使用Python+OpenCV+Keras实现基于车牌的无口罩车辆驾驶员的惩罚生成

介绍
我们知道,在当前形势下,我们正在逐步稳定地克服大流行病的情况,而且情况每天都在改善。但是,众所周知,即使已经开始接种疫苗,彻底根除该病毒仍需花费很多年。因此,为安全起见,在接下来的几年中,我们所有人都可能会习惯于戴口罩。
就违反交通规则而言,政府仍然严格对在路上开车不戴口罩的人处以罚款。
建立一个系统,能够追踪所有交通违法者的细节,提高公民的意识和纪律,是一个非常有用的办法。
还可以通过另外创建一个仪表板监视程序来跟踪该交通规则违反者的增加或减少,在给定期间内收集罚款,确定主要违反规则的人群,从而改善该系统。
工作范围
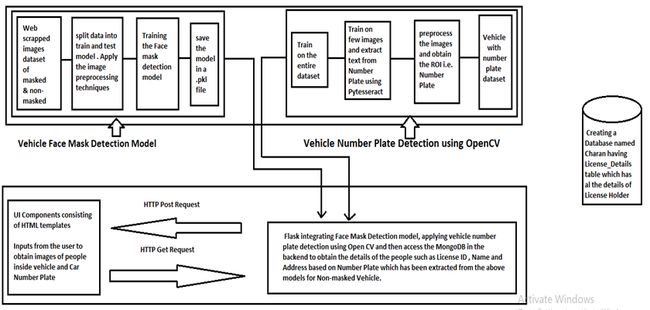
作为代码实现的一部分,我们计划设计一个模型,将图像分类为戴口罩的和没戴口罩的。对于获得的属于没戴口罩类别的图像,我们获取车辆号牌的图像,并尝试提取车辆详细信息。
车牌识别使用第二个模型完成,该模型接收带有车牌的输入作为汽车图像。一旦完成了车辆ID,我们便将详细信息传递到虚拟数据库,该数据库包含车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将产生罚款,该罚款将直接发送到违规者的家庭住址。
软件架构
网页抓取图片

项目始于确定要使用的数据集的问题。在我们的项目中,在线冲浪几乎无法为我们提供可用于我们项目的现有数据集。
因此,我们决定应用网络抓取收集戴口罩和没戴口罩的图像。
我们使用Beautiful Soap and Requests库从网站下载图像并将其保存到包含戴口罩和没带口罩驾驶员的不同文件夹中。
我们从下面的URL中提取了数据,这些URL由已屏蔽图像和未屏蔽图像组成。
链接url1 = https://www.gettyimages.in/photos/driving-mask?page=
链接url2 = https://www.gettyimages.in/photos/driving-without-mask?page=
下面是一段代码,演示了Web上的图像抓取。
from bs4 import *
import requests as rq
import os
url1 = 'https://www.gettyimages.in/photos/driving-mask?page='
url2 = '&phrase=driving%20mask&sort=mostpopular'
url_list=[]
Links = []
for i in range(1,56):
full_url = url1+str(i)+url2
url_list.append(full_url)
for lst in url_list:
r2 = rq.get(lst)
soup = BeautifulSoup(r2.text, 'html.parser')
x=soup.select('img[src^="https://media.gettyimages.com/photos/"]')
for img in x:
Links.append(img['src'])
print(len(Links))
for index, img_link in enumerate(Links):
if i <= len(Links):
img_data = rq.get(img_link).content
with open("Masked_Drivers/" + str(index + 1) + '.jpg', 'wb+') as f:
f.write(img_data)
i += 1
图像预处理
在将图像发送到模型之前,我们需要应用一些清理技术,例如图像大小调整图像的灰度和将像素重新缩放为较低的值。之后,图像和目标将保存在阵列中。
import cv2,os
data_path='Dataset'
categories=os.listdir(data_path)
labels=[i for i in range(len(categories))]
label_dict=dict(zip(categories,labels)) #empty dictionary
print(label_dict)
print(categories)
print(labels)
img_size=100
data=[]
target=[]
img_size=100
data=[]
target=[]
for category in categories:
folder_path=os.path.join(data_path,category)
img_names=os.listdir(folder_path)
for img_name in img_names:
img_path=os.path.join(folder_path,img_name)
img=cv2.imread(img_path)
try:
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#Coverting the image into gray scale
resized=cv2.resize(gray,(img_size,img_size))
#resizing the gray scale into 50x50, since we need a fixed common size for all the images in the dataset
data.append(resized)
target.append(label_dict[category])
#appending the image and the label(categorized) into the list (dataset)
