从前慢-Mysql高级及实战
Mysql高级及实战

1 Linux 系统安装MySQL
1.1 下载Linux 安装包
https://dev.mysql.com/downloads/mysql/5.7.html#downloads
1.2 安装MySQL
1) 卸载 centos 中预安装的 mysql
rpm -qa | grep -i mysql
rpm -e mysql-libs-5.1.71-1.el6.x86_64 --nodeps
2) 上传 mysql 的安装包
alt + p -------> put E:/test/MySQL-5.6.22-1.el6.i686.rpm-bundle.tar
3) 解压 mysql 的安装包
mkdir mysql
tar -xvf MySQL-5.6.22-1.el6.i686.rpm-bundle.tar -C /root/mysql
4) 安装依赖包
yum -y install libaio.so.1 libgcc_s.so.1 libstdc++.so.6 libncurses.so.5 --setopt=protected_multilib=false
yum update libstdc++-4.4.7-4.el6.x86_64
5) 安装 mysql-client
rpm -ivh MySQL-client-5.6.22-1.el6.i686.rpm
6) 安装 mysql-server
rpm -ivh MySQL-server-5.6.22-1.el6.i686.rpm
1.3 启动 MySQL 服务
service mysql start
service mysql stop
service mysql status
service mysql restart
1.4 登录MySQL
mysql 安装完成之后, 会自动生成一个随机的密码, 并且保存在一个密码文件中 : /root/.mysql_secret
mysql -u root -p
登录之后, 修改密码 :
set password = password('cqm');
授权远程访问 :
grant all privileges on *.* to 'root' @'%' identified by 'cqm';
flush privileges;
2 索引
2.1 索引概述
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获
取数据的数据结构(有序)。在数据之外,数据库系统还维护者满
足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)
数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构
就是索引。如下面示意图所示 :
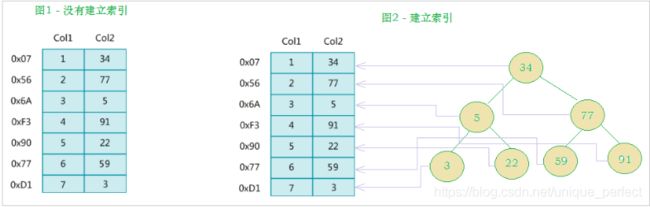
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地
址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。
为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个
节点分别包含索引键值和一个指向对应数据记录物理地址的指针,
这样就可以运用二叉查找快速获取到相应数据。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引
往往以索引文件的形式存储在磁盘上。索引是数据库中用来提高性
能的最常用的工具。
2.2 索引优势劣势
优势
1) 类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
2) 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
劣势
1) 实际上索引也是一张表,该表中保存了主键与索引字段,并
指向实体类的记录,所以索引列也是要占用空间的。
2) 虽然索引大大提高了查询效率,同时却也降低更新表的速度,
如对表进行INSERT、UPDATE、DELETE。因为更新表时,
MySQL 不仅要保存数据,还要保存一下索引文件每次更新添
加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
2.3 索引结构
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的。
所以每种存储引擎的索引都不一定完全相同,也不是所有的存储
引擎都支持所有的索引类型的。MySQL目前提供了以下4种索引:
- BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
- HASH 索引:只有Memory引擎支持 , 使用场景简单 。
- R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,
主要用于地理空间数据类型,通常使用较少,不做特别介绍。
- Full-text (全文索引) :全文索引也是MyISAM的一个特殊索引类型,
主要用于全文索引,InnoDB从Mysql5.6版本开始支持全文索引。
MyISAM、InnoDB、Memory三种存储引擎对各种索引类型的支持
| 索引 | InnoDB引擎 | MyISAM引擎 | Memory引擎 |
|---|---|---|---|
| BTREE索引 | 支持 | 支持 | 支持 |
| HASH 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不
一定是二叉的)结构组织的索引。其中聚集索引、复合索引、前缀索引、
唯一索引默认都是使用 B+tree 索引,统称为 索引。
2.3.1 BTREE 结构
BTree又叫多路平衡搜索树,一颗m叉的BTree特性如下:
- 树中每个节点最多包含m个孩子。
- 除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子。
- 若根节点不是叶子节点,则至少有两个孩子。
- 所有的叶子节点都在同一层。
- 每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
以5叉BTree为例,key的数量:公式推导[ceil(m/2)-1] <= n <= m-1。所以 2 <= n <=4 。
当n>4时,中间节点分裂到父节点,两边节点分裂。
插入 C N G A H E K Q M F W L T Z D P R X Y S 数据为例。
演变过程如下:
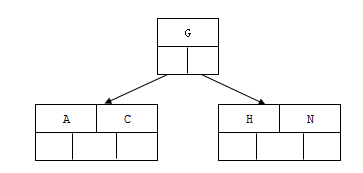
1) 插入前4个字母 C N G A

2) 插入H,n>4,中间元素G字母向上分裂到新的节点
3) 插入E,K,Q不需要分裂

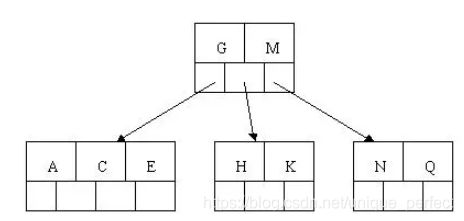
4) 插入M,中间元素M字母向上分裂到父节点G
5) 插入F,W,L,T不需要分裂
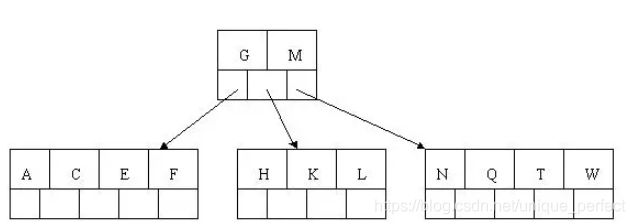
6) 插入Z,中间元素T向上分裂到父节点中

7) 插入D,中间元素D向上分裂到父节点中。然后插入P,R,X,Y不需要分裂

8) 最后插入S,NPQR节点n>5,中间节点Q向上分裂,但分裂后父
节点DGMT的n>5,中间节点M向上分裂

到此,该BTREE树就已经构建完成了, BTREE树 和 二叉树 相比,
查询数据的效率更高, 因为对于相同的数据量来说,BTREE的层级
结构比二叉树小,因此搜索速度快。
2.3.2 B+TREE 结构
B+Tree为BTree的变种,B+Tree与BTree的区别为:
1) n叉B+Tree最多含有n个key,而BTree最多含有n-1个key。
2) B+Tree的叶子节点保存所有的key信息,依key大小顺序排列。
3) 所有的非叶子节点都可以看作是key的索引部分。

由于B+Tree只有叶子节点保存key信息,查询任何key都要从root走
到叶子。所以B+Tree的查询效率更加稳定。
2.3.3 MySQL中的B+Tree
MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基
础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序
指针的B+Tree,提高区间访问的性能。
MySQL中的 B+Tree 索引结构示意图:

2.4 索引分类
1) 单值索引 :即一个索引只包含单个列,一个表可以有多个单列索引
2) 唯一索引 :索引列的值必须唯一,但允许有空值
3) 复合索引 :即一个索引包含多个列
2.5 索引语法
索引在创建表的时候,可以同时创建, 也可以随时增加新的索引。
准备环境:
create database demo_01 default charset=utf8mb4;
use demo_01;
CREATE TABLE `city` (
`city_id` int(11) NOT NULL AUTO_INCREMENT,
`city_name` varchar(50) NOT NULL,
`country_id` int(11) NOT NULL,
PRIMARY KEY (`city_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`country_name` varchar(100) NOT NULL,
PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'西安',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2);
insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'北京',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'上海',1);
insert into `country` (`country_id`, `country_name`) values(1,'China');
insert into `country` (`country_id`, `country_name`) values(2,'America');
insert into `country` (`country_id`, `country_name`) values(3,'Japan');
insert into `country` (`country_id`, `country_name`) values(4,'UK');
2.5.1 创建索引
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
示例 : 为city表中的city_name字段创建索引 ;
![]()
2.5.2 查看索引
show index from table_name;
示例:查看city表中的索引信息;
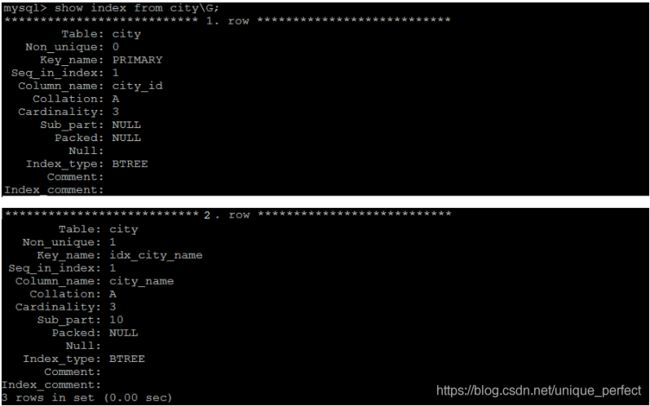
2.5.3 删除索引
DROP INDEX index_name ON tbl_name;
示例 : 想要删除city表上的索引idx_city_name,可以操作如下:
![]()
2.5.4 ALTER命令
1) alter table tb_name add primary key(column_list);
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
2) alter table tb_name add unique index_name(column_list);
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
3 alter table tb_name add index index_name(column_list);
添加普通索引, 索引值可以出现多次。
4) alter table tb_name add fulltext index_name(column_list);
该语句指定了索引为FULLTEXT, 用于全文索引
2.6 索引设计原则
索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符
合这些原则,便于提升索引的使用效率,更高效的使用索引。
- 对查询频次较高,且数据量比较大的表建立索引。
- 索引字段的选择,最佳候选列应当从where子句的条件中提取,
如果where子句中的组合比较多,那么应当挑选最常用、过滤效果
最好的列的组合。
- 使用唯一索引,区分度越高,使用索引的效率越高。
- 索引可以有效的提升查询数据的效率,但索引数量不是多多益善,索
引越多,维护索引的代价自然也就水涨船高。对于插入、更新、删除
等DML操作比较频繁的表来说,索引过多,会引入相当高的维护代价,
降低DML操作的效率,增加相应操作的时间消耗。另外索引过多的
话,MySQL也会犯选择困难病,虽然最终仍然会找到一个可用的索
引,但无疑提高了选择的代价。
- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引
访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段
总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,
相应的可以有效的提升MySQL访问索引的I/O效率。
- 利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N
个索引,如果查询时where子句中使用了组成该索引的前几个字段,
那么这条查询SQL可以利用组合索引来提升查询效率。
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS);
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;
3 视图
3.1 视图概述
视图(View)是一种虚拟存在的表。视图并不在数据库中实际存在,
行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动
态生成的。通俗的讲,视图就是一条SELECT语句执行后返回的结果集。
所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
视图相对于普通的表的优势主要包括以下几项。
- 简单:使用视图的用户完全不需要关心后面对应的表的结构、关联
条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集。
- 安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权
限管理并不能限制到某个行某个列,但是通过视图就可以简单的实现。
- 数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,
源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来
解决,不会造成对访问者的影响。
3.2 创建或者修改视图
创建视图的语法为:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
修改视图的语法为:
ALTER [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
选项 :
WITH [CASCADED | LOCAL] CHECK OPTION 决定了是否允许更新数据使记录不再满足视图的条件。
LOCAL : 只要满足本视图的条件就可以更新。
CASCADED : 必须满足所有针对该视图的所有视图的条件才可以更新。 默认值.
示例 , 创建city_country_view视图 , 执行如下SQL :
create or replace view city_country_view as
select t.*,c.country_name from country c , city t where c.country_id = t.country_id;
查询视图 :

3.3 查看视图
从 MySQL 5.1 版本开始,使用 SHOW TABLES 命令的时候不
仅显示表的名字,同时也会显示视图的名字,而不存在单独显示
视图的 SHOW VIEWS 命令。

同样,在使用 SHOW TABLE STATUS 命令的时候,不但可以显示
表的信息,同时也可以显示视图的信息。
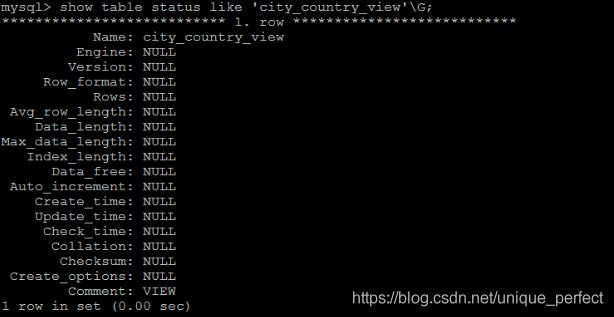
如果需要查询某个视图的定义,可以使用 SHOW CREATE VIEW 命令进
行查看 :

3.4 删除视图
DROP VIEW [IF EXISTS] view_name [, view_name] ...[RESTRICT | CASCADE]
示例 , 删除视图city_country_view :
DROP VIEW city_country_view ;
4 存储过程和函数
4.1 存储过程和函数概述
存储过程和函数是 事先经过编译并存储在数据库中的一段 SQL 语
句的集合,调用存储过程和函数可以简化应用开发人员的很多工
作,减少数据在数据库和应用服务器之间的传输,对于提高数
据处理的效率是有好处的。
存储过程和函数的区别在于函数必须有返回值,而存储过程没有。
函数 : 是一个有返回值的过程 ;
过程 : 是一个没有返回值的函数 ;
4.2 创建存储过程
CREATE PROCEDURE procedure_name ([proc_parameter[,...]])
begin
-- SQL语句
end ;
示例 :
delimiter $
create procedure pro_test1()
begin
select 'Hello Mysql' ;
end$
delimiter ;
DELIMITER
该关键字用来声明SQL语句的分隔符 , 告诉 MySQL 解释器,该段
命令是否已经结束了,mysql是否可以执行了。默认情况下,
delimiter是分号;。在命令行客户端中,如果有一行命令以分
号结束,那么回车后,mysql将会执行该命令。
4.3 调用存储过程
call procedure_name() ;
4.4 查看存储过程
-- 查询db_name数据库中的所有的存储过程
select name from mysql.proc where db='db_name';
-- 查询存储过程的状态信息
show procedure status;
-- 查询某个存储过程的定义
show create procedure test.pro_test1 \G;
4.5 删除存储过程
DROP PROCEDURE [IF EXISTS] sp_name ;
4.6 语法
存储过程是可以编程的,意味着可以使用变量,表达式,控制结构 ,
来完成比较复杂的功能。
4.6.1 变量
- DECLARE
通过 DECLARE 可以定义一个局部变量,该变量的作用范围
只能在 BEGIN…END 块中。
DECLARE var_name[,...] type [DEFAULT value]
delimiter $
create procedure pro_test2()
begin
declare num int default 5;
select num+ 10;
end$
delimiter ;
- SET
直接赋值使用 SET,可以赋常量或者赋表达式,具体语法如下:
SET var_name = expr [, var_name = expr] ...
DELIMITER $
CREATE PROCEDURE pro_test3()
BEGIN
DECLARE NAME VARCHAR(20);
SET NAME = 'MYSQL';
SELECT NAME ;
END$
DELIMITER ;
也可以通过select ... into 方式进行赋值操作 :
DELIMITER $
CREATE PROCEDURE pro_test5()
BEGIN
declare countnum int;
select count(*) into countnum from city;
select countnum;
END$
DELIMITER ;
4.6.2 if条件判断
语法结构 :
if search_condition then statement_list
[elseif search_condition then statement_list] ...
[else statement_list]
end if;
需求:
根据定义的身高变量,判定当前身高的所属的身材类型
180 及以上 ----------> 身材高挑
170 - 180 ---------> 标准身材
170 以下 ----------> 一般身材
delimiter $
create procedure pro_test6()
begin
declare height int default 175;
declare description varchar(50);
if height >= 180 then
set description = '身材高挑';
elseif height >= 170 and height < 180 then
set description = '标准身材';
else
set description = '一般身材';
end if;
select description ;
end$
delimiter ;
调用结果为 :

