【第十届“泰迪杯”数据挖掘挑战赛】B题:电力系统负荷预测分析 ARIMA、AutoARIMA、LSTM、Prophet、多元Prophet 实现
目录
- 相关链接
- 完整代码下载链接
- 1 读取数据预处理的文件
- 2 查看时序
- 3 异常值缺失值
-
- 3.1 HeatMap颜色
- 3.2 缺失值处理(多种填充方式)
- 4 数据平滑与采样
- 5 平稳性检验
- 6 数据转换
- 7 特征工程
-
- 7.1 时序提取
- 7.2 编码循环特征
- 7.3 时间序列分解
- 7.4 滞后特征
- 7.6 探索性数据分析
- 7.7 相关性分析
- 7.8 自相关分析
- 8 建模
-
- 8.1 时序中交叉验证
- 8.2 单变量时间序列模型
-
- 8.2.1 ARIMA
- 8.2.2 LSTM
- 8.2.3 AutoARIMA
- 8.3 多元时序预测
-
- 8.3.1 多元Propher
相关链接
(1)【第十届“泰迪杯”数据挖掘挑战赛】B题:电力系统负荷预测分析 问题一Baseline方案
(2)【第十届“泰迪杯”数据挖掘挑战赛】B题:电力系统负荷预测分析 问题一ARIMA、AutoARIMA、LSTM、Prophet 多方案实现
(3)【第十届“泰迪杯”数据挖掘挑战赛】B题:电力系统负荷预测分析 问题二 时间突变分析 Python实现
完整代码下载链接
https://mianbaoduo.com/o/bread/YpiZmp9v
1 读取数据预处理的文件
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from colorama import Fore
from sklearn.metrics import mean_absolute_error, mean_squared_error
import math
import warnings # Supress warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
np.random.seed(7)
df = pd.read_csv(r"./data/泰迪杯数据2.csv")
df.head()

df = df.rename(columns={'日期1':'date'})
df

2 查看时序
from datetime import datetime, date
df['date'] = pd.to_datetime(df['date'])
df.head().style.set_properties(subset=['date'], **{'background-color': 'dodgerblue'})

# To compelte the data, as naive method, we will use ffill
f, ax = plt.subplots(nrows=7, ncols=1, figsize=(15, 25))
for i, column in enumerate(df.drop('date', axis=1).columns):
。。。略
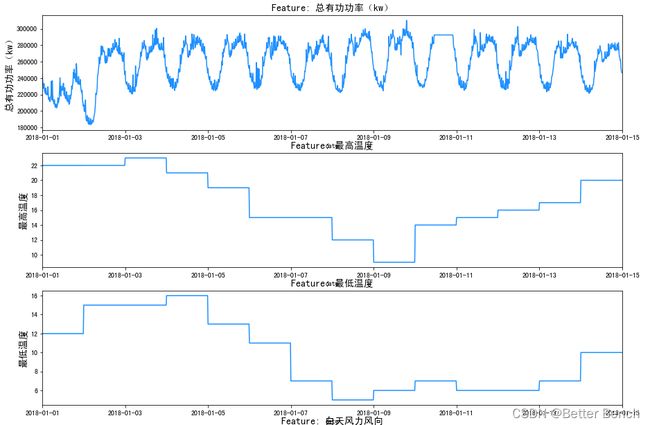

df = df.sort_values(by='date')
# Check time intervals
df['delta'] = df['date'] - df['date'].shift(1)
df[['date', 'delta']].head()

