3D目标检测论文汇总
https://zhuanlan.zhihu.com/p/97397273
-
目标检测最新进展总结与展望 2019
一、单目图像下的3D目标检测
-
从单幅图像到双目立体视觉的3D目标检测算法
1.1谷歌最新论文:从图像中进行3-D目标检测 “MobilePose: Real-Time Pose Estimation for Unseen Objects with Weak Shape Supervision“
1.2 GS3D:An Effcient 3D Object Detection Framework for Autonomous Driving
自动驾驶领域下的单目图像3D物体检测
- https://zhuanlan.zhihu.com/p/94193850
-
GS3D:一种用于自动驾驶的高效3D物体检测框架(中文全文)
-
论文https://arxiv.org/abs/1903.10955?context=cs.CV
-
GS3D An Efficient 3D Object Detection Framework for Autonomous Driving算法解析
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
港中文和商汤科技的王晓刚教授团队出品,研究方向是3D目标检测任务。
文章贡献
- 基于可靠的2D检测结果,提出了一种单纯依靠单目摄像头数据的方法有效地为目标获取粗糙的基本3D长方体边界框。该长方体提供了目标的位置,尺寸,方向的可靠近似,可以作为未来精细化调整提供指导;
- 利用2D图像上的投影3D边界框可见表面上潜在的3D结构信息,提出使用从这些表面提取的特征解决之前方法仅仅使用2D边界框特征时存在的特征模糊问题。通过表面特征的融合,模型可以达到更好的判断能力并且提升细化精度;
- 设计并研究了一些精细化方法并得出结论。基于离散分类的具有质量敏感损失的方法比直接对3D边界框细化任务进行回归的方法要更好。
GS3D
下图显示了GS3D框架的整体流程。

GS3D框架整体流程图
有上图可以看出,整个流程的步骤包括CNN的检测器获取2D边界框和方向、生成叫做指南的基本长方体、2D边界框的特征融合为具有区分度的结构化信息用于消除特征模糊、融合特征用于3D子网的CNN改进指南。下面分别详细介绍这四个步骤。
2D检测和方向预测
这一步是基于Faster R-CNN框架进行的改进,增加了一个方向预测的分支,如下图所示,统称为2D+O子网络。这块的做法有点类似人脸的方向预测,应该是有所借鉴。

2D检测和方向预测结构
指导生成
基于可信赖的2D检测结果可以预测每个2D边界框的3D边界框。在特定的场景中,比如自动驾驶场景下,相同类别的实例对象尺度的分布是低方差和单峰的,只需要使用一个固定的对应关系就可以。本文是基于自动驾驶场景的,所以通过分析得到了一个关系公式,将其作为生成3D边界框的指导。
表面特征提取
接下来,使用给定的3D边界框(即上一步得到的指导)投影表面区域来提取3D结构指定的特征,以便更准确的确定。表面特征提取步骤的效果示意图如下所示。

3D边界框表面特征提取
除了使用3D边界框表面提取的特征外,还使用了来自2D边界框所提取的特征来提供纹理信息。将上述两个特征进行融合后为最后细化步骤所使用。
细化方法
文章指出,大范围内的回归通常不会比离散分类更好,因此将残差回归转换为3D边界框改进的分类任务。主要思想是将残余范围分成几个区间,并将残差值分类到一个区间。由于指导可能来自2D边界框的误报,因此将区间视为多个二分类问题。训练期间,如果所有类别的置信度都非常低时,可以将指导视为背景并在前向计算中不使用。作者期望分类中预测的置信度反映相应类别的目标框的质量,从而让更准确的目标框获得更高的分数,因此训练过程中使用BCE作为损失函数,具体公式见论文。
实验
作者在KITTI目标检测基准测试集上评估了文章提出的框架。评估模型的2D子网络和3D子网络都是基于VGG-16。2D子网络使用ImageNet预训练的模型参数进行初始化,在训练期间,2D子网络的训练模型被用于对3D子网络进行初始化。
主要分成几个步骤:
1、 二维box的定位、类别判断、以及角度预测
2、 物体的3d box尺寸的预估,以及3d box在相机坐标系下的位置粗略计算
3、 物体3d box的refinment
该文是提供一个在自动驾驶的单目图像3D目标检测框架。其努力是提取2D图像的基础3D信息,并确定没有点云或立体图像数据的目标3D边框。它利用现成的2D目标检测器,可以有效地为每个预测的2D边框获得粗糙的长方体(cuboid)。这个长方体精度还可以,能指导细化过程确定目标的3D边框。
与仅用2D边框提取特征进行细化的方法不同,该系统采用可见表面的视觉特征来探索目标的3D结构信息。它利用曲面的特征来消除仅用2D边框所带来的表示歧义问题。
如图所示是歧义的示例:3D框彼此之间差别很大,只有左侧的框是正确的,但它们对应的2D边框完全相同。

该方法的关键思想的直观介绍如下图:(a)首先预测可靠的2D边框及其观察方向。 (b)基于预测的2D信息,利用技术有效地确定对应目标的基本长方体,称为引导(guidance)。 (c)从投影可见表面及其紧密的2D边框提取的特征,模型通过分类和质量-觉察的损失函数进行精确的细化过程。

2D检测方面,该方法添加朝向预测分支修改faster R-CNN框架,如图所示。
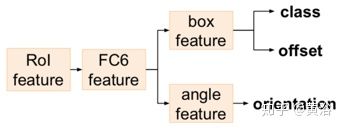
而整个3D目标检测范例如图所示:基于CNN的模型(2D+O subnet)获取2D边框和目标的观察方向O(Observation direction);然后,通过2D检测器获得2D边框和有投影矩阵的方向,生成前面提到的引导部分。从可见表面提取的特征以及投影引导的2D边框用于细化模型(3D子网)。 这个细化模型不是直接回归,而是通过基于质量-觉察损失项的分类操作获得更准确的结果。

