【Linux】Linux基本指令和工具操作大集合(vim、gcc/g++、gdb、make/makefile、git)
【Linux】Linux基本指令和工具操作大集合(vim、gcc/g++、gdb、make/makefile、git)
文章目录
- 【Linux】Linux基本指令和工具操作大集合(vim、gcc/g++、gdb、make/makefile、git)
- 一、基础指令
-
- 1.1 与目录相关的指令
- 1.2 与文件相关的指令
- 1.3 与压缩相关的指令
- 1.4 与匹配查找相关的指令
- 1.5 与时间相关的指令
- 1.6 与权限相关的指令
- 1.7 常用的操作
- 二、常用工具
-
- 2.1 yum
- 2.2 vim编辑器
- 2.3 gcc与g++编译器
- 2.4 gdb调试器
- 2.5 make与makefile自动化架构工具
- 2.6 git版本管理工具
一、基础指令
1.1 与目录相关的指令
● ls
功能:(list)查看文件/文件夹信息 ls [选项] [文件/目录] -a 所有; -l 详细信息; -t 以时间排序
使用方法:ls [选项] [文件/目录]
补充:-a 所有; -l 详细信息; -t 以时间排序; -r 对目录反向排序
● pwd
功能:显示用户当前所在的路径(绝对路径)
使用方法:pwd
● cd
功能:(change directory) 切换工作目录
使用方法:cd [目录]
补充:. 当前路径; … 上一级目录; ~ 家目录; / 根目录
绝对路径:从根目录开始计算到某一个文件夹所经历的路径
相对路径:是相对某一个目录到另一个目录所经历的路径
● mkdir
功能:(make directory) 创建文件/文件夹
使用方法:mkdir [文件夹名称]
mkdir -p [目录文件夹]
补充:-p (parents)可以带有路径的名称,一次可以建立多个目录
● rmdir / rm
功能:(remove directory) 删除文件/文件夹
使用方法:rm -r [待删除的文件夹]
补充:-r (recursion)删除目录以及其下所有文件; -f (force)强制删除; -i 删除前逐一询问确认
rm -r ./* 删除当前路径下的文件及文件夹
rm ./* 删除当前路径下的所有文件
对于rm而言慎用*比如这里的:
rm -rf / 或者 rm -rf /* 它会将linux操作系统中根目录下的所有文件都删除,慎用!!!
● cp
功能:(copy) 复制文件/文件夹
使用方法:cp -r [源文件] [拷贝到哪里]
cp -r [源文件] [拷贝到哪里去]/[重命名之后的名称]
补充:-f (force) 强制复制;-i (interactive) 覆盖之前先询问; -r (recursion) 递归处理
● mv
功能:(move) 移动、重命名文件/文件夹
使用方法:mv [源文件/文件夹] [移动到哪里去]
mv [文件/文件夹] [重命名之后的名称]
1.2 与文件相关的指令
● touch
功能:创建文件
使用方法:touch [文件名]
补充:-t 使用指定的日期时间
● cat
功能:查看目标文件的内容
使用方法:cat [文件名]
补充:echo “string” > [filename] 将string字符串重定向到filename当中
● head
功能:显示文件的开头至标准输出中
使用方法:head [文件名]
head -[n] [文件名]
补充:不加选项时,默认查看头部10行; -n 前n行
● tail
功能:显示文件的尾部至标准输出中
使用方法:tail [文件名]
tail -[n] [文件名]
tail -f [文件名]
补充:不加选项时,默认查看尾部10行; -n 尾部的n行; -f 监控文件是否有新的内容
● more
功能:分页查看目标文件中的内容
使用方法:more [文件名]
补充:f (front) 向下翻页;q (quit) 退出 或者 ctrl+c 退出
● less
功能:分页查看目标文件中的内容
使用方法:less [文件名]
补充:less比more更灵活,more没有办法向前面翻,只能向后翻。
-i 忽略搜索时的大小写;-N 显示每行的行号。