df['delta'].sum(), df['delta'].count()
(Timedelta(‘13 days 23:45:00’), 1439)
df = df.drop('delta', axis=1)
df.isna().sum()
date 0
总有功功率(kw) 51
最高温度 6
最低温度 0
白天风力风向 0
夜晚风力风向 0
天气1 0
天气2 0
dtype: int64
3 异常值缺失值
f, ax = plt.subplots(nrows=2, ncols=1, figsize=(15, 15))
。。。略
ax[1].set_xlim([date(2018, 1, 1), date(2018, 1, 15)])
3.1 HeatMap颜色
Accent, Accent_r, Blues, Blues_r, BrBG, BrBG_r, BuGn, BuGn_r,
BuPu, BuPu_r, CMRmap, CMRmap_r, Dark2, Dark2_r, GnBu, GnBu_r,
Greens, Greens_r, Greys, Greys_r, OrRd, OrRd_r,
Oranges, Oranges_r, PRGn, PRGn_r, Paired, Paired_r, Pastel1, Pastel1_r, Pastel2, Pastel2_r,
PiYG, PiYG_r, PuBu, PuBuGn, PuBuGn_r, PuBu_r, PuOr, PuOr_r, PuRd, PuRd_r, Purples, Purples_r,
RdBu, RdBu_r, RdGy, RdGy_r, RdPu, RdPu_r, RdYlBu, RdYlBu_r, RdYlGn, RdYlGn_r, Reds, Reds_r,
Set1, Set1_r, Set2, Set2_r, Set3, Set3_r, Spectral, Spectral_r, Wistia, Wistia_r, YlGn, YlGnBu,
YlGnBu_r, YlGn_r, YlOrBr, YlOrBr_r, YlOrRd, YlOrRd_r, afmhot, afmhot_r, autumn, autumn_r, binary,
binary_r, bone, bone_r, brg, brg_r, bwr, bwr_r, cividis, cividis_r, cool, cool_r, coolwarm,
coolwarm_r, copper, copper_r, cubehelix, cubehelix_r, flag, flag_r, gist_earth, gist_earth_r,
gist_gray, gist_gray_r, gist_heat, gist_heat_r, gist_ncar, gist_ncar_r, gist_rainbow,
gist_rainbow_r, gist_stern, gist_stern_r, gist_yarg, gist_yarg_r, gnuplot, gnuplot2,
gnuplot2_r, gnuplot_r, gray, gray_r, hot, hot_r, hsv, hsv_r, icefire, icefire_r, inferno,
inferno_r, jet, jet_r, magma, magma_r, mako, mako_r, nipy_spectral, nipy_spectral_r,
ocean, ocean_r, pink, pink_r, plasma, plasma_r, prism, prism_r, rainbow, rainbow_r,
rocket, rocket_r, seismic, seismic_r, spring, spring_r, summer, summer_r, tab10, tab10_r,
tab20, tab20_r, tab20b, tab20b_r, tab20c, tab20c_r, terrain, terrain_r, twilight, twilight_r,
twilight_shifted, twilight_shifted_r, viridis, viridis_r, vlag, vlag_r, winter, winter_r
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(16,5))
sns.heatmap(df.T.isna(), cmap='Reds_r')
ax.set_title('Missing Values', fontsize=16)
for tick in ax.yaxis.get_major_ticks():
tick.label.set_fontsize(14)
plt.show()

3.2 缺失值处理(多种填充方式)
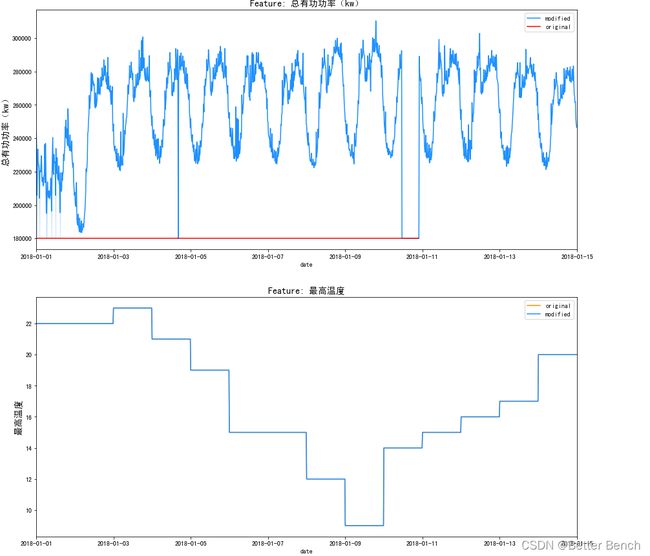
f, ax = plt.subplots(nrows=4, ncols=1, figsize=(15, 12))
sns.lineplot(x=df['date'], y=df['总有功功率(kw)'].fillna(0), ax=ax[0], color='darkorange', label = 'modified')
sns.lineplot(x=df['date'], y=df['总有功功率(kw)'].fillna(np.inf), ax=ax[0], color='dodgerblue', label = 'original')
ax[0].set_title('Fill NaN with 0', fontsize=14)
ax[0].set_ylabel(ylabel='Volume', fontsize=14)
。。。略
for i in range(4):
ax[i].set_xlim([date(2018, 1, 1), date(2018, 1, 15)])
plt.tight_layout()
plt.show()