4.6.3 传递参数
语法格式 :
create procedure procedure_name([in/out/inout] 参数名 参数类型)
...
IN : 该参数可以作为输入,也就是需要调用方传入值 , 默认
OUT: 该参数作为输出,也就是该参数可以作为返回值
INOUT: 既可以作为输入参数,也可以作为输出参数
IN - 输入
需求 :
根据定义的身高变量,判定当前身高的所属的身材类型
delimiter $
create procedure pro_test5(in height int)
begin
declare description varchar(50) default '';
if height >= 180 then
set description='身材高挑';
elseif height >= 170 and height < 180 then
set description='标准身材';
else
set description='一般身材';
end if;
select concat('身高 ', height , '对应的身材类型为:',description);
end$
delimiter ;
OUT-输出
需求 :
根据传入的身高变量,获取当前身高的所属的身材类型
create procedure pro_test5(in height int , out description varchar(100))
begin
if height >= 180 then
set description='身材高挑';
elseif height >= 170 and height < 180 then
set description='标准身材';
else
set description='一般身材';
end if;
end$
调用:
call pro_test5(168, @description)$
select @description$
@description : 这种变量要在变量名称前面加上“@”符号,叫做用户会话变量,代表整个会话过程他都是有作用的,这个类似于全局变量一样。
@@global.sort_buffer_size : 这种在变量前加上 "@@" 符号, 叫做 系统变量
4.6.4 case结构
语法结构 :
方式一 :
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE;
方式二 :
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE;
需求:
给定一个月份, 然后计算出所在的季度
delimiter $
create procedure pro_test9(month int)
begin
declare result varchar(20);
case
when month >= 1 and month <=3 then
set result = '第一季度';
when month >= 4 and month <=6 then
set result = '第二季度';
when month >= 7 and month <=9 then
set result = '第三季度';
when month >= 10 and month <=12 then
set result = '第四季度';
end case;
select concat('您输入的月份为 :', month , ' , 该月份为 : ' , result) as content ;
end$
delimiter ;
4.6.5 while循环
while search_condition do
statement_list
end while;
需求:
计算从1加到n的值
delimiter $
create procedure pro_test8(n int)
begin
declare total int default 0;
declare num int default 1;
while num<=n do
set total = total + num;
set num = num + 1;
end while;
select total;
end$
delimiter ;
4.6.6 repeat结构
有条件的循环控制语句, 当满足条件的时候退出循环 。while 是满足条件才执行,repeat 是满足条件就退出循环。
语法结构 :
REPEAT
statement_list
UNTIL search_condition
END REPEAT;
需求:
计算从1加到n的值
delimiter $
create procedure pro_test10(n int)
begin
declare total int default 0;
repeat
set total = total + n;
set n = n - 1;
until n=0
end repeat;
select total ;
end$
delimiter ;
4.6.7 loop语句
LOOP 实现简单的循环,退出循环的条件需要使用其他的语句定义,
通常可以使用 LEAVE 语句实现,具体语法如下:
[begin_label:] LOOP
statement_list
END LOOP [end_label]
如果不在 statement_list 中增加退出循环的语句,那么 LOOP 语句
可以用来实现简单的死循环。
4.6.8 leave语句
用来从标注的流程构造中退出,通常和 BEGIN ... END 或者
循环一起使用。下面是一个使用 LOOP 和 LEAVE 的简单例子 ,
退出循环:
delimiter $
CREATE PROCEDURE pro_test11(n int)
BEGIN
declare total int default 0;
ins: LOOP
IF n <= 0 then
leave ins;
END IF;
set total = total + n;
set n = n - 1;
END LOOP ins;
select total;
END$
delimiter ;
4.6.9 游标/光标
游标是用来存储查询结果集的数据类型 , 在存储过程和函数中可以
使用光标对结果集进行循环的处理。光标的使用包括光标的声
明、OPEN、FETCH 和 CLOSE,其语法分别如下。
声明光标:
DECLARE cursor_name CURSOR FOR select_statement ;
OPEN 光标:
OPEN cursor_name ;
FETCH 光标:
FETCH cursor_name INTO var_name [, var_name] ...
CLOSE 光标:
CLOSE cursor_name ;
初始化脚本:
create table emp(
id int(11) not null auto_increment ,
name varchar(50) not null comment '姓名',
age int(11) comment '年龄',
salary int(11) comment '薪水',
primary key(`id`)
)engine=innodb default charset=utf8 ;
insert into emp(id,name,age,salary) values(null,'金毛狮王',55,3800),(null,'白眉鹰王',60,4000),(null,'青翼蝠王',38,2800),(null,'紫衫龙王',42,1800);
-- 查询emp表中数据, 并逐行获取进行展示
create procedure pro_test11()
begin
declare e_id int(11);
declare e_name varchar(50);
declare e_age int(11);
declare e_salary int(11);
declare emp_result cursor for select * from emp;
open emp_result;
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
close emp_result;
end$
通过循环结构 , 获取游标中的数据 :
DELIMITER $
create procedure pro_test12()
begin
DECLARE id int(11);
DECLARE name varchar(50);
DECLARE age int(11);
DECLARE salary int(11);
DECLARE has_data int default 1;
DECLARE emp_result CURSOR FOR select * from emp;
DECLARE EXIT HANDLER FOR NOT FOUND set has_data = 0;
open emp_result;
repeat
fetch emp_result into id , name , age , salary;
select concat('id为',id, ', name 为' ,name , ', age为 ' ,age , ', 薪水为: ', salary);
until has_data = 0
end repeat;
close emp_result;
end$
DELIMITER ;
4.7 存储函数
CREATE FUNCTION function_name([param type ... ])
RETURNS type
BEGIN
...
END;
案例 :
定义一个存储过程, 请求满足条件的总记录数 ;
delimiter $
create function count_city(countryId int)
returns int
begin
declare cnum int ;
select count(*) into cnum from city where country_id = countryId;
return cnum;
end$
delimiter ;
调用:
select count_city(1);
select count_city(2);
5 触发器
5.1 介绍
触发器是与表有关的数据库对象,指在 insert/update/delete 之前或
之后,触发并执行触发器中定义的SQL语句集合。触发器的这种特
性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据
校验等操作 。
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与
其他的数据库是相似的。现在触发器还只支持行级触发,不支持
语句级触发。
| 触发器类型 | NEW 和 OLD的使用 |
|---|---|
| INSERT 型触发器 | NEW 表示将要或者已经新增的数据 |
| UPDATE 型触发器 | OLD 表示修改之前的数据 , NEW 表示将要或已经修改后的数据 |
| DELETE 型触发器 | OLD 表示将要或者已经删除的数据 |
5.2 创建触发器
create trigger trigger_name
before/after insert/update/delete
on tbl_name
[ for each row ] -- 行级触发器
begin
trigger_stmt ;
end;
需求
通过触发器记录 emp 表的数据变更日志 , 包含增加, 修改 , 删除 ;
首先创建一张日志表 :
create table emp_logs(
id int(11) not null auto_increment,
operation varchar(20) not null comment '操作类型, insert/update/delete',
operate_time datetime not null comment '操作时间',
operate_id int(11) not null comment '操作表的ID',
operate_params varchar(500) comment '操作参数',
primary key(`id`)
)engine=innodb default charset=utf8;
创建 insert 型触发器,完成插入数据时的日志记录 :
DELIMITER $
create trigger emp_logs_insert_trigger
after insert
on emp
for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values(null,'insert',now(),new.id,concat('插入后(id:',new.id,', name:',new.name,', age:',new.age,', salary:',new.salary,')'));
end $
DELIMITER ;
创建 update 型触发器,完成更新数据时的日志记录 :
DELIMITER $
create trigger emp_logs_update_trigger
after update
on emp
for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values(null,'update',now(),new.id,concat('修改前(id:',old.id,', name:',old.name,', age:',old.age,', salary:',old.salary,') , 修改后(id',new.id, 'name:',new.name,', age:',new.age,', salary:',new.salary,')'));
end $
DELIMITER ;
创建delete 行的触发器 , 完成删除数据时的日志记录 :
DELIMITER $
create trigger emp_logs_delete_trigger
after delete
on emp
for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values(null,'delete',now(),old.id,concat('删除前(id:',old.id,', name:',old.name,', age:',old.age,', salary:',old.salary,')'));
end $
DELIMITER ;
测试:
insert into emp(id,name,age,salary) values(null, '光明左使',30,3500);
insert into emp(id,name,age,salary) values(null, '光明右使',33,3200);
update emp set age = 39 where id = 3;
delete from emp where id = 5;
5.3 删除触发器
语法结构 :
drop trigger [schema_name.]trigger_name
如果没有指定 schema_name,默认为当前数据库 。
5.4 查看触发器
可以通过执行 SHOW TRIGGERS 命令查看触发器的状态、语法
等信息。
语法结构 :
show triggers;
6 Mysql的体系结构概览

整个MySQL Server由以下组成
- Connection Pool : 连接池组件
- Management Services & Utilities : 管理服务和工具组件
- SQL Interface : SQL接口组件
- Parser : 查询分析器组件
- Optimizer : 优化器组件
- Caches & Buffers : 缓冲池组件
- Pluggable Storage Engines : 存储引擎
- File System : 文件系统
1) 连接层
最上层是一些客户端和链接服务,包含本地sock 通信和大多数基于
客户端/服务端工具实现的类似于 TCP/IP的通信。主要完成一些类似
于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池
的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以
实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证
它所具有的操作权限。
2) 服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利用索引等, 最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存,如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
3) 引擎层
存储引擎层, 存储引擎真正的负责了MySQL中数据的存储和提取,服
务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功
能,这样我们可以根据自己的需要,来选取合适的存储引擎。
4)存储层
数据存储层, 主要是将数据存储在文件系统之上,并完成与存储引擎的交互。
和其他数据库相比,MySQL有点与众不同,它的架构可以在多
种不同场景中应用并发挥良好作用。主要体现在存储引擎上,插
件式的存储引擎架构,将查询处理和其他的系统任务以及数据的
存储提取分离。这种架构可以根据业务的需求和实际需要选
择合适的存储引擎。
7 存储引擎
7.1 存储引擎概述
和大多数的数据库不同, MySQL中有一个存储引擎的概念, 针对不同
的存储需求可以选择最优的存储引擎。
存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式 。
存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型。
Oracle,SqlServer等数据库只有一种存储引擎。MySQL提供了插件
式的存储引擎架构。所以MySQL存在多种存储引擎,可以根据需要
使用相应引擎,或者编写存储引擎。
MySQL5.0支持的存储引擎包含 : InnoDB 、MyISAM 、BDB、MEMORY、
MERGE、EXAMPLE、NDB Cluster、ARCHIVE、CSV、
BLACKHOLE、FEDERATED等,其中InnoDB和BDB提供事务安全表,
其他存储引擎是非事务安全表。
可以通过指定 show engines , 来查询当前数据库支持的存储引擎 :

创建新表时如果不指定存储引擎,那么系统就会使用默认的存储引擎,
MySQL5.5之前的默认存储引擎是MyISAM,5.5之后就改为了InnoDB。
查看Mysql数据库默认的存储引擎 , 指令 :
show variables like '%storage_engine%' ;

7.2 各种存储引擎特性
下面重点介绍几种常用的存储引擎, 并对比各个存储引擎之间的区别, 如下表所示 :
| 特点 | InnoDB | MyISAM | MEMORY | MERGE | NDB |
|---|---|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 | 没有 | 有 |
| 事务安全 | 支持 | ||||
| 锁机制 | 行锁(适合高并发) | 表锁 | 表锁 | 表锁 | 行锁 |
| B树索引 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 哈希索引 | 支持 | ||||
| 全文索引 | 支持(5.6版本之后) | 支持 | |||
| 集群索引 | 支持 | ||||
| 数据索引 | 支持 | 支持 | 支持 | ||
| 索引缓存 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 数据可压缩 | 支持 | ||||
| 空间使用 | 高 | 低 | N/A | 低 | 低 |
| 内存使用 | 高 | 低 | 中等 | 低 | 高 |
| 批量插入速度 | 低 | 高 | 高 | 高 | 高 |
| 支持外键 | 支持 |
下面我们将重点介绍最长使用的两种存储引擎: InnoDB、MyISAM ,
另外两种 MEMORY、MERGE , 了解即可。
7.2.1 InnoDB
InnoDB存储引擎是Mysql的默认存储引擎。InnoDB存储引擎提供了具有
提交、回滚、崩溃恢复能力的事务安全。但是对比MyISAM的存储引擎,
InnoDB写的处理效率差一些,并且会占用更多的磁盘空间以保留数据
和索引。
InnoDB存储引擎不同于其他存储引擎的特点 :
事务控制
create table goods_innodb(
id int NOT NULL AUTO_INCREMENT,
name varchar(20) NOT NULL,
primary key(id)
)ENGINE=innodb DEFAULT CHARSET=utf8;
start transaction;
insert into goods_innodb(id,name)values(null,'Meta20');
commit;

测试,发现在InnoDB中是存在事务的;
外键约束
MySQL支持外键的存储引擎只有InnoDB,在创建外键的时候,
要求父表必须有对应的索引 , 子表在创建外键的时候,
也会自动的创建对应的索引。
下面两张表中 , country_innodb是父表 , country_id为主键索引,
city_innodb表是子表,country_id字段为外键,对应于country_innodb
表的主键country_id 。
create table country_innodb(
country_id int NOT NULL AUTO_INCREMENT,
country_name varchar(100) NOT NULL,
primary key(country_id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
create table city_innodb(
city_id int NOT NULL AUTO_INCREMENT,
city_name varchar(50) NOT NULL,
country_id int NOT NULL,
primary key(city_id),
key idx_fk_country_id(country_id),
CONSTRAINT `fk_city_country` FOREIGN KEY(country_id) REFERENCES country_innodb(country_id) ON DELETE RESTRICT ON UPDATE CASCADE
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into country_innodb values(null,'China'),(null,'America'),(null,'Japan');
insert into city_innodb values(null,'Xian',1),(null,'NewYork',2),(null,'BeiJing',1);
在创建索引时, 可以指定在删除、更新父表时,对子表进行的相应操作,
包括 RESTRICT、CASCADE、SET NULL 和 NO ACTION。
RESTRICT和NO ACTION相同, 是指限制在子表有关联记录的情况下,
父表不能更新;
CASCADE表示父表在更新或者删除时,更新或者删除子表对应的记录;
SET NULL 则表示父表在更新或者删除的时候,子表的对应字段
被SET NULL 。
针对上面创建的两个表, 子表的外键指定是ON DELETE RESTRICT
ON UPDATE CASCADE 方式的, 那么在主表删除记录的时候, 如果子表
有对应记录, 则不允许删除, 主表在更新记录的时候, 如果子表有
对应记录, 则子表对应更新 。
表中数据如下图所示 :

外键信息可以使用如下两种方式查看 :
show create table city_innodb;

删除country_id为1 的country数据:
delete from country_innodb where country_id = 1;
更新主表country表的字段 country_id :
update country_innodb set country_id = 100 where country_id = 1;
![]()
更新后, 子表的数据信息为 :

存储方式
InnoDB 存储表和索引有以下两种方式 :
1 使用共享表空间存储, 这种方式创建的表的表结构保存在.frm文件中,
数据和索引保存在 innodb_data_home_dir 和 innodb_data_file_path定
义的表空间中,可以是多个文件。
2 使用多表空间存储, 这种方式创建的表的表结构仍然存在 .frm 文件中,
但是每个表的数据和索引单独保存在 .ibd 中。
![]()
7.2.2 MyISAM
MyISAM 不支持事务、也不支持外键,其优势是访问的速度快,对事
务的完整性没有要求或者以SELECT、INSERT为主的应用基本上都可以
使用这个引擎来创建表 。有以下两个比较重要的特点:
不支持事务
create table goods_myisam(
id int NOT NULL AUTO_INCREMENT,
name varchar(20) NOT NULL,
primary key(id)
)ENGINE=myisam DEFAULT CHARSET=utf8;

