big data 入门
big data
- 参考厦门大学-林子雨-大数据技术原理与应用(第2版)
- Hadoop 1.0
- Hadoop 2.0
-
- HDFS 2.0的新特性
-
- HDFS HA
- HDFS Federation
- YARN 新一代资源调度管理框架(未完成)
- Hadoop 生态系统中具有代表性的功能组件
- HDFS
-
- 主节点(Master Node)/名称节点(`Name Node`)。
- 从节点(Slave Node)/数据节点(`Data Node`)
- HDFS 体系结构
- HDFS 存储原理
-
- 冗余数据保存
- 数据存取策略
- 数据错误与恢复
- 读写数据流程
- Hbase
- NoSQL
-
- 典型的四种类型
- NoSQL 三大基石
-
- CAP
- BASE
- 最终一致性
- MapReduce
-
- 分布式并行编程
- MapReduce 模型
- Map
- Reduce
- MapReduce 具体应用
- 流计算
- Apache Druid
参考厦门大学-林子雨-大数据技术原理与应用(第2版)
Hadoop 1.0
Apache 旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础框架。
基于 Java 语言开发,很好的跨平台特性,可部署在廉价的计算机集群中。
Hadoop 的核心是分布式文件系统 HDFS(Hadoop Distributed File System) 和 MapReduce
Hadoop 被公认为是行业大数据标准开元软件,提供了分布式环境下的海量数据的处理能力。
Hadoop 2.0: HDFS + MapReduce + YARN
Hadoop 2.0
Hadoop 从 1.0 到 2.0 的改进
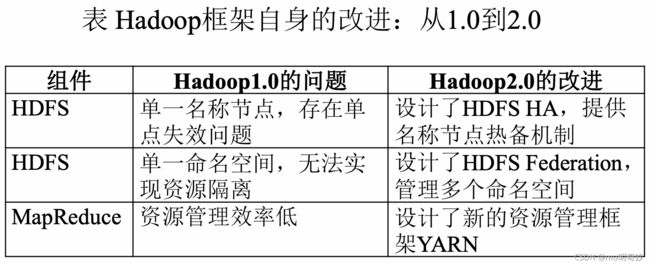
HDFS 2.0的新特性
HDFS 2.0的新特性主要有两个,HDFS HA 和 HDFS Federation。
HDFS HA
HDFS 1.0 回顾:
一个 NameNode,一个 SecondaryNameNode,多个 DataNode
NameNode 保存元数据。其中磁盘上保存 FsImage 和 EditLog;内存中保存映射关系,即每个文件包含哪些块,每个块存储在哪个 DataNode。
SecondaryNameNode 的作用是防止 EditLog 过大,导致 NameNode 重启时耗时太长。
HDFS 1.0 存在单点故障问题。
HDFS HA(High Available) 解决了单点故障问题。
HA 集群设置两个 NameNode,一个 Active 活跃,一个 Standby 待命。一旦 Active 故障无法提供服务,立即切换到 Standby(ZooKeeper 保证这一点,通过心跳监控节点的健康状态)。两个 NameNode 的状态保持同步(通过一个共享存储系统(NFS、QJM或Zookeeper)来实现)。两个 NameNode 都维护映射信息,DataNode 同时向两个 NameNode 汇报信息。
HDFS Federation
HDFS 1.0 回顾:
除了单点故障问题,HDFS 1.0 还存在以下问题:
不可以水平扩展
系统整体性能受限于单个 NameNode 的吞吐量
单个 NameNode 难以提供不同程序之间的隔离性
HDFS HA 是热备份,只解决了高可用性。
HDFS Federation 中,设置了多个相互独立的 NameNode,使得 HDFS 的命名服务能够水平扩展。这些 NameNode 分别管理各自的命名空间和块,相互之间是 Federation 联盟关系,不需要彼此协调。
HDFS Federation 中,所有 NameNode 共享底层的 DataNode 存储数据。同一个 NameNode 的那个命名空间的所有块,形成一个块池。
