概述
物化视图和视图类似,反映的是某个查询的结果,但是和视图仅保存SQL定义不同,物化视图本身会存储数据,因此是物化了的视图。
当用户查询的时候,原先创建的物化视图会注册到优化器中,用户的查询命中物化视图后,会直接去物化视图拿数据(缓存),提高运行速度,是典型的空间换时间。
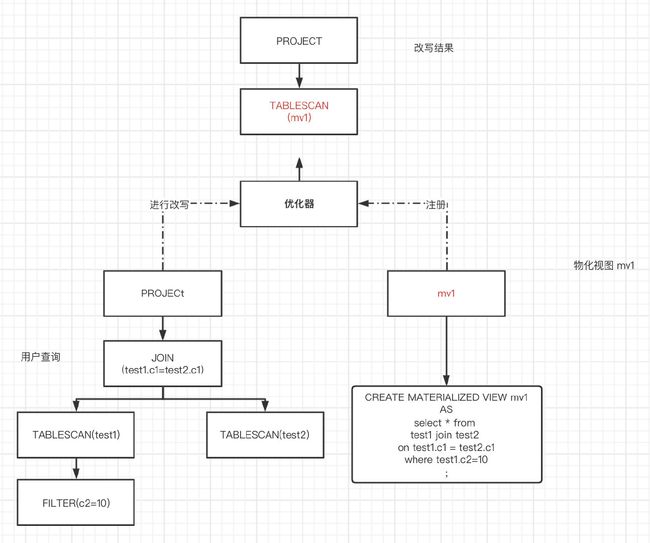
本篇文章会先介绍《Optimizing Queries Using Materialized Views: A Practical, Scalable Solution》如果改写物化视图,接下来会说明 calcite 的物化视图改写逻辑。
物化视图有三个需要解决的问题:
- View design: determining what views to materialize, including how to store and index them.
第一个问题,是要选择哪些数据需要进行物化,这个通常是由用户自己决定的,我们能做的就是收集用户的统计信息,展示高频的表信息,查询谓词或者子查询,辅助用户判断哪些数据需要物化。
另外 calcite 也有一个 Lattices 的功能,可以自动收集统计星型模型和雪花模型的表,自动构建部分 cube 的物化视图。
- View maintenance: efficiently updating materialized views when base tables are updated.
第二个问题,当原始表更新后,如果更新物化视图表。
当原始表增加数据或更新数据后,是直接增量更新到物化视图,还是全量更新到物化视图,实时触发还是延迟触发抑或是定时触发,这些都是需要考虑的点。
- View exploitation: making efficient use of materialized views to speed up query processing.
如果利用物化视图进行加速,主要是对用户查询进行改写,使查询命中物化视图然后进行改写。
主要有三种改写方法,基于语法的改写,基于规则的改写 ,基于结构的改写。
这里只介绍论文中的基于结构的改写算法,对其他几种有兴趣的同学可以看看阿里的这篇:一文详解物化视图改写 。
物化视图重写算法
《Optimizing Queries Using Materialized Views: A Practical, Scalable Solution》 一文介绍了一种物化视图重写算法,Calcite 有一种 SPJG 重写算法,正式基于这篇 paper 实现的。
这篇论文,主要介绍了一种 SPJG视图(即 Join-Select-Project-GroupBy 视图) rewrite 的方法,即前面提到的基于结构的改写算法。
基于结构的改写算法,会提取查询和物化视图的各项结构信息,包括,表,列信息,谓词信息,表达式等等,然后用一个算法这些结构信息进行验证,物化视图补偿等等操作,最终完成改写。
join-select-project (SPJ) views and queries 改写
物化视图能够被用户查询改写的先决条件:
- equivalence classes (等价类,即 SQL 相等的列,是后续做进一步判断的基础)
- The view contains all rows needed by the query expression.( 物化视图 view 包含的行,需要覆盖用户 query 查询所需要的行。)
- All required rows can be selected from the view.( 用户 query 需要的数据,都能够在 view 中查询得到。)
- Can output expressions be computed (query sql 中的表达式都能过被 view 计算出来)
- Do rows occur with correct duplication factor(有相同的重复语义,比如 distinct)
接下来,将说明前面的几种先决条件判断方法。
等价类(equivalence classes)
等价类(equivalence classes),即一组等价的列的集合 ,是基于等价谓词求出来的。如果在一条 SQL 中,两个列包含在一个等价类中,那么就说明这两个列在这一条 SQL 中是完全等价的。
另外等价类可以基于传递性,判断两个列等价,例如 A=date_format(now(), '%Y%m%D') 和 B=date_format(now(), '%Y%m%D'),因为函数是确定性的,可以得到 A=B,如果我们还有 inner join 的条件 B=C,可以进一步得到 A=B=C。
根据 calcite 的代码,equivalence classes 的计算方式,是通过计算所有的等价谓词信息 ,将所有相等的 columns 按照 HashMap
根据等价类的特性,物化视图 view 中一些缺失的列可以通过等价类获得等价的列作为替代。
条件1 : The view contains all rows needed by the query expression
为什么
为什么需要判断物化视图 view 包含的行,覆盖用户 query 查询所需要的行,这里举个简单的例子:
//物化视图
CREATE MATERIALIZED VIEW mv1 AS
SELECT column1,column2,column3,column4
FROM test1
WHERE column1=column2
AND column3=column4;
//用户查询
SELECT column1,column2,column3,column4
FROM test1
WHERE column1=column2;
这里物化视图的条件为 column1=column2 & column3=column4,而用户 query 的条件为 column1=column2。物化视图多了一个谓词条件column3=column4,那么物化视图的 SQL 查询结果数据大概率是比用户 query 的数据少的,所以用户查询无法将自身改写成这个物化视图。
