OpenCV图像处理视频教程——入门篇(二)
文章目录
-
- 10 膨胀与腐蚀
-
- (1)形态学操作(morphology operators)——膨胀、腐蚀
- (2)相关API
- (3)动态调整结构元素大小TrackBar
- 11 形态学操作
-
- (1)开操作- open
- (2)闭操作- close
- (3)形态学梯度- Morphological Gradient
- (4)顶帽- Tophat
- (5)黑帽- Blackhat
- (6)API
- 12 形态学操作应用——提取水平与垂直线
-
- (1)原理方法
-
- 结构元素
- (2)提取步骤
- (3)自适应阈值化操作adaptiveThreshold()函数
-
- 函数原型
-
- 参数说明
- (4)实例
- 13 图像金字塔(Image Pyramid)——上采样与降采样(特征提取基础)
-
- (1)图像金字塔概念
- (2)高斯金字塔:
- (3)高斯不同(Difference of Gaussian-DOG):
-
- 拉普拉斯金字塔:
- (4)采样相关API
-
- 演示
-
- normalize函数原型:
- 14 基本阈值操作
-
- (1)图像阈值(Threshold)
- (2)阈值类型
-
- 1)阈值二值化(THRESH_BINARY)
- 2)阈值反二值化(THRESH_BINARY_INV)
- 3)截断(THRESH_TRUNC)
- 4)阈值取零(THRESH_TOZERO)
- 5)阈值反取零(THRESH_TOZERO_INV)
- 6)OTSU算法——最大类间方差法(THRESH_OTSU)
- 7)THRESH_TRANGLE
- (3)代码
- 15 自定义线性滤波
-
- (1)卷积概念
- (2)常见算子
-
- 1)Robert算子
- 2)Sobel算子
- 3)拉普拉斯算子
- (3)自定义卷积滤波
- 16 处理边缘
-
- (1)卷积边缘问题
- (2)处理边缘
- (3)API说明
- 17 Sobel算子
-
- (1)卷积应用-图像边缘提取
-
- Sobel算子
- (2)API说明
- 18 Laplance算子
-
- (1)理论
- (2)cv::Laplacian
- 19 Canny边缘检测
-
- (1)Canny算法介绍
-
- ①计算梯度幅度和方向:
- ②根据角度对幅值进行非极大值抑制
- ③用双阈值算法检测和连接边缘
- (2)API
- 20 霍夫变换 —— 直线
-
- 霍夫直线变换介绍
- API
-
- 标准霍夫变换和多尺度霍夫变换(Standard Hough Transform&Multiscale Hough Transform)
- 渐进概率式霍夫变换(Progressive Probability Houth Transform)
10 膨胀与腐蚀
1 膨胀
2 腐蚀
(1)形态学操作(morphology operators)——膨胀、腐蚀
- 图像形态学操作——基于形状的一系列图像处理操作的合集,主要是基于集合论基础上的形态学数学
- 形态学有四个基本操作:腐蚀、膨胀、开、闭
- 膨胀与腐蚀是图像处理中最常用的形态学操作手段
- 膨胀: 跟卷积操作类似,计算kernel下图像上最大像素值来替换锚点的像素,锚点定义在kernel的中心,kernel可以是任意形状
- 腐蚀: 计算kernel下图像上最小的像素值来替换锚点的像素
(2)相关API
getStructuringElement(int shape, Size ksize, Point anchor);
int shape形状: MORPH_RECT \ MORPH_CROSS \ MORPH_ELLIPSESize ksize大小: kernelPoint anchor锚点: 默认是Point(-1, -1)是中心像素
dilate(Mat src, Mat dst, kernel)
d s t ( x , y ) = max ( x ′ , y ′ ) : e l e m e n t ( x ′ , y ′ ) ≠ 0 s r c ( x + x ′ , y + y ′ ) dst(x,y)=\max_{(x',y'):element(x',y')\neq0}src(x+x',y+y') dst(x,y)=(x′,y′):element(x′,y′)=0maxsrc(x+x′,y+y′)
erode(Mat src, Mat dst, kernel)
d s t ( x , y ) = min ( x ′ , y ′ ) : e l e m e n t ( x ′ , y ′ ) ≠ 0 s r c ( x + x ′ , y + y ′ ) dst(x,y)=\min_{(x',y'):element(x',y')\neq0}src(x+x',y+y') dst(x,y)=(x′,y′):element(x′,y′)=0minsrc(x+x′,y+y′)
(3)动态调整结构元素大小TrackBar
createTrackbar(const String& trackbarname, const String winName, int* value, int count, Trackbarcallback func, void* userdata=0);
其中最重要的是callback函数功能。如果设置为NULL就是说只有值更新,但是不会调用callback的函数。
callback函数形式为(int, void*) typedef void (*TrackbarCallback)(int pos, void* userdata);
highgui.hpp源码中对参数的解释:
@param trackbarname Name of the trackbar.
@param winname Name of the window that is the parent of the trackbar.
