机器学习数据不平衡不均衡处理之SMOTE算法实现
20201125
当多数类和少数类数量相差太大的时候,少数类不一定要补充到和多数类数量一致
最好的办法就是全部过采样到最大记录数的类别
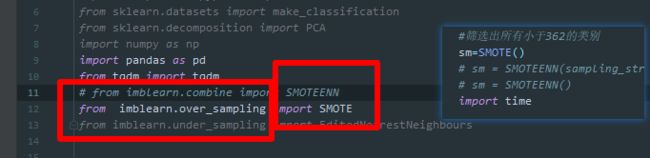
调参
SMOTE:只是过采样
SMOTEENN:过采样的同时欠采样
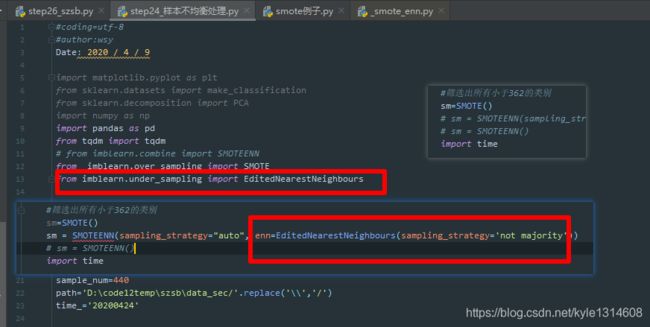
要调ENN的参数,先在前面import
https://blog.csdn.net/Li_yi_chao/article/details/94630920
Borderline-SMOTE 过程
https://blog.csdn.net/weixin_37801695/article/details/86243998
https://www.cnblogs.com/massquantity/p/9382710.html
https://www.cnblogs.com/Determined22/p/5772538.html
SMOTE的详细过程
重点
https://www.cnblogs.com/massquantity/p/9382710.html
https://blog.csdn.net/weixin_37801695/article/details/86243998
- Border-line SMOTE
这个算法会先将所有的少数类样本分成三类,如下图所示:
“noise” : 所有的k近邻个样本都属于多数类
“danger” : 超过一半的k近邻样本属于多数类
“safe”: 超过一半的k近邻样本属于少数类
其k近邻是和所有的样本数据计算吗?
https://blog.csdn.net/a358463121/article/details/52304670
重点
https://juejin.im/post/5e181578f265da3e1e0567c6#heading-27
重点 源码
https://juejin.im/post/5e181578f265da3e1e0567c6
https://www.cnblogs.com/massquantity/p/9382710.html
https://www.cnblogs.com/43726581Gavin/archive/2018/05/16/9043993.html
https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.combine.SMOTEENN.html
API 地址
sampling_type:
The type of sampling. Can be either 'over-sampling',
'under-sampling', or 'clean-sampling'.
sampling_strategy
imblearn.over_sampling.SMOTE(
sampling_strategy = ‘auto’,
random_state = None, ## 随机器设定
k_neighbors = 5, ## 用相近的 5 个样本(中的一个)生成正样本
m_neighbors = 10, ## 当使用 kind={‘borderline1’, ‘borderline2’, ‘svm’}
out_step = ‘0.5’, ## 当使用kind = ‘svm’
kind = ‘regular’, ## 随机选取少数类的样本
– borderline1: 最近邻中的随机样本b与该少数类样本a来自于不同的类
– borderline2: 随机样本b可以是属于任何一个类的样本;
– svm:使用支持向量机分类器产生支持向量然后再生成新的少数类样本
svm_estimator = SVC(), ## svm 分类器的选取
n_jobs = 1, ## 使用的例程数,为-1时使用全部CPU
ratio=None
)
https://blog.csdn.net/yeziyezi1986/article/details/103202012
https://zhuanlan.zhihu.com/p/81857985
网上关于数据不平衡处理的讨论有很多,大致来说,数据不平衡的处理方法有三种:一是欠采样,二是过采样,三是调整权重。
今天要说的是过采样中的一个算法SMOTE。在网上找到一个Python库imbalance-learn package 。它是专门用来处理数据不平衡的,网址在这:https://pypi.python.org/pypi/imbalanced-learn#id27
安装说明安装之后就可以使用了,下面是一个简单的例子:
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
from imblearn.combine import SMOTEENN
print(__doc__)
# Generate the dataset
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=100, random_state=10)
print(y)
print(y.shape)
sm = SMOTEENN()
X_resampled, y_resampled = sm.fit_sample(X, y)
print(y_resampled)
print(y_resampled.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
输出为:
[1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1]
(100,)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
(177,)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可见,该算法将标签为0的样本扩展多了77个。
