Python————Pandas统计分析基础
Pandas简介
pandas:强大的数据分析和处理工具
快速、灵活、富有表现力的数据结构:DataFrame数据框和Series系列
Pandas读取文本数据
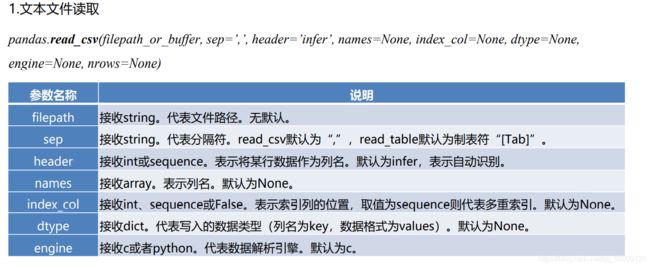
#读写不同数据源的数据
import pandas as pd
data_txt = pd.read_csv('meal_order_info.txt',sep=' ') #指定一行中数据间的分隔符为空格
data_csv = pd.read_csv('meal_order_info.csv',encoding='GBK') #设置解码方式为GBK
data_txt

data_csv

储存数据框
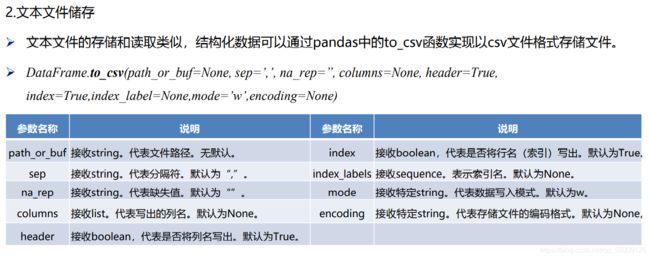
#将数据框储存为文本文件数据
data_csv.to_csv('tmp/data_csv.csv',index=None,encoding ='gbk') #index为行索引 ,header为列索引 None为取消
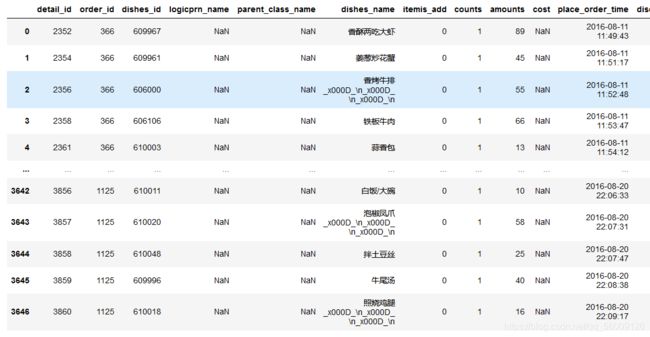
Pandas读取excel文件

#Pandas读取excel文件
data_excel =pd.read_excel('meal_order_detail.xlsx',sheet_name='meal_order_detail2')
data_excel
将数据框储存为excel文件
#将数据框储存为excel文件
data_excel.to_excel('tmp/data_excel.xlsx',index=None,sheet_name='test1')
构建数据框

#series 系列
import pandas as pd
ser1 = pd.Series([1,2,'a'],index=['a','b','c'])
print(ser1)
ser2 = pd.Series({'a':[1,2,3],'b':['1','2','3']})
print(ser2)

d=[[1.3,2.0,3,4],[2,4,1,4],[2,5,1.9,7],[3,1,0,11]]
print(d)
df = pd.DataFrame(d,index=['a','b','c','d'],columns=['A','B','C','D']) #index 设置行名称 columns 设置列名称
print(df)