部分代码示例:
#include11 形态学操作
1 开操作- open
2 闭操作- close
3 形态学梯度- Morphological Gradient
4 顶帽- top hat
5 黑帽- black hat
(1)开操作- open
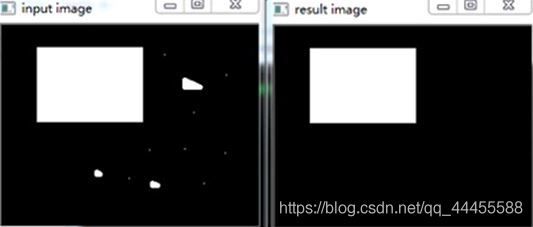
- 先腐蚀后膨胀 d s t = o p e n ( s r c , e l e m e n t ) = d i l a t e ( e r o d e ( s r c , e l e m e n t ) ) dst = open(src, element) = dilate(erode(src, element)) dst=open(src,element)=dilate(erode(src,element))
- 可以去掉小的对象,假设对象是前景色,背景是黑色
(2)闭操作- close
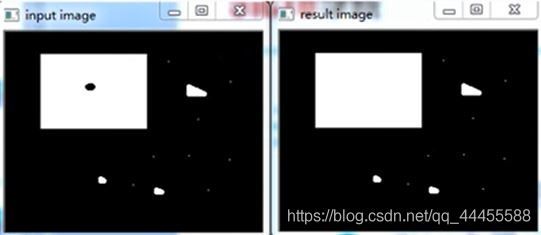
- 先膨胀后腐蚀 d s t = c l o s e ( s r c , e l e m e n t ) = e r a s e ( d i l a t e ( s r c , e l e m e n t ) ) dst=close(src,element)=erase(dilate(src,element)) dst=close(src,element)=erase(dilate(src,element))
- 可以填充小的洞,假设对象是前景色,背景是黑色
(3)形态学梯度- Morphological Gradient
- 膨胀减去腐蚀 d s t = m o r p h g r a d ( s r c , e l e m e n t ) = d i l a t e ( s r c , e l e m e n t ) − e r o d e ( s r c , e l e m e n t ) dst=morph_{grad}(src,element)=dilate(src,element)-erode(src,element) dst=morphgrad(src,element)=dilate(src,element)−erode(src,element)
- 像素差较小的地方 d i l a t e dilate dilate和 e r o d e erode erode得到的锚点结果相近,相减锚点像素低变暗;像素差较大的地方(如边缘) d e l a t e delate delate和 e r o d e erode erode得到锚点像素差距大,相减像素值高变亮
- 又称为基本梯度(其他还有内部梯度、方向梯度)
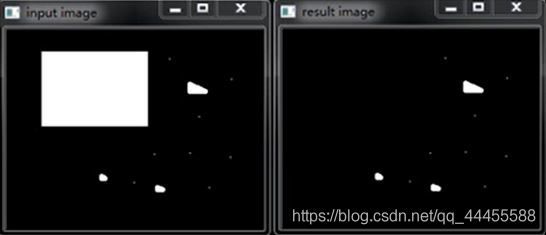
(4)顶帽- Tophat
- 原图像和开操作差值得到的图像
(5)黑帽- Blackhat
- 闭操作和原图像之间的差值得到的图像
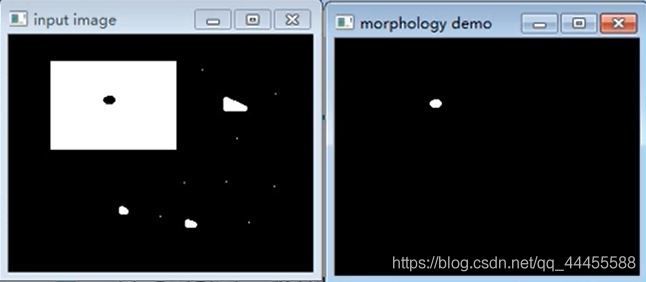
(6)API
morphologyEx(src, dst, CV_MOP_OPEN, kernel);Mat src—— 输入图像Mat dst—— 输出图像int OPT—— MORPH_OPEN / MORPH_CLOSE / MORPH_GRADIENT / MORPH_TOPHAT / MORPH_BLACKHAT 形态学操作类型Mat kernel—— 结构元素int Iteration—— 迭代次数,默认是1
12 形态学操作应用——提取水平与垂直线
1 原理方法
2 实现步骤
(1)原理方法
图像形态学操作时,可以通过自定义的结构元素实现结构元素对输入图像一些对象敏感、一些对象不敏感,这样就会让敏感的对象改变而不敏感的对象保留输出。通过使用两个最基本的形态学操作——膨胀和腐蚀,使用不同的结构元素实现对输入图像的操作,得到想要的结果。
结构元素
- 上述膨胀与腐蚀过程可以使用任意的结构元素
- 常见的形状:矩形、圆、直线、磁盘形状、砖石形状等各种自定义形状
(2)提取步骤
- 输入图像彩色图像
imread - 转换为灰度图像
cvtColor - 转换为二值图像
adaptiveThreshold - 定义结构元素
- 开操作
MORPH_OPEN提取水平垂直线
(3)自适应阈值化操作adaptiveThreshold()函数
在图像阈值化操作中,更关注在二值化图像中对目标和背景进行分割,但是固定的阈值难以达到理想的分割效果。自适应阈值化操作是根据邻域块的像素值分布确定该像素位置上的二值化阈值。
函数原型
void adaptiveThreshold(InputArray src, OutputArray dst,
double maxValue, int adaptiveMethod,
int thresholeType, int blockSize, double C)
参数说明
- 输入图像,单通道8位浮点类型Mat
- 输出图像,和输入图像同样尺寸和类型
- 预设满足条件的最大值
- 指定自适应阈值算法。可选择ADAPTIVE_THRESH_MEAN_C(0)或ADAPTIVE_THRESH_GAUSSIAN_C(1)
- ADAPTIVE_THRESH_MEAN_C是对参数6定义的邻域内取均值,减去参数7得到阈值;THRESH_BINERY将大于阈值的取1,小于阈值的取0;THRESH_BINERY_INV将大于阈值取0,小于阈值的取1