f (front) 向下翻页;b (back) 向上翻页;q (quit)退出 ctrl+c 退出;Pgup 和 PgDn 也可翻页。
1.3 与压缩相关的指令
● zip / unzip
功能:压缩和解压缩文件/文件夹
使用方法:压缩文件: zip [压缩后的文件名称].zip [待压缩的文件]
压缩文件夹:zip [压缩后的文件夹名称].zip [待压缩的文件夹] -r
解压缩:unzip [待解压缩的文件].zip
补充:-r 递归处理,将指定目录下的所有文件和子目录一并处理
● gzip
使用方法:压缩:tar -zcvf [压缩后的文件名称].tar.gz [待压缩的文件/文件夹]
解压缩:tar -zxvf [压缩后的文件名称].tar.gz
● bzip2
使用方法:压缩:tar -jcvf [压缩后的文件名称].tar.bz2 [待压缩的文件/文件夹]
解压缩: tar -jxvf [压缩后的文件名称].tar.bz2
补充:-z 采用gzip压缩;-j 采用bzip2压缩; -c (create)建立一个压缩文件;-x 解开一个压缩文件
1.4 与匹配查找相关的指令
● find
功能:在目录结构中搜索文件
使用方法:find -name [文件名]
补充:
-name [filename] //通过文件名查找
-size [n/-n/+n] //查找文件大小为n/小于n/大于n的文件
-type [b/d/c/p/l/f] //通过文件类型查找,块设备、目录、字符设备、管道、符号链接、普通文件
-ctime [-n] [+n] //通过文件创建时间来查找文件,-n指n天以内,+n指n天以前
-atime [-n] [+n] //通过文件访问时间来查找文件,-n指n天以内,+n指n天以前
-mtime [-n] [+n] //通过文件更改时间来查找文件,-n指n天以内,+n指n天以前
-perm [777] //通过执行权限来查找
-user [username] //通过文件属主来查找
-group [groupname] //通过文件所属组来查找
-nouser //查无有效属主的文件,即文件的属主在/etc/passwd中不存
-nogroup //查无有效属组的文件,即文件的属组在/etc/groups中不存在
-prune //查找时忽略某个目录
-mount //查找文件时不跨越文件系统mount点
-follow //如果遇到符号链接文件,就跟踪链接所指的文件
● grep
功能:在指定文件中搜索字符串并打印出来
使用方法:grep [选项] [要搜索的字符串] [文件]
补充:-i 忽略 大小写; -n 顺便输出行号;-v 反向选择; -c 计算找到该字符串的次数;-a 将binary文件以text文件的方式搜寻数据; --color==auto 将找到的字符串加上颜色显示。
1.5 与时间相关的指令
● date
功能:时间显示
使用方法:date +%F-%X
补充:%Y 年;%m 月;%d 日;%F 相当于%Y-%m-%d;
%H 时;%M 分;%S 秒;%X 相当于%H:%M:%S。
● 时间戳
使用方法:时间 -> 时间戳: date +%s
时间戳 -> 时间:date -d@[时间戳]
补充:Unix时间戳是从1970年1月1日开始所经历的秒数,不考虑闰年。
1.6 与权限相关的指令
系统操作权限: 管理员root权限 和 普通用户权限,使用su - root切换,exit退出。
对用户的分类:所属者-u 所属组-g 其他-o
对操作的分类:可读-r 可写-w 可执行-x
修改文件的权限:读权限:chmod u ± \pm ± r / g ± \pm ± r / o ± \pm ± r [filename]
写权限:chmod u ± \pm ± w / g ± \pm ± w / o ± \pm ± w [filename]
可执行权限:chmod u ± \pm ± x / g ± \pm ± x / o ± \pm ± x [filename]
粘滞位:对于其他用户来说,在修饰了粘滞位的目录中可以创建文件,只能由超级管理员、该目录的所属者、改文件的所属者删除,不能删除他人的文件
chmod +t [filename]
1.7 常用的操作
ifconfig、man、shutdown、ping、whoami、adduser、passwd