df['总有功功率(kw)'] = df['总有功功率(kw)'].interpolate()
4 数据平滑与采样
重采样可以提供数据的附加信息。有两种类型的重采样:
上采样是指增加采样频率(例如从几天到几小时)
下采样是指降低采样频率(例如,从几天到几周)
在这个例子中,我们将使用。resample()函数
fig, ax = plt.subplots(ncols=1, nrows=3, sharex=True, figsize=(16,12))
sns.lineplot(df['date'], df['总有功功率(kw)'], color='dodgerblue', ax=ax[0])
ax[0].set_title('总有功功率(kw) Volume', fontsize=14)
。。。略
for i in range(3):
ax[i].set_xlim([date(2018, 1, 1), date(2018, 1, 14)])

# As we can see, downsample to weekly could smooth the data and hgelp with analysis
downsample = df[['date',
'总有功功率(kw)',
]].resample('7D', on='date').mean().reset_index(drop=False)
# df = downsample.copy()
downsample

5 平稳性检验
目测:绘制时间序列并检查趋势或季节性
基本统计:分割时间序列并比较每个分区的平均值和方差
统计检验:增强的迪基富勒检验
# A year has 52 weeks (52 weeks * 7 days per week) aporx.
rolling_window = 52
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(15, 6))
。。。略
plt.show()
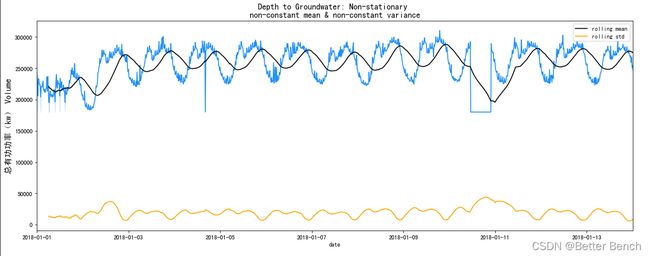
现在,我们将检查每个变量: p值小于0.05 检查ADF统计值与critical_values的比较范围
from statsmodels.tsa.stattools import adfuller
result = adfuller(df['总有功功率(kw)'].values)
result
(-5.279986646245767, 6.0232754503160645e-06, 24, 1415,
{‘1%’: -3.434979825137732, ‘5%’: -2.8635847436211317, ‘10%’: -2.5678586114197954}, 29608.16365155926)
# Thanks to https://www.kaggle.com/iamleonie for this function!
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(12, 6))
def visualize_adfuller_results(series, title, ax):
。。。略
visualize_adfuller_results(df['总有功功率(kw)'].values, '总有功功率(kw)',ax=ax)
# visualize_adfuller_results(df['temperature'].values, 'Temperature', ax[1, 0])
# visualize_adfuller_results(df['river_hydrometry'].values, 'River_Hydrometry', ax[0, 1])
# visualize_adfuller_results(df['drainage_volume'].values, 'Drainage_Volume', ax[1, 1])
# visualize_adfuller_results(df['depth_to_groundwater'].values, 'Depth_to_Groundwater', ax[2, 0])
# f.delaxes(ax[2, 1])
plt.tight_layout()
plt.show()