如果验证条件
令Wq表示查询表达式的谓词,而Wv表示视图表达式的谓词。我们只要确定, (select * from T1,T2,…,Tm where Wq) 和(select * from T1,T2, …,Tm where Wv) 的情况下,Wq是 Wv的子集。即我们需要确定Wq⇒Wv是否成立。
然后我们对 Wq 和 Wv 进行拆解,将谓词重写为Wq = Pq1 ∧ Pq2 ∧...∧Pqm ,和Wv = Pv1∧Pv2 ∧...∧ Pvn。
paper 设计一种算法来对 sql 进行匹配,将所有的谓词分为三种,等价谓词 PE,范围谓词 PN,剩余谓词PU。

公式 (A⇒C) ⇒ (AB⇒C) 对任意谓词 A、B、C 成立。换句话说,如果我们能推导出 A 本身包含 C 那么肯定 A 和 B 一起就包含 C 。为了确定查询所需的所有行是否存在于视图中,我们可以应用以下三个测试:
(PEq ⇒ PEv ) (Equijoin subsumption test)
(PEq∧ PRq ⇒ PRv) (Range subsumption test)
(PEq ∧PUq ⇒ PUv ) (Residual subsumption test)
Equijoin subsumption test(等价包含测试)
Equijoin subsumption test 要求视图中所有相等的列在查询中也必须相等(反之则不然,因为用户 query 可以补偿到物化视图中)。通过为用户查询 query 和物化视图计算列等价类来实现此测试,假设视图包含(A=B 和 B=C),查询包含(A=C 和 C=B)。
即使实际的谓词不匹配,它们在逻辑上也是等价的,因为它们都暗示 A=B=C。这一点将等价类摘出来就可以很清楚得观测到。 即通过使用等价类可以正确捕获传递性的影响。
另外如果用户 query 包含更多的条件,比如多一个 C=D ,这个条件在最后的改写过程中,也可以加到物化视图中,这个谓词就称为补偿谓词(即物化视图没有,补偿给物化视图)。
Range subsumption test(范围谓词包含测试)
范围包含测试有一个简单的算法。 将查询中的每个等价类与一个范围相关联,该范围指定了等价类中列的下限和上限, 两个边界最初都未初始化。
然后我们一一考虑范围谓词,找到包含引用列的等价类,并根据需要设置或调整其范围。 如果谓词是 (Ti.Cp <= c) 类型,我们将上限设置为其当前值和 c 的最小值。 如果是 (Ti.Cp >= c) 类型,我们将上限设置为其当前值和 c 的最大值。 (Ti.Cp < c) 形式的谓词被视为 (Ti.Cp <= c-Δ),其中 c-Δ 表示列 Ti.Cp 的域中 c 之前的最小值。 (Ti.Cp > c) 形式的谓词被视为 (Ti.Cp <= c+Δ)。 最后,形如 (Ti.Cp = c) 的谓词被视为 (Ti.Cp >= c)∧ (Ti.Cp <= c)。 对视图重复相同的过程。
举个简单的例子:
//物化视图
CREATE MATERIALIZED VIEW mv1 AS
SELECT column1,column2,column3,column4,column5
FROM test1
WHERE column3 > 10;
//查询
SELECT column1,column2,column3,column4,column5
FROM test1
WHERE column3 > 50;
- 物化视图范围谓词:{column3 } ∈ (10, +∞)
- 用户查询谓词:{column3 } ∈ (50, +∞)
query 中的范围谓词在物化视图的范围之内,在最终改写中,需要将 column3 > 50 这个条件作为补偿谓词加到物化视图中。
Residual subsumption test(剩余谓词包含测试)
剩余谓词就是出去上面两种谓词后,剩下的谓词(比如 a like "str"),只能通过精确匹配,判断用户 query 和物化视图是否属于同一种类型的谓词 & 有相同的值,确定它们是否包含。
条件2 : All required rows can be selected from the view
经过调解1 的验证,就可以确定用户查询的谓词,包含物化视图的谓词,接下来要确保补偿谓词能够在物化视图执行。
三种补偿谓词为:
- 比较物化视图和用户 query 等价类时获得的列等价谓词。 比如谓词:(o_orderdate = l_shipdate)。
- 根据物化视图范围谓词,检查用户 query 范围谓词时获得的范围谓词。 比如谓词: ({p_partkey, l_partkey} <= 160) 。
- 查询中不匹配的剩余谓词。 比如谓词:(l_quantity*l_extendedprice > 100)。
要使条件2 验证通过:
- 将视图等价类与查询等价类进行比较时构造补偿列等价谓词。 尝试将每个列引用映射到物化视图输出列(通过视图等价类),若映射失败,则改写失败。
- 通过比较列范围来构造补偿范围谓词。 尝试将每个列引用映射到物化视图的输出列(使用查询等价类)。 若映射失败,则改写失败。
- 查找物化视图中缺少的 query 的剩余谓词。 尝试将每个列引用映射到物化视图输出列(使用查询等价类)。 若映射失败,则改写失败。
条件3 : Can output expressions be computed
检查是否可以从视图中计算查询的所有输出表达式,即检查附加谓词是否可以正确计算。
如果输出表达式是常量,则只需将常量复制到输出中即可。 如果输出表达式是简单的列引用,需要检查是否可以将其映射(使用查询等效类)到视图的输出列。
对于其他表达式,我们首先检查视图输出是否包含完全相同的表达式(考虑到列的等效性)。如果是这样,则仅将输出表达式替换为对匹配视图输出列的引用。 如果不是,我们将检查表达式的源列是否可以全部映射到视图输出列,即是否可以从(简单)输出列中计算出完整的表达式。
条件 4 :Do rows occur with correct duplication factor?
