on="a")
2: 外连接 指定how="outer"
df1.merge(df3,on="a",how="outer")
3: 左连接 指定how="outer"
df1.merge(df3,on="a",how="left")
4: 右连接 指定how="outer"
df1.merge(df3,on="a",how="right")
5: 若是两个表中没有相同的列索引怎么办? left_on="O",right_on="X"
df4=pd.DataFrame(np.zeros((3,4)),index=["A","B","C"],columns=list("qwer"))
df4
df5=pd.DataFrame(np.ones((2,5)),index=["A","B"],columns=list("tyuio"))
df5
df4.merge(df5,left_on="q",right_on="i",how="outer")

13:pandas 索引和复合索引:
1:#获取索引
df1.index

2:#指定(修改)索引
df1.index=["a",'b']
df1

3:#重新设置index
df1.reindex(["a","f"])#注意这里面f行返回的都是空值

4:# 指定某一列作为index,drop 是希望把a列的值作为索引 同时不希望删掉a列中的值
df1.set_index("a",drop=False)
df1.set_index("a").index

5:# 返回index的唯一值
df1["a"].unique()

df1.set_index("b").index.unique()
len(df1.set_index("b").index)
list(df1.set_index("b").index)

6:#复合索引,设置两个列作为索引 就是复合索引
df1.set_index(["a","b"]).index

Series复合索引:
1:创建一个数组 a=pd.DataFrame({'a':range(7),"b":range(7,0,-1),"c":["one","one","one","two","two","two","two"],"d":list("hijkmno")})
a b c d
0 0 7 one h
1 1 6 one i
2 2 5 one j
3 3 4 two k
4 4 3 two m
5 5 2 two n
6 6 1 two o
2:指定c列和d列作为index,并取a列的值
x=a.set_index(["c","d"])["a"]
x
c d
one h 0
i 1
j 2
two k 3
m 4
n 5
o 6
Name: a, dtype: int64
3:复合索引下怎么取值呢 ?--->直接根据索引取值即可
x["one","h"]----->0
4:swaplevel()方法可以将两列索引交换位置显示出来具体的索引值,方便查看索引取值
x.swaplevel()
d c
h one 0
i one 1
j one 2
k two 3
m two 4
n two 5
o two 6
Name: a, dtype: int64
5:swaplevel()["索引"]--->能取到该索引对应的值
x.swaplevel()["h"]
c
one 0
Name: a, dtype: int64
DataFrame复合索引
1: 指定c列和d列作为index,并取a列的值 !!!注意这里用[[]渠道的就是DataFrme类型的数组
x=a.set_index(["c","d"])[["a"]]
x
a
c d
one h 0
i 1
j 2
two k 3
m 4
n 5
o 6
2:DataFrme数组中怎么对复合索引进行取值呢?--->x.loc["one"]
x.loc["one"]
a
d
h 0
i 1
j 2
3:DataFrme数组中对复合索引怎么取到具体的值?--->每取一次索引,一次loc
x.loc["one"].loc["h"]
a 0
Name: h, dtype: int64
4:DataFrme数组 同样可以使用swaplevel()方法
x.swaplevel().loc["h"]
a
c
one 0