- ADAPTIVE_THRESH_GAUSSIAN_C是对邻域取高斯分布加权后的结果,再做相应的操作
- 指定阈值类型。可选择THRESH_BINERY(0)或THRESH_BINARY_INV(1)(即二进制阈值或反二进制阈值)
- 邻域块大小,用来计算区域阈值
- 参数C是与算法有关的参数,是一个从均值或加权均值提取的常数
在Mat对象前加~可以取反即 像 素 = 255 − 像 素 像素=255-像素 像素=255−像素,和bitwise_not()一样。
(4)实例
- 图像 bit.png
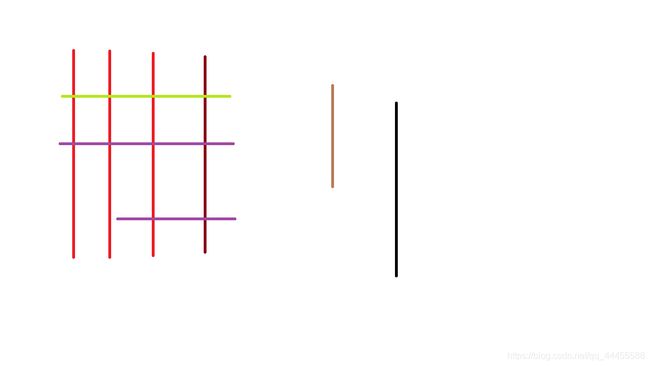
#include 
2. 图片ABCD.png

#include 
13 图像金字塔(Image Pyramid)——上采样与降采样(特征提取基础)
1 图像金字塔概念
2 采样API
可以参考 1、2
(1)图像金字塔概念
- 我们在图像处理中常常会调整图像大小,最常见的就是放大(zoom in)和缩小(zoom out),尽管几何变换也可以实现图像的放大和缩小,但是我们使用图像金字塔
- 一个图像金字塔是一系列的图像组成,最底层一张是图像尺寸最大,最上方的图像尺寸最小,从空间上从上向下看就像一个古代的金字塔
分辨率(resolution):采样点的个数
- 高斯金字塔: 用来对图像进行降采样
- 拉普拉斯金字塔: 用来重建一张图片根据它的上采样图片
(2)高斯金字塔:
- 高斯金字塔是从底向上,逐层降采样得到
- 降采样之后图像大小是原图像 H × W H×W H×W的四分之一 H 2 × W 2 \frac{H}{2}×\frac{W}{2} 2H×2W,就是对原图像删除偶数行与列,即可得到降采样之后的图片
- 高斯金字塔的生成过程分为两步:
- 对当前层进行高斯模糊
- 删除当前层的偶数行与列
(3)高斯不同(Difference of Gaussian-DOG):
- 定义:就是把同一张图像在不同的参数下做高斯模糊之后的结果相减,得到的输出图像。称为高斯不同(DOG)
- 高斯不同是图像的内在特征,在灰度图像增强、角点检测中经常用到

拉普拉斯金字塔:

(4)采样相关API
- 上采样(cv::pyrUp) —— zoom in 放大
pyrUp(Mat src, Mat dst, Size(src.cols*2, src.rows*2))生成的图像是原图在宽与高各放大两倍
- 降采样(cv::pyrDown) —— zoom out 缩小
pyrDown(Mat src, Mat dst, Size(src.cols/2, src.rows/2))生成的图像是原图在宽与高各缩小1/2
演示
#include 这里为了使得DOG显示的更明显,引入归一化normalize。
normalize函数原型:
void normalize(InputArray src, OutputArraydst, double alpha = 1, double beta = 0, int norm_type = NORM_L2, int dtype = -1, InputArray mask = noArray() )
- double alpha —— range normalization模式的最大值
- double beta —— range normalization模式的最小值
- int norm_type —— 归一化的类型(枚举类型)
- NORM_MINMAX: 数组的数值被平移或缩放到一个指定的范围,线性归一化,一般较常用
d s t ( i , j ) = ( s r c ( i , j ) − m i n ( s r c ) ) ∗ ( α − β ) ( m a x ( s r c ) − m i n ( s r c ) ) + β dst(i,j)=\frac{(src(i,j)-min(src))*(\alpha-\beta)}{(max(src)-min(src)) + \beta} dst(i,j)=(max(src)−min(src))+β(src(i,j)−min(src))∗(α−β)也就是各个像素值乘上了norm的倍数 - NORM_INF: 归一化数组的C-范数(绝对值的最大值)
- NORM_L1 : 归一化数组的L1-范数(绝对值的和)
- NORM_L2: 归一化数组的(欧几里德)L2-范数 根号下平方和
- NORM_MINMAX: 数组的数值被平移或缩放到一个指定的范围,线性归一化,一般较常用
- int dtype —— -1即默认输出数组和输入数组的type相同
- mask —— 操作腌膜
14 基本阈值操作
1 图像阈值
2 阈值类型
OpenCV官方文档
(1)图像阈值(Threshold)
阈值是什么?简单点说是把图像分割的标尺,这个标尺是根据阈值产生算法(Binary Segmentation二值分割)

(2)阈值类型
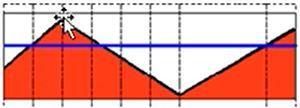
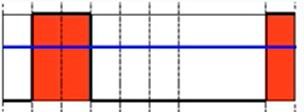
1)阈值二值化(THRESH_BINARY)

这个图片内还包含了自适应阈值化——可以参考第12节