HDFS Federation 的优势(解决的问题):
集群扩展性。多个名称节点管理各自的目录,使得一个集群可以扩展到更多节点,不再向 1.0 那样受限于单个 NameNode 的内存。
性能更高效。多个名称节点管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率
良好的隔离性。用户可根据需要将不同业务数据交由不同名称节点管理,这样不同业务之间影响很小
HDFS Federation 未解决 NameNode 的单点故障问题,需要为每一个 NameNode 部署一个后备(Standby)节点来确保 NameNode 挂掉后不影响业务。
YARN 新一代资源调度管理框架(未完成)
Hadoop 生态系统中具有代表性的功能组件
Pig:通过提供的 Pig Latin 语言编写简单的脚本来实现复杂的数据分析,而不用写复杂的 MapReduce 应用程序。
Pig 会将用户写的脚本转化为 MapReduce 作业在 Hadoop 集群上运行。
Tez:支持 DAG 作业的计算框架。
Tez 基于 MapReduce 框架,把 Map 和 Reduce 分成更加细粒度的元操作。分解后的元操作可以更灵活的组合。经过控制程序组装后,形成一个大的 DAG 作业,提升了程序运行的整体逻辑,去除不必要的操作,提高性能。
Spark:
Hadoop 的 MapReduce 计算模型延迟过高(基于磁盘、前一个任务执行完之前,其他任务无法开始),无法胜任实时的快速计算的需求,只适用于离线批处理的应用场景。
出现了 Spark:内存计算,基于 DAG 的任务调度执行机制,当今最热门的大数据计算平台
Kafka:高吞吐的分布式发布订阅消息系统,用户通过 Kafka 可以发布消息,也可以实时订阅消费消息。
Kafka 可以同时满足在线实时处理和离线批量处理
在大数据生态系统中,可以把 Kafka 作为数据交换的枢纽,不同类型的分布式系统(RDBMS、NoSQL、流处理系统、批处理系统等),可以统一接入到 Kafka,实现和 Hadoop 的各个组件之间的不同类型数据的实时高效数据交换。

HDFS
分布式文件系统:将文件分布存储到多个节点上,节点构成集群。硬件开销低
节点分为两类:
主节点(Master Node)/名称节点(Name Node)。
NameNode 管理 HDFS 的命名空间(namespace),保存了两个核心的数据结构 FsImage 和 EditLog。FsImage 记录了文件系统树和树中所有文件和文件夹的元数据。EditLog 记录了所有文件的更新操作日志(创建、删除、重命名等)。
NameNode 启动时会将 FsImage 中的内容加载到内存,再执行 EditLog,使得内存中的元数据和实际的同步。
FsImage 是 GB 级别的,EditLog 比较小。直接更新 FsImage 耗时,于是每次更新先写 EditLog。
EditLog 不可能无限写,且 EditLog 越大,NameNode 重启时的耗时就越久。于是定期要将 Editlog 的内容写入 FsImage。这需要第二名称节点 SecondaryNameNode。SecondaryNameNode 用来保存 NameNode 中元数据的备份。
SecondaryNameNode 工作流程:将 NameNode 的 FsImage 和 EditLog 通过 HTTP_GET 到本地,加载 FsImage 到内存,根据一条条 EditLog 更新 FsImage,同时让 NameNode 将此刻开始的新的操作日志保存在 edit.new 中。EditLog 全部更新到 FsImage 后,将此 FsImage 通过 HTTP_POST 发给 NameNode 作为新的 FsImage,edit.new 作为新的 EditLog。通过这个过程 EditLog 变小了。