这个点比较直观,不细说。
rewrite
如果完成了前面提到的物化视图 rewrite 判断,以及谓词补偿,那进行重写其实就比较简单了,直接生成新的 logical plan 节点然后替换就可以了。
这部分通常是做到 CBO 优化器中,一条 sql 可以被多个物化视图改写,甚至可以被一个物化视图改写多次,在 CBO 优化器中可以利用其特性,根据 COST 模型找出最佳 plan。
故重点是如果判断物化视图 view 的逻辑计划能否进行 rewrite ,是否进行补偿。
举例
例1
创建视图:
Create view V2 with schemabinding as
Select l_orderkey, o_custkey, l_partkey,
l_shipdate, o_orderdate,
l_quantity*l_extendedprice as gross_revenue
From dbo.lineitem, dbo.orders, dbo.part
Where l_orderkey = o_orderkey
And l_partkey = p_partkey
And p_partkey >= 150
And o_custkey >= 50 and o_custkey <= 500
And p_name like ‘%abc%’
用户 Query:
Select l_orderkey, o_custkey, l_partkey,
l_quantity*l_extendedprice
From lineitem, orders, part
Where l_orderkey = o_orderkey
And l_partkey = p_partkey
And l_partkey >= 150 and l_partkey <= 160
And o_custkey = 123
And o_orderdate = l_shipdate
And p_name like ‘%abc%’
And l_quantity*l_extendedprice > 100
Step 1: 计算等价类
- View equivalence classes: {l_orderkey, o_orderkey}, {l_partkey, p_partkey}, {o_orderdate}, {l_shipdate}
- Query equivalence classes: {l_orderkey, o_orderkey}, {l_partkey, p_partkey}, {o_orderdate, l_shipdate}
Step 2: 检查 View 等价类
这里 view 相比 query ,少了 {o_orderdate, l_shipdate},所以后续需要加上这个等价谓词。
Step 3 : 计算范围谓词
- View ranges: {l_partkey, p_partkey} ∈ (150, +∞), {o_custkey} ∈ (50, 500)
- Query ranges: {l_partkey, p_partkey} ∈ (150, 160), {o_custkey} ∈ (123, 123)
Step 4 : 计算 Query 范围谓词
Query 中 {l_partkey, p_partkey} 的范围 (150, 160) 在相应的 View 相关谓词的范围内,但上限不匹配,因此我们必须在 View 中添加补偿谓词 ({l_partkey, p_partkey} <= 160)。 {o_custkey} 上的范围 (123, 123) 在 View 也在相应的视图谓词的范围内,但边界不匹配,因此我们必须添加补偿谓词 (o_custkey >= 123) 和 (o_custkey <= 123),可以简化为 (o_custkey = 123)。
Step 5 : 计算 View 剩余谓词
- View residual predicate: p_name like ‘%abc%’
- Query residual predicate: p_name like ‘%abc%’, l_quantity*l_extendedprice > 100
该 View只有一个剩余谓词 p_name like ‘%abc%’,它也存在于 Query 中。 必须添加补偿额外的剩余谓词 l_quantity*l_extendedprice > 100。
该视图通过了所有测试,因此我们得出结论,它包含所有必需的行。 必须添加的补偿谓词是 (o_orderdate = l_shipdate)、({p_partkey, l_partkey} <= 160)、(o_custkey = 123) 和 (l_quantity*l_extendedprice > 100.00)。
Calcite 物化视图实现
前面提到物化视图的三个问题:
- 哪些数据需要被物化
- 如何保持原始表与物化表的同步关系
- 如何进行改写
这里主要是看 calcite 如果进行改写。那么衍生出两个问题:
- 物化视图如何被定义 & 注册
- 物化视图改写流程
两种改写算法
Calcite 有两种物化视图 rewrite 的实现,一种是 SubstitutionVisitor 及其扩展 MaterializedViewSubstitutionVisitor(使用的 rule 是 unifyrule系列规则),另一种则是MaterializedViewRule。
- SubstitutionVisitor: based on pattern, and bottom-up visit.
- MaterializedViewRule: analyze semantics with relnode, such as SPJA
SubstitutionVisitor 的优势和缺陷:
- 轻松扩展:可以方便新建一个自定义模式来匹配并使用 mv 重写查询的计划。
- 支持out join
- 不止 'SPJA' :SubstitutionVisitor支持更多模式,如:Sort。
缺陷:
- 不支持 JOIN 补偿,这在
MaterializedViewRule中实现 - 受join顺序影响,eg:query(a join b), mv(b join a)
第二种MaterializedViewRule,实现并拓展自 [GL01] 所述算法,其实现方式提取 query 的relnode结构(谓词信息,列信息等),然后进行验证,构建补偿谓词并完成重写,这是一种更加先进的方式,但目前其适用范围比 SubstitutionVisitor更窄,比如join 类型必须为 inner-join。
第一种SubstitutionVisitor 重写,在 calcite 基本快要被废弃了,这里主要介绍 MaterializedViewRule的主要实现方式,即前面介绍的算法。
calcite 物化视图原理
MV 是怎么注册的
在 model json 文件中,可以配置 Materize View SQL,然后 Calcite 会将 MV 的 SQL 解析成 RelNode 而后存储到 VolcanoPlanner#materializations 字段中。

每次执行的时候,并不会直接循环所有缓存中的物化视图,而是会通过VolcanoPlanner#registerMaterializations() 找出被命中的物化视图,然后进一步判断是否该写。
protected void registerMaterializations() {
// Avoid using materializations while populating materializations!
final CalciteConnectionConfig config =
context.unwrap(CalciteConnectionConfig.class);
if (config == null || !config.materializationsEnabled()) {
return;
}
// Register rels using materialized views.