3D引导的估算方法基于自动驾驶设置的一些发现。 目标3D边框的顶部中心在2D平面上非常接近其2D边框顶部中点的投影;而类似地,3D边框底部中心的投影接近2D边框并位于其上方。其理由见以下事实:大多数目标顶部位置的投影非常接近2D图像的消失线,因为摄像头位于行驶场景中数据收集车的顶部,而其他目标和它具有相似的高度。
朝向角的解释见下图,即观测角α和整体转角θ的俯视图:蓝色箭头代表观察轴,红色箭头代表汽车的行驶方向;作为右手坐标系,正旋转是顺时针方向。

表面特征提取的方法基于3D边框的投影表面区域(引导),下图给出一个例子,可见的投影表面分别对应于以浅红色、绿色和蓝色示出的目标的顶部、左侧和背面。由于所有感兴趣目标都在地面上,因此底面始终是不可见的,主要用顶面提取特征。对于其他4个表面,可以通过目标的观察方向确定可见性。

从可见表面提取的特征是连接在一起的,用卷积层压缩通道数并融合不同表面的信息。如图所示,还需要从2D边框提取特征提供上下文信息。将2D边框特征与融合的曲面特征连接在一起,最后用于细化。

大范围的回归通常不比离散分类好,因此将残差回归转换为3D边框细化的分类过程。其主要思想是将残差范围划分为多个区间,识别残差值是位于其中一个区间。
2D子网和3D子网均基于VGG-16 网络体系结构。 2D子网通过ImageNet数据集预训练的分类模型初始化参数。然后用训练的2D子网模型初始化训练的3D子网参数。最后看实验结果的例子,如图所示:最后一行两个图像的红色框显示了典型失败案例;在左图,右下角的汽车框(红色)位置与真实汽车有明显的偏差;在右图,红色虚线框是模型误认为的负框。

1.3 Pseudo-LiDAR from Visual Depth Estimation 2019CVPR
作者:Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger
论文链接:https://arxiv.org/abs/1812.07179
项目链接:https://mileyan.github.io/pseudo_lidar/
代码链接:https://github.com/mileyan/pseudo_lidar
- https://blog.csdn.net/weixin_30426065/article/details/101934911
- https://blog.csdn.net/wqwqqwqw1231/article/details/103300948
- https://zhuanlan.zhihu.com/p/91479831
-
cvpr2019-伪雷达3D目标检测 解读
本文提出了一个重要观点:使用图像做三维目标检测,其效果差不是因为使用图像得到的深度信息不准确,而是因为使用前视图这种表示方式的问题。
由于本文并未提出什么新的网络,所以这篇paper的解读与其他的结构不太一样。
检测结构

上图为本文提出的检测结构,整体分为两步走,第一步通过计算Depth Map,恢复出Pseudo LiDAR,第二部使用融合图像和点云的方法检测三维物体。
深度估计:本文算法与深度估计部分无关,这里可用单目深度估计或者双目深度估计,本文采用双目深度。
双目深度估计输入一对左右图像Il,Ir,输出与任意一图像大小相同的视差图Y(disparity map)。本文假设左图为参考图像,并在Y矩阵中存每个像素相对于右图的水平视差。由下式得到深度图:(其中fU为左图的水平方向的焦距)

这里补充下双目相机的视差估计原理(下图截自SLAM十四讲):