d s t ( x , y ) = { m a x V a l , if src(x,y) > thresh 0 , otherwise dst(x,y)= \begin{cases} maxVal, & \text {if src(x,y) > thresh} \\ 0, & \text{otherwise} \end{cases} dst(x,y)={maxVal,0,if src(x,y) > threshotherwise
大于阈值为1,小于阈值为0
2)阈值反二值化(THRESH_BINARY_INV)
d s t ( x , y ) = { 0 , if src(x,y) > thresh m a x V a l , otherwise dst(x,y)= \begin{cases} 0, & \text {if src(x,y) > thresh} \\ maxVal, & \text{otherwise} \end{cases} dst(x,y)={0,maxVal,if src(x,y) > threshotherwise
大于阈值为0,小于阈值为1
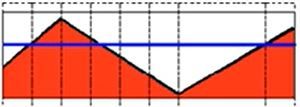
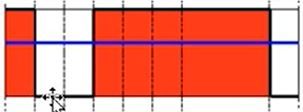
3)截断(THRESH_TRUNC)
d s t ( x , y ) = { t h r e s h o l d , if src(x,y) > thresh s r c ( x , y ) , otherwise dst(x,y)= \begin{cases} threshold, & \text {if src(x,y) > thresh} \\ src(x,y), & \text{otherwise} \end{cases} dst(x,y)={threshold,src(x,y),if src(x,y) > threshotherwise
大于阈值为阈值,小于阈值保留
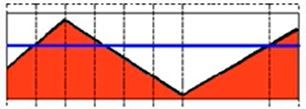
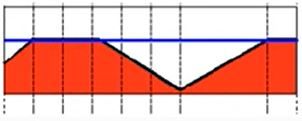
4)阈值取零(THRESH_TOZERO)
d s t ( x , y ) = { s r c ( x , y ) , if src(x,y) > thresh 0 , otherwise dst(x,y)= \begin{cases} src(x,y), & \text {if src(x,y) > thresh} \\ 0, & \text{otherwise} \end{cases} dst(x,y)={src(x,y),0,if src(x,y) > threshotherwise
大于阈值保留,小于阈值取零
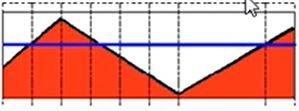

5)阈值反取零(THRESH_TOZERO_INV)
d s t ( x , y ) = { 0 , if src(x,y) > thresh s r c ( x , y ) , otherwise dst(x,y)= \begin{cases} 0, & \text {if src(x,y) > thresh} \\ src(x,y), & \text{otherwise} \end{cases} dst(x,y)={0,src(x,y),if src(x,y) > threshotherwise
大于阈值取零,小于阈值保留

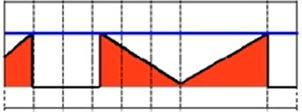
6)OTSU算法——最大类间方差法(THRESH_OTSU)
适用于大多数求全局阈值情况,但只能针对单一目标分割,对目标和背景大小悬殊,类间方差函数可能呈多峰的情况,效果不好。
原理反推:
OTSU算法是假设了一个阈值,分别对大于阈值的一类C1和小于阈值的一类C2做局部方差,两类的局部均值分别是Mean1和Mean2,图像的全局均值是Mean,像素被分成C1的概率是P1,被分成C2的概率是P2。
P 1 ∗ M e a n 1 + P 2 ∗ M e a n 2 = M e a n P1*Mean1+P2*Mean2=Mean P1∗Mean1+P2∗Mean2=Mean
P 1 + P 2 = 1 P1+P2=1 P1+P2=1
类间方差:
σ 2 = P 1 ( M e a n 1 − M e a n ) 2 + P 2 ( M e a n 2 − M e a n ) 2 \sigma^2=P1(Mean1-Mean)^2+P2(Mean2-Mean)^2 σ2=P1(Mean1−Mean)2+P2(Mean2−Mean)2
σ 2 = P 1 ⋅ P 2 ( M e a n 1 − M e a n 2 ) 2 \sigma^2=P1·P2(Mean1-Mean2)^2 σ2=P1⋅P2(Mean1−Mean2)2
该算法的目的就是使这个类间方差最大化。
可以参考这位博主(写的很详细,我也是借鉴了他的内容):https://blog.csdn.net/weixin_40647819/article/details/90179953
7)THRESH_TRANGLE
这个不做过多解释了,同样是用来寻找阈值的方法。
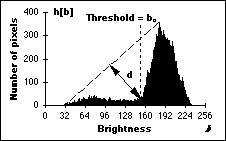
这两种算法仅适用于灰度八位图像!!!