如果数据不是静态的,但我们想使用一个模型,如ARIMA(需要这个特征),数据必须转换。
将序列转换为平稳序列的两种最常见的方法是:
变换:例如对数或平方根,以稳定非恒定方差
差分:从以前的值中减去当前值
6 数据转换
(1)对数
df['总有功功率(kw)_log'] = np.log(abs(df['总有功功率(kw)']))
。。。略
sns.distplot(df['总有功功率(kw)_log'], ax=ax[1])

(2)一阶差分
# First Order Differencing
ts_diff = np.diff(df['总有功功率(kw)'])
df['总有功功率(kw)_diff_1'] = np.append([0], ts_diff)
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(15, 6))
visualize_adfuller_results(df['总有功功率(kw)_diff_1'], 'Differenced (1. Order) \n Depth to Groundwater', ax)

7 特征工程
7.1 时序提取
df['year'] = pd.DatetimeIndex(df['date']).year
df['month'] = pd.DatetimeIndex(df['date']).month
df['day'] = pd.DatetimeIndex(df['date']).day
。。。略
df[['date', 'year', 'month', 'day', 'day_of_year', 'week_of_year', 'quarter', 'season']].head()

7.2 编码循环特征
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(20, 3))
sns.lineplot(x=df['date'], y=df['month'], color='dodgerblue')
ax.set_xlim([date(2018, 1, 1), date(2018, 1, 14)])
plt.show()

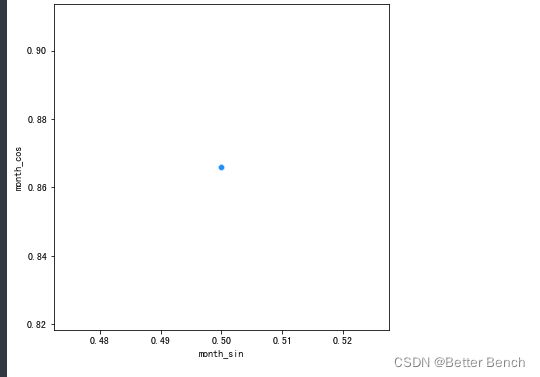
month_in_year = 12
df['month_sin'] = np.sin(2*np.pi*df['month']/month_in_year)
df['month_cos'] = np.cos(2*np.pi*df['month']/month_in_year)
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(6, 6))
sns.scatterplot(x=df.month_sin, y=df.month_cos, color='dodgerblue')
plt.show()
7.3 时间序列分解
from statsmodels.tsa.seasonal import seasonal_decompose
core_columns = [
'总有功功率(kw)']
。。。略
fig, ax = plt.subplots(ncols=2, nrows=4, sharex=True, figsize=(16,8))
for i, column in enumerate(['总有功功率(kw)', '最低温度']):
res = seasonal_decompose(df[column], freq=52, model='additive', extrapolate_trend='freq')
ax[0,i].set_title('Decomposition of {}'.format(column), fontsize=16)
res.observed.plot(ax=ax[0,i], legend=False, color='dodgerblue')
ax[0,i].set_ylabel('Observed', fontsize=14)
。。。略
plt.show()
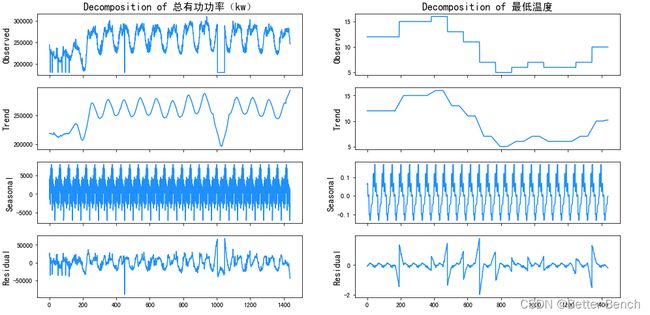
7.4 滞后特征
weeks_in_month = 4
for column in core_columns:
df[f'{column}_seasonal_shift_b_2m'] = df[f'{column}_seasonal'].shift(-2 * weeks_in_month)
df[f'{column}_seasonal_shift_b_1m'] = df[f'{column}_seasonal'].shift(-1 * weeks_in_month)
df[f'{column}_seasonal_shift_1m'] = df[f'{column}_seasonal'].shift(1 * weeks_in_month)
df[f'{column}_seasonal_shift_2m'] = df[f'{column}_seasonal'].shift(2 * weeks_in_month)
df[f'{column}_seasonal_shift_3m'] = df[f'{column}_seasonal'].shift(3 * weeks_in_month)
7.6 探索性数据分析
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(15, 6))
f.suptitle('Seasonal Components of Features', fontsize=16)
for i, column in enumerate(core_columns):
。。。略
plt.tight_layout()
plt.show()
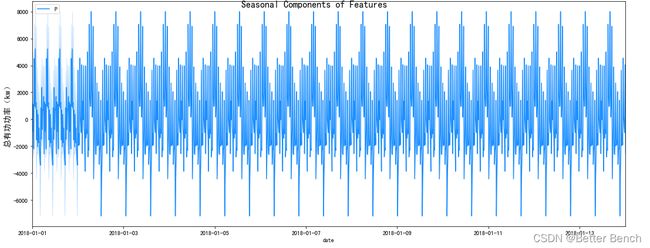
7.7 相关性分析
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(8, 8))
。。。略
plt.tight_layout()
plt.show()