二、常用工具
2.1 yum
yum list
yum search
yum install
yum remove
2.2 vim编辑器
vim有三种模式:[普通模式]、[插入模式]、[底行模式]。三种模式的切换如下图。vim的使用我分为7个字来说:移、删、复、替、撤、更、跳。这些使用的命令均是在[普通模式]下,即需要按下Esc键退出到[普通模式]。
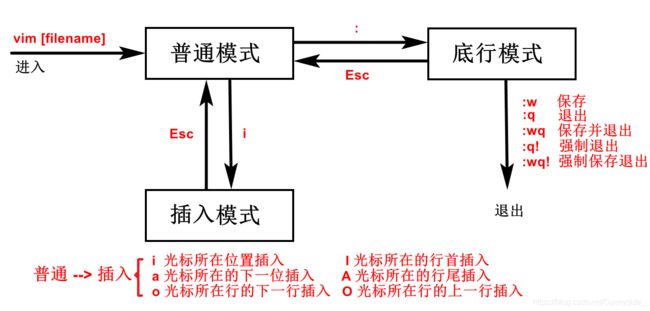
● 移动
- gg 跳转到当前文本的首部
- G 跳转到当前文本的尾部
- w 以一个单词为基准向后移动 (word)
- b 以一个单词为基准向前移动 (back)
- ctrl + f 以“页”为基准向前翻页 (forward)
- ctrl + b 以“页”为基准向后翻页 (back)
● 删除
删除单个字符
- x 删除光标当前所在字符
- X 删除光标之前的一个字符
删除整行或多行
- dd 删除光标所在行的数据
- [num] dd 从光标所在行开始,删除num行数据
● 复制
-
yy 复制光标所在行的数据
-
[num] yy 从光标所在行开始,复制num行数据
-
p 向光标的下一行粘贴
-
P 向光标的上一行粘贴
注意:vim中复制粘贴会出现缩进错乱问题
解决方法:在vim的[底行模式]在输入
:set paste,在进入[paste模式]后在按i进入[插入 模式],进行复制粘贴就可以了。退出[paste模式]只需输入:set nopaste即可解除。具体原因和[paste]模式在***中有详细说明。
● 替换
- r 替换光标所在的单个字符
- R 替换多个字符,进入replace模式,然后替换光标所在字符,Esc退出
● 撤销
- u 撤销上一次的操作
- ctrl + r 反撤销
● 更改
- cw 更改光标当前所在字/词,并且会进入插入模式
● 跳转
- [num] G 跳转 到具体某一行
● 注释
- ctrl + v 进入 V_BLOCK 模式
- J(↓)、K(↑)、H(←)、L(→) 选中所要注释的行
- shift + i 输入注释符
- 两次 ESC 退出即可
● 反注释
- ctrl + v 进入 V_BLOCK 模式
- J(↓)、K(↑)、H(←)、L(→) 选中所要反注释的行
- d / x 删除注释符
2.3 gcc与g++编译器
● 预处理(宏替换、条件编译)<生成 test.i 文件>
预处理主要包括:(1)去注释 (2)宏替换 (3)头文件展开 (4)条件编译
操作:gcc/g++ -E [源码文件] -o [预处理之后的文件名称].i
实例:g++ -E test.cpp -o test.i
● 将所有的#define删除,并展开所有的宏定义;
● 处理所有的预编译指令,例如:#if,#elif,#else,#endif;
● 处理#include预编译指令,将被包含的文件插入到预编译指令的位置;
● 添加行号信息文件名信息,便于调试;
● 删除所有的注释:// 、/**/等;
● 保留所有的#pragma编译指令,因为在编写程序的时候,我们经常要用到#pragma指令来设定编译器的状态或者是指示编译器完成一些特定的动作。
● 编译(高级语言 -> 汇编语言)<生成 test.s 文件>
编译主要包括:(1)扫描(词法分析) (2)语法/语义分析 (3)源代码优化 (4)生成汇编指令
操作:gcc/g++ -S [源码文件] -o [编译之后的文件名称].s
实例:g++ -S test.i -o test.s
● 汇编(汇编语言 -> 二进制文件)<生成 test.o 文件>
汇编主要将编译阶段生成的 .s 文件转化成机器可以识别的二进制文件
操作:gcc/g++ -c [源码文件] -o [汇编之后的文件名称].o
实例:g++ -c test.s -o test.o
● 链接(生成可执行文件/库文件)<生成 exe 文件>
链接主要包括:(1)地址和空间的分配 (2)符号决议 (3)重定位
操作:gcc/g++ [汇编之后的文件名称].o -o [链接之后的文件名称]
实例:g++ test.o -o test
● 地址和空间:系统给函数、变量分配地址和空间;
● 符号决议:也可以说地址绑定,分动态链接和静态链接;