NameNode 将每个文件包含哪些块、每个块存储在哪个 DataNode 这些映射信息保存在内存中。当新的 DataNode 加入集群时,将 DataNode 上的块列表同步 NameNode,并定期更新,以确保 NameNode 保存最新的块映射。
NameNode 维护了块和节点本地 Linux 文件系统的文件的映射关系。
从节点(Slave Node)/数据节点(Data Node)
DataNode 是 HDFS 的工作节点,负责数据的存储和读取,根据客户端或 NameNode 的调度进行数据的存储和检索,并定期向 NameNode 发送自己存储的块列表。
各个 DataNode 中的数据会保存在所在节点的本地 Linux 文件系统中。
块:HDFS 默认一个块 64MB(远大于普通文件系统,可以最小化寻址开销),一个文件分为多个块,以块作为存储单位。
HDFS 体系结构
主从结构,一个 HDFS 集群包括一个 NameNode 和多个 DataNode。NameNode 作为中心服务器,负责文件系统的命名空间和客户端对文件的访问。一般每个 DataNode 运行一个进程,负责处理客户端的读写请求(不是 NameNode 转发的请求,NameNode 只负责把文件信息返回给客户端),在 NameNode 的调度下进行文件块的创建、更新、删除等操作。每个 DataNode 的数据实际上是保存在本地 Linux 文件系统中的。
通信协议
以 TCP/IP 为基础。
客户端-NameNode:根据客户端协议
NameNode-DataNode:根据 DataNode 协议
客户端-数据节点:RPC
HDFS 1.0 只有一个 NameNode 的局限性:
1.命名空间限制。由于 NameNode 保存在节点中。
2.性能瓶颈。整个系统的吞吐量,受限于单个 NameNode 的吞吐量。
3.隔离问题。只有一个命名空间,无法对不同应用程序进行隔离。
4.可用性。一旦这个唯一的 NameNode 故障,整个集群不可用。(在 2.0 中改善)
HDFS 存储原理
冗余数据保存
多副本,一个数据块的多个副本分布存储在不同节点上。
数据存取策略
存
第一个副本放在上传文件的节点。如果是集群外提交,放在一个磁盘、CPU 比较空闲的节点
第二个副本放在与第一个副本不同机架的节点上。
第三个副本放在与第一个副本相同机架的不同节点上。
更多副本,随机节点。
取
当客户端从 NameNode 获得的数据块部分所在的 DataNode 的机架与客户端所在机架相同时,优先读该副本,否则随机选副本读取。
数据错误与恢复
NameNode 出错:SecondaryNameNode。(2.0 还有其他高可用方案)
DataNode 出错:心跳机制。冗余因子机制。
数据出错:由网络传输、磁盘错误等导致。客户端读取后,md5、sha1 校验。
读写数据流程
读数据:
客户端从 NameNode 文件元数据获得文件的数据块副本所在的 DataNode。
选择距离近的 DataNode,读取数据。
写数据:
客户端请求创建文件,NameNode 更新元数据。
客户端写入数据到 DataNode。
复制出多个副本保存在不同 DataNode。
Hbase
见另一篇文章 hbase
NoSQL
典型的四种类型
键值数据库、列族数据库、文档数据库、图形数据库
键值数据库:理想的缓冲层解决方案
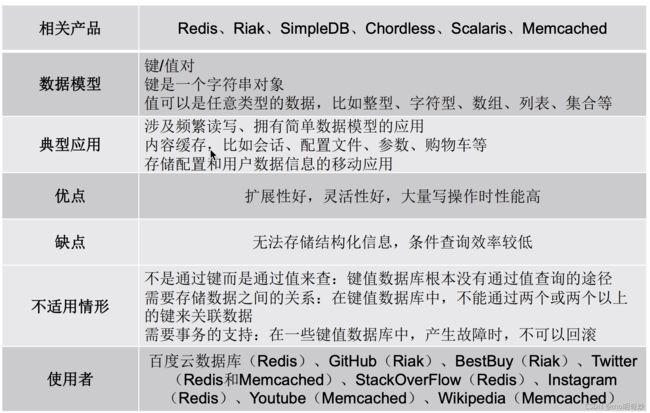
列族数据库:

文档数据库:存储、索引、管理面向文档的或类似的半结构化数据。使用 JSON 数据结构、嵌套结构等非规范化数据的场景。
灵活,每一行记录就是一个文档
相关产品:MongoDB、CouchDB 等
图形数据库:
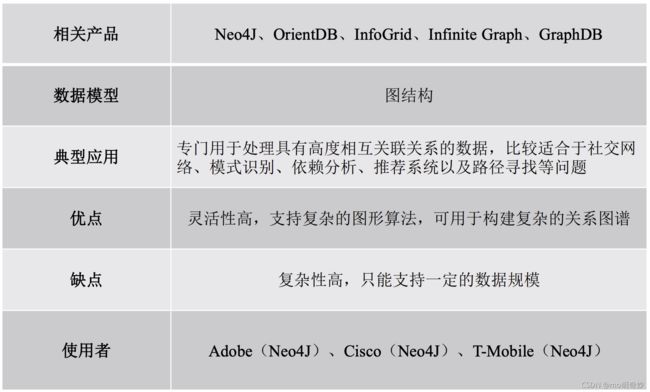
NoSQL 三大基石
CAP
C:Consistency,一致性,指任意一个读总能读到之前写的数据。分布式环境中,多点的数据一致。
A:Available,可用性,指快速获得数据,每个请求无论成功失败都能快速获得相应、返回操作结果