通过测试,我们发现,在MyISAM存储引擎中,是没有事务控制的 ;
文件存储方式
每个MyISAM在磁盘上存储成3个文件,其文件名都和表名相同,但拓展名
分别是 :
.frm (存储表定义);
.MYD(MYData , 存储数据);
.MYI(MYIndex , 存储索引);
![]()
7.2.3 MEMORY
Memory存储引擎将表的数据存放在内存中。每个MEMORY表实际
对应一个磁盘文件,格式是.frm ,该文件中只存储表的结构,而其数
据文件,都是存储在内存中,这样有利于数据的快速处理,提高整个
表的效率。MEMORY 类型的表访问非常地快,因为他的数据是存放
在内存中的,并且默认使用HASH索引 , 但是服务一旦关闭,表中的数
据就会丢失。
7.2.4 MERGE
MERGE存储引擎是一组MyISAM表的组合,这些MyISAM表必须结
构完全相同,MERGE表本身并没有存储数据,对MERGE类型的表可
以进行查询、更新、删除操作,这些操作实际上是对内部的MyISAM表进行的。
对于MERGE类型表的插入操作,是通过INSERT_METHOD子句定义插
入的表,可以有3个不同的值,使用FIRST 或 LAST 值使得插入操作被相
应地作用在第一或者最后一个表上,不定义这个子句或者定义为NO,表示
不能对这个MERGE表执行插入操作。
可以对MERGE表进行DROP操作,但是这个操作只是删除MERGE表的
定义,对内部的表是没有任何影响的。

下面是一个创建和使用MERGE表的示例 :
1). 创建3个测试表 order_1990, order_1991, order_all , 其中order_all是前两个表的MERGE表 :
create table order_1990(
order_id int ,
order_money double(10,2),
order_address varchar(50),
primary key (order_id)
)engine = myisam default charset=utf8;
create table order_1991(
order_id int ,
order_money double(10,2),
order_address varchar(50),
primary key (order_id)
)engine = myisam default charset=utf8;
create table order_all(
order_id int ,
order_money double(10,2),
order_address varchar(50),
primary key (order_id)
)engine = merge union = (order_1990,order_1991) INSERT_METHOD=LAST default charset=utf8;
2)分别向两张表中插入记录
insert into order_1990 values(1,100.0,'北京');
insert into order_1990 values(2,100.0,'上海');
insert into order_1991 values(10,200.0,'北京');
insert into order_1991 values(11,200.0,'上海');
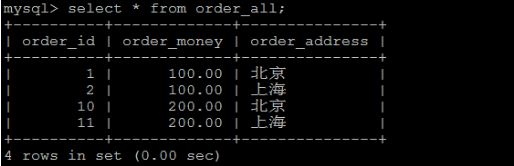
3)查询3张表中的数据。
order_1990中的数据 :
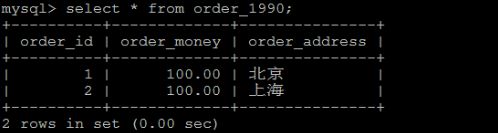
order_1991中的数据 :
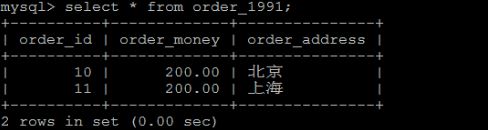
order_all中的数据
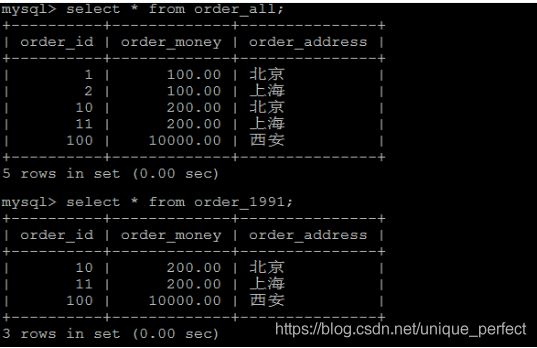
4). 往order_all中插入一条记录 ,由于在MERGE表定义时,INSERT_METHOD 选择的是LAST,那么插入的数据会想最后一张表中插入。
insert into order_all values(100,10000.0,'西安');
7.3 存储引擎的选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。
对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
以下是几种常用的存储引擎的使用环境。
- InnoDB : 是Mysql的默认存储引擎,用于事务处理应用程序,支持
外键。如果应用对事务的完整性有比较高的要求,在并发条件下要
求数据的一致性,数据操作除了插入和查询意外,还包含很多的更
新、删除操作,那么InnoDB存储引擎是比较合适的选择。InnoDB存
储引擎除了有效的降低由于删除和更新导致的锁定, 还可以确保事
务的完整提交和回滚,对于类似于计费系统或者财务系统等对数据
准确性要求比较高的系统,InnoDB是最合适的选择。
- MyISAM : 如果应用是以读操作和插入操作为主,只有很少的更新和
删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个
存储引擎是非常合适的。
- MEMORY:将所有数据保存在RAM中,在需要快速定位记录和其他
类似数据环境下,可以提供几块的访问。MEMORY的缺陷就是对表的
大小有限制,太大的表无法缓存在内存中,其次是要确保表的数据可
以恢复,数据库异常终止后表中的数据是可以恢复的。MEMORY表通
常用于更新不太频繁的小表,用以快速得到访问结果。
- MERGE:用于将一系列等同的MyISAM表以逻辑方式组合在一起,
并作为一个对象引用他们。MERGE表的优点在于可以突破对单个
MyISAM表的大小限制,并且通过将不同的表分布在多个磁盘上,
可以有效的改善MERGE表的访问效率。这对于存储诸如数据仓
储等VLDB环境十分合适。
8 优化SQL步骤
在应用的的开发过程中,由于初期数据量小,开发人员写 SQL 语句
时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量
的急剧增长,很多 SQL 语句开始逐渐显露出性能问题,对生产的
影响也越来越大,此时这些有问题的 SQL 语句就成为整个系统性能的
瓶颈,因此我们必须要对它们进行优化,本章将详细介绍在 MySQL
中优化 SQL 语句的方法。
当面对一个有 SQL 性能问题的数据库时,我们应该从何处入手来
进行系统的分析,使得能够尽快定位问题 SQL 并尽快解决问题。
8.1 查看SQL执行频率
MySQL 客户端连接成功后,通过 show [session|global] status
命令可以提供服务器状态信息。show [session|global] status
可以根据需要加上参数“session”或者“global”来显示 session
级(当前连接)的计结果和 global 级(自数据库上次启动至今)
的统计结果。如果不写,默认使用参数是“session”。
下面的命令显示了当前 session 中所有统计参数的值:
show status like 'Com_______';

show status like 'Innodb_rows_%';
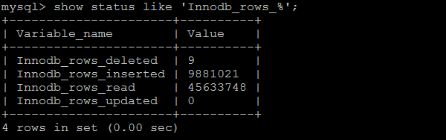
Com_xxx 表示每个 xxx 语句执行的次数,我们通常比较关心的是以下
几个统计参数。
| 参数 | 含义 |
|---|---|
| Com_select | 执行 select 操作的次数,一次查询只累加 1。 |
| Com_insert | 执行 INSERT 操作的次数,对于批量插入的 INSERT 操作,只累加一次。 |
| Com_update | 执行 UPDATE 操作的次数。 |
| Com_delete | 执行 DELETE 操作的次数。 |
| Innodb_rows_read | select 查询返回的行数。 |
| Innodb_rows_inserted | 执行 INSERT 操作插入的行数。 |
| Innodb_rows_updated | 执行 UPDATE 操作更新的行数。 |
| Innodb_rows_deleted | 执行 DELETE 操作删除的行数。 |
| Connections | 试图连接 MySQL 服务器的次数。 |
| Uptime | 服务器工作时间。 |
| Slow_queries | 慢查询的次数。 |
Com_*** : 这些参数对于所有存储引擎的表操作都会进行累计。
Innodb_*** : 这几个参数只是针对InnoDB 存储引擎的,累加的算法也略有不同。
8.2 定位低效率执行SQL
可以通过以下两种方式定位执行效率较低的 SQL 语句。
- 慢查询日志 : 通过慢查询日志定位那些执行效率较低的 SQL 语句,
用--log-slow-queries[=file_name]选项启动时,mysqld 写一个包含所有
执行时间超过 long_query_time 秒的 SQL 语句的日志文件。具体可
以查看本书第 26 章中日志管理的相关部分。
- show processlist : 慢查询日志在查询结束以后才纪录,所以在应用反
映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使
用show processlist命令查看当前MySQL在进行的线程,包括线程的
状态、是否锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁
表操作进行优化。

1) id列,用户登录mysql时,系统分配的"connection_id",可以使用函数connection_id()查看
2) user列,显示当前用户。如果不是root,这个命令就只显示用户权限范围的sql语句
3) host列,显示这个语句是从哪个ip的哪个端口上发的,可以用来跟踪出现问题语句的用户
4) db列,显示这个进程目前连接的是哪个数据库
5) command列,显示当前连接的执行的命令,一般取值为休眠(sleep),
查询(query),连接(connect)等
6) time列,显示这个状态持续的时间,单位是秒
7) state列,显示使用当前连接的sql语句的状态,很重要的列。state描
述的是语句执行中的某一个状态。一个sql语句,以查询为例,可能需要
经过copying to tmp table、sorting result、sending data等状态才可以完成
8) info列,显示这个sql语句,是判断问题语句的一个重要依据
8.3 explain分析执行计划
通过以上步骤查询到效率低的 SQL 语句后,可以通过 EXPLAIN或
者 DESC命令获取 MySQL如何执行 SELECT 语句的信息,包括在
SELECT 语句执行过程中表如何连接和连接的顺序。
查询SQL语句的执行计划 :
explain select * from tb_item where id = 1;

explain select * from tb_item where title = '阿尔卡特 (OT-979) 冰川白 联通3G手机3';

| 字段 | 含义 |
|---|---|
| id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等 |
| table | 输出结果集的表 |
| type | 表示表的连接类型,性能由好到差的连接类型为( system —> const -----> eq_ref ------> ref -------> ref_or_null----> index_merge —> index_subquery -----> range -----> index ------> all ) |
| possible_keys | 表示查询时,可能使用的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
8.3.1 环境准备
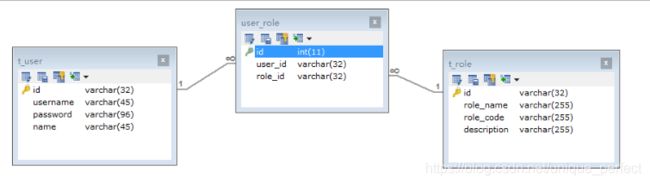
CREATE TABLE `t_role` (
`id` varchar(32) NOT NULL,
`role_name` varchar(255) DEFAULT NULL,
`role_code` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_role_name` (`role_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_user` (
`id` varchar(32) NOT NULL,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_user_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_role` (
`id` int(11) NOT NULL auto_increment ,
`user_id` varchar(32) DEFAULT NULL,
`role_id` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_ur_user_id` (`user_id`),
KEY `fk_ur_role_id` (`role_id`),
CONSTRAINT `fk_ur_role_id` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `fk_ur_user_id` FOREIGN KEY (`user_id`) REFERENCES `t_user` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `t_user` (`id`, `username`, `password`, `name`) values('1','super','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','超级管理员');
insert into `t_user` (`id`, `username`, `password`, `name`) values('2','admin','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','系统管理员');
insert into `t_user` (`id`, `username`, `password`, `name`) values('3','cqm','$2a$10$8qmaHgUFUAmPR5pOuWhYWOr291WJYjHelUlYn07k5ELF8ZCrW0Cui','test02');
insert into `t_user` (`id`, `username`, `password`, `name`) values('4','stu1','$2a$10$pLtt2KDAFpwTWLjNsmTEi.oU1yOZyIn9XkziK/y/spH5rftCpUMZa','学生1');
insert into `t_user` (`id`, `username`, `password`, `name`) values('5','stu2','$2a$10$nxPKkYSez7uz2YQYUnwhR.z57km3yqKn3Hr/p1FR6ZKgc18u.Tvqm','学生2');
insert into `t_user` (`id`, `username`, `password`, `name`) values('6','t1','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','老师1');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('5','学生','student','学生');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('7','老师','teacher','老师');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('8','教学管理员','teachmanager','教学管理员');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('9','管理员','admin','管理员');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('10','超级管理员','super','超级管理员');
INSERT INTO user_role(id,user_id,role_id) VALUES(NULL, '1', '5'),(NULL, '1', '7'),(NULL, '2', '8'),(NULL, '3', '9'),(NULL, '4', '8'),(NULL, '5', '10') ;
8.3.2 explain之id
id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句
或者是操作表的顺序。id 情况有三种 :
1) id 相同表示加载表的顺序是从上到下。
explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and u.id = ur.user_id ;

2) id 不同id值越大,优先级越高,越先被执行。
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'))

3) id 有相同,也有不同,同时存在。id相同的可以认为是一组,
从上往下顺序执行;在所有的组中,id的值越大,优先级越高,
越先执行。
EXPLAIN SELECT * FROM t_role r , (SELECT * FROM user_role ur WHERE ur.`user_id` = '2') a WHERE r.id = a.role_id ;

8.3.3 explain之select_type
表示 SELECT 的类型,常见的取值,如下表所示:
| select_type | 含义 |
|---|---|
| SIMPLE | 简单的select查询,查询中不包含子查询或者UNION |
| PRIMARY | 查询中若包含任何复杂的子查询,最外层查询标记为该标识 |
| SUBQUERY | 在SELECT 或 WHERE 列表中包含了子查询 |
| DERIVED | 在FROM 列表中包含的子查询,被标记为 DERIVED(衍生) MYSQL会递归执行这些子查询,把结果放在临时表中 |
| UNION | 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED |
| UNION RESULT | 从UNION表获取结果的SELECT |
8.3.4 explain之table
展示这一行的数据是关于哪一张表的
8.3.5 explain之type
type 显示的是访问类型,是较为重要的一个指标,可取值为:
| type | 含义 |
|---|---|
| NULL | MySQL不访问任何表,索引,直接返回结果 |
| system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 |
| const | 表示通过索引一次就找到了,const 用于比较primary key 或者 unique 索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常亮。const于将 “主键” 或 “唯一” 索引的所有部分与常量值进行比较 |
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 |
| ref | 非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) |
| range | 只检索给定返回的行,使用一个索引来选择行。 where 之后出现 between , < , > , in 等操作。 |
| index | index 与 ALL的区别为 index 类型只是遍历了索引树, 通常比ALL 快, ALL 是遍历数据文件。 |
| all | 将遍历全表以找到匹配的行 |
结果值从最好到最坏以此是:
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system > const > eq_ref > ref > range > index > ALL
一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref 。
8.3.6 explain之 key
possible_keys : 显示可能应用在这张表的索引, 一个或多个。
key : 实际使用的索引, 如果为NULL, 则没有使用索引。
key_len : 表示索引中使用的字节数, 该值为索引字段最大可能长度,
并非实际使用长度,在不损失精确性的前提下, 长度越短越好 。
8.3.7 explain之rows
扫描行的数量。
8.3.8 explain之extra
其他的额外的执行计划信息,在该列展示 。
| extra | 含义 |
|---|---|
| using filesort | 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为 “文件排序”, 效率低。 |
| using temporary | 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于 order by 和 group by; 效率低 |
| using index | 表示相应的select操作使用了覆盖索引, 避免访问表的数据行, 效率不错。 |
8.4 show profile分析SQL
Mysql从5.0.37版本开始增加了对 show profiles 和 show profile 语句
的支持。show profiles 能够在做SQL优化时帮助我们了解时间都耗
费到哪里去了。
通过 have_profiling 参数,能够看到当前MySQL是否支持profile:

默认profiling是关闭的,可以通过set语句在Session级别开启profiling:
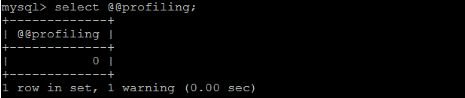
set profiling=1; //开启profiling 开关;
通过profile,我们能够更清楚地了解SQL执行的过程。
首先,我们可以执行一系列的操作,如下图所示:
show databases;
use db01;
show tables;
select * from tb_item where id < 5;
select count(*) from tb_item;
执行完上述命令之后,再执行show profiles 指令,来查看SQL语句执行的耗时:
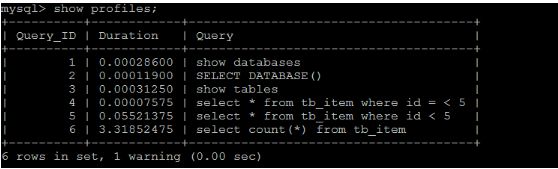
通过show profile for query query_id 语句可以查看到该SQL执行
过程中每个线程的状态和消耗的时间:
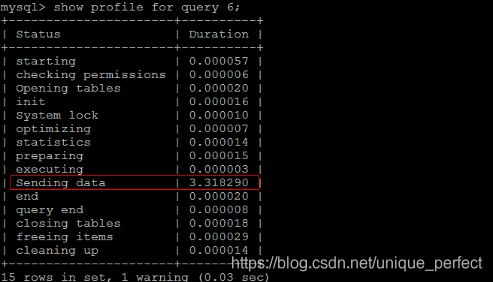
TIP :
Sending data 状态表示MySQL线程开始访问数据行并把结果
返回给客户端,而不仅仅是返回个客户端。由于在Sending data状
态下,MySQL线程往往需要做大量的磁盘读取操作,所以经常是整各
查询中耗时最长的状态。
在获取到最消耗时间的线程状态后,MySQL支持进一步选择all、cpu、
block io 、context switch、page faults等明细类型类查看MyS
QL在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间 :
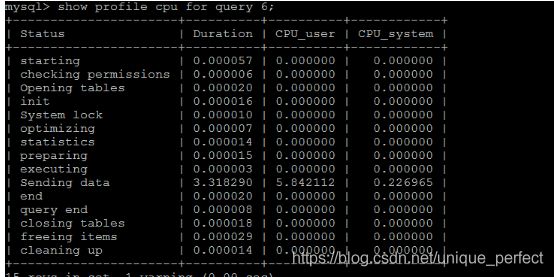
| 字段 | 含义 |
|---|---|
| Status | sql 语句执行的状态 |
| Duration | sql 执行过程中每一个步骤的耗时 |
| CPU_user | 当前用户占有的cpu |
| CPU_system | 系统占有的cpu |
8.5 trace分析优化器执行计划
MySQL5.6提供了对SQL的跟踪trace, 通过trace文件能够进一步了解为
什么优化器选择A计划, 而不是选择B计划。
打开trace , 设置格式为 JSON,并设置trace最大能够使用的内存大小,
避免解析过程中因为默认内存过小而不能够完整展示。
SET optimizer_trace="enabled=on",end_markers_in_json=on;
set optimizer_trace_max_mem_size=1000000;
执行SQL语句 :
select * from tb_item where id < 4;
最后, 检查information_schema.optimizer_trace就可以知道MySQL是如何执行SQL的 :
select * from information_schema.optimizer_trace\G;
*************************** 1. row ***************************
QUERY: select * from tb_item where id < 4
TRACE: {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `tb_item`.`id` AS `id`,`tb_item`.`title` AS `title`,`tb_item`.`price` AS `price`,`tb_item`.`num` AS `num`,`tb_item`.`categoryid` AS `categoryid`,`tb_item`.`status` AS `status`,`tb_item`.`sellerid` AS `sellerid`,`tb_item`.`createtime` AS `createtime`,`tb_item`.`updatetime` AS `updatetime` from `tb_item` where (`tb_item`.`id` < 4)"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "(`tb_item`.`id` < 4)",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`tb_item`.`id` < 4)"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`tb_item`.`id` < 4)"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`tb_item`.`id` < 4)"
}
] /* steps */
} /* condition_processing */
},
{
"table_dependencies": [
{
"table": "`tb_item`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [
{
"table": "`tb_item`",
"range_analysis": {
"table_scan": {
"rows": 9816098,
"cost": 2.04e6
} /* table_scan */,
"potential_range_indices": [
{
"index": "PRIMARY",
"usable": true,
"key_parts": [
"id"
] /* key_parts */
}
] /* potential_range_indices */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "PRIMARY",
"ranges": [
"id < 4"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 3,
"cost": 1.6154,
"chosen": true
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */,
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "PRIMARY",
"rows": 3,
"ranges": [
"id < 4"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 3,
"cost_for_plan": 1.6154,
"chosen": true
} /* chosen_range_access_summary */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`tb_item`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "range",
"rows": 3,
"cost": 2.2154,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"cost_for_plan": 2.2154,
"rows_for_plan": 3,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`tb_item`.`id` < 4)",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`tb_item`",
"attached": "(`tb_item`.`id` < 4)"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"refine_plan": [
{
"table": "`tb_item`",
"access_type": "range"
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */
},
{
"join_execution": {
"select#": 1,
"steps": [
] /* steps */
} /* join_execution */
}
] /* steps */
}
9 索引的使用
索引是数据库优化最常用也是最重要的手段之一, 通过索引通常可
以帮助用户解决大多数的MySQL的性能优化问题。
9.1 验证索引提升查询效率
在我们准备的表结构tb_item 中, 一共存储了 300 万记录;
A. 根据ID查询
select * from tb_item where id = 1999\G;
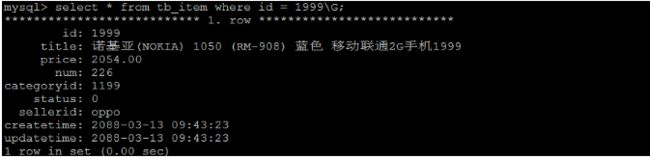
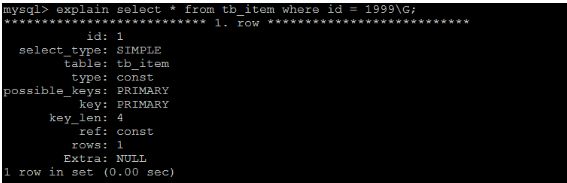
查询速度很快, 接近0s , 主要的原因是因为id为主键,有索引;
2) 根据 title 进行精确查询
select * from tb_item where title = 'iphoneX 移动3G 32G941'\G;
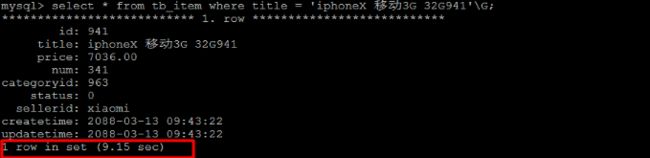
查看SQL语句的执行计划 :

处理方案 , 针对title字段, 创建索引 :
create index idx_item_title on tb_item(title);

索引创建完成之后,再次进行查询 :
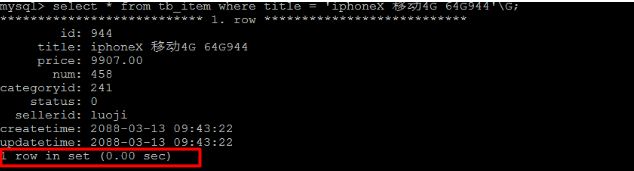
通过explain , 查看执行计划,执行SQL时使用了刚才创建的索引

9.2 索引的使用
9.2.1 准备环境
create table `tb_seller` (
`sellerid` varchar (100),
`name` varchar (100),
`nickname` varchar (50),
`password` varchar (60),
`status` varchar (1),
`address` varchar (100),
`createtime` datetime,
primary key(`sellerid`)
)engine=innodb default charset=utf8mb4;
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('alibaba','阿里巴巴','阿里小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('baidu','百度科技有限公司','百度小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('huawei','华为科技有限公司','华为小店','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('cqm','传智播客教育科技有限公司','传智播客','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itheima','黑马程序员','黑马程序员','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('luoji','罗技科技有限公司','罗技小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('oppo','OPPO科技有限公司','OPPO官方旗舰店','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('ourpalm','掌趣科技股份有限公司','掌趣小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('qiandu','千度科技','千度小店','e10adc3949ba59abbe56e057f20f883e','2','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('sina','新浪科技有限公司','新浪官方旗舰店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('xiaomi','小米科技','小米官方旗舰店','e10adc3949ba59abbe56e057f20f883e','1','西安市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('yijia','宜家家居','宜家家居旗舰店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
create index idx_seller_name_sta_addr on tb_seller(name,status,address);
9.2.2 避免索引失效
1). 全值匹配 ,对索引中所有列都指定具体值。
改情况下,索引生效,执行效率高。
explain select * from tb_seller where name='小米科技' and status='1' and address='北京市'\G;

2) 最左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列
开始,并且不跳过索引中的列。
匹配最左前缀法则,走索引:

违法最左前缀法则 , 索引失效:
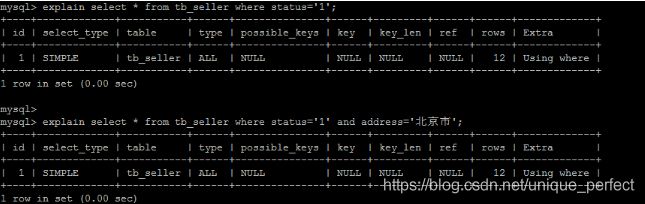
如果符合最左法则,但是出现跳跃某一列,只有最左列索引生效:

3) 范围查询右边的列,不能使用索引 。

根据前面的两个字段name , status 查询是走索引的, 但是
最后一个条件address 没有用到索引。
4) 不要在索引列上进行运算操作, 索引将失效。

5) 字符串不加单引号,造成索引失效

由于,在查询是,没有对字符串加单引号,MySQL的查询优化器,会
自动的进行类型转换,造成索引失效。
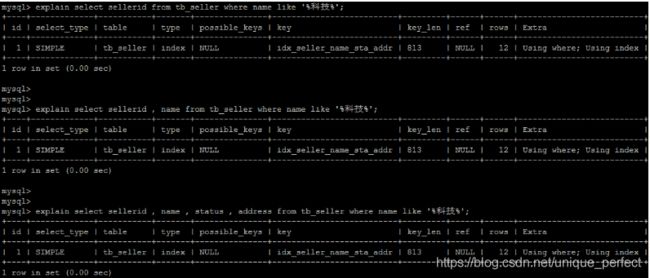
6) 尽量使用覆盖索引,避免select *
尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),
减少select * 。

如果查询列,超出索引列,也会降低性能。

TIP :
using index :使用覆盖索引的时候就会出现
using where:在查找使用索引的情况下,需要回表去查询所需的数据
using index condition:查找使用了索引,但是需要回表查询数据
using index ; using where:查找使用了索引,但是需要的数据都
在索引列中能找到,所以不需要回表查询数据
7) 用or分割开的条件, 如果or前的条件中的列有索引,而后面
的列中没有索引,那么涉及的索引都不会被用到。
示例,name字段是索引列 , 而createtime不是索引列,中间是or进行连接是不走索引的 :
explain select * from tb_seller where name='黑马程序员' or createtime = '2088-01-01 12:00:00'\G;

8) 以%开头的Like模糊查询,索引失效。
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引
失效。

解决方案 :
通过覆盖索引来解决
9) 如果MySQL评估使用索引比全表更慢,则不使用索引。

10) is NULL , is NOT NULL有时索引失效。

11) in 走索引, not in 索引失效。

12) 单列索引和复合索引。
尽量使用复合索引,而少使用单列索引 。
创建复合索引
create index idx_name_sta_address on tb_seller(name, status, address);
就相当于创建了三个索引 :
name
name + status
name + status + address
创建单列索引
create index idx_seller_name on tb_seller(name);
create index idx_seller_status on tb_seller(status);
create index idx_seller_address on tb_seller(address);
数据库会选择一个最优的索引(辨识度最高索引)来使用,并不
会使用全部索引 。
9.3 查看索引使用情况
show status like 'Handler_read%';
show global status like 'Handler_read%';

Handler_read_first:索引中第一条被读的次数。如果较高,表示服
务器正执行大量全索引扫描(这个值越低越好)。
Handler_read_key:如果索引正在工作,这个值代表一个行被索引值
读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经
常使用(这个值越高越好)。
Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约
束或如果执行索引扫描来查询索引列,该值增加。
Handler_read_prev:按照键顺序读前一行的请求数。该读
方法主要用于优化ORDER BY ... DESC。
Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量
查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL
扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味
着运行效率低,应该建立索引来补救。
Handler_read_rnd_next:在数据文件中读下一行的请求数。如果
你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或
写入的查询没有利用索引。
10 SQL优化
10.1 大批量插入数据
环境准备 :
CREATE TABLE `tb_user_1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
`birthday` datetime DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`email` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`qq` varchar(32) DEFAULT NULL,
`status` varchar(32) NOT NULL COMMENT '用户状态',
`create_time` datetime NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_user_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
CREATE TABLE `tb_user_2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
`birthday` datetime DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`email` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`qq` varchar(32) DEFAULT NULL,
`status` varchar(32) NOT NULL COMMENT '用户状态',
`create_time` datetime NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_user_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
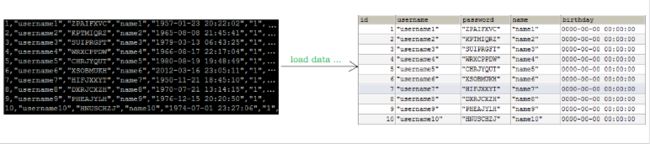
当使用load 命令导入数据的时候,适当的设置可以提高导入的效率。
对于 InnoDB 类型的表,有以下几种方式可以提高导入的效率:
1) 主键顺序插入
因为InnoDB类型的表是按照主键的顺序保存的,所以将导入的数据
按照主键的顺序排列,可以有效的提高导入数据的效率。如果InnoDB表
没有主键,那么系统会自动默认创建一个内部列作为主键,所以如
果可以给表创建一个主键,将可以利用这点,来提高导入数据的效率。
脚本文件介绍 :
sql1.log ----> 主键有序
sql2.log ----> 主键无序
插入ID顺序排列数据:

插入ID无序排列数据:

2) 关闭唯一性校验
在导入数据前执行 SET UNIQUE_CHECKS=0,关闭唯一性校验,在导入
结束后执行SET UNIQUE_CHECKS=1,恢复唯一性校验,可以提高
导入的效率。
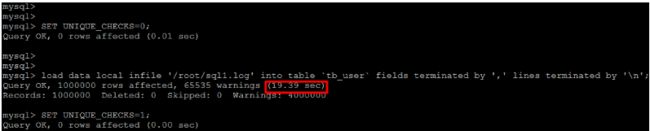
3) 手动提交事务
如果应用使用自动提交的方式,建议在导入前执行 SET AUTOCOMMIT=0,
关闭自动提交,导入结束后再执行 SET AUTOCOMMIT=1,打开自动提交,
也可以提高导入的效率。
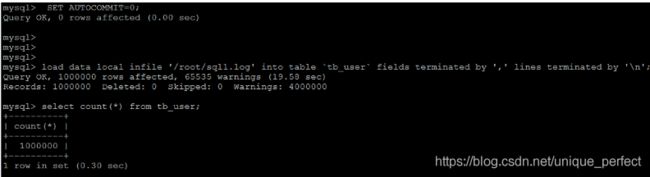
10.2 优化insert语句
当进行数据的insert操作的时候,可以考虑采用以下几种优化方案。
- 如果需要同时对一张表插入很多行数据时,应该尽量使用多个
值表的insert语句,这种方式将大大的缩减客户端与数据库之间
的连接、关闭等消耗。使得效率比分开执行的单个insert语句快。
示例, 原始方式为:
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
优化后的方案为 :
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
在事务中进行数据插入。
start transaction;
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
commit;
数据有序插入
insert into tb_test values(4,'Tim');
insert into tb_test values(1,'Tom');
insert into tb_test values(3,'Jerry');
insert into tb_test values(5,'Rose');
insert into tb_test values(2,'Cat');
优化后
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
insert into tb_test values(4,'Tim');
insert into tb_test values(5,'Rose');
10.3 优化order by语句
10.3.1 环境准备
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(3) NOT NULL,
`salary` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800');
insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200');
insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700');
insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400');
insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100');
insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900');
insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500');
create index idx_emp_age_salary on emp(age,salary);
10.3.2 两种排序方式
1) 第一种是通过对返回数据进行排序,也就是通常说的 filesort 排序,
所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。