(3)代码
#include 15 自定义线性滤波
1 卷积概念
2 常见算子
3 自定义卷积模糊
(1)卷积概念
我觉得知乎这篇写的很易懂,不是令人头大的傅里叶和拉普拉斯变换https://www.zhihu.com/question/22298352。
- 卷积是图像处理中一个操作,是kernel在图像的每个像素上的操作
- Kernel(算子)本质上一个固定大小的矩阵数组,其中心点称作锚点(Anchor Point)
- 简单来讲,对图像的卷积就是把kernel放到像素数组上,求算锚点周围覆盖的像素点积和,用来替换掉锚点覆盖下的那个像素点,准确的说这里的kernel旋转了180°

对这个图片而言:
d s t ( x , y ) = ∑ i = − 1 1 ∑ j = − 1 1 g ( i , j ) f ( x − j , y − j ) dst(x,y)=\sum_{i=-1}^{1}\sum_{j=-1}^{1}g(i,j)f(x-j,y-j) dst(x,y)=i=−1∑1j=−1∑1g(i,j)f(x−j,y−j)
不是大家熟悉的数学上卷积操作的原因是图片像素是离散的,连续的卷积公式是:
f ( t ) ∗ g ( t ) = ∫ − ∞ + ∞ f ( τ ) g ( t − τ ) d τ f(t)*g(t)=\int_{-\infty}^{+\infty}f(\tau)g(t-\tau)d\tau f(t)∗g(t)=∫−∞+∞f(τ)g(t−τ)dτ当然这是傅里叶卷积变换还有拉普拉斯卷积变换
f ( t ) ∗ g ( t ) = ∫ 0 t f ( τ ) g ( t − τ ) d τ f(t)*g(t)=\int_{0}^tf(\tau)g(t-\tau)d\tau f(t)∗g(t)=∫0tf(τ)g(t−τ)dτ
(2)常见算子
1)Robert算子
Robert_X会使得图像反对角线的边缘差异明显。
原理:像素变化较小的地方,反对角线1和-1使得锚点像素接近0(黑),在像素变化较大的边缘,会使锚点像素>0与周围像素0相比更明显。
∣ + 1 0 0 − 1 ∣ \begin{vmatrix} +1 & 0 \\ 0 & -1 \\ \end{vmatrix} ∣∣∣∣+100−1∣∣∣∣
Robert_Y会使得图像正对角线的边缘差异明显。
∣ 0 + 1 − 1 0 ∣ \begin{vmatrix} 0 & +1 \\ -1 & 0 \\ \end{vmatrix} ∣∣∣∣0−1+10∣∣∣∣
2)Sobel算子
边缘检测,是canny边缘检测重要的一步。
Sobel_X这个x方向的算子会使x方向边缘增强。
∣ − 1 0 1 − 2 0 2 − 1 0 1 ∣ \begin{vmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \\ \end{vmatrix} ∣∣∣∣∣∣−1−2−1000121∣∣∣∣∣∣
Sobel_Y这个y方向的算子会使y方向边缘增强。
∣ − 1 − 2 − 1 0 0 0 1 2 1 ∣ \begin{vmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \\ \end{vmatrix} ∣∣∣∣∣∣−101−202−101∣∣∣∣∣∣
3)拉普拉斯算子
可以获取整个图像的边缘信息。
∣ 0 − 1 0 − 1 4 − 1 0 − 1 0 ∣ \begin{vmatrix} 0 & -1 & 0 \\ -1 & 4 & -1 \\ 0 & -1 & 0 \\ \end{vmatrix} ∣∣∣∣∣∣0−10−14−10−10∣∣∣∣∣∣
(3)自定义卷积滤波
使用fliter2D,函数原型(之前详解过入门篇(上)第三节):
void filter2D(InputArray src, OutputArray dst, int ddepth, InputArray kernel, Point anchor = Point(-1, -1), double delta = (0.0), int borderType =4)
应用:
Mat src, dst;
src = imread("PATH.jpg");
Mat kernel = (Mat_<uchar>(2, 2) << 1, 0, 0, -1);
filter2D(src, dst, -1, kernel, Point(-1, -1));
再次对waitKey介绍,可以参考https://www.cnblogs.com/happyamyhope/p/8474850.html
- 函数功能:不断刷新图像,频率为delay,单位为毫秒(ms),返回值为当前键盘的按键值
- 等待delay>0毫秒,如果在此期间有按键按下,则立即结束并返回按下按键的ASCII码,否则返回值为-1;若delay=0毫秒,则无限等待下去,直到有按键按下为止
- waitKey仅仅对窗口机制起作用,即nameWindow或者imshow产生的窗口
- 注意!waitKey返回值是int类型的
- 当选用键盘上特定的按键结束循环时,应当将返回值转换成char类型,可以用(char)强制类型转换,也可以用static_cast
()转换 - 举例(部分):
int delay;
int ksize;
int index = 0;
while(true)
{
delay = waitKey(500);
if((char)delay == 27) //ESC
{
break;
}
ksize = 5 + (index % 8) * 2;
Mat kernel = Mat::ones(Size(ksize, ksize), CV_32F) / (float)(ksize * ksize);
filter2D(src, dst, -1, kernel, Point(-1, -1));
index++;