P:Tolerance Of NetWork Partition,分区容忍性指出现网络分区(系统的部分节点无法与其他节点通信)时,系统也能正常运行。
CAP 理论:一个系统不可能同时满足 C、A、P 三大特性,最多同时满足两个。
CA:放弃 P,简单的做法是把事务相关的内容放在一台机器上。严重影响系统可扩展性。
CP:放弃 A,当出现网络分区时,受影响的服务需等待数据一致,期间无法对外服务
AP:放弃 C,允许返回不一致的数据
BASE
BA:Basically Available,基本可用,当分布式系统的一部分出现故障,其他部分仍然能正常服务,允许分区失败
S:Soft-State,软状态,数据状态允许有一段时间不同步,具有一定滞后性
E:Eventual Consistency,最终一致性,虽然允许有一段时间读的不是最新的数据,但最终必须能读到最新数据
最终一致性
N:冗余副本份数
W:更新时需要保证写入的节点数
R:读取时需要读的节点数
W + R > N:强一致性
W + R <= N:弱一致性
MapReduce
分布式并行编程
分布式程序运行在大规模计算机集群上,可以并行执行大规模数据处理任务,获得海量数据的计算能力。
谷歌提出分布式并行编程框架 MapReduce,Hadoop MapReduce 是它的开源实现。
MapReduce相较于传统的并行计算框架的优势:容错好、硬件便宜、扩展性好、编程简单、适用场景:批处理、非实时、数据密集
MapReduce 模型
MapReduce 将复杂的并行计算过程高度抽象为两个函数:Map 和 Reduce。
“分而治之”,一个存储在 HDFS 的大数据集,会被切分成多个 split,被多个 Map 任务并行处理。
“计算向数据靠拢”,需要大量网络传输开销。
Master/Slave架构,一个 Master,多个 Slave,Master 上运行 JobTracker,Slave 上运行 TaskTracker。
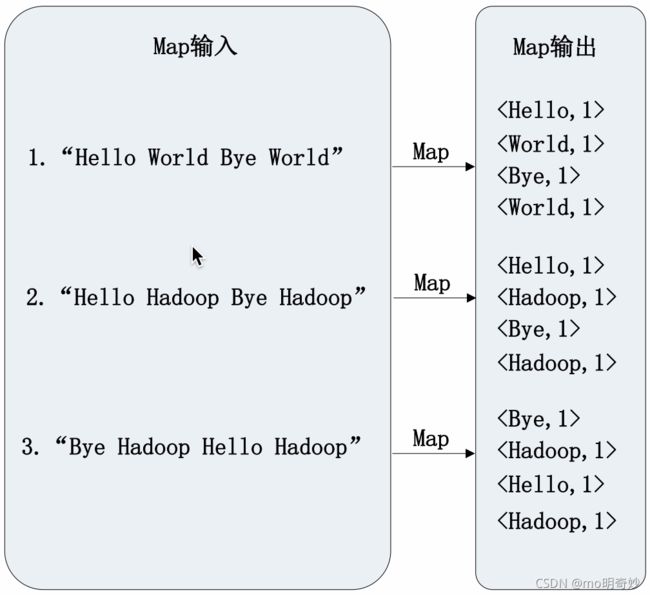
Map
WordCount 执行过程实例
Reduce
WordCount 执行过程实例
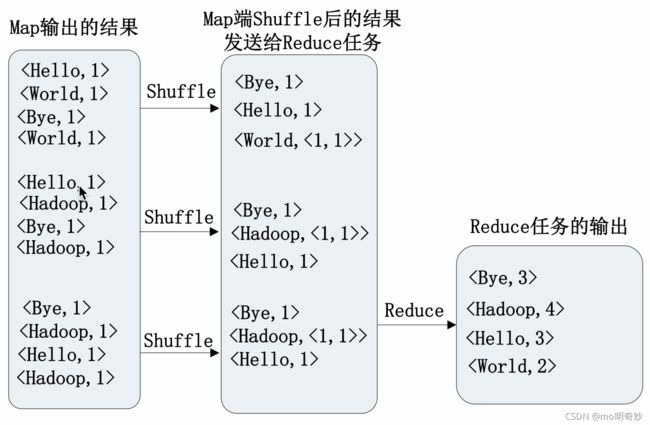
MapReduce 具体应用
关系代数运算(选择、投影、并、交、差、连接)
分组与聚合运算
矩阵-向量乘法
矩阵乘法
流计算
静态数据
流数据(动态数据):数据以大量、快速、时变的流形式持续到达
流数据的特征
- 数据快速持续到达,潜在大小也许是无穷尽的
- 数据来源众多、格式复杂
- 不十分关注存贮,经过处理后,可以丢弃或存储
- 注重数据的整体价值,而不是个人数据的价值
- 数据无序,不完整
静态数据的计算模式:批量计算:充裕时间处理,如 Hadoop
流数据的计算模式:数据量大、来源复杂的实时计算——流计算
流计算:实时获取来自不同数据源的海量数据,经过实时分析处理,获取有价值的信息
流计算的基本理念:数据的价值随着时间流逝而降低,如用户的点击流。因此,当数据出现时就应该马上处理。为了及时处理流数据,就需要一个低延迟、可扩展、高可靠的处理引擎。
流计算系统的要求:
- 高性能,每秒几十万条数据
- 海量式,TB、PB 级别的数据规模
- 实时性,响应时间秒级、毫秒级
- 分布式,能够平滑扩展
- 易用性,能够快速地开发和部署
- 可靠性,可靠地处理流数据
流计算处理流程:数据实时采集->数据实时计算->实时查询(无需用户主动查询,而是将实时计算结果主动推送给用户)服务
流计算应用场景:实时分析、实时交通
开源流计算框架:Twitter Storm
Storm 之于实时计算类似于 Hadoop 之余批处理
流计算系统更关注延时,批处理系统更关注吞吐率
Apache Druid
https://blog.csdn.net/weixin_44595582/article/details/121106127