except Exception as e:
print('Exception:',e)
import numpy as np
data=np.array(data)/255.0
data=np.reshape(data,(data.shape[0],img_size,img_size,1))
target=np.array(target)
from keras.utils import np_utils
new_target=np_utils.to_categorical(target)
np.save('data',data)
np.save('target',new_target)
建立模型
在这里,我们使用Keras的Sequential设计CNN模型。使用大约200个神经元作为输入来构建CNN。
应用激活函数和最大池化技术后,我们将获得另一组输出特征,这些特征将通过Conv2D的另一层传递。
最后,我们从softmax中获得2个输出,它们代表输入图像的戴口罩或未戴口罩状态。
from keras.models import Sequential
from keras.layers import Dense,Activation,Flatten,Dropout
from keras.layers import Conv2D,MaxPooling2D
from keras.callbacks import ModelCheckpoint
model=Sequential()
model.add(Conv2D(200,(3,3),input_shape=data.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(100,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(50,activation='relu'))
model.add(Dense(2,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
训练和测试模型
构建CNN模型后,我们将数据分为训练集和测试集。后来,我们通过设置各种参数(例如时期,训练集,验证集和验证拆分值),在训练和测试数据上拟合CNN模型。
from sklearn.model_selection import train_test_split
train_data,test_data,train_target,test_target=train_test_split(data,target,test_size=0.4)
checkpoint = ModelCheckpoint('model-{epoch:03d}.model',monitor='val_loss',verbose=0,save_best_only=True,mode='auto')
history=model.fit(train_data,train_target,epochs=20,callbacks=[checkpoint],validation_split=0.1)

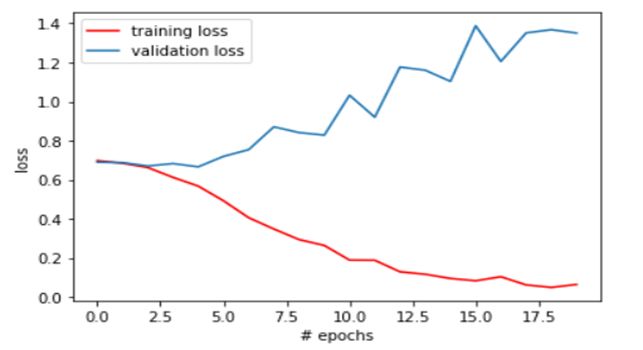
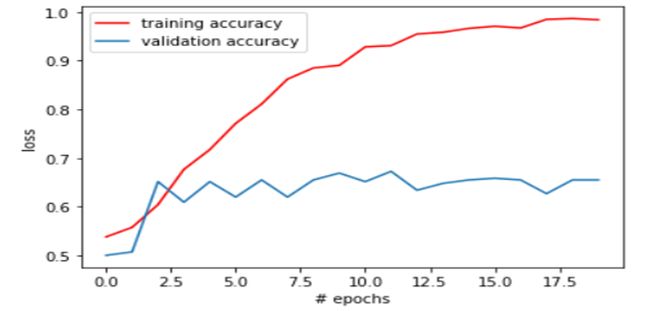
测量精度和损耗
然后,我们根据训练和测试数据集计算损失和准确性。可以看出,测试数据集的准确性比训练数据集的准确性低。
此外,与测试数据集相比,测试数据集中发生的损失更多。
保存人脸检测模型并暴露于新数据
接下来,我们将使用上述过程创建的模型存储在pickle文件中。稍后,我们将利用该模型来确定给定图像的驾驶员是否戴了口罩。
基本上,模型的输出将具有两个值,分别代表戴口罩和未戴口罩的概率。在这两个值中,大于0.5的概率值将被视为结果。
数组输出内部的第一个值表示驾驶员戴口罩的概率,第二个值表示驾驶员不戴口罩的概率。
model.save('saved_model/my_model')
INFO:tensorflow:Assets written to: saved_model/my_model\assets
from keras.models import load_model
new_model = load_model('saved_model/my_model')
import cv2,os
img_path = 'test/755.jpg'
img_size=100
data=[]
img=cv2.imread(img_path)
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
resized=cv2.resize(gray,(img_size,img_size))
data.append(resized)
data=np.array(data)/255.0
data=np.reshape(data,(data.shape[0],img_size,img_size,1))
output = new_model.predict(data)
print(output)
[[0.00447709 0.995523 ]]
车牌号码图像预处理
我们在车牌上应用图像处理技术以减小图像尺寸,并通过在车牌周围绘制一个矩形框来跟踪车牌号码。
for f1 in files:
img = cv2.imread(f1)
img = cv2.resize(img, (IMAGE_SIZE,IMAGE_SIZE))
X.append(np.array(img))
from lxml import etree
def resizeannotation(f):
tree = etree.parse(f)