2) 第二种通过有序索引顺序扫描直接返回有序数据,这种情况即为
using index,不需要额外排序,操作效率高。

多字段排序

了解了MySQL的排序方式,优化目标就清晰了:尽量减少额外的排序,
通过索引直接返回有序数据。where 条件和Order by 使用相同的索引,
并且Order By 的顺序和索引顺序相同, 并且Order by 的字段都是升
序,或者都是降序。否则肯定需要额外的操作,这样就会出现FileSort。
10.3.3 Filesort的优化
通过创建合适的索引,能够减少 Filesort 的出现,但是在某些情
况下,条件限制不能让Filesort消失,那就需要加快 Filesort的排
序操作。对于Filesort , MySQL 有两种排序算法:
1) 两次扫描算法 :MySQL4.1 之前,使用该方式排序。首先根据条
件取出排序字段和行指针信息,然后在排序区 sort buffer 中排序,
如果sort buffer不够,则在临时表 temporary table 中存储排序结
果。完成排序之后,再根据行指针回表读取记录,该操作可能
会导致大量随机I/O操作。
2)一次扫描算法:一次性取出满足条件的所有字段,然后在排
序区 sort buffer 中排序后直接输出结果集。排序时内存开销较
大,但是排序效率比两次扫描算法要高。
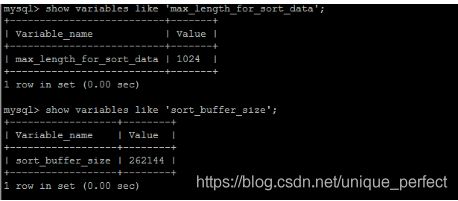
MySQL 通过比较系统变量 max_length_for_sort_data 的大小和
Query语句取出的字段总大小, 来判定是否那种排序算法,如果
max_length_for_sort_data 更大,那么使用第二种优化之后的算
法;否则使用第一种。
可以适当提高sort_buffer_size和max_length_for_sort_data系
统变量,来增大排序区的大小,提高排序的效率。
10.4 优化order by语句
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY
相比,GROUP BY 主要只是多了排序之后的分组操作。当然,如
果在分组的时候还使用了其他的一些聚合函数,那么还需要一些
聚合函数的计算。所以,在GROUP BY 的实现过程中,与 ORDER BY
一样也可以利用到索引。
如果查询包含 group by 但是用户想要避免排序结果的消耗,
则可以执行order by null 禁止排序。如下 :
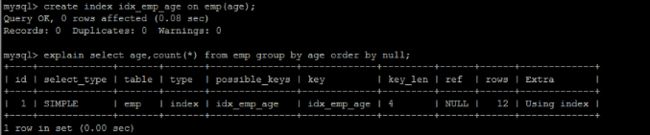
drop index idx_emp_age_salary on emp;
explain select age,count(*) from emp group by age;

优化后
explain select age,count(*) from emp group by age order by null;

从上面的例子可以看出,第一个SQL语句需要进行"filesort",
而第二个SQL由于order by null 不需要进行 "filesort",
而上文提过Filesort往往非常耗费时间。
创建索引 :
create index idx_emp_age_salary on emp(age,salary);
10.5 优化嵌套查询
Mysql4.1版本之后,开始支持SQL的子查询。这个技术可
以使用SELECT语句来创建一个单列的查询结果,然后把
这个结果作为过滤条件用在另一个查询中。使用子查询可
以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操
作,同时也可以避免事务或者表锁死,并且写起来也很
容易。但是,有些情况下,子查询是可以被更高效的连接(JOIN)替代。
示例 ,查找有角色的所有的用户信息 :
explain select * from t_user where id in (select user_id from user_role );
执行计划为 :

优化后 :
explain select * from t_user u , user_role ur where u.id = ur.user_id;

连接(Join)查询之所以更有效率一些 ,是因为MySQL不需要在内存
中创建临时表来完成这个逻辑上需要两个步骤的查询工作。
10.6 优化OR条件
对于包含OR的查询子句,如果要利用索引,则OR之间的每个条件列都
必须用到索引 , 而且不能使用到复合索引; 如果没有索引,则应该考
虑增加索引。
获取 emp 表中的所有的索引 :

示例 :
explain select * from emp where id = 1 or age = 30;


建议使用 union 替换 or :

我们来比较下重要指标,发现主要差别是 type 和 ref 这两项
type 显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
UNION 语句的 type 值为 ref,OR 语句的 type 值为 range,可以看到这是一个很明显的差距
UNION 语句的 ref 值为 const,OR 语句的 type 值为 null,const 表示是常量值引用,非常快
这两项的差距就说明了 UNION 要优于 OR 。
10.7 优化分页查询
一般分页查询时,通过创建覆盖索引能够比较好地提高性能。一个常
见又非常头疼的问题就是 limit 2000000,10 ,此时需要MySQL排序
前2000010 记录,仅仅返回2000000 - 2000010 的记录,其他记录
丢弃,查询排序的代价非常大 。

优化思路一
在索引上完成排序分页操作,最后根据主键关联回原表查询所需
要的其他列内容。

优化思路二
该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询 。

10.8 使用SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL
语句中加入一些人为的提示来达到优化操作的目的。
10.8.1 USE INDEX
在查询语句中表名的后面,添加 use index 来提供希望MySQL
去参考的索引列表,就可以让MySQL不再考虑其他可用的索引。
create index idx_seller_name on tb_seller(name);
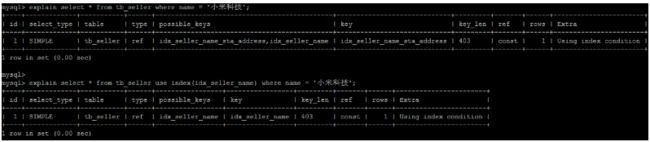
10.8.2 IGNORE INDEX
如果用户只是单纯的想让MySQL忽略一个或者多个索引,则可以
使用 ignore index 作为 hint 。
explain select * from tb_seller ignore index(idx_seller_name) where name = '小米科技';
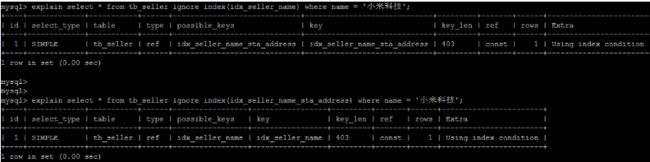
10.8.3 FORCE INDEX
为强制MySQL使用一个特定的索引,可在查询中使用 force index
作为hint 。
create index idx_seller_address on tb_seller(address);

11 应用优化
11.1 应用优化
前面章节,我们介绍了很多数据库的优化措施。但是在实际生产
环境中,由于数据库本身的性能局限,就必须要对前台的应用进
行一些优化,来降低数据库的访问压力。
11.1.1 使用连接池
对于访问数据库来说,建立连接的代价是比较昂贵的,因为我们
频繁的创建关闭连接,是比较耗费资源的,我们有必要建立 数据
库连接池,以提高访问的性能。
11.1.2 减少对MySQL的访问
11.1.2.1 避免对数据进行重复检索
在编写应用代码时,需要能够理清对数据库的访问逻辑。能够一次
连接就获取到结果的,就不用两次连接,这样可以大大减少对数据库
无用的重复请求。
比如 ,需要获取书籍的id 和name字段 , 则查询如下:
select id , name from tb_book;
之后,在业务逻辑中有需要获取到书籍状态信息, 则查询如下:
select id , status from tb_book;
这样,就需要向数据库提交两次请求,数据库就要做两次
查询操作。其实完全可以用一条SQL语句得到想要的结果。
select id, name , status from tb_book;
11.1.2.2 增加cache层
在应用中,我们可以在应用中增加 缓存 层来达到减轻数据库负担的
目的。缓存层有很多种,也有很多实现方式,只要能达到降低数据
库的负担又能满足应用需求就可以。
因此可以部分数据从数据库中抽取出来放到应用端以文本方式存
储, 或者使用框架(Mybatis, Hibernate)提供的一级缓存/二级缓存,
或者使用redis数据库来缓存数据 。
11.1.3 负载均衡
负载均衡是应用中使用非常普遍的一种优化方法,它的机制就是
利用某种均衡算法,将固定的负载量分布到不同的服务器上, 以此
来降低单台服务器的负载,达到优化的效果。
11.1.3.1 利用MySQL复制分流查询
通过MySQL的主从复制,实现读写分离,使增删改操作走主节点,查
询操作走从节点,从而可以降低单台服务器的读写压力。

11.1.3.2 采用分布式数据库架构
分布式数据库架构适合大数据量、负载高的情况,它有良好
的拓展性和高可用性。通过在多台服务器之间分布数据,可以实
现在多台服务器之间的负载均衡,提高访问效率。
12 Mysql中查询缓存优化
12.1 概述
开启Mysql的查询缓存,当执行完全相同的SQL语句的时候,服务
器就会直接从缓存中读取结果,当数据被修改,之前的缓存会
失效,修改比较频繁的表不适合做查询缓存。
12.2 操作流程
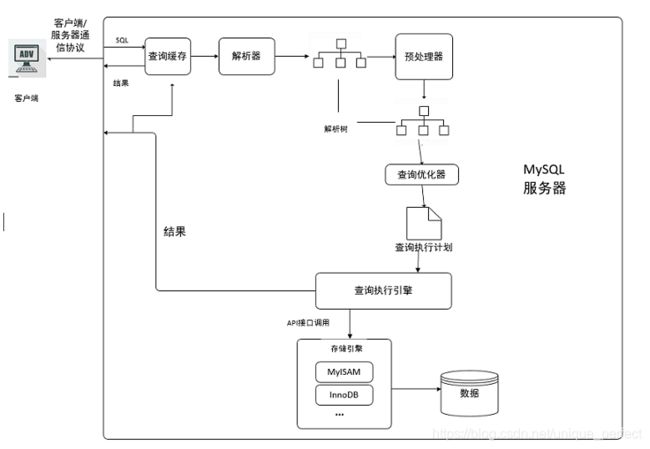
1 客户端发送一条查询给服务器;
2 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储
在缓存中的结果。否则进入下一阶段;
3 服务器端进行SQL解析、预处理,再由优化器生成对应的
执行计划;
4 MySQL根据优化器生成的执行计划,调用存储引擎的API来执
行查询;
5 将结果返回给客户端。
12.3 查询缓存配置
1 查看当前的MySQL数据库是否支持查询缓存:
SHOW VARIABLES LIKE 'have_query_cache';

2 查看当前MySQL是否开启了查询缓存 :
SHOW VARIABLES LIKE 'query_cache_type';

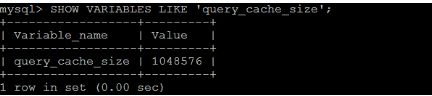
3 查看查询缓存的占用大小 :
SHOW VARIABLES LIKE 'query_cache_size';
4 查看查询缓存的状态变量:
SHOW STATUS LIKE 'Qcache%';
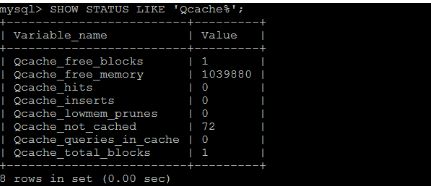
各个变量的含义如下:
| 参数 | 含义 |
|---|---|
| Qcache_free_blocks | 查询缓存中的可用内存块数 |
| Qcache_free_memory | 查询缓存的可用内存量 |
| Qcache_hits | 查询缓存命中数 |
| Qcache_inserts | 添加到查询缓存的查询数 |
| Qcache_lowmen_prunes | 由于内存不足而从查询缓存中删除的查询数 |
| Qcache_not_cached | 非缓存查询的数量(由于 query_cache_type 设置而无法缓存或未缓存) |
| Qcache_queries_in_cache | 查询缓存中注册的查询数 |
| Qcache_total_blocks | 查询缓存中的块总数 |
12.4 开启查询缓存
MySQL的查询缓存默认是关闭的,需要手动配置参数 query_cache_type ,
来开启查询缓存。query_cache_type 该参数的可取值有三个 :
| 值 | 含义 |
|---|---|
| OFF 或 0 | 查询缓存功能关闭 |
| ON 或 1 | 查询缓存功能打开,SELECT的结果符合缓存条件即会缓存,否则,不予缓存,显式指定 SQL_NO_CACHE,不予缓存 |
| DEMAND 或 2 | 查询缓存功能按需进行,显式指定 SQL_CACHE 的SELECT语句才会缓存;其它均不予缓存 |
在 /usr/my.cnf 配置中,增加以下配置 :