//通过 `SubstitutionVisitor` ,获取可能进行重写的物化视图
final List>> materializationUses =
RelOptMaterializations.useMaterializedViews(originalRoot, materializations);
for (Pair> use : materializationUses) {
RelNode rel = use.left;
Hook.SUB.run(rel);
registerImpl(rel, root.set);
}
//通过 table 引用构建的图算法,计算剩余可能被重写的物化视图
// Register table rels of materialized views that cannot find a substitution
// in root rel transformation but can potentially be useful.
final Set applicableMaterializations =
new HashSet<>(
RelOptMaterializations.getApplicableMaterializations(
originalRoot, materializations));
for (Pair> use : materializationUses) {
applicableMaterializations.removeAll(use.right);
}
for (RelOptMaterialization materialization : applicableMaterializations) {
RelSubset subset = registerImpl(materialization.queryRel, null);
RelNode tableRel2 =
RelOptUtil.createCastRel(
materialization.tableRel,
materialization.queryRel.getRowType(),
true);
registerImpl(tableRel2, subset.set);
}
// Register rels using lattices.
//通过 lattices 计算物化视图
final List> latticeUses =
RelOptMaterializations.useLattices(
originalRoot, ImmutableList.copyOf(latticeByName.values()));
if (!latticeUses.isEmpty()) {
RelNode rel = latticeUses.get(0).left;
Hook.SUB.run(rel);
registerImpl(rel, root.set);
}
}
计算物化视图和用户 query 表引用计算
这里的条件基本就一个:物化视图至少包含一个 Query 的表引用。
表引用情况有三种:
- 全匹配
- 物化视图的表引用是用户 query 表引用的子集
- 用户 query 表引用是物化视图的表引用的子集
这三种情况都有可能进行改写,但物化视图至少包含一个用户 query 的表引用。
通过 lattices 注册
第三个是使用 lattices 进行注册,lattices 是 Calcite 针对星型模型和雪花模型推出的一种物化视图框架,主要可以物化星型模型中部分 cube ,能够智能收集信息并智能决定物化哪些维度等。有点类似 kylin 的思路。
CBO 注册逻辑(registerImpl)
上面注册逻辑中可以看到,计算出 ListregisterImpl注册。这里涉及到 calcite 中 rule 注册的逻辑,Calcite 用 VolcanoPlanner 模型来进行 CBO 优化,这里不详细说明流程,具体情况可以看这里: Apache Calcite 优化器详解(二)
简单说就是每个新的 Relnode 都会生成一个 Relset 和 RelSubset。每次新建一个 RelSubset ,都会遍历所有可以 match 该 RelSubset 的 Rule(物化视图改写也是一种 rule),创建一个 VolcanoRuleMatch 对象(会记录 RelNode、RelOptRuleOperand 等信息,RelOptRuleOperand 中又会记录 Rule 的信息)。记录 importance 信息并将这个 VolcanoRuleMatch 添加到对应的 RuleQueue 中。
实际进行优化的findBestExp()方法中,主要就是遍历 RuleQueue ,实现 DP 优化算法。
第二个问题,MV 改写是怎样的
VolcanoPlanner CBO 优化的最后一个阶段,就是通过 findBestExp() 方法找到最佳的 plan,这里会先通过 registerMaterializations() 注册 物化视图相关 rule,这也就是上面说到的内容。
而实际注册的 rule ,基本都是 AbstractMaterializedViewRule 的子类 ,这个 Rule 有多个衍生的 rule,MaterializedViewProjectFilterRule,MaterializedViewProjectJoinRule 等适配不同的 query。在上一步中,会寻找 equel 的 relnode 和 match,然后调用这些 rule 迭代 rel 信息,替换 MV 后生成新的 RelNode,完成物化视图的 sql rewrite 过程。
触发入口,是在每个 rule 的 onMatch() 方法中,但实际执行,是在 AbstractMaterializedViewRule#perform() 中。
/**
* Rewriting logic is based on "Optimizing Queries Using Materialized Views:
* A Practical, Scalable Solution" by Goldstein and Larson.
*
* On the query side, rules matches a Project-node chain or node, where node
* is either an Aggregate or a Join. Subplan rooted at the node operator must
* be composed of one or more of the following operators: TableScan, Project,
* Filter, and Join.
*
*
For each join MV, we need to check the following:
*
* - The plan rooted at the Join operator in the view produces all rows
* needed by the plan rooted at the Join operator in the query.
* - All columns required by compensating predicates, i.e., predicates that
* need to be enforced over the view, are available at the view output.
* - All output expressions can be computed from the output of the view.
* - All output rows occur with the correct duplication factor. We might
* rely on existing Unique-Key - Foreign-Key relationships to extract that
* information.
*
*
* In turn, for each aggregate MV, we need to check the following:
*
* - The plan rooted at the Aggregate operator in the view produces all rows
* needed by the plan rooted at the Aggregate operator in the query.
* - All columns required by compensating predicates, i.e., predicates that
* need to be enforced over the view, are available at the view output.
* - The grouping columns in the query are a subset of the grouping columns
* in the view.
* - All columns required to perform further grouping are available in the
* view output.
* - All columns required to compute output expressions are available in the
* view output.
*
*
* The rule contains multiple extensions compared to the original paper. One of
* them is the possibility of creating rewritings using Union operators, e.g., if
* the result of a query is partially contained in the materialized view.
