python决策树———泰坦尼克号乘客生存预测完整流程
一、前序
1. 数据介绍
在Kaggle举行了很多数据分析比赛,其中比较著名的就有泰坦尼克号乘客生还预测,主要分析在泰坦尼克号事件中,存活下来的人主要特征是什么。
该数据集共有数据量1309,其中训练集的大小为891,测试集大小为418。
数据一共12个特征,如下所示:
PassengerId: 乘客编号
Survived :存活情况(存活:1 ; 死亡:0)
Pclass : 客舱等级
Name : 乘客姓名
Sex : 性别
Age : 年龄
SibSp : 同乘的兄弟姐妹/配偶数
Parch : 同乘的父母/小孩数
Ticket : 船票编号
Fare : 船票价格
Cabin :客舱号
Embarked : 登船港口
2. 工具介绍
本次数据分析用到的工具有:
①scikit-learn 0.20.1
②pandas 0.25.0
③numpy 1.19.0
④python 3.6
⑤matplotlib
⑥jupyter notebook(主要编程工具)
二. 数据处理
1. 查看数据
#1 导包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score #交叉验证
from sklearn.model_selection import train_test_split #训练集测试集的划分
from sklearn.model_selection import GridSearchCV #网格搜索
from sklearn import tree
#2 导入数据
data = pd.read_csv(r"C:\Users\Administrator\Desktop\data.csv")
# 查看数据大小
print('数据集的大小:',data.shape)
# 数据的前几行
data.head()
数据共有891行,12列

'''
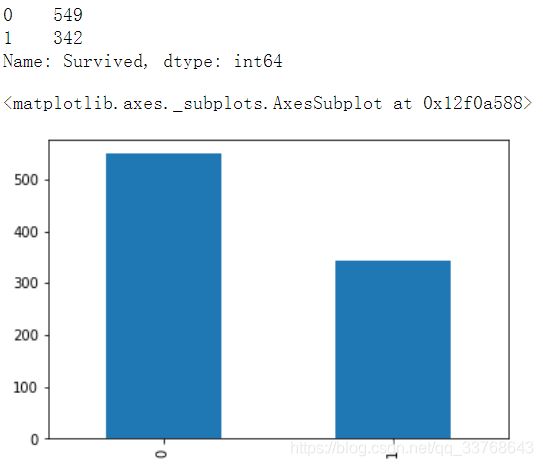
训练集中类别为0(死亡)的有549个,类别为1(存活)的有342个
'''
print(data.Survived.value_counts())
data.Survived.value_counts().plot(kind='bar')
2. 查看数据描述和完整性
data.describe()

data.info()
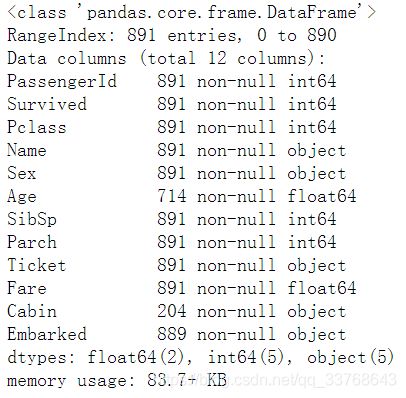
从中可以看出,上表中看到Age列有714行,缺失了177行;
Cabin有204行,缺失了687行;
Embarked有889行,缺失了2行。
所以我们要对缺失值进行处理。
3. 缺失值处理
首先删除掉缺失值太多的列,与预测结果无关的列Cabin、Name、Ticket、PassengerId
data = data.drop(["Cabin","Name","Ticket","PassengerId"],axis=1)
接着是对Age和Embarked列进行填充;
对于Age,用中位数填充,因为中位数不受极端的影响;
对于Embarked,用最多的值填充,这个特征在该数据中最多的值为S。

print(data['Embarked'].value_counts())
data['Embarked'].fillna('S', inplace=True)
查看处理后的数据,可以看到数据中不在有缺失特征的数据了。
data.info()
data.head()

4. 特征提取
有些变量是离散型的,如Sex、Pclass和Embarked,我们对这些特征进行处理,用数值代替类别,并对其中两类以上的特征进行One-hot编码。
# 将性别的值映射为数值
sex_mapDict = {'male':1, 'female':0}
data['Sex'] = data['Sex'].map(sex_mapDict)
# 对Pclass和Embarked特征进行One-Hot编码
data = pd.concat([data, pd.get_dummies(data['Pclass'], prefix='Pclass')], axis=1)
data = pd.concat([data, pd.get_dummies(data['Embarked'], prefix='Embarked')], axis=1)
# 删除舰艇等级(Pclass)和(Embarked)列
data.drop('Embarked', axis=1, inplace=True)
data.drop('Pclass', axis=1, inplace=True)
data.head()