imshow("output", dst);
}
16 处理边缘
1 卷积边缘问题
2 处理边缘
(1)卷积边缘问题
图像卷积的时候边界像素,不能被卷积操作,原因在于边界像素没有完全跟kernel重叠,所以当3×3滤波时有1个像素的边缘没有被处理,5×5滤波的时候有2个像素的边缘未处理。
(2)处理边缘
在卷积开始之前增加边缘像素,填充的像素值为0或者RGB黑色,比如3×3在四周各填充一个像素的边缘,在深度学习中叫padding,这样就确保图像的边缘被处理,在卷积处理之后再去掉这些边缘。OpenCV中默认的处理方法是:BORDER_DEFAULT,此外常用的还有如下几种:
- BORDER_CONSTANT——填充边缘用指定像素值
- BORDER_REPLICATE——填充边缘像素用已知的边缘像素值
- BORDER_WRAP——用另外一边的像素来补充填充
- 意思很像是换行,当处理到图像边缘时,换用下一行的最左端像素做处理
(3)API说明
copyMakeBorder(
Mat src, //输入图像
Mat dst, //添加边缘图像
int top, //边缘长度,一般上下左右都取相同值
int bottom,
int left,
int right,
int borderType, //边缘类型
Scalar value
)
实际上不需要调用copyMakeBorder。调用GaussianBlur时,最后一个参数值默认就是BORDER_DEFAULT,同样也可以换成BORDER_CONSTANT等。
//示例
GaussianBlur(src, dst, Size(5, 5), 0, 0, BORDER_DEFAULT);
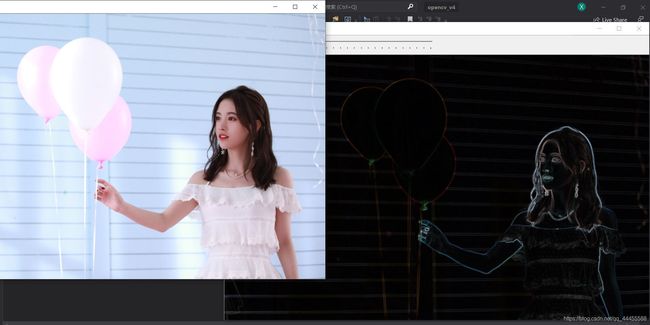
17 Sobel算子
1 卷积应用-图像边缘提取
2 相关API
(1)卷积应用-图像边缘提取
图像求导,由于图像像素值都是离散的,有别于连续的求导方式,使用相邻像素相减即可。
- 边缘是像素值发生跃迁的地方,是图像的显著特征之一,在特征提取、对象检测、模式识别等方面都有重要的作用。
- 如何捕捉/提取边缘——对图像求它的一阶导数 δ = f ( x ) − f ( x − 1 ) \delta = f(x)-f(x-1) δ=f(x)−f(x−1), δ \delta δ越大,说明像素在该方向变化越大。
Sobel算子
- 是离散微分算子(Discrete Differentiation Operator)用来计算图像灰度的近似梯度。
- Sobel算子功能集合了高斯平滑和微分求导。
- 又被成为一阶微分算子,求导算子,在水平和垂直两个方向上求导,得到图像X方向与Y方向梯度图像。
Sobel_X这个x方向的算子会计算x方向边缘梯度。
G x = ∣ − 1 0 1 − 2 0 2 − 1 0 1 ∣ G_x=\begin{vmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \\ \end{vmatrix} Gx=∣∣∣∣∣∣−1−2−1000121∣∣∣∣∣∣
Sobel_Y这个y方向的算子会计算y方向边缘梯度。
G y = ∣ − 1 − 2 − 1 0 0 0 1 2 1 ∣ G_y=\begin{vmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \\ \end{vmatrix} Gy=∣∣∣∣∣∣−101−202−101∣∣∣∣∣∣
最终图像梯度为 G = G x 2 + G y 2 G=\sqrt{G_x^2+G_y^2} G=Gx2+Gy2,为了使得计算机计算更快实际上使用了 G = ∣ G x ∣ + ∣ G y ∣ G=|G_x|+|G_y| G=∣Gx∣+∣Gy∣。
- 求取导数的近似值,kernel=3不是很准确,OpenCV使用改进版本Scharr函数,算子如下:
G x = ∣ − 3 0 3 − 10 0 10 − 3 0 3 ∣ G_x=\begin{vmatrix} -3 & 0 & 3 \\ -10 & 0 & 10 \\ -3 & 0 & 3 \\ \end{vmatrix} Gx=∣∣∣∣∣∣−3−10−30003103∣∣∣∣∣∣
G y = ∣ − 3 − 10 − 3 0 0 0 3 10 3 ∣ G_y=\begin{vmatrix} -3 & -10 & -3 \\ 0 & 0 & 0 \\ 3 & 10 & 3 \\ \end{vmatrix} Gy=∣∣∣∣∣∣−303−10010−303∣∣∣∣∣∣
(2)API说明

cv::Sobel(
InputArray src, //输入图像
OutputArray dst, //输出图像,大小与输入图像一致
int depth, //输出图像深度
int dx, //x方向,几阶导数
int dy, //y方向,几阶导数
int ksize, //卷积核边长
double scale = 1, //放大倍数
double delta = 0,
int borderType = BORDER_DEFAULT //边缘处理
)
cv::Scharr(
//参数相同
)
使用convertScaleAbs可以实现图像增强的快速运算: d s t i = s a t u r a t e u c h a r ( ∣ α ∗ s r c i + β ∣ ) dst_i=saturate_{uchar}(|\alpha*src_i+\beta|) dsti=saturateuchar(∣α∗srci+β∣)
//使用convertScaleAbs
void cv::convertScaleAbs(
cv::InputArray src, // 输入数组
cv::OutputArray dst, // 输出数组
double alpha = 1.0, // 乘数因子
double beta = 0.0 // 偏移量
);