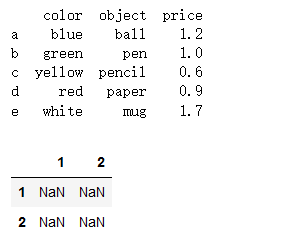
d={'color':['blue','green','yellow','red','white'],
'object':['ball','pen','pencil','paper','mug'],
'price':[1.2,1.0,0.6,0.9,1.7]}
frame = pd.DataFrame(d,index=['a','b','c','d','e'])
print(frame)
pd.DataFrame(index=[1,2],columns=[1,2]) #生成全部都是缺失值的数据框
pd.DataFrame(1,index=[1,2],columns=[1,2]) #生成全部都是1的数据框

查看数据框的常用属性

#数据框的常用属性
d=[[1.3,2.0,3,4],[2,4,1,4],[2,5,1.9,7],[3,1,0,11]]
df = pd.DataFrame(d,index=['a','b','c','d'],columns=['A','B','C','D'])
print(df)
print(df.values)
print(df.index)
print(df.shape)
print(df.dtypes) #查看数据框内每一列数据的类型

按行列顺序访问数据框中的元素
d=[[1.3,2.0,3,4],[2,4,1,4],[2,5,1.9,7],[3,1,0,11]]
df = pd.DataFrame(d,index=['a','b','c','d'],columns=['A','B','C','D'])
print(df)
print(df['A']) #单列数据访问
print(df[['A','C']]) #多列数据的访问
print(df.head(3)) #查看数据的前3行
print(df.tail(3)) #查看数据的后3行
print(df.iloc[0,0]) #查看数据的第0行,第0列
print(df.iloc[0:3,0])
print(df.iloc[:,0])
print(df.iloc[0,:])

按行列名称访问数据框中的元素
print(df.loc['a','A'])
print(df.loc['a':'c','A']) #按名称访问 'a':'c' 是闭区间
print(df.loc[:,'A'])
print(df.loc['a':'c',:])
print(df.loc[['a','c'],['A','C']])

修改数据框中的数据

d=[[1.3,2.0,3,4],[2,4,1,4],[2,5,1.9,7],[3,1,0,11]]
df = pd.DataFrame(d,index=['a','b','c','d'],columns=['A','B','C','D'])
print(df)
df.loc['a','A'] = 101 #修改数据框中的数据
df.loc[:,'B'] = 0.25
df.loc[:,'C']=[1,2,3,4]
print(df)


d=[[1.3,2.0,3,4],[2,4,1,4],[2,5,1.9,7],[3,1,0,11]]
df = pd.DataFrame(d,index=['a','b','c','d'],columns=['A','B','C','D'])
print(df)
df['E']=5 #添加额外的列
df['F']=[1,2,3,4]
print(df)

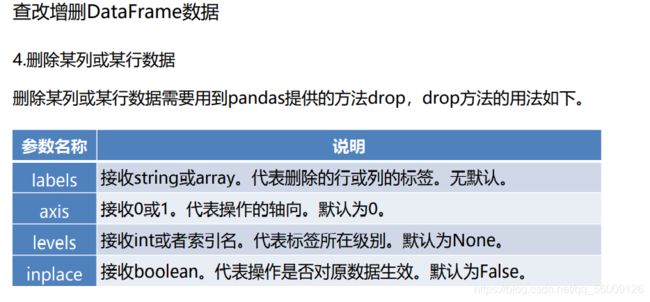
删除数据框中的元素
d=[[1.3,2.0,3,4],[2,4,1,4],[2,5,1.9,7],[3,1,0,11]]
df = pd.DataFrame(d,index=['a','b','c','d'],columns=['A','B','C','D'])
print(df)
print(df.drop('D',axis=1,inplace=False)) #删除单列数据 inplace不添加时默认为False
#当inplace=False时,不对源数据进行修改,而是返回一个副本文件
#当inplace=True时,直接对源数据进行修改
print(df.drop(['a','c'],axis=0))