for dim in tree.xpath("size"):
width = int(dim.xpath("width")[0].text)
height = int(dim.xpath("height")[0].text)
for dim in tree.xpath("object/bndbox"):
xmin = int(dim.xpath("xmin")[0].text)/(width/IMAGE_SIZE)
ymin = int(dim.xpath("ymin")[0].text)/(height/IMAGE_SIZE)
xmax = int(dim.xpath("xmax")[0].text)/(width/IMAGE_SIZE)
ymax = int(dim.xpath("ymax")[0].text)/(height/IMAGE_SIZE)
return [int(xmax), int(ymax), int(xmin), int(ymin)]
以下是使用OpenCV在给定图像中使用牌照周围的矩形框检测到的牌照号码示例。

使用OpenCV和Pytesseract从车牌中提取文本
我们可以使用OpenCV提取车牌号。我们可以使用边缘检测技术提取文本。在获得灰度格式的图像后,我们将图像转换为双向滤镜模式。
接下来,我们在感兴趣的区域周围绘制一个包含车牌ID的框,使用Pytesseract库中具有图像到字符串功能的函数,我们可以获得车牌编号。
import cv2
import imutils
import numpy as np
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
for i in lst_add[1562:1572]:
print(i)
img = cv2.imread(i,cv2.IMREAD_COLOR)
img = cv2.resize(img, (600,400) )
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray, 13, 15, 15)
edged = cv2.Canny(gray, 30, 200)
contours = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
contours = sorted(contours, key = cv2.contourArea, reverse = True)[:10]
screenCnt = None
for c in contours:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
if len(approx) == 4:
screenCnt = approx
break
if screenCnt is None:
detected = 0
print ("No contour detected")
else:
detected = 1
if detected == 1:
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)
mask = np.zeros(gray.shape,np.uint8)
new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)
new_image = cv2.bitwise_and(img,img,mask=mask)
(x, y) = np.where(mask == 255)
(topx, topy) = (np.min(x), np.min(y))
(bottomx, bottomy) = (np.max(x), np.max(y))
Cropped = gray[topx:bottomx+1, topy:bottomy+1]
text = pytesseract.image_to_string(Cropped, config='--psm 11')
print("Detected license plate Number is:",text)
img = cv2.resize(img,(500,300))
Cropped = cv2.resize(Cropped,(400,200))
cv2.imshow('car',img)
cv2.imshow('Cropped',Cropped)
cv2.waitKey(1)
cv2.destroyAllWindows()
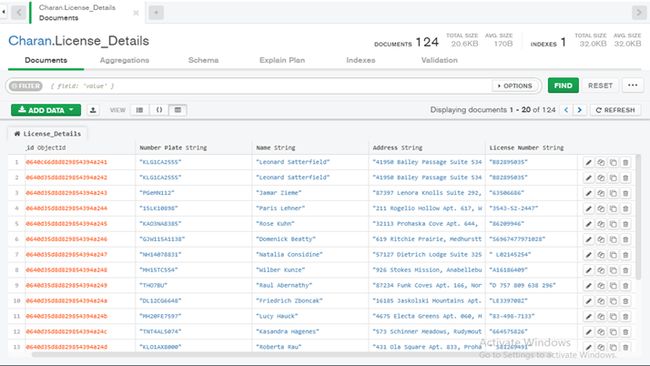
为车牌持有人构建虚拟的MongoDB数据库
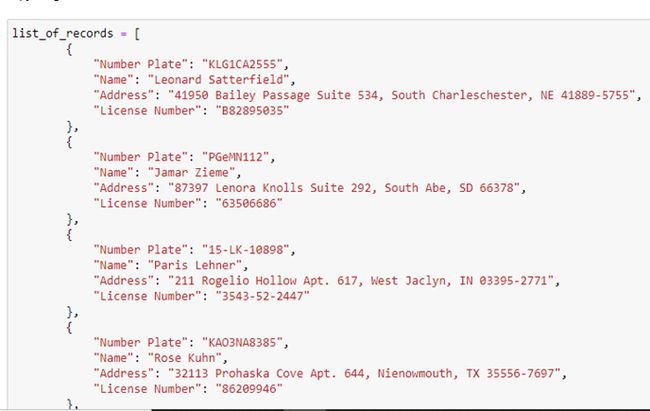
我们使用pymongo库在MongoDB中创建一个名为Charan的数据库。在MongoDB内部创建一个名为License Details的表,该表包含多个字段,例如License ID,候选人名称,地址和车牌号。
因此,我们设计了一个虚拟数据库表,其中包含所有相关详细信息,以使用车牌识别人员详细信息。
from flask_pymongo import PyMongo
DEFAULT_CONNECTION_URL = "mongodb://localhost:27017/"
DB_NAME = "Charan"
# Establish a connection with mongoDB
client = pymongo.MongoClient(DEFAULT_CONNECTION_URL)
client.list_database_names()
dataBase = client[DB_NAME]
COLLECTION_NAME = "License_Details"