*/
protected void perform(RelOptRuleCall call, Project topProject, RelNode node) {
final RexBuilder rexBuilder = node.getCluster().getRexBuilder();
final RelMetadataQuery mq = call.getMetadataQuery();
final RelOptPlanner planner = call.getPlanner();
final RexExecutor executor =
Util.first(planner.getExecutor(), RexUtil.EXECUTOR);
final RelOptPredicateList predicates = RelOptPredicateList.EMPTY;
final RexSimplify simplify =
new RexSimplify(rexBuilder, predicates, executor);
final List materializations =
planner.getMaterializations();
//调用 `isValidPlan(topProject, node, mq)`,验证 RelNode 是否满足 rewrite 先觉条件,这个每个 rule 都有不同的实现,比如 join 需要通过 `RelMetadataQuery` 获取 RelNode 的 NodeType。
if (!materializations.isEmpty()) {
// 1. Explore query plan to recognize whether preconditions to
// try to generate a rewriting are met
if (!isValidPlan(topProject, node, mq)) {
return;
}
// 2. Initialize all query related auxiliary data structures
// that will be used throughout query rewriting process
// Generate query table references
//获取所有 table 引用,以便后续各种操作,这一步基本都是通过RelMetadataQuery获取各种信息
final Set queryTableRefs = mq.getTableReferences(node);
if (queryTableRefs == null) {
// Bail out
return;
}
// Extract query predicates
//提取 查询的所有谓词,等价谓词和剩余谓词
final RelOptPredicateList queryPredicateList =
mq.getAllPredicates(node);
if (queryPredicateList == null) {
// Bail out
return;
final RexNode pred =
simplify.simplifyUnknownAsFalse(
RexUtil.composeConjunction(rexBuilder,
queryPredicateList.pulledUpPredicates));
//将查询两种谓词包装成 RexNode,等价谓词(左)和剩余谓词(右)
final Pair queryPreds = splitPredicates(rexBuilder, pred);
// Extract query equivalence classes. An equivalence class is a set
// of columns in the query output that are known to be equal.
//提取 query 的等价类(equivalence class),equivalence class 即 query output 中,已知等价的 columns 的集合
final EquivalenceClasses qEC = new EquivalenceClasses();
//遍历等价谓词,并将等价谓词的列都存起来
for (RexNode conj : RelOptUtil.conjunctions(queryPreds.left)) {
assert conj.isA(SqlKind.EQUALS);
RexCall equiCond = (RexCall) conj;
qEC.addEquivalenceClass(
(RexTableInputRef) equiCond.getOperands().get(0),
(RexTableInputRef) equiCond.getOperands().get(1));
}
// 3. We iterate through all applicable materializations trying to
// rewrite the given query
//遍历所有给定物化视图,并尝试重写,一个 relnode 可以对应多个 materialization view
for (RelOptMaterialization materialization : materializations) {
//获取 view 的 RelNode,并提取各种基础信息,比如所有的 RelTableRef
RelNode view = materialization.tableRel;
Project topViewProject;
RelNode viewNode;
//materialization.queryRel 表示注册的 MV sql
//materialization.tableRel 表示注册的 MV 的 table name relnode
//这里找到 topViewProject
if (materialization.queryRel instanceof Project) {
topViewProject = (Project) materialization.queryRel;
viewNode = topViewProject.getInput();
} else {
topViewProject = null;
viewNode = materialization.queryRel;
}
// Extract view table references
final Set viewTableRefs = mq.getTableReferences(viewNode);
if (viewTableRefs == null) {
// Skip it
continue;
}
// Filter relevant materializations. Currently, we only check whether
// the materialization contains any table that is used by the query
//第一个过滤条件,这里只检查 MV 是否包含用户 query 所要的表
// TODO: Filtering of relevant materializations can be improved to be more fine-grained.
boolean applicable = false;
for (RelTableRef tableRef : viewTableRefs) {
if (queryTableRefs.contains(tableRef)) {
applicable = true;
break;
}
}
if (!applicable) {
// Skip it
continue;
}
//跟步骤 1 一样,不过这里对 MV query 进行校验(Valid)
// 3.1. View checks before proceeding
if (!isValidPlan(topViewProject, viewNode, mq)) {
// Skip it
continue;
}
// 3.2. Initialize all query related auxiliary data structures
// that will be used throughout query rewriting process
// Extract view predicates
//跟步骤 2 类似,不过这里获取的是 MV 的各种谓词信息,表达式
final RelOptPredicateList viewPredicateList =
mq.getAllPredicates(viewNode);
if (viewPredicateList == null) {
// Skip it
continue;
}
final RexNode viewPred = simplify.simplifyUnknownAsFalse(
RexUtil.composeConjunction(rexBuilder,
viewPredicateList.pulledUpPredicates));
//获取 MV 的两种谓词,等价谓词(左)和剩余谓词(右)
final Pair viewPreds = splitPredicates(rexBuilder, viewPred);
// Extract view tables
//用 view 和 query 的所有表进行匹配,有三种匹配结果
//MatchModality.COMPLETE:所有 MV view 的 tables 和 query 的 tables 都一致
//MatchModality.QUERY_PARTIAL:用户查询是 MV 视图的子集 的情况,检查 MV 和 query 是否保持相同的基数,主要是获取所有等价谓词,tableref 等信息,然后 compensatePartial 进行判断
//MatchModality.VIEW_PARTIAL:MV 视图是用户 query 的子集,直接调用compensateViewPartial(不同 rule 有不同实现)进行重写添加缺失的 view,重写成功则更新 view 相关信息,后面再对 view 进行补偿
MatchModality matchModality;
Multimap compensationEquiColumns =
ArrayListMultimap.create();
if (!queryTableRefs.equals(viewTableRefs)) {
//进行补偿
// We try to compensate, e.g., for join queries it might be
// possible to join missing tables with view to compute result.
