Pytorch autoencoder降维
1. 我们一般面对的数据是numpy array的格式,如何转变为支持batch_size,shuffle等功能的数据集呢,pytorch 采用 DataLoader类来实现,参考源码
# DataLoader 类的构造函数
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, multiprocessing_context=None):
torch._C._log_api_usage_once("python.data_loader")
# TensorDataset 类,继承了Dataset
class TensorDataset(Dataset)我们采用如下步骤:1. numpy array -> tensor 2.tensor -> dataset 3.通过dataloader加载dataset;具体实现demo如下:
import torch
from torch.utils.data import DataLoader,Dataset,TensorDataset
from sklearn.datasets import load_iris
iris=load_iris()
data=iris.data
tensor_x=torch.from_numpy(data)
my_dataset=TensorDataset(tensor_x)
my_dataset_loader=DataLoader(my_dataset,batch_size=10,shuffle=False)
print(isinstance(my_dataset,Dataset)) # 返回是true
- 一些基本概念
- batch,一般来说会采用梯度下降的方法进行迭代,估计参数;深度学习中一般采用sgd,batch就是每次迭代参数用到的样本量
- epoch,轮训的次数;1个epoch等于使用训练集中全部样本训练一次
- autoencoder原理和作用

针对iris数据集,构建了一个autoencoder模型
class autoencode(nn.Module):
def __init__(self):
super(autoencode,self).__init__()
self.encoder=nn.Sequential(
nn.Linear(4, 3),
nn.Tanh(),
nn.Linear(3, 2),
)
self.decoder=nn.Sequential(
nn.Linear(2, 3),
nn.Tanh(),
nn.Linear(3, 4),
nn.Sigmoid()
)
def forward(self, x):
encoder=self.encoder(x)
decoder=self.decoder(encoder)
return encoder,decoder
- 降维
上图中 Encoded Data 就是降维后的向量,针对sklearn里面的iris数据集,训练一个autoencoder模型,进行降维,最终压缩到2维
import matplotlib.pyplot as plt
x_=[]
y_=[]
for i, (x, y) in enumerate(my_dataset):
_, pred = model(V(x)) # 这里的model为训练好的autoencoder模型
#loss = criterion(pred, x)
dimension=_.data.numpy()
x_.append(dimension[0])
y_.append(dimension[1])
plt.scatter(numpy.array(x_),numpy.array(y_),c=Y)
for i in range(len(numpy.array(x_))):
plt.annotate(i,(x_[i],y_[i]))
plt.show()
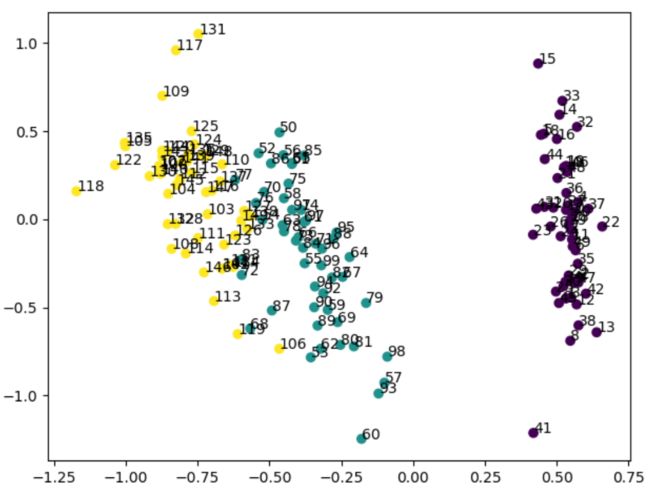
维度降低到2维的时候,还是能比较明显的把类别区分开来。
完整的代码:
import torch.nn as nn
from torch.autograd import Variable as V
import torch
from torch.utils.data import DataLoader,Dataset,TensorDataset
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
import numpy
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
###### 读入数据
iris=load_iris()
x=iris.data
y=iris.target
Y=y # 在画图中备用
###### 对输入进行归一化,因为autoencoder只用到了input
MMScaler=MinMaxScaler()
x=MMScaler.fit_transform(x)
iforestX=x
###### 输入数据转换成神经网络接受的dataset类型,batch设定为10
tensor_x=torch.from_numpy(x.astype(numpy.float32))
tensor_y=torch.from_numpy(y.astype(numpy.float32))
my_dataset=TensorDataset(tensor_x,tensor_y)
my_dataset_loader=DataLoader(my_dataset,batch_size=10,shuffle=False)
#print(isinstance(my_dataset,Dataset))
###### 定义一个autoencoder模型
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder,self).__init__()
self.encoder=nn.Sequential(
nn.Linear(4, 3),
nn.Tanh(),
nn.Linear(3, 2),
)
self.decoder=nn.Sequential(
nn.Linear(2, 3),
nn.Tanh(),
nn.Linear(3, 4),
nn.Sigmoid()
)
def forward(self, x):
encoder=self.encoder(x)
decoder=self.decoder(encoder)
return encoder,decoder
model=autoencoder()
####### 定义损失函数
criterion=nn.MSELoss()
####### 定义优化函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 如果采用SGD的话,收敛不下降
####### epoch 设定为300
for epoch in range(300):
total_loss = 0
for i ,(x,y) in enumerate(my_dataset_loader):
_,pred=model(V(x))
loss=criterion(pred,x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss+=loss
if epoch % 100==0:
print(total_loss.data.numpy())
###### 基于训练好的model做降维并可视化
x_=[]
y_=[]
for i, (x, y) in enumerate(my_dataset):
_, pred = model(V(x))
#loss = criterion(pred, x)
dimension=_.data.numpy()
x_.append(dimension[0])
y_.append(dimension[1])
plt.scatter(numpy.array(x_),numpy.array(y_),c=Y)
for i in range(len(numpy.array(x_))):
plt.annotate(i,(x_[i],y_[i]))
plt.show()