**三. 特征选择 **
该阶段我们的目的是选择重要特征进行训练,我们用pearson相关系数法查看
corrDf = data.corr()
corrDf['Survived'].sort_values(ascending =False)
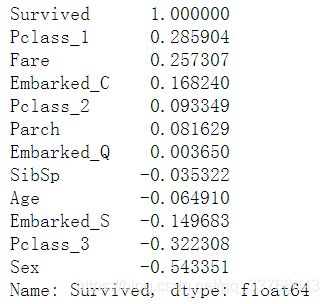
根据结果,从中我们挑选出相关度较高的特征,忽略影响较小的特征。所以我们忽略Parch、SibSp特征,选择剩余特征进行训练。
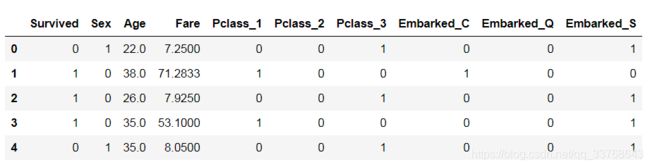
data.drop(['Parch','SibSp'],axis=1, inplace=True)
data.head()
四. 模型训练
4.1 划分数据集
首先我们需要构建训练集和测试集。
data.drop(['Survived'],axis=1,inplace=True)
targets = pd.read_csv(r"C:\Users\Administrator\Desktop\data.csv", usecols=['Survived'])['Survived'].values
#划分训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data, targets, test_size=0.2)
# 输出数据集大小
print ('原始数据集特征:',data.shape,
'训练数据集特征:',train_X.shape ,
'验证数据集特征:',test_X.shape)
print ('原始数据集标签:',targets.shape,
'训练数据集标签:',train_Y.shape ,
'验证数据集标签:',test_Y.shape)
训练集和测试集数量和维度如下所示:

4.2 模型超参数选择
通过GridSearchCV的网格搜索方法,探索决策树的最佳超参数,从splitter、criterion、max_depth和min_samples_leaf四个参数构建出最佳参数方案,评价指标为f1_score,cv(交叉验证)次数为5。
#决策树模型选择
params={
"splitter":("best","random")
,"criterion":("gini","entropy")
,"max_depth":[*range(1,10)]
,"min_samples_leaf":[*range(1,21,2)]
}
clf=tree.DecisionTreeClassifier()
GS = GridSearchCV(clf,params,cv=5,scoring='f1')
GS.fit(train_X,train_Y)
print(GS.best_params_) #最佳参数
print(GS.best_score_) #最优评分(对应最佳参数)
超参数选择结果如下:

4.3 模型训练和评估
我们用上一阶段得到的超参数训练模型并对测试集进行预测,代码和结果如下所示:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(criterion="entropy",max_depth=8, min_samples_leaf=7, splitter='best')
model.fit(train_X,train_Y)
print('决策树score:',model.score(test_X,test_Y))
print('决策树f1_score:',f1_score(test_Y,model.predict(test_X)))

最终f1_score的结果为0.72
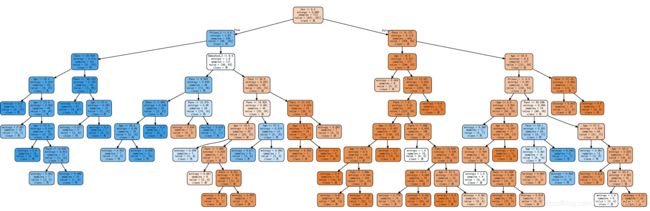
4.4 模型可视化
我们用graphviz包来可视化我们训练好的决策树模型,代码如下
import graphviz
# 特征
feature_name = ['Sex','Age','Fare','Pclass_1','Pclass_2','Pclass_3','Embarked_C','Embarked_Q','Embarked_S']
dot_data = tree.export_graphviz(model,feature_names=feature_name,out_file = 'tree.dot'
,class_names=["活", "死"]
,filled=True
,rounded=True)
with open("tree.dot",encoding='utf-8') as f:
dot_graph = f.read()
graph=graphviz.Source(dot_graph.replace("helvetica","FangSong"))
graph.view()
代码运行效果如下:
4.5 集成学习
我们用集成学习方法再预测一次,随机森林是决策树的集成。
我们通过特征选择,模型训练和模型评估,验证集成学习在测试集上的评估指标是否有提升。
from sklearn.ensemble import RandomForestClassifier
#模型选择
params={
"n_estimators":[*range(10,30)]
,"criterion":("gini","entropy")
,"max_depth":[*range(3,10)]
,"min_samples_leaf":[*range(3,21,5)]
}
clf = RandomForestClassifier()
GS = GridSearchCV(clf,params,cv=5,scoring='f1')
GS.fit(train_X,train_Y)
print(GS.best_params_) #最佳参数
print(GS.best_score_) #最优评分(对应最佳参数)
model = RandomForestClassifier(criterion='entropy',max_depth=8,min_samples_leaf=1,n_estimators=10)
model.fit(train_X,train_Y)
print('随机森林score:',model.score(test_X,test_Y))
print('随机森林f1_score:',f1_score(test_Y,model.predict(test_X)))
评估结果如下,可以看到集成学习确实能提高f1_score