// Two supported cases: query tables are subset of view tables (we need to
// check whether they are cardinality-preserving joins), or view tables are
// subset of query tables (add additional tables through joins if possible)
if (viewTableRefs.containsAll(queryTableRefs)) {
//通过这个来控制补偿机制
matchModality = MatchModality.QUERY_PARTIAL;
//对于用户查询是 MV 视图的子集 的情况,主要是获取所有等价谓词,tableref 等信息,然后 compensatePartial 进行判断
final EquivalenceClasses vEC = new EquivalenceClasses();
for (RexNode conj : RelOptUtil.conjunctions(viewPreds.left)) {
assert conj.isA(SqlKind.EQUALS);
RexCall equiCond = (RexCall) conj;
vEC.addEquivalenceClass(
(RexTableInputRef) equiCond.getOperands().get(0),
(RexTableInputRef) equiCond.getOperands().get(1));
}
//确认 query 是否能够使用 MV view 进行 rewrite
if (!compensatePartial(viewTableRefs, vEC, queryTableRefs,
compensationEquiColumns)) {
// Cannot rewrite, skip it
continue;
}
} else if (queryTableRefs.containsAll(viewTableRefs)) {
//若MV 视图是用户 query 的子集,直接调用compensateViewPartial(不同 rule 有不同实现)进行重写
// 重写目标是将 QUery 有但 view 没有的表添加到 view 中,重写成功则更新 view 相关信息,后续会再使用
matchModality = MatchModality.VIEW_PARTIAL;
ViewPartialRewriting partialRewritingResult = compensateViewPartial(
call.builder(), rexBuilder, mq, view,
topProject, node, queryTableRefs, qEC,
topViewProject, viewNode, viewTableRefs);
if (partialRewritingResult == null) {
// Cannot rewrite, skip it
continue;
}
// Rewrite succeeded
view = partialRewritingResult.newView;
topViewProject = partialRewritingResult.newTopViewProject;
viewNode = partialRewritingResult.newViewNode;
} else {
// Skip it
continue;
}
} else {
matchModality = MatchModality.COMPLETE;
}
// 4. We map every table in the query to a table with the same qualified
// name (all query tables are contained in the view, thus this is equivalent
// to mapping every table in the query to a view table).
//获取 query 中所有具有相等 qualified name 的 RelTableRef,并存储起来
final Multimap multiMapTables = ArrayListMultimap.create();
for (RelTableRef queryTableRef1 : queryTableRefs) {
for (RelTableRef queryTableRef2 : queryTableRefs) {
if (queryTableRef1.getQualifiedName().equals(
queryTableRef2.getQualifiedName())) {
multiMapTables.put(queryTableRef1, queryTableRef2);
}
}
}
// If a table is used multiple times, we will create multiple mappings,
// and we will try to rewrite the query using each of the mappings.
// Then, we will try to map every source table (query) to a target
// table (view), and if we are successful, we will try to create
// compensation predicates to filter the view results further
// (if needed).
//
//如果一张表被使用多次,将对该表创建多重映射,并将重写用户 query 使用这些映射。
//然后尝试将 QUERY 的 table 映射到 MV view 的 table。
//如果可以进行映射,那么下一步将填充剩余谓词
final List> flatListMappings =
generateTableMappings(multiMapTables);
//遍历 query table -> view table 的映射集合
for (BiMap queryToViewTableMapping : flatListMappings) {
// TableMapping : mapping query tables -> view tables
// 4.0. If compensation equivalence classes exist, we need to add
// the mapping to the query mapping
//如果存在compensation equivalence(补偿等价类),我们需要将这些加到 query mapping 中
final EquivalenceClasses currQEC = EquivalenceClasses.copy(qEC);
if (matchModality == MatchModality.QUERY_PARTIAL) {
for (Entry e
: compensationEquiColumns.entries()) {
// Copy origin
RelTableRef queryTableRef = queryToViewTableMapping.inverse().get(
e.getKey().getTableRef());
RexTableInputRef queryColumnRef = RexTableInputRef.of(queryTableRef,
e.getKey().getIndex(), e.getKey().getType());
// Add to query equivalence classes and table mapping
currQEC.addEquivalenceClass(queryColumnRef, e.getValue());
queryToViewTableMapping.put(e.getValue().getTableRef(),
e.getValue().getTableRef()); // identity
}
}
// 4.1. Compute compensation predicates, i.e., predicates that need to be
// enforced over the view to retain query semantics. The resulting predicates
// are expressed using {@link RexTableInputRef} over the query.
// First, to establish relationship, we swap column references of the view
// predicates to point to query tables and compute equivalence classes.
//计算补偿谓词,生成的谓词在查询中使用 {@link RexTableInputRef} 表示。
final RexNode viewColumnsEquiPred = RexUtil.swapTableReferences(
rexBuilder, viewPreds.left, queryToViewTableMapping.inverse());
final EquivalenceClasses queryBasedVEC = new EquivalenceClasses();
for (RexNode conj : RelOptUtil.conjunctions(viewColumnsEquiPred)) {
assert conj.isA(SqlKind.EQUALS);
RexCall equiCond = (RexCall) conj;
queryBasedVEC.addEquivalenceClass(
(RexTableInputRef) equiCond.getOperands().get(0),
(RexTableInputRef) equiCond.getOperands().get(1));
}
//计算得到补偿的等价谓词和剩余谓词
// TODO : computeCompensationPredicates 是如果提取补偿谓词的
Pair compensationPreds =
computeCompensationPredicates(rexBuilder, simplify,
currQEC, queryPreds, queryBasedVEC, viewPreds,
queryToViewTableMapping);
//若补偿谓词为空,并且允许 union rewrite,那么进行 union 的改写
if (compensationPreds == null && generateUnionRewriting) {
// Attempt partial rewriting using union operator. This rewriting
// will read some data from the view and the rest of the data from
// the query computation. The resulting predicates are expressed
// using {@link RexTableInputRef} over the view.