7.8 自相关分析
from pandas.plotting import autocorrelation_plot
autocorrelation_plot(df['总有功功率(kw)_diff_1'])
plt.show()

from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
f, ax = plt.subplots(nrows=2, ncols=1, figsize=(16, 8))
。。。略
plt.show()

8 建模
8.1 时序中交叉验证
from sklearn.model_selection import TimeSeriesSplit
N_SPLITS = 3
X = df['date']
y = df['总有功功率(kw)']
folds = TimeSeriesSplit(n_splits=N_SPLITS)
f, ax = plt.subplots(nrows=N_SPLITS, ncols=2, figsize=(16, 9))
for i, (train_index, valid_index) in enumerate(folds.split(X)):
。。。略
for i in range(N_SPLITS):
ax[i, 0].set_xlim([date(2018, 1, 1), date(2018, 1, 14)])
ax[i, 1].set_xlim([date(2018, 1, 1), date(2018, 6, 30)])
plt.tight_layout()
plt.show()

8.2 单变量时间序列模型
train_size = int(0.85 * len(df))
test_size = len(df) - train_size
df = df.fillna(0)
univariate_df = df[['date', '总有功功率(kw)']].copy()
univariate_df.columns = ['ds', 'y']
train = univariate_df.iloc[:train_size, :]
x_train, y_train = pd.DataFrame(univariate_df.iloc[:train_size, 0]), pd.DataFrame(univariate_df.iloc[:train_size, 1])
x_valid, y_valid = pd.DataFrame(univariate_df.iloc[train_size:, 0]), pd.DataFrame(univariate_df.iloc[train_size:, 1])
print(len(train), len(x_valid))
8.2.1 ARIMA
from statsmodels.tsa.arima_model import ARIMA
import warnings
warnings.ignore=True
。。。略
# Prediction with ARIMA
# y_pred, se, conf = model_fit.forecast(202)
y_pred, se, conf = model_fit.forecast(216)
# Calcuate metrics
score_mae = mean_absolute_error(y_valid, y_pred)
score_rmse = math.sqrt(mean_squared_error(y_valid, y_pred))
print(Fore.GREEN + 'RMSE: {}'.format(score_rmse))
RMSE: 30973.353510293528
f, ax = plt.subplots(1)
f.set_figheight(6)
f.set_figwidth(15)
model_fit.plot_predict(1, 1300, ax=ax)
sns.lineplot(x=x_valid.index, y=y_valid['y'], ax=ax, color='orange', label='Ground truth') #navajowhite
ax.set_title(f'Prediction \n MAE: {score_mae:.2f}, RMSE: {score_rmse:.2f}', fontsize=14)
ax.set_xlabel(xlabel='Date', fontsize=14)
ax.set_ylabel(ylabel='总有功功率(kw)', fontsize=14)
ax.set_ylim(100000, 350392)
plt.show()

f, ax = plt.subplots(1)
f.set_figheight(4)
f.set_figwidth(15)
sns.lineplot(x=x_valid.index, y=y_pred, ax=ax, color='blue', label='predicted') #navajowhite
sns.lineplot(x=x_valid.index, y=y_valid['y'], ax=ax, color='orange', label='Ground truth') #navajowhite
ax.set_xlabel(xlabel='Date', fontsize=14)
ax.set_ylabel(ylabel='总有功功率(kw)', fontsize=14)
plt.show()