collection = dataBase[COLLECTION_NAME]
创建由键值格式的数据组成的词典列表。我们可以通过将列表作为MongoDB的insert_many函数中的参数传递来直接将详细信息推入表中。
将Flask与两个模型和MongoDB集成以实现端到端流程
我们创建了一个flask main.py,该flask链接到各种HTML模板,以从用户那里获取前端汽车驾驶员图像的输入。
然后,该图像由CNN模型处理,以在后端进行口罩检测,并且无论驾驶员是否戴口罩,结果都将显示在HTML模板中。
下面的代码以图像文件的形式从用户那里获取输入,对图像应用各种预处理技术,例如调整大小,灰度,重新排列图像阵列,然后将图像发送到已经训练好的模型以确定输出。
@app.route('/', methods=['POST'])
def upload_file():
img_size=100
data=[]
uploaded_file = request.files['file']
result=''
if uploaded_file.filename != '':
filename = uploaded_file.filename
uploaded_file.save(os.path.join(app.config['UPLOAD_PATH'], filename))
img_path = os.path.join(app.config['UPLOAD_PATH'], filename)
print(img_path)
img=cv2.imread(img_path)
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
resized=cv2.resize(gray,(img_size,img_size))
data.append(resized)
data=np.array(data)/255.0
data=np.reshape(data,(data.shape[0],img_size,img_size,1))
new_model = load_model('saved_model/my_model')
output = new_model.predict(data)
if output[0][0]>=0.5:
result = 'The person is Masked'
else:
result = 'The Person is Non Masked'
print(result)
return render_template('Show.html',result=result)
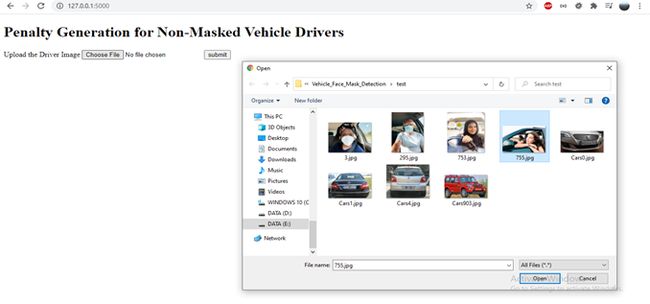
以下是HTML模板,该HTML模板作为上载图像文件的一部分显示给用户。
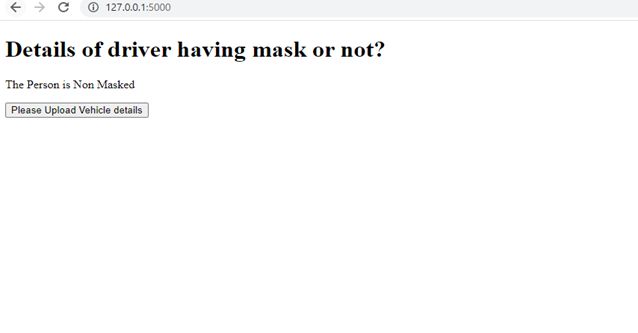
下面是一个Html模板,当POST方法在处理完图像后发送结果时显示,显示驾驶员是否戴了口罩。
接下来,我们上传车辆图像,该图像已被确定为驾驶员没有戴口罩。车辆的图像再次通过图像预处理阶段进行处理,在该阶段中,模型会尝试从车牌中的车牌框中提取文本。
@app.route('/Vehicle', methods=['POST'])
def table2():
uploaded_file = request.files['file']
result=''
if uploaded_file.filename != '':
path='static/car'
filename = uploaded_file.filename
uploaded_file.save(os.path.join(path, filename))
img_path = os.path.join(path, filename)
print(img_path)
img = cv2.imread(img_path,cv2.IMREAD_COLOR)
img = cv2.resize(img, (600,400) )
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray, 13, 15, 15)
edged = cv2.Canny(gray, 30, 200)
contours = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
contours = sorted(contours, key = cv2.contourArea, reverse = True)[:10]
screenCnt = None
for c in contours:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
if len(approx) == 4:
screenCnt = approx
break
if screenCnt is None:
detected = 0
print ("No contour detected")
else:
detected = 1
if detected == 1:
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)
mask = np.zeros(gray.shape,np.uint8)
new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)
new_image = cv2.bitwise_and(img,img,mask=mask)
(x, y) = np.where(mask == 255)
(topx, topy) = (np.min(x), np.min(y))