//尝试加上 union operator 进行 sql rewrite
compensationPreds = computeCompensationPredicates(rexBuilder, simplify,
queryBasedVEC, viewPreds, currQEC, queryPreds,
queryToViewTableMapping.inverse());
if (compensationPreds == null) {
// This was our last chance to use the view, skip it
continue;
}
RexNode compensationColumnsEquiPred = compensationPreds.left;
RexNode otherCompensationPred = compensationPreds.right;
assert !compensationColumnsEquiPred.isAlwaysTrue()
|| !otherCompensationPred.isAlwaysTrue();
// b. Generate union branch (query).
//进行改写,生成 union branch
final RelNode unionInputQuery = rewriteQuery(call.builder(), rexBuilder,
simplify, mq, compensationColumnsEquiPred, otherCompensationPred,
topProject, node, queryToViewTableMapping, queryBasedVEC, currQEC);
if (unionInputQuery == null) {
// Skip it
continue;
}
// c. Generate union branch (view).
// We trigger the unifying method. This method will either create a Project
// or an Aggregate operator on top of the view. It will also compute the
// output expressions for the query.
final RelNode unionInputView = rewriteView(call.builder(), rexBuilder, simplify, mq,
matchModality, true, view, topProject, node, topViewProject, viewNode,
queryToViewTableMapping, currQEC);
if (unionInputView == null) {
// Skip it
continue;
}
// d. Generate final rewriting (union).
//分别对 query 和 view 进行 rewrite,最后再处理
final RelNode result = createUnion(call.builder(), rexBuilder,
topProject, unionInputQuery, unionInputView);
if (result == null) {
// Skip it
continue;
}
call.transformTo(result);
} else if (compensationPreds != null) {
RexNode compensationColumnsEquiPred = compensationPreds.left;
RexNode otherCompensationPred = compensationPreds.right;
// a. Compute final compensation predicate.
//判断等价补偿谓词和剩余补偿谓词,是否都返回 true
if (!compensationColumnsEquiPred.isAlwaysTrue()
|| !otherCompensationPred.isAlwaysTrue()) {
// All columns required by compensating predicates must be contained
// in the view output (condition 2).
// 条件 2 判断,补偿谓词所需的列都在 view 中
// 使用映射的方式,将表引用及对应列引用映射到 View 中,若返回 null 则失败,即改写失败
List viewExprs = topViewProject == null
? extractReferences(rexBuilder, view)
: topViewProject.getChildExps();
// For compensationColumnsEquiPred, we use the view equivalence classes,
// since we want to enforce the rest
//如果等价谓词不总为 TRUE,使用视图等价类,因为要强制执行剩余部分
if (!compensationColumnsEquiPred.isAlwaysTrue()) {
//这里 rewrite 的作用,基本上就是把之前 column 的映射再转回来
compensationColumnsEquiPred = rewriteExpression(rexBuilder, mq,
view, viewNode, viewExprs, queryToViewTableMapping.inverse(), queryBasedVEC,
false, compensationColumnsEquiPred);
if (compensationColumnsEquiPred == null) {
// Skip it
continue;
}
}
// For the rest, we use the query equivalence classes
//对于剩余谓词,使用 query 等价类
if (!otherCompensationPred.isAlwaysTrue()) {
otherCompensationPred = rewriteExpression(rexBuilder, mq,
view, viewNode, viewExprs, queryToViewTableMapping.inverse(), currQEC,
true, otherCompensationPred);
if (otherCompensationPred == null) {
// Skip it
continue;
}
}
}
// 合并补偿的等价谓词和剩余谓词,获得最终需要在 view 上面执行的剩余谓词
final RexNode viewCompensationPred =
RexUtil.composeConjunction(rexBuilder,
ImmutableList.of(compensationColumnsEquiPred,
otherCompensationPred));
// b. Generate final rewriting if possible.
// First, we add the compensation predicate (if any) on top of the view.
// Then, we trigger the unifying method. This method will either create a
// Project or an Aggregate operator on top of the view. It will also compute
// the output expressions for the query.
//生成最终重写,
//1. 添加补偿谓词到 view
//2. 调用统一方法,生成一个 project 或一个 Aggregate operator on top of view。
RelBuilder builder = call.builder().transform(c -> c.withPruneInputOfAggregate(false));
RelNode viewWithFilter;
// 如果最终的补偿谓词并非总是 true,生成 viewWithFilter 的时候需要加上 FIlter
if (!viewCompensationPred.isAlwaysTrue()) {
RexNode newPred =
simplify.simplifyUnknownAsFalse(viewCompensationPred);
viewWithFilter = builder.push(view).filter(newPred).build();
// No need to do anything if it's a leaf node.
if (viewWithFilter.getInputs().isEmpty()) {
call.transformTo(viewWithFilter);
return;
}
// We add (and push) the filter to the view plan before triggering the rewriting.
// This is useful in case some of the columns can be folded to same value after
// filter is added.