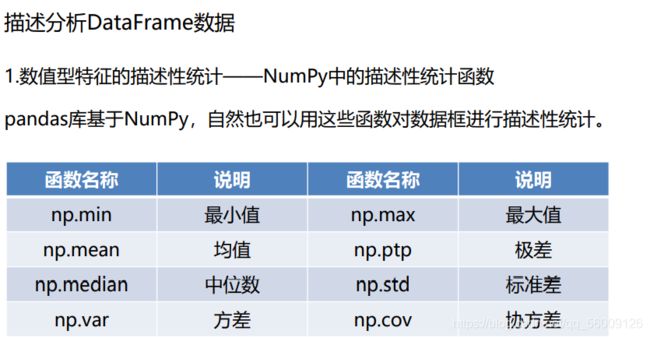
描述分析数据框中的元素


import numpy as np
d=[[1.3,2.0,3,4],[2,4,1,4],[2,5,1.9,7],[3,1,0,11]]
df = pd.DataFrame(d,index=['a','b','c','d'],columns=['A','B','C','D'])
print(df)
print(np.mean(df,axis=1) ) #求均值 axis=1 按行 axis=0 按列 默认按列
df.std()
df.describe()
df['A'].value_counts() 统计出A列元素的出现次数

转换成时间类型数据

import pandas as pd
order = pd.read_csv('tmp/meal_order_info.csv',encoding='gbk')
#print(order)
print(order['lock_time'].dtype)
order['lock_time'] = pd.to_datetime(order['lock_time']) #将lock_time这一列的数据类型转为时间类型
print(order['lock_time'].dtype)

order['lock_time']

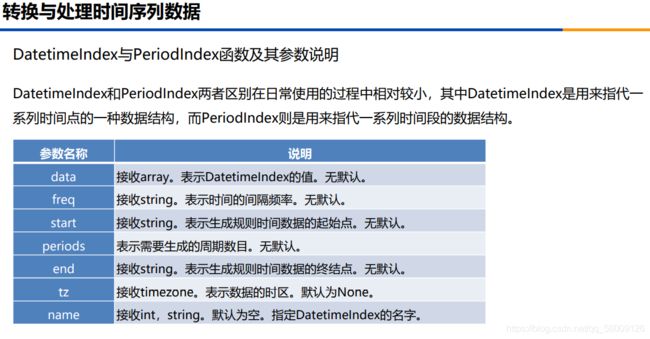
print(pd.DatetimeIndex(order['lock_time']))
print(pd.PeriodIndex(order['lock_time'],freq='H'))

时间类型数据的常用操作
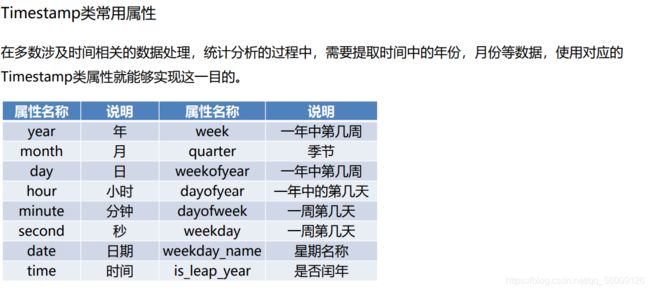


print(order['lock_time'])
print(order['lock_time'][0].year) #查看第0个元素的年份
print(order['lock_time'].dt.year) #查看所有元素的年份
print(order['lock_time'].dt.month) #查看所有元素的月份
print(order['lock_time'].dt.week) #查看所有元素是每年第几个星期
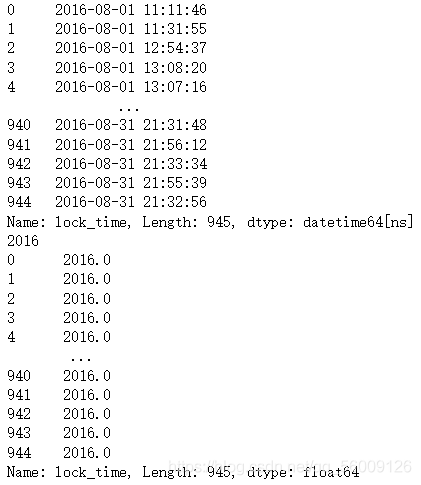
print(order['lock_time']+pd.Timedelta(days=1) ) #将日期全部增加一天
print(order['lock_time'][1]-order['lock_time'][0] ) #将第1个元素和第0个元素相减 求时间差
分组聚合操作