● 重定位:假设此时又两个文件A与B。A需要B中的某个函数mov的地址,未链接前将地址置为0,当A与B链接后修改目标地址,完成重定位。
2.4 gdb调试器
程序的发布有debug模式和release模式,Linux中gcc/g++默认的是release模式,因此在使用gdb调试时,必须在源代码生成二进制程序的时候加上 -g 选项。
g++ test.cpp -o test -g //编译
gdb ./test //加载
● 操作
- ( r ) run / start 让代码运行起来
- ( n ) next 逐过程
- ( s ) step 逐语句
- ( c ) continue 继续执行,不再调试
- until 直接运行到指定文件的指定行
- ( l ) list 查看源码文件
● 断点
- ( b ) breakpoint 设置断点
- ( ib ) info breakpoint 查看断点信息
- enable [断点序号] 使当前断点生效
- disable [断点序号] 使当前断点不生效
- delete [断点序号] 删除当前断点
- watch 变量监控,给具体的变量打断点
● 内存
- ( p ) print 打印变量的值
- ( bt ) back trace 查看函数调用栈情况
- ( q ) quit 退出调试
程序在崩溃时,会产生cordump文件。cordump文件叫做核心转储文件,保存的是程序在崩溃之前正在做的事情,以及各个变量的内容。cordump文件的大小取决于core file size的大小,这个可以使用ulimit命令来更改。
常见的错误:
segmentation fault (段错误):11号信号 --> 访问内存越界,访问空指针
double free: 6号信号 --> 是否重复释放
2.5 make与makefile自动化架构工具
make:makefile的解释程序,逐行解释执行makefile中的项目构建规则
makefile:记录项目构架规则流程的文本文件
● makefile的编写规则
格式:
目标对象:依赖对象
[Tab] 编译命令
- 目标对象:想要生成的目标对象
- 依赖对象:生成对象所依赖的对象
- 编辑命令:使用依赖对象生成目标对象的方法
● make解释makefile的规则
-
对比目标对象和依赖对象的最后一次修改时间(目标对象比较新,则不需要重新生成目标对象;反之,依赖对象比较新,需要重新生成目标对象)
-
永远只为生成第一个目标对象而服务
-
如果依赖对象不存在,则会在当前的makefile的编写规则中查找生成依赖对象的方法。
● 预定义变量
-
$^ 所有依赖对象
-
$@ 目标对象
-
$< 所有依赖对象的第一个依赖对象
-
$% 当目标文件是一个静态库文件时,代表静态库的一个成员名
-
$? 所有比目标文件更新的依赖文件列表,空格分隔。如果目标文件时静态库文件,代表的是库文件(.o 文件)
● 通配符
| 通配符 | 使用说明 |
|---|---|
| %.o | 所有以.o结尾的文件 |
| %.c | 所有以.c结尾的文件 |
| %.s | 所有以.s结尾的文件 |
| * | 匹配0个或者是任意多个字符 |
| ? | 匹配任意一个字符 |
| [] | 我们可以指定匹配的字符放在 “[]” 中 |
● 实例
//实例1
test:*.c
gcc -o $@ $^
//实例2
.PHONY: clean //.PHONY的意思是clean是一个伪目标
clean:
-rm -rf *.o
clean的规则不要放在文件的开头,不然,这就会变成 make 的默认目标。有个不成文的规矩是——“clean 从来都是放在文件的最后”。
2.6 git版本管理工具
● 克隆远端仓库
- git clone [url]
● 提交代码到远端仓库
- git 标记:git add [filename/foldername]
- 提交到本地仓库:git commit -m “日志信息”
- 推送到远端仓库:git push origin master
● 删除远端仓库内容
- git rm [filename/foldername]
- git commit -m "×××"
- git push orgin master