// 触发重写前,添加 filter 并 PUSH 到 view plan。
Pair pushedNodes =
pushFilterToOriginalViewPlan(builder, topViewProject, viewNode, newPred);
topViewProject = (Project) pushedNodes.left;
viewNode = pushedNodes.right;
} else {
//如果 filter 总是 TRUE ,那么只需要生成 view
viewWithFilter = builder.push(view).build();
}
//进行重写,生成最终的 view
//这里 Agg 和 Join rule 都有自己的实现,主要看 join
final RelNode result = rewriteView(builder, rexBuilder, simplify, mq, matchModality,
false, viewWithFilter, topProject, node, topViewProject, viewNode,
queryToViewTableMapping, currQEC);
if (result == null) {
// Skip it
continue;
}
call.transformTo(result);
} // end else
}
}
}
}
这种方式有以下限制:
- Aggregate 或 Join 类型的 sql ,其子查询节点的 root ,必须为以下几种:TableScan, Project, Filter, and Join,且仅支持 inner join 类型的 sql。
Join 类型进行改写,条件如下:
- MV 的 logical plan 中 join operator ,需包含所有 query 中,join operator 需要的所有数据。
- 拥有补偿谓词所需的列
- 所有的输出表达式都可以从视图的输出中计算出来。
- 所有输出行都以正确的重复因子出现。
而对于 aggregate MV,需要满足以下:
- MV 的 logical plan 中 Aggregate operator ,需包含所有 query Aggregate operator 需要的所有数据。
- 拥有补偿谓词所需的列
- 查询中的分组列是视图中分组列的子集。
- 视图输出中提供了进一步分组所需的所有列。
- 视图输出中提供了计算输出表达式所需的所有列。
基本都是最上面提到的条件。
说明:
等价类:EquivalenceClasses:a set of equivalent columns
具体流程如下:
首先,对用户 query 进行预处理,包括校验,提取信息,构建等价类等。
- 调用
isValidPlan(topProject, node, mq),验证 RelNode 是否满足 rewrite 先决定条件,这个join 和 Aggregate rule 都有不同的实现,比如 join 仅支持 relnode 节点类型:TableScan - Project - Filter - Inner Join。 - 通过 RelMetadataQuery,生成 sql rewrite 过程中,所需要的一些辅助数据(所有 table 表引用等)。提取用户 query 的谓词条件,分为两部分:等价谓词,剩余谓词。表引用,表达式(常量表达式,函数等)等等。
- 构建等价类
EquivalenceClasses,等价类是从等价谓词中提取的 columns 集合
然后,遍历 relnode 的所有物化视图,尝试重写并注册新 relnode。
-
首先,和 query 一样,获取物化视图的基本信息,校验,构建等价类。
-
尝试计算补偿谓词,若不能则跳过视图,根据 query 和 MV 物化视图的 table 表引用数量,分三种情况。
- MatchModality.COMPLETE:所有 MV view 的 tables 和 query 的 tables 都一致,什么都不做。
- MatchModality.QUERY_PARTIAL:用户查询 表引用是 MV 视图的子集 的情况,检查 MV 和 query 是否保持相同的基数(join 的情况),主要是获取所有等价谓词,tableref 等信息,然后 compensatePartial 进行判断是否物化视图能进行 review。即最上面介绍的特殊 case,需要根据唯一健,外健等约束进行判断。
- MatchModality.VIEW_PARTIAL:MV 视图表引用是用户 query 的子集,会调用compensateViewPartial(不同 rule 有不同实现)检测业务 query 能否使用 view 进行重写,可以的话会将 Query 中多出来的表(若存在谓词那便添加这些补偿谓词)添加到 view 中并新生成一个物化视图(初步改写)。
-
经过上述步骤,可以认定 Query 和 View 具有相同的表引用关系(或 view 有多的表引用但不影响)。
-
开始计算补偿谓词,需要在视图 view 上执行补偿谓词以保证 query 语义。
- 创建 query 表引用 -> view 表引用的映射集合
List。 - 物化视图的等价谓词,交换 view column 指向的 TABLE 为 QUERY 的 table ,然后再计算等价类。调用
computeCompensationPredicates计算补偿谓词,包括等价补偿谓词和剩余补偿谓词。交换 view 的表引用,是为了方便判断:视图 view 的查询条件都为 query 条件的子集。如果 view 条件不为 query 的子集,补偿谓词为空。 - 若计算得到的补偿谓词为空并且允许 union 重写,则进行 union 重写(最开始 union 类型是不支持改写的,这里是 calcite 的扩展。这部分先忽略。)
- 先进行优化,如果补偿谓词条件用 AND 相连后,结果总为 true ,类似 where 1=1,那么省略部分操作,生成新的 view。
- 否则进行判断,All columns required by compensating predicates must be contained in the view output(条件二) 。具体做法是将补偿谓词的列进行映射。
- 生成 view ,并将补偿谓词信息加到这个 view 中,调用统一方法,生成一个 project 或一个 Aggregate operator on top of view。最后再调用
rewriteView(不同 join 有不同实现)生成最终重写后的 relnode,再将新的 relnode 注册。等待后续 CBO 进一步优化。
- 创建 query 表引用 -> view 表引用的映射集合
小结
本篇文章主要介绍了物化视图的功能,作用,以及实现过程中需要解决的三个问题。主要介绍物化视图如何进行改写,需要实现哪些条件等等。
然后主要说明 Calcite 如何注册物化视图和实现 SPJG 改写算法。
以上~
Optimizing Queries Using Materialized Views: A Practical, Scalable Solution
一文详解物化视图改写
Materialized Views
Apache Calcite 优化器详解(二)