配置完毕之后,重启服务既可生效 ;
然后就可以在命令行执行SQL语句进行验证 ,执行一条比较耗时
的SQL语句,然后再多执行几次,查看后面几次的执行时间;获取通
过查看查询缓存的缓存命中数,来判定是否走查询缓存。
12.5 查询缓存SELECT选项
可以在SELECT语句中指定两个与查询缓存相关的选项 :
SQL_CACHE : 如果查询结果是可缓存的,
并且 query_cache_type 系统变量的值为ON或 DEMAND ,
则缓存查询结果 。
SQL_NO_CACHE : 服务器不使用查询缓存。它既不检查查询缓存,
也不检查结果是否已缓存,也不缓存查询结果。
例子:
SELECT SQL_CACHE id, name FROM customer;
SELECT SQL_NO_CACHE id, name FROM customer;
12.6 查询缓存失效的情况
1) SQL 语句不一致的情况, 要想命中查询缓存,查询的SQL语句必须一致。
SQL1 : select count(*) from tb_item;
SQL2 : Select count(*) from tb_item;
2) 当查询语句中有一些不确定的时,则不会缓存。如 : now() , current_date() , curdate() , curtime() , rand() , uuid() , user() , database() 。
SQL1 : select * from tb_item where updatetime < now() limit 1;
SQL2 : select user();
SQL3 : select database();
3) 不使用任何表查询语句。
select 'A';
4) 查询 mysql, information_schema或 performance_schema 数据库中的表时,不会走查询缓存。
select * from information_schema.engines;
13 Mysql内存管理及优化
13.1 内存优化原则
1) 将尽量多的内存分配给MySQL做缓存,但要给操作系统和其他程序
预留足够内存。
2) MyISAM 存储引擎的数据文件读取依赖于操作系统自身的IO缓存,因
此,如果有MyISAM表,就要预留更多的内存给操作系统做IO缓存。
3) 排序区、连接区等缓存是分配给每个数据库会话(session)专用的,其
默认值的设置要根据最大连接数合理分配,如果设置太大,不但浪费
资源,而且在并发连接较高时会导致物理内存耗尽。
13.2 MyISAM 内存优化
myisam存储引擎使用 key_buffer 缓存索引块,加速myisam索引的读
写速度。对于myisam表的数据块,mysql没有特别的缓存机制,完全
依赖于操作系统的IO缓存。
key_buffer_size
key_buffer_size决定MyISAM索引块缓存区的大小,直接影
响到MyISAM表的存取效率。可以在MySQL参数文件中设置
key_buffer_size的值,对于一般MyISAM数据库,建议至少
将1/4可用内存分配给key_buffer_size。
在/usr/my.cnf 中做如下配置:
key_buffer_size=512M
read_buffer_size
如果需要经常顺序扫描myisam表,可以通过增大read_buffer_size的值
来改善性能。但需要注意的是read_buffer_size是每个session独占
的,如果默认值设置太大,就会造成内存浪费。
read_rnd_buffer_size
对于需要做排序的myisam表的查询,如带有order by子句的sql,适
当增加 read_rnd_buffer_size 的值,可以改善此类的sql性能。但
需要注意的是 read_rnd_buffer_size 是每个session独占的,如果默
认值设置太大,就会造成内存浪费。
13.3 InnoDB内存优化
innodb用一块内存区做IO缓存池,该缓存池不仅用来缓存innodb的索引块,
而且也用来缓存innodb的数据块。
innodb_buffer_pool_size
该变量决定了 innodb 存储引擎表数据和索引数据的最大缓存区大小。在
保证操作系统及其他程序有足够内存可用的情况下,innodb_buffer_pool_size
的值越大,缓存命中率越高,访问InnoDB表需要的磁盘I/O 就越少,性
能也就越高。
innodb_buffer_pool_size=512M
innodb_log_buffer_size
决定了innodb重做日志缓存的大小,对于可能产生大量更新记录的
大事务,增加innodb_log_buffer_size的大小,可以避免innodb在事
务提交前就执行不必要的日志写入磁盘操作。
innodb_log_buffer_size=10M
14 Mysql并发参数调整
从实现上来说,MySQL Server 是多线程结构,包括后台线程
和客户服务线程。多线程可以有效利用服务器资源,提高数据库
的并发性能。在Mysql中,控制并发连接和线程的主要参数包括
max_connections、back_log、thread_cache_size、table_open_cahce。
14.1 max_connections
采用max_connections 控制允许连接到MySQL数据库的最大数量,
默认值是 151。如果状态变量 connection_errors_max_connections 不
为零,并且一直增长,则说明不断有连接请求因数据库连接数已达
到允许最大值而失败,这是可以考虑增大max_connections 的值。
Mysql 最大可支持的连接数,取决于很多因素,包括给定操作系统
平台的线程库的质量、内存大小、每个连接的负荷、CPU的处理
速度,期望的响应时间等。在Linux 平台下,性能好的服务器,
支持 500-1000 个连接不是难事,需要根据服务器性能进行评估设定。
14.2 back_log
back_log 参数控制MySQL监听TCP端口时设置的积压请求栈大
小。如果MySql的连接数达到max_connections时,新来的请求
将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量
即back_log,如果等待连接的数量超过back_log,将不被授予
连接资源,将会报错。5.6.6 版本之前默认值为 50 , 之后的版
本默认为 50 + (max_connections / 5), 但最大不超过900。
如果需要数据库在较短的时间内处理大量连接请求, 可以考虑
适当增大back_log 的值。
14.3 table_open_cache
该参数用来控制所有SQL语句执行线程可打开表缓存的数量, 而在
执行SQL语句时,每一个SQL执行线程至少要打开 1 个表缓存。该
参数的值应该根据设置的最大连接数 max_connections 以及每个连
接执行关联查询中涉及的表的最大数量来设定 :
max_connections x N ;
14.4 thread_cache_size
为了加快连接数据库的速度,MySQL 会缓存一定数量的客户服
务线程以备重用,通过参数 thread_cache_size 可控制 MySQL
缓存客户服务线程的数量。
14.5 innodb_lock_wait_timeout
该参数是用来设置InnoDB 事务等待行锁的时间,默认值是50ms , 可以根据需要进行动态设置。对于需要快速反馈的业务系统来说,可以将行锁的等待时间调小,以避免事务长时间挂起; 对于后台运行的批量处理程序来说, 可以将行锁的等待时间调大, 以避免发生大的回滚操作。
15 Mysql锁问题
15.1 锁概述
锁是计算机协调多个进程或线程并发访问某一资源的机制(避免争抢)。
在数据库中,除传统的计算资源(如 CPU、RAM、I/O 等)的争用
以外,数据也是一种供许多用户共享的资源。如何保证数据并发
访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲
突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,
锁对数据库而言显得尤其重要,也更加复杂。
15.2 锁分类
从对数据操作的粒度分 :
1) 表锁:操作时,会锁定整个表。
2) 行锁:操作时,会锁定当前操作行。
从对数据操作的类型分:
1) 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
2) 写锁(排它锁):当前操作没有完成之前,它会阻断其他写锁和读锁。
15.3 Mysql锁
相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特
点是不同的存储引擎支持不同的锁机制。下表中罗列出了各存储引擎对
锁的支持情况:
| 存储引擎 | 表级锁 | 行级锁 | 页面锁 |
|---|---|---|---|
| MyISAM | 支持 | 不支持 | 不支持 |
| InnoDB | 支持 | 支持 | 不支持 |
| MEMORY | 支持 | 不支持 | 不支持 |
| BDB | 支持 | 不支持 | 支持 |
MySQL这3种锁的特性可大致归纳如下 :
| 锁类型 | 特点 |
|---|---|
| 表级锁 | 偏向MyISAM 存储引擎,开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。 |
| 行级锁 | 偏向InnoDB 存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 |
| 页面锁 | 开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。 |
从上述特点可见,很难笼统地说哪种锁更好,只能就具体应用的特点来说哪种锁更合适!仅从锁的角度来说:表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web 应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并查询的应用,如一些在线事务处理(OLTP)系统。
15.4 MyISAM 表锁
MyISAM 存储引擎只支持表锁,这也是MySQL开始几个版本中唯一支持
的锁类型。
15.4.1 如何加表锁
MyISAM 在执行查询语句(SELECT)前,会自动给涉及的所有表加
读锁,在执行更新操作(UPDATE、DELETE、INSERT 等)前,会
自动给涉及的表加写锁,这个过程并不需要用户干预,因此,用户一
般不需要直接用 LOCK TABLE 命令给 MyISAM 表显式加锁。
显示加表锁语法:
加读锁 : lock table table_name read;
加写锁 : lock table table_name write;
15.4.2 读锁案例
准备环境
create database demo_03 default charset=utf8mb4;
use demo_03;
CREATE TABLE `tb_book` (
`id` INT(11) auto_increment,
`name` VARCHAR(50) DEFAULT NULL,
`publish_time` DATE DEFAULT NULL,
`status` CHAR(1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=myisam DEFAULT CHARSET=utf8 ;
INSERT INTO tb_book (id, name, publish_time, status) VALUES(NULL,'java编程思想','2088-08-01','1');
INSERT INTO tb_book (id, name, publish_time, status) VALUES(NULL,'solr编程思想','2088-08-08','0');
CREATE TABLE `tb_user` (
`id` INT(11) auto_increment,
`name` VARCHAR(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=myisam DEFAULT CHARSET=utf8 ;
INSERT INTO tb_user (id, name) VALUES(NULL,'令狐冲');
INSERT INTO tb_user (id, name) VALUES(NULL,'田伯光');
客户端 一 :
1)获得tb_book 表的读锁
lock table tb_book read;
2) 执行查询操作
select * from tb_book;

可以正常执行 , 查询出数据。
客户端 二 :
3) 执行查询操作
select * from tb_book;
客户端 一 :
4)查询未锁定的表
select name from tb_seller;
![]()
客户端 二 :
5)查询未锁定的表
select name from tb_seller;
可以正常查询出未锁定的表;
客户端 一 :
6) 执行插入操作
insert into tb_book values(null,'Mysql高级','2088-01-01','1');

执行插入, 直接报错 , 由于当前tb_book 获得的是 读锁, 不能执行更新操作。
客户端 二 :
7) 执行插入操作
insert into tb_book values(null,'Mysql高级','2088-01-01','1');
![]()
当在客户端一中释放锁指令 unlock tables 后 ,客户端二中的 inesrt 语句 , 立即执行 ;
15.4.3 写锁案例
客户端 一 :
1)获得tb_book 表的写锁
lock table tb_book write ;
2)执行查询操作
select * from tb_book ;
查询操作执行成功;
3)执行更新操作
update tb_book set name = 'java编程思想(第二版)' where id = 1;
![]()
更新操作执行成功 ;
客户端 二 :
4)执行查询操作
select * from tb_book ;

当在客户端一中释放锁指令 unlock tables 后 , 客户端二中的 select 语句 , 立即执行 ;

15.4.4 结论
锁模式的相互兼容性如表中所示:

由上表可见:
1) 对MyISAM 表的读操作,不会阻塞其他用户对同一表的读请求,但
会阻塞对同一表的写请求;
2) 对MyISAM 表的写操作,则会阻塞其他用户对同一表的读和写操作;
简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁,则既会
阻塞读,又会阻塞写。
此外,MyISAM 的读写锁调度是写优先,这也是MyISAM不适合做写
为主的表的存储引擎的原因。因为写锁后,其他线程不能做任何操
作,大量的更新会使查询很难得到锁,从而造成永远阻塞。
15.4.5 查看锁的争用情况
show open tables;

In_user : 表当前被查询使用的次数。如果该数为零,则表是打开的,但是当前没有被使用。
Name_locked:表名称是否被锁定。名称锁定用于取消表或对表进行重命名等操作。
show status like 'Table_locks%';
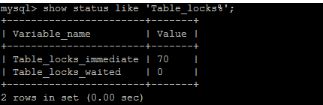
Table_locks_immediate : 指的是能够立即获得表级锁的次数,每立即获取锁,值加1。
Table_locks_waited : 指的是不能立即获取表级锁而需要等待的次数,每
等待一次,该值加1,此值高说明存在着较为严重的表级锁争用情况。
15.5 InnoDB 行锁
15.5.1 行锁介绍
行锁特点 :偏向InnoDB 存储引擎,开销大,加锁慢;会出现死锁;
锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
InnoDB 与 MyISAM 的最大不同有两点:一是支持事务;二是 采用了行级锁。
15.5.2 背景知识
事务及其ACID属性
事务是由一组SQL语句组成的逻辑处理单元。
事务具有以下4个特性,简称为事务ACID属性。
| ACID属性 | 含义 |
|---|---|
| 原子性(Atomicity) | 事务是一个原子操作单元,其对数据的修改,要么全部成功,要么全部失败。 |
| 一致性(Consistent) | 在事务开始和完成时,数据都必须保持一致状态。 |
| 隔离性(Isolation) | 数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的 “独立” 环境下运行。 |
| 持久性(Durable) | 事务完成之后,对于数据的修改是永久的。 |
并发事务处理带来的问题
| 问题 | 含义 |
|---|---|
| 丢失更新(Lost Update) | 当两个或多个事务选择同一行,最初的事务修改的值,会被后面的事务修改的值覆盖。 |
| 脏读(Dirty Reads) | 当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。 |
| 不可重复读(Non-Repeatable Reads) | 一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现和以前读出的数据不一致。 |
| 幻读(Phantom Reads) | 一个事务按照相同的查询条件重新读取以前查询过的数据,却发现其他事务插入了满足其查询条件的新数据。 |
事务隔离级别
为了解决上述提到的事务并发问题,数据库提供一定的事务隔离机
制来解决这个问题。数据库的事务隔离越严格,并发副作用越小,但
付出的代价也就越大,因为事务隔离实质上就是使用事务在一定程
度上“串行化” 进行,这显然与“并发” 是矛盾的。
数据库的隔离级别有4个,由低到高依次为Read uncommitted、
Read committed、Repeatable read、Serializable,
这四个级别可以逐个解决脏写、脏读、不可重复读、幻读这几类问题。
| 隔离级别 | 丢失更新 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| Read uncommitted | × | √ | √ | √ |
| Read committed | × | × | √ | √ |
| Repeatable read(默认) | × | × | × | √ |
| Serializable | × | × | × | × |
备注 : √ 代表可能出现 , × 代表不会出现 。
Mysql 的数据库的默认隔离级别为 Repeatable read , 查看方式:
show variables like 'tx_isolation';

15.5.3 InnoDB的行锁模式
InnoDB 实现了以下两种类型的行锁。
- 共享锁(S):又称为读锁,简称S锁,共享锁就是多个事务
对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
- 排他锁(X):又称为写锁,简称X锁,排他锁就是不能与其他锁并存,如
一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他
锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取
和修改。
对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);
对于普通SELECT语句,InnoDB不会加任何锁;
可以通过以下语句显示给记录集加共享锁或排他锁 。
共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
排他锁(X) :SELECT * FROM table_name WHERE ... FOR UPDATE
15.5.4 案例准备工作
create table test_innodb_lock(
id int(11),
name varchar(16),
sex varchar(1)
)engine = innodb default charset=utf8;
insert into test_innodb_lock values(1,'100','1');
insert into test_innodb_lock values(3,'3','1');
insert into test_innodb_lock values(4,'400','0');
insert into test_innodb_lock values(5,'500','1');
insert into test_innodb_lock values(6,'600','0');
insert into test_innodb_lock values(7,'700','0');
insert into test_innodb_lock values(8,'800','1');
insert into test_innodb_lock values(9,'900','1');
insert into test_innodb_lock values(1,'200','0');
create index idx_test_innodb_lock_id on test_innodb_lock(id);
create index idx_test_innodb_lock_name on test_innodb_lock(name);
15.5.5 行锁基本演示


15.5.6 无索引行锁升级为表锁
如果不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,实际效果跟表锁一样。
查看当前表的索引 : show index from test_innodb_lock ;


由于 执行更新时 , name字段本来为varchar类型, 我们是作为数
组类型使用,存在类型转换,索引失效,最终行锁变为表锁 ;
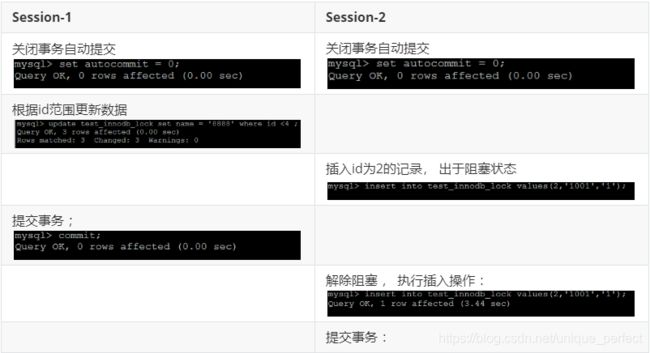
15.5.7 间隙锁危害
当我们用范围条件,而不是使用相等条件检索数据,并请求共享或
排他锁时,InnoDB会给符合条件的已有数据进行加锁; 对于键值在条
件范围内但并不存在的记录,叫做 "间隙(GAP)" , InnoDB也会对
这个 "间隙" 加锁,这种锁机制就是所谓的 间隙锁(Next-Key锁) 。
示例 :
15.5.8 InnoDB行锁争用情况
show status like 'innodb_row_lock%';