生成Pseudo-LiDAR数据:
在左图的相机坐标系中为每个像素(u,v)反投影的到3D坐标(x,y,z):((cU,cV)是像素坐标原点相对与相机中心的位置偏移,fV是垂直焦距)。将所有的像素点都反投影到3D坐标,得到3D点云{(x(n),y(n),z(n))}Nn=1(N为像素数目)。
Depth Map -> Pseudo LiDAR: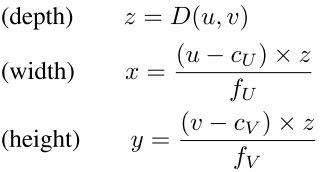
说白了就是将深度图(u, v, d)的表示方式转为点云的表示方式(x, y, z)。
然后就是对Pseudo LiDAR的处理,就是丢掉一些超出一定x,y,z边界的点,例如高于激光雷达1m的点丢弃掉等。
对使用Pseudo LiDAR有效性的解释
这块内容主要是在Data representation matters这一节中讲的,其实我对这一节的解释很不认可。
首先先说一下文中的解释:
文中首先提到了convolution有两个假设:
- local neighborhoods in the image have meaning, and the network should look at local patches
- all neighborhoods can be operated upon in an identical manner
然后提到在前视图中其实并不满足这两个假设:
- local patches on 2D images are only coherent physically if they are entirely contained in a single object. If they straddle object boundaries, then two pixels can be co-located next to each other in the depth map, yet can be very far away in 3D space. 二维图像上的局部面片只有在完全包含在单个对象中时才是物理相干的。如果它们跨越对象边界,那么两个像素可以在深度图中彼此相邻,但在三维空间中却可能非常遥远。
- objects that occur at multiple depths project to different scales in the depth map. A similarly sized patch might capture just a side-view mirror of a nearby car or the entire body of a far-away car. Existing 2D object detec- tion approaches struggle with this breakdown of assumptions and have to design novel techniques such as feature pyramidsto deal with this challenge.出现在多个深度的对象在深度图中投影到不同的比例。同样大小的patch可能只捕捉到附近汽车的侧视镜或远处汽车的整个车身。现有的2D对象检测方法与这种假设的分解相抗衡,必须设计新颖的技术,如特征金字塔来应对这一挑战。
我觉得第一个解释有点牵强:是因为在处理图像时,局部的patch如果在边缘上,其像素intensity的距离可能很大。所以CNN能够处理纹理边缘,为什么不能处理深度边缘?
第二点的解释其实就是说,俯视图的好处是要预测的box的大小与车辆的远近没有关系。但这种scale的变化在图像中就存在,需要用FPN的方法去弥补。
所以我认为,文章中想强调的点就是在Point Cloud中检测,或者在俯视图中检测可以带来不用处理scale的好处。而这一点正是巨大涨点的原因!
然后作者在本节也提供了一个实验,但我并不觉得这个实验有什么用。图片中,车辆与背景存在遮挡,车辆与背景的深度相差很大,在边缘做个滤波,简单的理解就是平均一下,很容易就将边缘的点拉的离真实很远,这个事实很好理解。但我还是认为,CNN能处理纹理边缘,同样能处理深度边缘。
我认为本文合理的解释是在Experiment这个部分中:
“while performing local computations like convolutions or ROI pooling along height and width of an image makes sense to 2D object detection, it will oper- ate on 2D pixel neighborhoods with pixels that are far apart in 3D, making the precise localization of 3D objects much harder”
我的理解是:在对box进行预测时,2D中的anchor或者proposal中包含了很多neighborhood的信息,但这些图像空间内的neighborhood在三维空间中离得很远,所以会产生很大的干扰。
实验
本文的实验做的非常充分。总体来说就是先找一些baselines, 使用图像做三维检测方法,MONO3D [4], 3DOP [5], and MLF [33]。
然后使用PSMNET [3], DISPNET [21], and SPS-STEREO [35]得到深度图,将其转为Pseudo LiDAR,再用F-PointNet和AVOD去检测,得到的结果与baseline做比较。效果要好很多。
实验结果拿到了使用图像做三维目标检测的第一,效果非常好。但我觉得这个实验与本文章强调的点还有一些距离:
1、感觉实验没有比摆脱一个问题:是不是有可能Frustum-PointNet和AVOD的性能就是强!
因为本文是想强调,使用图像效果差的原因是在数据的表示方面,而不是精度方面。我的分析是说,其实这个差别可能是在在俯视图中检测可以带来不用处理scale的好处。所以我认为还可以检测网络相同,不同点只是用俯视图和前视图的实验。例如使用FasterRCNN或者FPN,只是把最后的回归头的回归量的数量由2D的4个变成3D的7个(x, y, z, w, h, l, angle-z)
2、另外一点,文章强调:使用图像做三维目标检测,其效果差不是因为使用图像得到的深度信息不准确,而是因为使用前视图这种表示方式的问题。但可以看到使用Pseudo LiDAR的效果还是要比使用激光雷达差很多的。这个在文章中并没有详细讨论。可以从原文的Table I中可以看到,只有AVOD,IoU=0.5,Easy情况下,AP差不多,其他情况下,差的还是挺多的。这是否是由于恢复的三维信息不准确而产生的?我能想到的实验,是用激光点替换一部分用双目视觉恢复的深度点,替换的数量递增,看看是否效果也能递增。从而解释最终结果的gap。另外一个实验,可以将激光点云投影到前视图,做成深度图,看看效果会下降多少。
总体而言,这篇文章的idea很明显,实验效果也很好!
1.4 3D Bounding Box Estimation Using Deep Learning and Geometry
- 3D Bounding Box Estimation Using Deep Learning and Geometry(中文)
- https://blog.csdn.net/qq_29462849/article/details/91314777
- https://zhuanlan.zhihu.com/p/64617445 翻译
- https://zoox.com/
-
自动驾驶--Deep3DBox
-
Apollo感知模块:(基于单目的摄像头物体检测)
-
实现代码 https://github.com/smallcorgi/3D-Deepbox
-
Deep3Dbox 复现笔记【附部分code】
本文是3D Bounding Box Estimation Using Deep Learning and Geometry的论文笔记及个人理解。这篇文章是单目图像3d目标检测的一个经典工作之一。其目的是从输入图片中提取3d bounding box。也是3d bounding box estimation的早期经典工作。本文的核心思路为:
- 根据2d bounding box与3d bounding box的约束关系构建了一组欠定方程组。
- 利用几何约束关系及bbox先验对该方程组的未知量自由度(freedom of degree)进行下降。
- 使用CNN对该方程组中的部分未知量进行预测,进一步下降自由度。
- 将23步骤的结果带入方程组,方程组转化为超定方程,可以进行求解。
0. 先修知识:
3d point与2d pixel之间存在一个投影关系,即:
![]() Eq. (1)
Eq. (1)
其中K是相机内参矩阵,R是旋转矩阵,T是平移。[R T]在一起就是仿射变换。大写Xo是3d空间的point,x是2d pixel。这个公式反应了图像坐标系与任意3d坐标系之间的关系。现在稍微解读下这个式子:

Xo是三维空间的点:表示为[x,y,z,1](齐次坐标)。[R T]为三维空间的旋转和平移变换,其反应了如何从当前点所属的三维空间坐标系变换到三维摄像机坐标系(坐标系变换可以可以参考线性代数中的基变换进行理解,也可以参考我上面的图,不同的三维坐标系就是基和原点的方向不同)。[R T]Xo则是将当前给定的point转化为摄像机坐标系下的point。之后我们可以根据相机模型(比如针孔相机模型)将摄像机坐标系下的三维点投影到图像坐标系下(通过矩阵K,即相机内参矩阵)。这里补充一下,相机内参矩阵其实潜在包含了两次坐标映射,一次是将三维坐标通过针孔相机模型投影到相机感光器件坐标上(这一步需要相机的焦距)。第二步是将底片坐标转化成图像坐标(需要感光器件的物理间距)。这些参数(焦距,感光器件间距)统称为相机内参。所以K[R T]Xo为Xo在图像像素上对应的坐标点。值得注意的是,如果Xo所处的三维空间坐标系是不同的,[R T]也是是不同的,如果三维空间坐标系是世界坐标系,[R T]也称为相机外参矩阵。
1. 目标坐标系:
在本论文中,Xo所属的三维空间坐标系就不是世界坐标系,而是目标坐标系(object坐标系),其可以定义为以3d bbox中心为原点,坐标轴垂直于盒子的各个平面:
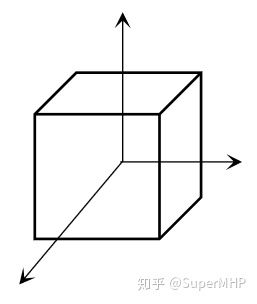
object 坐标系
那么如果三维空间坐标系是object坐标系,[R T]就会变得物理含义很强了。R反应了坐标系旋转关系,因为object坐标系的每个轴都垂直于bbox的各个平面,所以bbox的旋转就可以等价于坐标系在旋转,因此R可以反应3d bbox的旋转关系。而T在坐标变换中往往反应的是原点的对应关系,所以此处可以得到T反应的就是当前bbox所属的object坐标系的原点值,也就是当前3d bbox的centre的坐标(摄像机坐标系下的坐标)。这也就是为什么原文在Eq (1)中直接假设了R, T分别是bbox旋转角度和中心坐标的原因。这里也建议结合论文理解。
2. 3D bbox与2D bbox之间存在的约束关系
根据Eq. (1)。我们很容易将3D bbox投影到2D图像上,画下来就是这个样子:

从这里我们可以看出,对于投影在图像上的3d框,我们总可以用一个2d框包在外面。如下图:

那么从这里我们就可以很清晰的看出对应关系了。3d bbox的8个角点会对外围的2d bbox起到决定性作用。那么首先,假设3d bbox的长宽高分别为dx,dy,dz,然后我们就可以在object坐标系(关于object坐标系,可以看一下0章节的后面)中将3d bbox的角点表现出来:

然后我们可以把这些点根据Eq (1)投影到2d 图像坐标系,那么很容易获得一系列的对应关系,原文给出了xmin与3d bbox节点坐标的对应关系:

*tips: 这里之所以是最小的y对应图像空间最小的x,是取决于三维坐标系中y轴的定义。那么因为2d bbox存在四个点。所以根据xmin,ymin,xmax,ymax可以写出上述形式的式子共四个。这即为2d bbox与3d bbox构成的四个约束方程。而这组方程组中待求解参数有9个(仿射变换参数6个,bbox尺寸3个)。显然4个方程是解不出9个未知量的(欠定方程组)。那么如何解决这个问题,即为本文核心的idea。
3. 约束关系
原文在此段的描述比较详细,这里简单叙述下核心论点。
- 如何建模3d bounding box: 如果按照节点建模,过于复杂(8个点的排列组合高达上千种)。这里我觉得不重要,没人会这样建模吧= =。
- 先不考虑目标的具体位置,仅回归目标的大小,作者称这一步是顾及稳定性。
- 旋转角度先验:即汽车是在路面行驶,所以仅需考虑偏行角(yaw angle)。偏航角就是对应汽车左右拐弯的角度。另外两个角度分别对应汽车上下坡,和单边侧倾。文章认为不太需要考虑后两者。
- 预测相对角度而非绝对:即文章4.1的内容。首先文章剖析了绝对角的问题。绝对角即目标真实的旋转角度。参考下图可以发现绝对角的问题。