8.2.2 LSTM
from sklearn.preprocessing import MinMaxScaler
data = univariate_df.filter(['y'])
#Convert the dataframe to a numpy array
dataset = data.values
scaler = MinMaxScaler(feature_range=(-1, 0))
scaled_data = scaler.fit_transform(dataset)
scaled_data[:10]
array([[-0.50891613], [-0.50891613], [-0.59567808], [-0.59567808], [-0.60361527], [-1. ], [-0.63509216], [-0.63509216], [-0.58983584], [-0.58983584]])
# Defines the rolling window
look_back = 52
# Split into train and test sets
train, test = scaled_data[:train_size-look_back,:], scaled_data[train_size-look_back:,:]
d。。。略
x_train, y_train = create_dataset(train, look_back)
x_test, y_test = create_dataset(test, look_back)
# reshape input to be [samples, time steps, features]
x_train = np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1]))
x_test = np.reshape(x_test, (x_test.shape[0], 1, x_test.shape[1]))
print(len(x_train), len(x_test))
from keras.models import Sequential
from keras.layers import Dense, LSTM
#Build the LSTM model
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape=(x_train.shape[1], x_train.shape[2])))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')
#Train the model
model.fit(x_train, y_train, batch_size=16, epochs=10, validation_data=(x_test, y_test))
model.summary()
Epoch 1/10 70/70 [] - 15s 10ms/step - loss: 0.0417 - val_loss: 0.0071 Epoch 2/10 70/70 [] - 0s 3ms/step - loss: 0.0104 - val_loss: 0.0036 Epoch 3/10 70/70 [] - 0s 6ms/step - loss: 0.0081 - val_loss: 0.0023 Epoch 4/10 70/70 [] - 0s 4ms/step - loss: 0.0064 - val_loss: 0.0017 Epoch 5/10 70/70 [] - 0s 4ms/step - loss: 0.0059 - val_loss: 0.0017 Epoch 6/10 70/70 [] - 0s 3ms/step - loss: 0.0053 - val_loss: 0.0019 Epoch 7/10 70/70 [] - 0s 3ms/step - loss: 0.0065 - val_loss: 0.0019 Epoch 8/10 70/70 [] - 0s 3ms/step - loss: 0.0051 - val_loss: 0.0013 Epoch 9/10 70/70 [] - 0s 3ms/step - loss: 0.0048 - val_loss: 0.0023 Epoch 10/10 70/70 [] - 0s 4ms/step - loss: 0.0052 - val_loss: 0.0012 Model: “sequential” _________________________________________________________________
Layer (type) Output Shape Param # =================================================================
lstm (LSTM) (None, 1, 128) 92672
stm_1 (LSTM) (None, 64) 49408
dense (Dense) (None, 25) 1625
dense_1 (Dense) (None, 1) 26 =================================================================
Total params: 143,731 Trainable params: 143,731 Non-trainable params: 0
# Lets predict with the model
train_predict = model.predict(x_train)
test_predict = model.predict(x_test)
# invert predictions
train_predict = scaler.inverse_transform(train_predict)
y_train = scaler.inverse_transform([y_train])
test_predict = scaler.inverse_transform(test_predict)
y_test = scaler.inverse_transform([y_test])
# Get the root mean squared error (RMSE) and MAE
score_rmse = np.sqrt(mean_squared_error(y_test[0], test_predict[:,0]))
score_mae = mean_absolute_error(y_test[0], test_predict[:,0])
print(Fore.GREEN + 'RMSE: {}'.format(score_rmse))
from sklearn.metrics import r2_score
print('R2-score:',r2_score(y_test[0], test_predict[:,0]))
RMSE: 4502.091881948914
R2-score: 0.9519027039841994
x_train_ticks = univariate_df.head(train_size)['ds']
y_train = univariate_df.head(train_size)['y']
x_test_ticks = univariate_df.tail(test_size)['ds']
# Plot the forecast
f, ax = plt.subplots(1)
f.set_figheight(6)
f.set_figwidth(15)
sns.lineplot(x=x_train_ticks, y=y_train, ax=ax, label='Train Set') #navajowhite
sns.lineplot(x=x_test_ticks, y=test_predict[:,0], ax=ax, color='green', label='Prediction') #navajowhite
sns.lineplot(x=x_test_ticks, y=y_test[0], ax=ax, color='orange', label='Ground truth') #navajowhite
ax.set_title(f'Prediction \n MAE: {score_mae:.2f}, RMSE: {score_rmse:.2f}', fontsize=14)
ax.set_xlabel(xlabel='Date', fontsize=14)
ax.set_ylabel(ylabel='总有功功率(kw)', fontsize=14)
plt.show()