(bottomx, bottomy) = (np.max(x), np.max(y))
Cropped = gray[topx:bottomx+1, topy:bottomy+1]
text = pytesseract.image_to_string(Cropped, config='--psm 11')
print("Detected license plate Number is:",text)
#text='GJW-1-15-A-1138'
print('"{}"'.format(text))
re.sub(r'[^\x00-\x7f]',r'', text)
text = text.replace("\n", " ")
text = re.sub('[\W_]+', '', text)
print(text)
print('"{}"'.format(text))
query1 = {"Number Plate": text}
print("0")
for doc in collection.find(query1):
doc1 = doc
Name=doc1['Name']
Address=doc1['Address']
License=doc1['License Number']
return render_template('Penalty.html',Name=Name,Address=Address,License=License)
以下是车辆图像上传页面,该页面接收用户的输入并处理车辆图像以获得车牌号文字。
提取车牌编号的文本后,我们需要使用车号牌查找车牌持有人的详细信息,接下来我们将连接到MongoDB创建的名为License_Details的表。
一旦获得了车牌号,名称,地址等详细信息,我们就可以生成罚款并将其显示在HTML模板页面上。

未来的工作
与训练精度相比,口罩模型的测试精度要低得多。因此,未知数据集的错误分类非常高。另外,我们需要努力提高基于OpenCV的车牌提取的准确性,因为错误的关注区域可能会导致提取空的车牌文本。另外,可以进一步改善前端,使其更具吸引力。
参考
1.Face Mask Detector
https://www.researchgate.net/publication/344173985_Face_Mask_Detector
2.Face Recognition with Facial Mask Application and Neural Networks https://link.springer.com/chapter/10.1007/978-3-540-73007-1_85
3.An Automated System to Limit COVID-19 Using Facial Mask Detection in Smart City Network: https://ieeexplore.ieee.org/document/9216386
4.Automated Car Number Plate Detection System to detect far number plates http://www.iosrjournals.org/iosr-jce/papers/Vol18-issue4/Version-3/F1804033440.pdf
5.Automatic Number Plate Recognition System (ANPR): A Survey https://www.researchgate.net/publication/236888959_Automatic_Number_Plate_Recognition_System_ANPR_A_Survey
6.COVID-19: Face Mask Detector with OpenCV, Keras/TensorFlow, and Deep Learning https://www.pyimagesearch.com/2020/05/04/covid-19-face-mask-detector-with-opencv-keras-tensorflow-and-deep-learning/
7.OpenCV: Automatic License/Number Plate Recognition (ANPR) with Python https://www.pyimagesearch.com/2020/09/21/opencv-automatic-license-number-plate-recognition-anpr-with-python/
8.https://github.com/prajnasb/observations/tree/master/mask_classifier
9.https://github.com/aieml/face-mask-detection-keras
10.License Plate Recognition using OpenCV Python https://medium.com/programming-fever/license-plate-recognition-using-opencv-python-7611f85cdd6c
11.Plate Number Detection https://www.kaggle.com/alpertemel/plate-number-detection
12.Github链接 https://github.com/charanraj2411/Penalty-Generation-Non-Masked-Drivers-using-Number-Plate
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