汽车是直线行驶,但是随着位移的改变,其局部图像上看似乎发生了旋转,这是因为相机拍摄的原因,导致相对角度发生了变化,看上去就像汽车在旋转一样。这种特性对于CNN而言极其不利,因为如果采用绝对角作为ground truth。CNN需要将看上去转角不同的图像映射到同一个答案上,这是非常不利的。所以本文采用了局部相对角作为答案,即去回归目标相对相机射线的夹角。
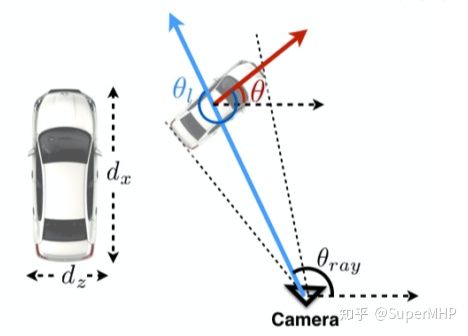
即图片中的theta_l。这个角度由目标绝对角度(theta)与相机射线角度 (theta_ray)共同决定。根据图像区域的关系,theta_ray是可以计算的,所以CNN只需估计相对角,我们就可以根据两个角度结合起来计算真正的目标绝对角度了。
综合这些而言,作者最后希望CNN去回归如下参数:目标相对角度,目标的尺寸。
4. 基于卷积神经网络的预测模型
网络模型没有太多新颖之处,首先基于2D检测器将2D bbox找出,将2D RoI区域输入神经网络,网络主干是三个stream,分别预测尺寸,转角与得分。
网络框架没什么值得细说的,下面说下ground truth的定义。首先本文的检测头也采用了以往2D检测中经常采用的anchor的设置,关于anchor的概念,不了解的可以先去看看faster rcnn。本文的anchor setting如下:
- 统一尺寸:即anchor尺寸仅设置一个,为所有object在数据集上的平均尺寸
- 不同的夹角:将360度转角划分成n个具备overlap的区间。
所以可以看出最终的anchor会有n个。而每一个2d roi都会根据这n个anchor计算结果,最终只保留最高得分的结果。那么接下来是ground truth的定义:
- dimensions: 真实bbox与anchor的差值。(原文中对应公式5)
- 转角:真实bbox与anchor转角的差值。(原文对应公式4)
- 得分:利用softmax预测bbox属于哪一个转角区间,所以其本质上反应的是anchor与真实bbox的角度匹配程度。
5. 位置预测(参考原文的supplementary)
CNN预测了转角与尺寸之后,由bbox构建的4个约束中的9个位置量仅剩三个了(三个转角先被先验简化成了一个,然后被CNN预测了。尺寸三个量被CNN预测,仅剩余bbox中心位置三个量了)。那么很容易就可以根据四个方程解出三个未知量,即bbox的中心位置。
以上就是该论文的内容。作为单目图片3d检测的早期工作,内容也十分经典。主要贡献在于给出了一套合理的包围盒回归方案。给出了相对角的定义,便于回归。当然原文也遗留了一些疑问,比如不知道为什么不使用CNN直接预测bbox的位置,而要回到方程组上。这些还需要进一步的思考
1.5 YOLO-6D (Real-Time Seamless Single Shot 6D Object Pose Prediction)
-
YOLO6D
-
【2018CVPR】实时单目6D物体姿态估计
-
【深度学习】目标检测之YOLOv2算法&6D姿态估计之YOLO-6D算法
-
Pytorch实现的YOLO-6D https://github.com/Microsoft/singleshotpose/
-
参考https://zhuanlan.zhihu.com/p/41790888
阅读本文之前需要对yolo算法有所了解,如果不了解的可以看我的两篇文章:
stone:你真的读懂yolo了吗?zhuanlan.zhihu.com stone:yolo v2详解zhuanlan.zhihu.com
stone:yolo v2详解zhuanlan.zhihu.com
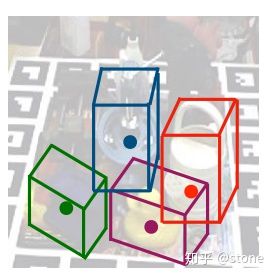
2D图像的目标检测算法我们已经很熟悉了,物体在2D图像上存在一个2D的bounding box,我们的目标就是把它检测出来。而在3D空间中,物体也存在一个3D bounding box,如果将3D bounding box画在2D图像上,那么长这样子:

这个3D bounding box可以表示一个物体的姿态。那什么是物体的姿态?实际上就是物体在3D空间中的空间位置xyz,以及物体绕x轴,y轴和z轴旋转的角度。换言之,只要知道了物体在3D空间中的这六个自由度,就可以唯一确定物体的姿态。
知道物体的姿态是很重要的。对于人来说,如果我们想要抓取一个物体,那么我们必须知道物体在3D空间中的空间位置xyz,但这个还不够,我们还要知道这个物体的旋转状态。知道了这些我们就可以愉快地抓取了。对于机器人而言也是一样,机械手的抓取动作也是需要物体的姿态的。因此研究物体的姿态有很重要的用途。
Real-Time Seamless Single Shot 6D Object Pose Prediction这篇文章提出了一种使用一张2D图片来预测物体6D姿态的方法。但是,并不是直接预测这个6D姿态,而是通过先预测3D bounding box在2D图像上的投影的1个中心点和8个角点,然后再由这9个点通过PNP算法计算得到6D姿态。我们这里不管怎么由PNP算法得到物体的6D姿态,而只关心怎么预测一个物体的3D bounding box在2D图像上的投影,即9个点的预测。
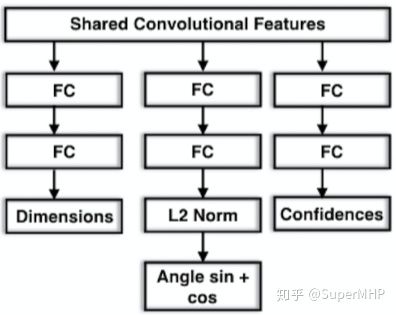
1. 思想
上面已经讲到,我们把预测6D姿态问题转为了预测9个坐标点的问题。而在2D的目标检测中,我们实际上也是需要预测坐标点xy的。那么,我们能不能把目标检测框架拿来用呢? 很显然是可以的。所以这篇文章就提出基于yolo的6D姿态估计框架。
2. 网络架构
整个网络结构图如下:

从上图可以看到,整个网络采用的是yolo v2的框架。网络吃一张2D的图片(a),吐出一个SxSx(9x2+1+C)的3D tensor(e)。我们会将原始输入图片划分成SxS个cell(c),物体的中心点落在哪个cell,哪个cell就负责预测这个物体的9个坐标点(9x2),confidence(1)以及类别(C),这个思路和yolo是一样的。下面分别介绍这些输出的意义。
3. 模型输出的意义
上面已经提到,模型输出的维度是13x13x(19+C),这个19=9x2+1,表示9个点的坐标以及1个confidence值,另外C表示的是类别预测概率,总共C个类别。
3.1 confidence的意义
confidencel表示cell含有物体的概率以及bbox的准确度(confidence=P(object) *IOU)。我们知道,在yolo v2中,confidence的label实际上就是gt bbox和预测的bbox的IOU。但是在6D姿态估计中,如果要算IOU的话,需要在3D空间中算,这样会非常麻烦,因此本文提出了一种新的IOU计算方法,即定义了一个confidence函数:

其中D(x)是预测的2D点坐标值与真实值之间的欧式距离,dth是提前设定的阈值,比如30pixel, alpha是超参,作者设置为2。从上图可以看出,当预测值与真实值越接近时候,D(x)越小,c(x)值越大,表示置信度越大。反之,表示置信度越小。需要注意的是,这里c(x)只是表示一个坐标点的c(x),而一个物体有9个点,因此会计算出所有的c(x)然后求平均。
另外需要注意的是,图上的那个公式是错的,和函数图对应不起来,真正的公式应该是:
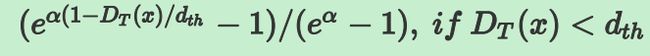
通过以上定义的confidence函数,就可以代替IoU的计算。
3.2 坐标的意义
上面讲到网络需要预测的9个点的坐标,包括8个角点和一个中心点。但是我们并不是直接预测坐标值,和yolo v2一样,我们预测的是相对于cell的偏移。不过中心点和角点还不一样,中心点的偏移一定会落在cell之内(因为中心点落在哪个cell哪个cell就负责预测这个物体),因此通过sigmoid函数将网络的输出压缩到0-1之间,但对于其他8个角点,是有可能落在cell之外的,所以我们没有对8个角点预测添加任何限制。因此坐标偏移可以表示为:
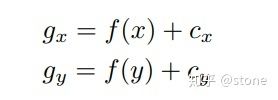
其中cx,cy表示cell的坐标。对于中心点而言,f(.)表示sigmoid函数,对于角点而言,f(.)表示恒等函数。
3.3 类别的意义
类别代表的意义很简单,就是指预测的类别概率,不过这是一个条件概率P(class/object),因为我们在训练的时候,只会在有物体的情况下才计算概率损失,这个和yolo是一样的。
3.4 多目标检测
以上讲的只是对于单目标的情况,如果是多目标的话,某个cell可能会落入多个物体,这个时候就需要使用anchor了,引入anchor之后,网络的输出相应地变为:13x13x(19+C)×anchors,这篇文章使用的anchor数目为5。引入anchor就需要考虑一个问题,如果一个物体落入了某个cell,那么这个cell中的哪个anchor去负责这个物体?这篇文章中的做法和yolo一样,就是去表物体的2D bounding box和anchor的尺寸,最匹配的那个anchor就负责这个物体。
4. 训练
4.1 损失函数
yolo的损失函数是很复杂的,具体计算方法可以参考我yolo v2的文章,唯一的区别就是IOU的计算方式发生了变化,其它没变。如果不考虑细节的话,可以简单的表示为:

Lpt,Lconf和Lid分别表示坐标点,confidence和分类的损失。前面的系数表示各项损失的权重。
4.2 训练技巧
- 数据的预处理。
对于输入图片进行大量的图像增强,另外做了换背景操作,即通过物体的mask将物体提取出来,然后粘贴到coco的数据集的图片上。
- 由于一开始网络的confidence预测是很不准的,因此在训练的早期,将损失函数中的 设置为0。也就是说不训练confidece。等坐标预测的结果变准的时候,这时候再将有物体cell设置 , 没有物体的cell设置 。
- 多尺度训练。这和yolo v2的多尺度训练的思想是一样的,由于输入图片到grid之间的缩小比例为32,因此本文设置了{320,352,..., 608}11种尺度进行训练。
5. 实验结果
以下展示一些检测结果:

可见检测效果还是不错的。
6. 总结
这篇文章实际上将6d姿态问题转为了2D图像中坐标点检测的问题,而2D坐标点的检测问题可以很好地利用目标检测框架来做。当然,这种做法会有一个问题,就是即使你在2D上坐标的检测误差很小,但映射到3D空间中可能会存在较大的误差。当然,这可能是2D图像作为输入的6D姿态估计算法都会面临的问题。不过这篇文章的这个思路还是很值得借鉴的。
1.6 SSD-6D Making RGB-Based 3D Detection and 6D Pose Estimation Great Again
- 代码复现
- 原论文作者github地址 论文链接
-
SSD-6D论文阅读 SSD-6D解读
-
3D目标检测&6D姿态估计之SSD-6D算法--by leona

Fig.9 SSD-6D Architecture, figure from reference[6]
SSD-6D的模型结构如上图Fig.9所示,其关键流程介绍如下:
输入为一帧分辨率为299x299的三通道RGB图片
输入数据先经过Inception V4进行特征提取和计算
分别在分辨率为71x71、35x35、17x17、9x9、5x5、3x3的特征图上进行SSD类似的目标值(4+C+V+R)回归,其中目标值包括4(2D包围框)、C(类别分类得分)、V(可能的视点的得分)和R(平面内旋转)
对回归的结果进行非极大抑制(NMS),最终得到结果
关键点:
Viewpoint classification VS pose regression:
作者认为尽管已有论文直接使用角度回归,但是有实验证明对于旋转角的检测,使用分类的方式比直接使用回归更加可靠,特别是使用离散化的viewpoints比网络直接输出精确数值效果更好
Dealing with symmetry and view ambiguity:
给定一个等距采样的球体,对于对称的目标物体,仅沿着一条弧线采样视图,对于半对称物体,则完全省略另一个半球,如图Fig.10所示