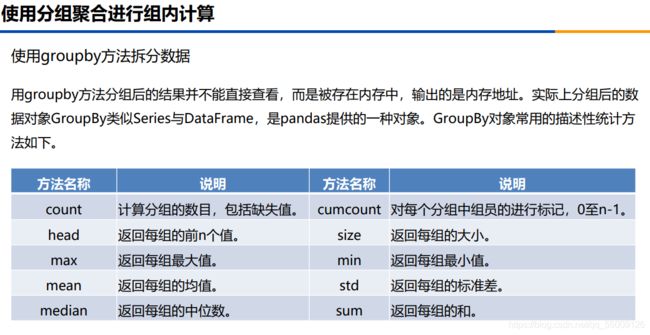
import pandas as pd
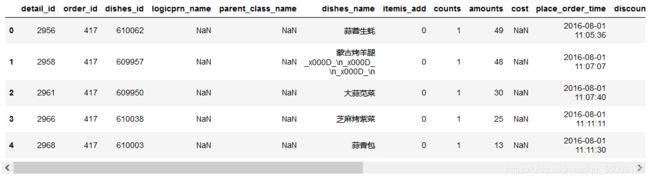
detail = pd.read_excel('tmp/meal_order_detail.xlsx')
detail.head()
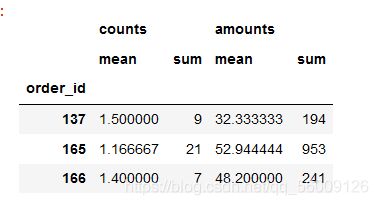
detail_group = detail[['order_id','counts','amounts']].groupby(by='order_id') #以order_id为分组依据
detail_group.agg('mean').head(3)

detail_group.agg(['mean','sum']).head(3)
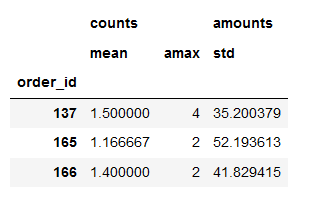
import numpy as np
detail_group.agg({'counts':['mean',np.max],'amounts':'std'}).head(3)
创建透视表与交叉表

import pandas as pd
detail = pd.read_excel('tmp/meal_order_detail.xlsx')
detail.head()

pd.pivot_table(detail[['order_id','counts','amounts']],index='order_id',aggfunc='sum').head(3)

pd.pivot_table(detail[['order_id','dishes_name','counts']],index='order_id',columns='dishes_name',aggfunc='sum')
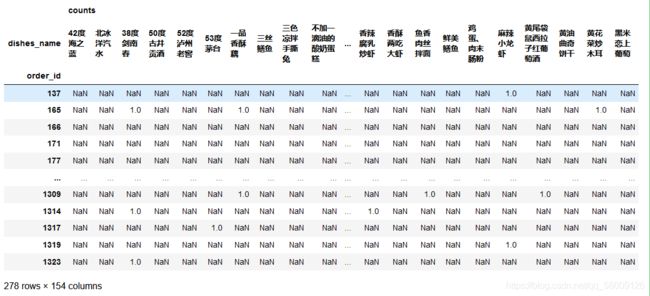
pd.pivot_table(detail[['order_id','dishes_name','counts']],index='order_id',columns='dishes_name',values='counts',fill_value=0).head()
pd.crosstab(index=detail['order_id'],columns=detail['dishes_name']).head()

pd.crosstab(index=detail['order_id'],columns=detail['dishes_name'],values=detail['counts'],aggfunc='sum').fillna(0).head()