8.2.3 AutoARIMA
from statsmodels.tsa.arima_model import ARIMA
import pmdarima as pm
。。。略
print(model.summary())

y_pred = model.predict(216)
from sklearn.metrics import r2_score
print('R2-score:',r2_score(y_valid, y_pred))
R2-score: -0.08425358340633804
model.plot_diagnostics(figsize=(16,8))
plt.show()

8.3 多元时序预测
df.columns
Index([‘date’, ‘总有功功率(kw)’, ‘最高温度’, ‘最低温度’, ‘白天风力风向’, ‘夜晚风力风向’, ‘天气1’, ‘天气2’], dtype=‘object’)
feature_columns = [
'最高温度', '最低温度', '白天风力风向', '夜晚风力风向', '天气1', '天气2'
]
target_column = ['总有功功率(kw)']
train_size = int(0.85 * len(df))
multivariate_df = df[['date'] + target_column + feature_columns].copy()
multivariate_df.columns = ['ds', 'y'] + feature_columns
train = multivariate_df.iloc[:train_size, :]
x_train, y_train = pd.DataFrame(multivariate_df.iloc[:train_size, [0,2,3,4,5,6,7]]), pd.DataFrame(multivariate_df.iloc[:train_size, 1])
x_valid, y_valid = pd.DataFrame(multivariate_df.iloc[train_size:, [0,2,3,4,5,6,7]]), pd.DataFrame(multivariate_df.iloc[train_size:, 1])
train.head()

train =multivariate_df.iloc[:train_size, :]
train

8.3.1 多元Propher
from fbprophet import Prophet
# Train the model
model = Prophet()
# model.add_regressor('最高温度')
# model.add_regressor('最低温度')
# model.add_regressor('白天风力风向')
# model.add_regressor('夜晚风力风向')
# model.add_regressor('天气1')
# model.add_regressor('天气2')
# Fit the model with train set
model.fit(train)
# Predict on valid set
y_pred = model.predict(x_valid)
# Calcuate metrics
score_mae = mean_absolute_error(y_valid, y_pred['yhat'])
score_rmse = math.sqrt(mean_squared_error(y_valid, y_pred['yhat']))
print(Fore.GREEN + 'RMSE: {}'.format(score_rmse))
from sklearn.metrics import r2_score
print('R2-score:',r2_score(y_valid, y_pred['yhat']))
# Plot the forecast
f, ax = plt.subplots(1)
f.set_figheight(6)
f.set_figwidth(15)
model.plot(y_pred, ax=ax)
sns.lineplot(x=x_valid['ds'], y=y_valid['y'], ax=ax, color='orange', label='Ground truth') #navajowhite
ax.set_title(f'Prediction \n MAE: {score_mae:.2f}, RMSE: {score_rmse:.2f}', fontsize=14)
ax.set_xlabel(xlabel='Date', fontsize=14)
ax.set_ylabel(ylabel='总有功功率(kw)', fontsize=14)
plt.show()