Fig.10 discrete viewpoints, figure from reference[6]
效果:

Tab.1 F1-scores for each sequence of LineMOD, table from reference[6]
1.7 单张图像估测物体三维位置 MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization
- 论文解读https://blog.csdn.net/abrams90/article/details/98484420
-
代码安装测试 MonoGRNet:一种用于单目三维物体检测和定位的几何推理网络
-
Zengyi-Qin/MonoGRNetgithub.com
在图像中,传统的物体定位或检测估计二维边界框,可以框住属于图像平面上物体的可见部分。但是,这种检测结果无法在真实的 3D 世界中提供场景理解的几何感知,这对很多应用的意义并不大。
代表论文:MonoGRNet:A Geometric Reasoning Network for Monocular 3D Object Localization
论文链接:https://arxiv.org/abs/1811.10247
该论文提出了使用 MonoGRNet,从单目 RGB 图像中通过几何推断,在已观察到的二维投影平面和在未观察到的深度维度中定位物体非模态三维边界框(Amodal Bounding Box, ABBox-3D),即实现了由二维视频确定物体的三维位置。
MonoGRNet 的主要思想是将 3D 定位问题解耦为几个渐进式子任务,这些子任务可以使用单目 RGB 数据来解决。网络从感知 2D 图像平面中的语义开始,然后在 3D 空间中执行几何推理。这里需要克服一个具有挑战性的问题是,在不计算像素级深度图的情况下准确估计实例 3D 中心的深度。该论文提出了一种新的个体级深度估计(Instance Depth Estimation, IDE)模块,该模块探索深度特征映射的大型感知域以捕获粗略的实例深度,然后联合更高分辨率的早期特征以优化 IDE。
为了同时检索水平和垂直位置,首先要预测 3D 中心的 2D 投影。结合 IDE,然后将投影中心拉伸到真实 3D 空间以获得最终的 3D 对象位置。所有组件都集成到端到端网络 MonoGRNet 中,其中有三个 3D 推理分支,如下图。最后通过联合的几何损失函数进行优化,最大限度地减少 3D 边界在整体背景下的边界框的差异。

MonoGRNet 由四个子网络组成,用于 2D 检测(棕色),个体深度估计(绿色),3D 位置估计(蓝色)和局部角落回归(黄色)。在检测到的 2D 边界框的引导下,网络首先估计 3D 框中心的深度和 2D 投影以获得全局 3D 位置,然后在本地环境中回归各个角坐标。最终的 3D 边界框基于估计的 3D 位置和局部角落在全局环境中以端到端的方式进行优化。

根据对具有挑战性的 KITTI 数据集的实验表明,该网络在 3D 物体定位方面优于最先进的单眼方法,且推理时间最短。

3D 检测性能,KITTI 验证集上的 3D 边界框的平均精度和 每张图像的推理时间。注意不比较基于 Stereo 的方法 3DOP,列出以供参考。
微软的一篇论文,下图是算法框图:提出instance depth estimation (IDE),不是图像的深度图,可以直接估计物体3-D边框的深度,还是采用ROIalign取代ROIpool;包括4个模块,即2d detection(棕色), instance depth estimation(绿色), 3d location estimation(蓝色) 和 local corner regression(黄色)。

这是估计Instance depth的模型结构:

这个示意图告诉我们3-D边框的图像定位关系:

Instance depth的概念的解释如下图,的确是比较节俭的做法:

一些结果展示:

1.8 M3D-RPN: Monocular 3D Region Proposal Network for Object Detection
- garrickbrazil/M3D-RPNgithub.com

- 解读https://xw.qq.com/cmsid/20200404A0373100
- 视频PPT https://www.bilibili.com/video/av80088903/
- 论文翻译https://blog.csdn.net/c20081052/article/details/100121359
题目:M3D-RPN:Monocular 3D Region Proposal Network for Object Detection
机构:Michigan State University, East Lansing MI
作者:Garrick Brazil, Xiaoming Liu
时间:2019.7.13
代码: http://cvlab.cse.msu.edu/ project-m3d-rpn.html(官方)
github: https://github.com/garrickbrazil/M3D-RPN
以3D方式了解场景是城市自动驾驶的重要组成部分。通常,昂贵的激光雷达传感器和立体RGB图像的结合对于成功的3D对象检测算法至关重要,而单目图像的方法会大大降低性能。
该文提议将单目3D目标检测问题重新构造为独立3D区域提议网络(RPN),即M3D-RPN(Monocular 3D Region Proposal Network for Object Detection),来缩小差距。M3D-RPN利用2D和3D透视图的几何关系,允许3D边框利用图像空间生成的强大卷积特征。
为了帮助解决繁琐的3D参数估计,该方法进一步设计了深度-觉察(depth-aware)的卷积层,可开发特定位置的特征,从而改善了3D场景的理解性能。下图所示,M3D-RPN用全局卷积(橙色)和局部深度-觉察卷积(蓝色)的单个单目3D区域提议网络来预测多类3D边框。