分别使用cv::Sobel对X方向和Y方向求导,并使用addWeighted将两张图片通过权值合并,得到最终边缘特征提取的图片效果。
18 Laplance算子
1 理论
2 API使用
(1)理论
在二阶微分时,最大变化处的值为零即边缘是零值。通过二阶导数计算,根据此理论可以提取边缘。
(2)cv::Laplacian
L a p l a c e ( f ) = δ 2 f δ x 2 + δ 2 f δ y 2 Laplace(f)=\frac{\delta^2 f}{\delta x^2}+\frac{\delta^2 f}{\delta y^2} Laplace(f)=δx2δ2f+δy2δ2f
处理流程:
- 高斯模糊 —— 去除噪声GaussianBlur()
- 转换为灰度图像cvtColor()
- 拉普拉斯 —— 二阶导数计算Laplacian()
- 取绝对值convertScaleAbs()
//imread就省去了
Mat src, dst, gray_src, edge_image;
GaussianBlur(src, dst, Size(3,3), 0, 0);
cvtColor(dst, gray_src, CV_BGR2GRAY);
//Sobel算子示例,位图深度应≥原深度八位CV_8U
Mat sobel_x, sobel_y;
Sobel(gray_src, sobel_x, -1, 1, 0, 3);
Sobel(gray_src, sobel_y, -1, 0, 1, 3);
addWeighted(sobel_x, 0.5, sobel_y, 0.5, dst);
convertScaleAbs(dst, dst); //先求绝对值,再取saturate
imshow("sobel_image", dst);
//Laplance算子
Mat laplacian_img;
Laplaican(gray_src, laplacian_img, -1, 3);
convertScaleAbs(laplancian_img, laplancian_img);
threshold(laplancian_img, laplancian_img, 0, 255, THRESH_OTSU);
imshow("laplance_img", laplancian_img);
19 Canny边缘检测
1 Canny算法介绍
2 API cv::Canny()
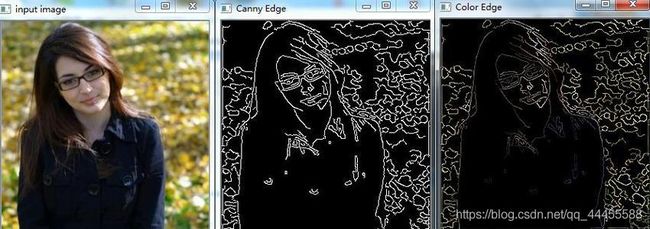
(1)Canny算法介绍
Canny边缘检测相比Sobel算子,做了改进:
- 基于边缘梯度方向的非极大值抑制;
- 双阈值的滞后阈值处理。
- 高斯模糊 —— GaussianBlur
- 灰度转换 —— cvtColor
- 计算梯度 —— Sobel/Scharr
- 根据梯度方向,进行非最大信号抑制 —— 在切向和法向把非最大像素点去掉
- 高低阈值和连接边缘
①计算梯度幅度和方向:
OpenCV中使用Sobel算子求取梯度信息。可以参考上一版。
Sobel_X这个x方向的算子会计算x方向边缘梯度。
G x = ∣ − 1 0 1 − 2 0 2 − 1 0 1 ∣ G_x=\begin{vmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \\ \end{vmatrix} Gx=∣∣∣∣∣∣−1−2−1000121∣∣∣∣∣∣
Sobel_Y这个y方向的算子会计算y方向边缘梯度。
G y = ∣ − 1 − 2 − 1 0 0 0 1 2 1 ∣ G_y=\begin{vmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \\ \end{vmatrix} Gy=∣∣∣∣∣∣−101−202−101∣∣∣∣∣∣
最终图像梯度为: G = G x 2 + G y 2 G=\sqrt{G_x^2+G_y^2} G=Gx2+Gy2
为了使得计算机计算更快实际上使用了: G = ∣ G x ∣ + ∣ G y ∣ G=|G_x|+|G_y| G=∣Gx∣+∣Gy∣角度为: θ M = a r c t a n d y d x \theta_M=arctan\frac{d_y}{d_x} θM=arctandxdy
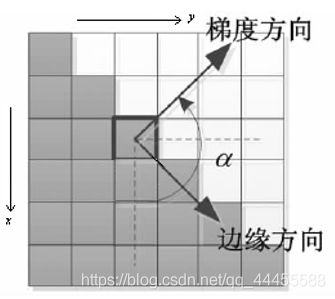
②根据角度对幅值进行非极大值抑制
沿着梯度方向对幅值进行非极大值抑制,而非边缘方向。
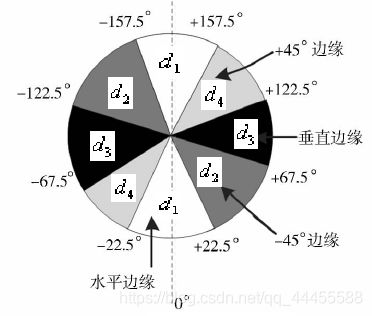
抑制方向为:
- 水平边缘 —— 梯度方向为垂直: θ M ∈ [ − 22.5 , 22.5 ] ⋃ [ − 157.5 , 157.5 ] \theta_M\in[-22.5, 22.5]\bigcup[-157.5,157.5] θM∈[−22.5,22.5]⋃[−157.5,157.5]
- 垂直边缘 —— 梯度方向为水平: θ M ∈ [ 67.5 , 112.5 ] ⋃ [ − 112.5 , − 67.5 ] \theta_M\in[67.5, 112.5]\bigcup[-112.5,-67.5] θM∈[67.5,112.5]⋃[−112.5,−67.5]
- 45°边缘 —— 梯度方向为135°: θ M ∈ [ 112.5 , 157.5 ] ⋃ [ − 67.5 , − 22.5 ] \theta_M\in[112.5, 157.5]\bigcup[-67.5,-22.5] θM∈[112.5,157.5]⋃[−67.5,−22.5]
- 135°边缘 —— 梯度方向为45°: θ M ∈ [ 22.5 , 67.5 ] ⋃ [ − 157.5 , − 112.5 ] \theta_M\in[22.5, 67.5]\bigcup[-157.5,-112.5] θM∈[22.5,67.5]⋃[−157.5,−112.5]