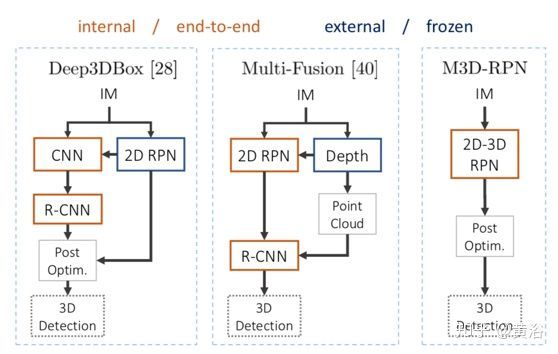
下图是M3D-RPN和以前方法Deep3DBox (CVPR’17) 和Multi-Fusion (CVPR’18) 的比较。注意的是,先前的工作由内部多步(橙色)和外部网络(蓝色)组成,而M3D-RPN是端到端训练的单击(single shot)网络。
下图则是M3D-RPN的概览。 该方法包括并行的全局(橙色)和局部(蓝色)特征提取路径。 全局特征使用规则的空间不变卷积,而局部特征表示深度觉察卷积(右图)。 深度-觉察卷积在行空间ki使用非共享内核,i = 1 . . . b,其中b表示格(bin)总数。为利用两种特征的变化,对来自并行路径的输出参数进行加权组合。

这里有3D锚框(anchor)的应用,如图是锚框的公式化和3D可视化,描绘了2D / 3D锚框公式的每个参数(左图)。 在图像视图(中)和鸟瞰图(右)中投影后,采用12个锚点,从中可以看到预计算的3D先验(prior)。 出于可视化目的,将锚框放置在特定的x3D位置,最大程度地减少从视角看过去的重叠。

其网络的骨干网用DenseNet-121,其中删除了最后的池化层,使网络步幅保持在16,另外将最后一个Dense-Block的卷积层扩大(dilate )2倍,以获得更大的视野。
最后看一个结果图:黄色代表汽车,绿色代表行人,橙色代表自行车。

5、Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image
6、Task-Aware Monocular Depth Estimation for 3D Object Detection
7、
8、Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud
9、Monocular 3D Object Detection and Box Fitting Trained End-to-End Using Intersection-over-Union Loss
10、Disentangling Monocular 3D Object Detection
11、Shift R-CNN: Deep Monocular 3d Object Detection With Closed-Form Geometric Constraints
12、Monocular 3D Object Detection via Geometric Reasoning on Keypoints
13、Monocular 3D Object Detection Leveraging Accurate Proposals and Shape Reconstruction
14、Accurate Monocular Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving
15、3D Bounding Boxes for Road Vehicles: A One-Stage, Localization Prioritized Approach using Single Monocular Images
16、Orthographic Feature Transform for Monocular 3D Object Detection
17、Multi-Level Fusion based 3D Object Detection from Monocular Images
19、Mono3D++: Monocular 3D Vehicle Detection with Two-Scale 3D Hypotheses and Task Priors
二、基于融合的方法RGB图像+激光雷达/深度图的3D目标检测
1、AVOD
2、A General Pipeline for 3D Detection of Vehicles
3、Adaptive and Azimuth-Aware Fusion Network of Multimodal Local Features for 3D Object Detection
4、Deep Continuous Fusion for Multi-Sensor 3D Object Detection
5、Frustum PointNets for 3D Object Detection from RGB-D Data
6、Joint 3D Proposal Generation and Object Detection from View Aggregation
7、Multi-Task Multi-Sensor Fusion for 3D Object Detection
8、Multi-View 3D Object Detection Network for Autonomous Driving
https://blog.csdn.net/hit1524468/article/details/80071631
https://blog.csdn.net/Julialove102123/article/details/77961674
9、PointFusion:Deep Sensor Fusion for 3D Bounding Box Estimation
10、Pseudo-LiDAR from Visual Depth Estimation:Bridging the Gap in 3D Object Detection for Autonomous Driving
三、基于激光雷达点云的3D目标检测
-
【CVPR 2020】Point-GNN 通过图神经网络实现3d目标检测论文解读
- 1、VoteNet 3DSSD
- 2、End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
- 3、Deep Hough Voting for 3D Object Detection in Point Clouds
- 4、STD: Sparse-to-Dense 3D Object Detector for Point Cloud
- 5、PointPillars: Fast Encoders for Object Detection from Point Clouds
- 6、PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
- 7、PIXOR: Real-time 3D Object Detection from Point Clouds
- 8、Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds
- 9、YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud
- 10、Vehicle Detection from 3D Lidar Using FCN(百度早期工作2016年)
- 11、Object Detection and Classification in Occupancy Grid Maps using Deep Convolutional Networks
- 12、RT3D: Real-Time 3-D Vehicle Detection in LiDAR Point Cloud for Autonomous Driving
- 13、BirdNet: a 3D Object Detection Framework from LiDAR information
- 14、IPOD: Intensive Point-based Object Detector for Point Cloud
- 15、PIXOR: Real-time 3D Object Detection from Point Clouds
- 16、DepthCN: Vehicle Detection Using 3D-LIDAR and ConvNet
- 17、YOLO4D: A ST Approach for RT Multi-object Detection and Classification from LiDAR Point Clouds
- 18、PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
- 19、Part-A^2 Net: 3D Part-Aware and Aggregation Neural Network for Object Detection from Point Cloud
- 20、Voxel-FPN: multi-scale voxel feature aggregation in 3D object detection from point clouds
- 21、Fast Point RCNN
- 22、StarNet: Targeted Computation for Object Detection in Point Clouds
- 23、Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection
- 24、LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving
四、基于RGB-D图像下的3D目标检测
- Frustum PointNets for 3D Object Detection from RGB-D Data
- Frustum VoxNet for 3D object detection from RGB-D or Depth images
- 3D目标检测于RGB-D(Object detection in RGB-D images)
五、基于立体视觉下的3D目标检测
1、Object-Centric Stereo Matching for 3D Object Detection
2、Triangulation Learning Network: from Monocular to Stereo 3D Object Detection
3、Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
4、Stereo R-CNN based 3D Object Detection for Autonomous Driving