非最大值抑制就是沿着抑制方向(梯度方向)保留邻域内极大值,删去其他边缘像素值。在每个点上,邻域中心与沿着对应梯度方向的两个像素值相比,若中心像素为最大值,测保留,否则置0,以便细化边缘。
③用双阈值算法检测和连接边缘
- 选取系数TH和TL,比率为2:1或3:1(一般取TH=0.3,TL=0.1);
- 将小于低阈值的点抛弃,赋0;大于高阈值的点标记成边缘点,赋1或255;
- 将小于高阈值,大于低阈值的点与TH像素连接时赋为边缘点。
(2)API
void Canny(InputArray image, OutputArray edges, double threshold1,
double threshold2, int apertureSize=3, bool L2gradient=false)
20 霍夫变换 —— 直线
1 霍夫直线变换介绍
2 API
霍夫直线变换介绍
参考霍夫变换直线检测(Line Detection)原理及示例
- Hough Line Transform用来做直线检测
- 前提条件是已经完成了边缘检测
- 平面空间到极坐标空间转换
x = ρ c o s θ , y = ρ s i n θ x=\rho cos\theta,y=\rho sin\theta x=ρcosθ,y=ρsinθ
ρ = x 2 + y 2 , t a n θ = y x ( x ≠ 0 ) \rho=x^2+y^2,tan\theta=\frac{y}{x}(x≠0) ρ=x2+y2,tanθ=xy(x=0) - 对于任意一条直线上的所有点来说,变换到极坐标系中,可以得到 ρ \rho ρ的大小 ρ = x c o s θ + y s i n θ \rho=xcos\theta+ysin\theta ρ=xcosθ+ysinθ

- 属于同一条直线上的点在极坐标 ( ρ , θ ) (\rho,\theta) (ρ,θ)必然在一个点上有最强的信号出现,根据此反算到平面坐标中就可以得到直线上各点的像素坐标,从而得到直线

- 如上图所示,左上图中一条直线,在不同坐标点带入公式 ρ = x c o s θ + y s i n θ \rho=xcos\theta+ysin\theta ρ=xcosθ+ysinθ,计算不同角度下的 ρ \rho ρ值,可以发现 ρ = 9 2 2 \rho=\frac{9\sqrt2}{2} ρ=292记5票,所以得到该直线在这个 8 ∗ 8 8*8 8∗8的像素坐标中的极坐标方程是 9 2 2 = x ∗ c o s 45 ° + y ∗ s i n 45 ° \frac{9\sqrt2}{2}=x*cos45°+y*sin45° 292=x∗cos45°+y∗sin45°,再 x = ρ c o s θ , y = ρ s i n θ x=\rho cos\theta,y=\rho sin\theta x=ρcosθ,y=ρsinθ变换回x-y坐标系。
API
标准霍夫变换和多尺度霍夫变换(Standard Hough Transform&Multiscale Hough Transform)
cv::HoughLines(
InputArray src, //输入图像,必须是8-bit的灰度图像
OutputArray lines, //输出的极坐标来表示直线
double rho, //生成极坐标时候的像素扫描步长,以像素为单位
double theta, //生成极坐标时候的角度步长,一般取值CV_PI/180,以弧度为单位
int threshold, //阈值。累加计数值的阈值参数,当参数空间某个交点的累加计数的值超过该阈值,则认为该交点对应了图像空间的一条直线。
double srn=0, //默认值为0,用于在多尺度霍夫变换中作为参数rho的除数,rho=rho/srn。
double stn=0, //默认值为0,用于在多尺度霍夫变换中作为参数theta的除数,theta=theta/stn。
//如果srn和stn同时为0,就表示HoughLines函数执行标准霍夫变换,否则就是执行多尺度霍夫变换。
double min_theta=0, //表示角度扫描范围0~180之间
double max_theta=CV_PI
)
渐进概率式霍夫变换(Progressive Probability Houth Transform)
cv::HoughLinesP(
InputArray src, //输入图像,必须8-bit的灰度图像
OutputArray lines, //输出的极坐标来表示直线
double rho, //生成极坐标的时候像素扫描步长
double theta, //生成极坐标时的角度步长,一般取值CV_PI/180
int threshold, //阈值,只有获得足够交点的极坐标点才被看成是直线
double minLineLength=0, //最小直线长度
double maxLineGap=0 //最大间隔。表示直线断裂的最大间隔距离阈值。即如果有两条线段是在一条直线上,但它们之间有间隙,那么如果这个间隔距离小于该值,则被认为是一条线段,否则认为是两条线段。
)
#include plines;
HoughLinesP(src_gray, plines, 1, CV_PI / 180.0, 10, 0, 10);
Scalar color = Scalar(0, 0, 255);
for (size_t i = 0; i < plines.size(); i++) {
Vec4f hline = plines[i];
line(dst, Point(hline[0], hline[1]), Point(hline[2], hline[3]), color, 3, LINE_AA);
}*/
imshow(OUTPUT_TITLE, dst);
waitKey(0);
return 0;
}