Innodb_row_lock_current_waits: 当前正在等待锁定的数量
Innodb_row_lock_time: 从系统启动到现在锁定总时间长度
Innodb_row_lock_time_avg:每次等待所花平均时长
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花
的时间
Innodb_row_lock_waits: 系统启动后到现在总共等待的次数
当等待的次数很高,而且每次等待的时长也不小的时候,我们就需要
分析系统中为什么会有如此多的等待,然后根据分析结果着手制定
优化计划。
15.3.9 总结
InnoDB存储引擎由于实现了行级锁定,虽然在锁定机制的实现方
面带来了性能损耗可能比表锁会更高一些,但是在整体并发处理能
力方面要远远由于MyISAM的表锁的。当系统并发量较高的时候,
InnoDB的整体性能和MyISAM相比就会有比较明显的优势。
但是,InnoDB的行级锁同样也有其脆弱的一面,当我们使用不当
的时候,可能会让InnoDB的整体性能表现不仅不能比MyISAM高,
甚至可能会更差。
优化建议:
- 尽可能让所有数据检索都能通过索引来完成,避免无索引行锁升级为表锁。
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少索引条件,及索引范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度
- 尽可使用低级别事务隔离(但是需要业务层面满足需求)
16 常用SQL技巧
16.1 SQL执行顺序
编写顺序
SELECT DISTINCT
<select list>
FROM
<left_table> <join_type>
JOIN
<right_table> ON <join_condition>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
ORDER BY
<order_by_condition>
LIMIT
<limit_params>
执行顺序
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT DISTINCT <select list>
ORDER BY <order_by_condition>
LIMIT <limit_params>
16.2 正则表达式使用
正则表达式(Regular Expression)是指一个用来描述或者匹配一系
列符合某个句法规则的字符串的单个字符串。
| 符号 | 含义 |
|---|---|
| ^ | 在字符串开始处进行匹配 |
| $ | 在字符串末尾处进行匹配 |
| . | 匹配任意单个字符, 包括换行符 |
| […] | 匹配出括号内的任意字符 |
| [^…] | 匹配不出括号内的任意字符 |
| a* | 匹配零个或者多个a(包括空串) |
| a+ | 匹配一个或者多个a(不包括空串) |
| a? | 匹配零个或者一个a |
| a1|a2 | 匹配a1或a2 |
| a(m) | 匹配m个a |
| a(m,) | 至少匹配m个a |
| a(m,n) | 匹配m个a 到 n个a |
| a(,n) | 匹配0到n个a |
| (…) | 将模式元素组成单一元素 |
select * from emp where name regexp '^T';
select * from emp where name regexp '2$';
select * from emp where name regexp '[uvw]';
16.3 MySQL常用函数
数字函数
| 函数名称 | 作 用 |
|---|---|
| ABS | 求绝对值 |
| SQRT | 求二次方根 |
| MOD | 求余数 |
| CEIL 和 CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
| POW 和 POWER | 两个函数的功能相同,都是所传参数的次方的结果值 |
| SIN | 求正弦值 |
| ASIN | 求反正弦值,与函数 SIN 互为反函数 |
| COS | 求余弦值 |
| ACOS | 求反余弦值,与函数 COS 互为反函数 |
| TAN | 求正切值 |
| ATAN | 求反正切值,与函数 TAN 互为反函数 |
| COT | 求余切值 |
字符串函数
| 函数名称 | 作 用 |
|---|---|
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 |
| INSERT | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| LEFT | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
日期函数
| 函数名称 | 作 用 |
|---|---|
| CURDATE 和 CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME 和 CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW 和 SYSDATE | 两个函数作用相同,返回当前系统的日期和时间值 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定日期中的月份英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH | 获取指定日期是一个月中是第几天,返回值范围是1~31 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| TIME_TO_SEC | 将时间参数转换为秒数 |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| DATE_ADD 和 ADDDATE | 两个函数功能相同,都是向日期添加指定的时间间隔 |
| DATE_SUB 和 SUBDATE | 两个函数功能相同,都是向日期减去指定的时间间隔 |
| ADDTIME | 时间加法运算,在原始时间上添加指定的时间 |
| SUBTIME | 时间减法运算,在原始时间上减去指定的时间 |
| DATEDIFF | 获取两个日期之间间隔,返回参数 1 减去参数 2 的值 |
| DATE_FORMAT | 格式化指定的日期,根据参数返回指定格式的值 |
| WEEKDAY | 获取指定日期在一周内的对应的工作日索引 |
聚合函数
| 函数名称 | 作用 |
|---|---|
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和,返回指定列的总和 |
| AVG | 求平均值,返回指定列数据的平均值 |
17 MySql中常用工具
17.1 mysql
该mysql不是指mysql服务,而是指mysql的客户端工具。
语法 :
mysql [options] [database]
连接选项
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
执行选项
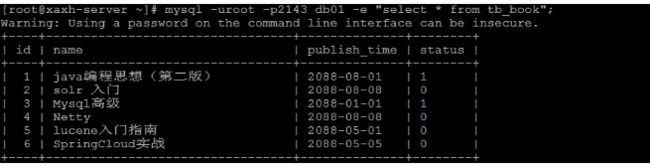
-e, --execute=name 执行SQL语句并退出
此选项可以在Mysql客户端执行SQL语句,而不用连接到MySQL数
据库再执行,对于一些批处理脚本,这种方式尤其方便。
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
17.2 mysqladmin
mysqladmin 是一个执行管理操作的客户端程序。可以用它来检查
服务器的配置和当前状态、创建并删除数据库等。
可以通过 : mysqladmin --help 指令查看帮助文档

示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
17.3 mysqlbinlog
由于服务器生成的二进制日志文件以二进制格式保存,所以
如果想要检查这些文本的文本格式,就会使用到mysqlbinlog
日志管理工具。
语法 :
mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
17.4 mysqldump
mysqldump 客户端工具用来备份数据库或在不同数据库之间进行数据迁移。备份内容包含创建表,及插入表的SQL语句。
语法 :
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
连接选项
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
输出内容选项
参数:
--add-drop-database 在每个数据库创建语句前加上 Drop database 语句
--add-drop-table 在每个表创建语句前加上 Drop table 语句 , 默认开启 ; 不开启 (--skip-add-drop-table)
-n, --no-create-db 不包含数据库的创建语句
-t, --no-create-info 不包含数据表的创建语句
-d --no-data 不包含数据
-T, --tab=name 自动生成两个文件:一个.sql文件,创建表结构的语句;
一个.txt文件,数据文件,相当于select into outfile
示例 :
mysqldump -uroot -p2143 db01 tb_book --add-drop-database --add-drop-table > a
mysqldump -uroot -p2143 -T /tmp test city
![]()
17.5 mysqlimport/source
mysqlimport 是客户端数据导入工具,用来导入mysqldump 加 -T 参数后导出的文本文件。
语法:
mysqlimport [options] db_name textfile1 [textfile2...]
示例:
mysqlimport -uroot -p2143 test /tmp/city.txt
如果需要导入sql文件,可以使用mysql中的source 指令 :
source /root/tb_book.sql
17.6 mysqlshow
mysqlshow 客户端对象查找工具,用来很快地查找存在哪些数据库、
数据库中的表、表中的列或者索引。
语法:
mysqlshow [options] [db_name [table_name [col_name]]]
参数:
--count 显示数据库及表的统计信息(数据库,表 均可以不指定)
-i 显示指定数据库或者指定表的状态信息
示例:
#查询每个数据库的表的数量及表中记录的数量
mysqlshow -uroot -p2143 --count
#查询test库中每个表中的字段书,及行数
mysqlshow -uroot -p2143 test --count
#查询test库中book表的详细情况
mysqlshow -uroot -p2143 test book --count
18 Mysql 日志
在任何一种数据库中,都会有各种各样的日志,记录着数据库工作的
方方面面,以帮助数据库管理员追踪数据库曾经发生过的各种事件。
MySQL 也不例外,在 MySQL 中,有 4 种不同的日志,分别是错误
日志、二进制日志(BINLOG 日志)、查询日志和慢查询日志,这些日
志记录着数据库在不同方面的踪迹。
18.1 错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动
和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当
数据库出现任何故障导致无法正常使用时,可以首先查看此日志。
该日志是默认开启的 , 默认存放目录为 mysql 的数据目录(var/lib/mysql),
默认的日志文件名为 hostname.err(hostname是主机名)。
查看日志位置指令 :
show variables like 'log_error%';
查看日志内容 :
tail -f /var/lib/mysql/xaxh-server.err

18.2 二进制日志
概述
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句
和 DML(数据操纵语言)语句,但是不包括数据查询语句。此日志
对于灾难时的数据恢复起着极其重要的作用,MySQL的主从复制,
就是通过该binlog实现的。
二进制日志,默认情况下是没有开启的,需要到MySQL的配置文件中开启,
并配置MySQL日志的格式。
配置文件位置 : /usr/my.cnf
日志存放位置 : 配置时,给定了文件名但是没有指定路径,日志默认
写入Mysql的数据目录。
#配置开启binlog日志, 日志的文件前缀为 mysqlbin -----> 生成的文件名如 : mysqlbin.000001,mysqlbin.000002
log_bin=mysqlbin
#配置二进制日志的格式
binlog_format=STATEMENT
日志格式
STATEMENT
该日志格式在日志文件中记录的都是SQL语句(statement),每一条
对数据进行修改的SQL都会记录在日志文件中,通过Mysql提供的
mysqlbinlog工具,可以清晰的查看到每条语句的文本。主从复制的时
候,从库(slave)会将日志解析为原文本,并在从库重新执行一次。
ROW
该日志格式在日志文件中记录的是每一行的数据变更,而不是记
录SQL语句。比如,执行SQL语句 : update tb_book set status='1' ,
如果是STATEMENT 日志格式,在日志中会记录一行SQL文件; 如
果是ROW,由于是对全表进行更新,也就是每一行记录都会发生变
更,ROW 格式的日志中会记录每一行的数据变更。
MIXED
这是目前MySQL默认的日志格式,即混合了STATEMENT 和 ROW两
种格式。默认情况下采用STATEMENT,但是在一些特殊情况下
采用ROW来进行记录。MIXED 格式能尽量利用两种模式的优点,而
避开他们的缺点。
18.2.1 日志读取
由于日志以二进制方式存储,不能直接读取,需要用mysqlbinlog工
具来查看,语法如下 :
mysqlbinlog log-file;
查看STATEMENT格式日志*
执行插入语句 :
insert into tb_book values(null,'Lucene','2088-05-01','0');
查看日志文件 :
![]()
mysqlbin.index : 该文件是日志索引文件 , 记录日志的文件名;
mysqlbing.000001 :日志文件
查看日志内容 :
mysqlbinlog mysqlbing.000001;

查看ROW格式日志
配置 :
#配置开启binlog日志, 日志的文件前缀为 mysqlbin -----> 生成的文件名如 : mysqlbin.000001,mysqlbin.000002
log_bin=mysqlbin
#配置二进制日志的格式
binlog_format=ROW
插入数据 :
insert into tb_book values(null,'SpringCloud实战','2088-05-05','0');
如果日志格式是 ROW , 直接查看数据 , 是查看不懂的 ; 可以在mysqlbinlog 后面加上参数 -vv
mysqlbinlog -vv mysqlbin.000002
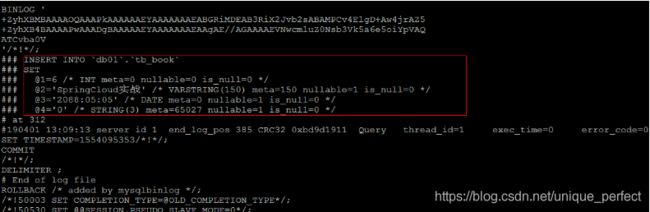
18.2.2 日志删除
对于比较繁忙的系统,由于每天生成日志量大 ,这些日志如果长时
间不清楚,将会占用大量的磁盘空间。下面我们将会讲解几种删除日
志的常见方法 :
方式一
通过 Reset Master 指令删除全部 binlog 日志,删除之后,
日志编号,将从 xxxx.000001重新开始 。
查询之前 ,先查询下日志文件 :

执行删除日志指令:
Reset Master
执行之后, 查看日志文件 :

方式三
执行指令purge master logs before 'yyyy-mm-dd hh24:mi:ss',该命令将删除
日志为 "yyyy-mm-dd hh24:mi:ss" 之前产生的所有日志 。
方式四
设置参数 --expire_logs_days=# ,此参数的含义是设置日志的过期天数,
过了指定的天数后日志将会被自动删除,这样将有利于减少DBA 管理日志
的工作量。
配置如下 :

18.3 查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据
的SQL语句。
默认情况下, 查询日志是未开启的。如果需要开启查询日志,可以设置以下
配置 :
#该选项用来开启查询日志 , 可选值 : 0 或者 1 ; 0 代表关闭, 1 代表开启
general_log=1
#设置日志的文件名 , 如果没有指定, 默认的文件名为 host_name.log
general_log_file=file_name
在 mysql 的配置文件 /usr/my.cnf 中配置如下内容 :

配置完毕之后,在数据库执行以下操作 :
select * from tb_book;
select * from tb_book where id = 1;
update tb_book set name = 'lucene入门指南' where id = 5;
select * from tb_book where id < 8;
执行完毕之后, 再次来查询日志文件 :

18.4 慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值
并且扫描记录数不小于 min_examined_row_limit 的所有的SQL语
句的日志。long_query_time 默认为 10 秒,最小为 0, 精度可以到微秒。
18.4.1 文件位置和格式
慢查询日志默认是关闭的 。可以通过两个参数来控制慢查询日志 :
# 该参数用来控制慢查询日志是否开启, 可取值: 1 和 0 , 1 代表开启, 0 代表关闭
slow_query_log=1
# 该参数用来指定慢查询日志的文件名
slow_query_log_file=slow_query.log
# 该选项用来配置查询的时间限制, 超过这个时间将认为值慢查询,
将需要进行日志记录, 默认10s
long_query_time=10
18.4.2 日志的读取
和错误日志、查询日志一样,慢查询日志记录的格式也是纯文本,可以
被直接读取。
1) 查询long_query_time 的值。

2) 执行查询操作
select id, title,price,num ,status from tb_item where id = 1;

由于该语句执行时间很短,为0s , 所以不会记录在慢查询日志中。
select * from tb_item where title like '%阿尔卡特 (OT-927) 炭黑 联通3G手机 双卡双待165454%' ;
![]()
该SQL语句 , 执行时长为 26.77s ,超过10s , 所以会记录在慢查询日志文件中。
3) 查看慢查询日志文件
直接通过cat 指令查询该日志文件 :

如果慢查询日志内容很多, 直接查看文件,比较麻烦, 这个时候
可以借助于mysql自带的 mysqldumpslow 工具, 来对慢查询日志进行
分类汇总。

19 Mysql复制
19.1 复制概述
复制是指将主数据库的DDL 和 DML 操作通过二进制日志传到从库服
务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得
从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以
作为其他从服务器的主库,实现链状复制。
19.2 复制原理
MySQL 的主从复制原理如下。

从上层来看,复制分成三步:
- Master 主库在事务提交时,会把数据变更作为时间 Events 记录在二
进制日志文件 Binlog 中。
- 主库推送二进制日志文件 Binlog 中的日志事件到从库的中继日志
Relay Log 。
- slave重做中继日志中的事件,将改变反映它自己的数据。
19.3 复制优势
MySQL 复制的有点主要包含以下三个方面:
- 主库出现问题,可以快速切换到从库提供服务。
- 可以在从库上执行查询操作,从主库中更新,实现读写分离,降低主库的访问压力。
- 可以在从库中执行备份,以避免备份期间影响主库的服务。
19.4 搭建步骤
19.4.1 master
1) 在master 的配置文件(/usr/my.cnf)中,配置如下内容:
#mysql 服务ID,保证整个集群环境中唯一
server-id=1
#mysql binlog 日志的存储路径和文件名
log-bin=/var/lib/mysql/mysqlbin
#错误日志,默认已经开启
#log-err
#mysql的安装目录
#basedir
#mysql的临时目录
#tmpdir
#mysql的数据存放目录
#datadir
#是否只读,1 代表只读, 0 代表读写
read-only=0
#忽略的数据, 指不需要同步的数据库
binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db01
2) 执行完毕之后,需要重启Mysql:
service mysql restart ;
3) 创建同步数据的账户,并且进行授权操作:
grant replication slave on *.* to 'cqm'@'192.168.192.131' identified by 'cqm';
flush privileges;
4) 查看master状态:
show master status;

字段含义:
File : 从哪个日志文件开始推送日志文件
Position : 从哪个位置开始推送日志
Binlog_Ignore_DB : 指定不需要同步的数据库
19.4.2 slave
1) 在 slave 端配置文件中,配置如下内容:
#mysql服务端ID,唯一
server-id=2
#指定binlog日志
log-bin=/var/lib/mysql/mysqlbin
2) 执行完毕之后,需要重启Mysql:
service mysql restart;
3) 执行如下指令 :
change master to master_host= '192.168.192.130', master_user='cqm', master_password='cqm', master_log_file='mysqlbin.000001', master_log_pos=413;
指定当前从库对应的主库的IP地址,用户名,密码,从哪个日志文件开始的那个位置开始同步推送日志。
4) 开启同步操作
start slave;
show slave status;

5) 停止同步操作
stop slave;
19.4.3 验证同步操作
1) 在主库中创建数据库,创建表,并插入数据 :
create database db01;
user db01;
create table user(
id int(11) not null auto_increment,
name varchar(50) not null,
sex varchar(1),
primary key (id)
)engine=innodb default charset=utf8;
insert into user(id,name,sex) values(null,'Tom','1');
insert into user(id,name,sex) values(null,'Trigger','0');
insert into user(id,name,sex) values(null,'Dawn','1');
2) 在从库中查询数据,进行验证 :
在从库中,可以查看到刚才创建的数据库:

在该数据库中,查询user表中的数据:

20 综合案例
20.1 需求分析
在业务系统中,需要记录当前业务系统的访问日志,该访问日志包
含:操作人,操作时间,访问类,访问方法,请求参数,请求结
果,请求结果类型,请求时长 等信息。记录详细的系统访问日志,
主要便于对系统中的用户请求进行追踪,并且在系统 的管理后台可
以查看到用户的访问记录。
记录系统中的日志信息,可以通过Spring 框架的AOP来实现。具体
的请求处理流程,如下:

20.2 搭建案例环境
20.2.1 数据库表
CREATE DATABASE mysql_demo DEFAULT CHARACTER SET utf8mb4 ;
CREATE TABLE `brand` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL COMMENT '品牌名称',
`first_char` varchar(1) DEFAULT NULL COMMENT '品牌首字母',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `item` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品id',
`title` varchar(100) NOT NULL COMMENT '商品标题',
`price` double(10,2) NOT NULL COMMENT '商品价格,单位为:元',
`num` int(10) NOT NULL COMMENT '库存数量',
`categoryid` bigint(10) NOT NULL COMMENT '所属类目,叶子类目',
`status` varchar(1) DEFAULT NULL COMMENT '商品状态,1-正常,2-下架,3-删除',
`sellerid` varchar(50) DEFAULT NULL COMMENT '商家ID',
`createtime` datetime DEFAULT NULL COMMENT '创建时间',
`updatetime` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
`birthday` datetime DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`email` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`qq` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `operation_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`operate_class` varchar(200) DEFAULT NULL COMMENT '操作类',
`operate_method` varchar(200) DEFAULT NULL COMMENT '操作方法',
`return_class` varchar(200) DEFAULT NULL COMMENT '返回值类型',
`operate_user` varchar(20) DEFAULT NULL COMMENT '操作用户',
`operate_time` varchar(20) DEFAULT NULL COMMENT '操作时间',
`param_and_value` varchar(500) DEFAULT NULL COMMENT '请求参数名及参数值',
`cost_time` bigint(20) DEFAULT NULL COMMENT '执行方法耗时, 单位 ms',
`return_value` varchar(200) DEFAULT NULL COMMENT '返回值',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
20.2.2 pom.xml
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.7maven.compiler.source>
<maven.compiler.target>1.7maven.compiler.target>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<spring.version>5.0.2.RELEASEspring.version>
<slf4j.version>1.6.6slf4j.version>
<log4j.version>1.2.12log4j.version>
<mybatis.version>3.4.5mybatis.version>
properties>
<dependencies>
<dependency>
<groupId>org.aspectjgroupId>
<artifactId>aspectjweaverartifactId>
<version>1.6.8version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.16.16version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-contextartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-context-supportartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-ormartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-testartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-webmvcartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-txartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>javax.servletgroupId>
<artifactId>javax.servlet-apiartifactId>
<version>3.1.0version>
<scope>providedscope>
dependency>
<dependency>
<groupId>javax.servlet.jspgroupId>
<artifactId>jsp-apiartifactId>
<version>2.0version>
<scope>providedscope>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>${log4j.version}version>
dependency>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>${mybatis.version}version>
dependency>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatis-springartifactId>
<version>1.3.0version>
dependency>
<dependency>
<groupId>c3p0groupId>
<artifactId>c3p0artifactId>
<version>0.9.1.2version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.5version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-coreartifactId>
<version>2.9.0version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
<version>2.9.0version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-annotationsartifactId>
<version>2.9.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.tomcat.mavengroupId>
<artifactId>tomcat7-maven-pluginartifactId>
<version>2.2version>
<configuration>
<port>8080port>
<path>/path>
<uriEncoding>utf-8uriEncoding>
configuration>
plugin>
plugins>
build>
20.2.3 web.xml
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
version="2.5">
<filter>
<filter-name>CharacterEncodingFilterfilter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilterfilter-class>
<init-param>
<param-name>encodingparam-name>
<param-value>utf-8param-value>
init-param>
<init-param>
<param-name>forceEncodingparam-name>
<param-value>trueparam-value>
init-param>
filter>
<filter-mapping>
<filter-name>CharacterEncodingFilterfilter-name>
<url-pattern>/*url-pattern>
filter-mapping>
<context-param>
<param-name>contextConfigLocationparam-name>
<param-value>classpath:applicationContext.xmlparam-value>
context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListenerlistener-class>
listener>
<servlet>
<servlet-name>springmvcservlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServletservlet-class>
<init-param>
<param-name>contextConfigLocationparam-name>
<param-value>classpath:springmvc.xmlparam-value>
init-param>
servlet>
<servlet-mapping>
<servlet-name>springmvcservlet-name>
<url-pattern>*.dourl-pattern>
servlet-mapping>
<welcome-file-list>
<welcome-file>log-datalist.htmlwelcome-file>
welcome-file-list>
web-app>
20.2.4 db.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://192.168.142.128:3306/mysql_demo
jdbc.username=root
jdbc.password=root
20.2.5 applicationContext.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="classpath:db.properties"/>
<context:component-scan base-package="cn.itcast">
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller">
context:exclude-filter>
context:component-scan>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="typeAliasesPackage" value="cn.itcast.pojo"/>
bean>
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driver}">property>
<property name="jdbcUrl" value="${jdbc.url}">property>
<property name="user" value="${jdbc.username}">property>
<property name="password" value="${jdbc.password}">property>
bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.itcast.mapper"/>
bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
bean>
<tx:annotation-driven transaction-manager="transactionManager">tx:annotation-driven>
beans>
20.2.6 springmvc.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="cn.itcast.controller">context:component-scan>
<mvc:annotation-driven>mvc:annotation-driven>
<aop:aspectj-autoproxy />
beans>
20.2.7 导入基础工程
20.3 通过AOP记录操作日志
20.3.1 自定义注解
通过自定义注解,来标示方法需不需要进行记录日志,如果该方法在访问时需要记录日志,则在该方法上标示该注解既可。
@Inherited
@Documented
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface OperateLog {
}
20.3.2 定义通知类
@Component
@Aspect
public class OperateAdvice {
private static Logger log = Logger.getLogger(OperateAdvice.class);
@Autowired
private OperationLogService operationLogService;
@Around("execution(* cn.itcast.controller.*.*(..)) && @annotation(operateLog)")
public Object insertLogAround(ProceedingJoinPoint pjp , OperateLog operateLog) throws Throwable{
System.out.println(" ************************ 记录日志 [start] ****************************** ");
OperationLog op = new OperationLog();
DateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
op.setOperateTime(sdf.format(new Date()));
op.setOperateUser(DataUtils.getRandStr(8));
op.setOperateClass(pjp.getTarget().getClass().getName());
op.setOperateMethod(pjp.getSignature().getName());
//获取方法调用时传递的参数
Object[] args = pjp.getArgs();
op.setParamAndValue(Arrays.toString(args));
long start_time = System.currentTimeMillis();
//放行
Object object = pjp.proceed();
long end_time = System.currentTimeMillis();
op.setCostTime(end_time - start_time);
if(object != null){
op.setReturnClass(object.getClass().getName());
op.setReturnValue(object.toString());
}else{
op.setReturnClass("java.lang.Object");
op.setParamAndValue("void");
}
log.error(JsonUtils.obj2JsonString(op));
operationLogService.insert(op);
System.out.println(" ************************** 记录日志 [end] *************************** ");
return object;
}
}
20.3.3 方法上加注解
在需要记录日志的方法上加上注解@OperateLog。
@OperateLog
@RequestMapping("/insert")
public Result insert(@RequestBody Brand brand){
try {
brandService.insert(brand);
return new Result(true,"操作成功");
} catch (Exception e) {
e.printStackTrace();
return new Result(false,"操作失败");
}
}
20.4 日志查询后端代码实现
20.4.1 Mapper接口
public interface OperationLogMapper {
public void insert(OperationLog operationLog);
public List<OperationLog> selectListByCondition(Map dataMap);
public Long countByCondition(Map dataMap);
}
20.4.2 Mapper.xml映射配置文件
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="cn.itcast.mapper.OperationLogMapper" >
<insert id="insert" parameterType="operationLog">
INSERT INTO operation_log(id,return_value,return_class,operate_user,operate_time,param_and_value,
operate_class,operate_method,cost_time)
VALUES(NULL,#{returnValue},#{returnClass},#{operateUser},#{operateTime},#{paramAndValue},
#{operateClass},#{operateMethod},#{costTime})
insert>
<select id="selectListByCondition" parameterType="map" resultType="operationLog">
select
id ,
operate_class as operateClass ,
operate_method as operateMethod,
return_class as returnClass,
operate_user as operateUser,
operate_time as operateTime,
param_and_value as paramAndValue,
cost_time as costTime,
return_value as returnValue
from operation_log
<include refid="oplog_where"/>
limit #{start},#{size}
select>
<select id="countByCondition" resultType="long" parameterType="map">
select count(*) from operation_log
<include refid="oplog_where"/>
select>
<sql id="oplog_where">
<where>
<if test="operateClass != null and operateClass != '' ">
and operate_class = #{operateClass}
if>
<if test="operateMethod != null and operateMethod != '' ">
and operate_method = #{operateMethod}
if>
<if test="returnClass != null and returnClass != '' ">
and return_class = #{returnClass}
if>
<if test="costTime != null">
and cost_time = #{costTime}
if>
where>
sql>
mapper>
20.4.3 Service
@Service
@Transactional
public class OperationLogService {
//private static Logger logger = Logger.getLogger(OperationLogService.class);
@Autowired
private OperationLogMapper operationLogMapper;
//插入数据
public void insert(OperationLog operationLog){
operationLogMapper.insert(operationLog);
}
//根据条件查询
public PageResult selectListByCondition(Map dataMap, Integer pageNum , Integer pageSize){
if(paramMap ==null){
paramMap = new HashMap();
}
paramMap.put("start" , (pageNum-1)*rows);
paramMap.put("rows",rows);
Object costTime = paramMap.get("costTime");
if(costTime != null){
if("".equals(costTime.toString())){
paramMap.put("costTime",null);
}else{
paramMap.put("costTime",new Long(paramMap.get("costTime").toString()));
}
}
System.out.println(dataMap);
long countStart = System.currentTimeMillis();
Long count = operationLogMapper.countByCondition(dataMap);
long countEnd = System.currentTimeMillis();
System.out.println("Count Cost Time : " + (countEnd-countStart)+" ms");
List<OperationLog> list = operationLogMapper.selectListByCondition(dataMap);
long queryEnd = System.currentTimeMillis();
System.out.println("Query Cost Time : " + (queryEnd-countEnd)+" ms");
return new PageResult(count,list);
}
}
20.4.4 Controller
@RestController
@RequestMapping("/operationLog")
public class OperationLogController {
@Autowired
private OperationLogService operationLogService;
@RequestMapping("/findList")
public PageResult findList(@RequestBody Map dataMap, Integer pageNum , Integer pageSize){
PageResult page = operationLogService.selectListByCondition(dataMap, pageNum, pageSize);
return page;
}
20.5 日志查询前端代码实现
前端代码使用 BootStrap + AdminLTE 进行布局, 使用Vuejs 进行视
图层展示。
20.5.1 js
<script>
var vm = new Vue({
el: '#app',
data: {
dataList:[],
searchEntity:{
operateClass:'',
operateMethod:'',
returnClass:'',
costTime:''
},
page: 1, //显示的是哪一页
pageSize: 10, //每一页显示的数据条数
total: 150, //记录总数
maxPage:8 //最大页数
},
methods: {
pageHandler: function (page) {
this.page = page;
this.search();
},
search: function () {
var _this = this;
this.showLoading();
axios.post('/operationLog/findList.do?pageNum=' + _this.page + "&pageSize=" + _this.pageSize, _this.searchEntity).then(function (response) {
if (response) {
_this.dataList = response.data.dataList;
_this.total = response.data.total;
_this.hideLoading();
}
})
},
showLoading: function () {
$('#loadingModal').modal({backdrop: 'static', keyboard: false});
},
hideLoading: function () {
$('#loadingModal').modal('hide');
},
},
created:function(){
this.pageHandler(1);
}
});
</script>
20.5.2 列表数据展示
<tr v-for="item in dataList">
<td><input name="ids" type="checkbox">td>
<td>{{item.id}}td>
<td>{{item.operateClass}}td>
<td>{{item.operateMethod}}td>
<td>{{item.returnClass}}td>
<td>{{item.returnValue}}td>
<td>{{item.operateUser}}td>
<td>{{item.operateTime}}td>
<td>{{item.costTime}}td>
<td class="text-center">
<button type="button" class="btn bg-olive btn-xs">详情button>
<button type="button" class="btn bg-olive btn-xs">删除button>
td>
tr>
20.5.3 分页插件
<div class="wrap" id="wrap">
<zpagenav v-bind:page="page" v-bind:page-size="pageSize" v-bind:total="total"
v-bind:max-page="maxPage" v-on:pagehandler="pageHandler">
zpagenav>
div>
20.6 联调测试
可以通过postman来访问业务系统,再查看数据库中的日志信息,
验证能不能将用户的访问日志记录下来。
20.7 分析性能问题
系统中用户访问日志的数据量,随着时间的推移,这张表的数据
量会越来越大,因此我们需要根据业务需求,来对日志查询模块
的性能进行优化。
1) 分页查询优化
由于在进行日志查询时,是进行分页查询,那也就意味着,在查看时,至
少需要查询两次:
A. 查询符合条件的总记录数。--> count 操作
B. 查询符合条件的列表数据。--> 分页查询 limit 操作
通常来说,count() 都需要扫描大量的行(意味着需要访问大量的数据)才
能获得精确的结果,因此是很难对该SQL进行优化操作的。如果需要对
count进行优化,可以采用另外一种思路,可以增加汇总表,或者redis
缓存来专门记录该表对应的记录数,这样的话,就可以很轻松的实现汇
总数据的查询,而且效率很高,但是这种统计并不能保证百分之百的准确 。
对于数据库的操作,“快速、精确、实现简单”,三者永远只能满足其二,
必须舍掉其中一个。
2) 条件查询优化
针对于条件查询,需要对查询条件,及排序字段建立索引。
3) 读写分离
通过主从复制集群,来完成读写分离,使写操作走主节点, 而读操作,走从节点。
4) MySQL服务器优化
5) 应用优化
20.8 性能优化-分页
20.8.1 优化count
创建一张表用来记录日志表的总数据量:
create table log_counter(
logcount bigint not null
)engine = innodb default CHARSET = utf8;
在每次插入数据之后,更新该表 :
<update id="updateLogCounter" >
update log_counter set logcount = logcount + 1
</update>
在进行分页查询时, 获取总记录数,从该表中查询既可。
<select id="countLogFromCounter" resultType="long">
select logcount from log_counter limit 1
</select>
20.8.2 优化limit
在进行分页时,一般通过创建覆盖索引,能够比较好的提高性能。一个
非常常见,而又非常头疼的分页场景就是 "limit 1000000,10" ,此时MySQL
需要搜索出前1000010 条记录后,仅仅需要返回第 1000001 到 1000010
条记录,前1000000 记录会被抛弃,查询代价非常大。
当点击比较靠后的页码时,就会出现这个问题,查询效率非常慢。
优化SQL:
select * from operation_log limit 3000000 , 10;
将上述SQL优化为 :
select * from operation_log t , (select id from operation_log order by id limit 3000000,10) b where t.id = b.id ;
<select id="selectListByCondition" parameterType="map" resultType="operationLog">
select
id ,
operate_class as operateClass ,
operate_method as operateMethod,
return_class as returnClass,
operate_user as operateUser,
operate_time as operateTime,
param_and_value as paramAndValue,
cost_time as costTime,
return_value as returnValue
from operation_log t,
(select id from operation_log
<where>
<include refid="oplog_where"/>
where>
order by id limit #{start},#{rows}) b where t.id = b.id
select>
20.9 性能优化-索引

当根据操作人进行查询时, 查询的效率很低,耗时比较长。原因就是因
为在创建数据库表结构时,并没有针对于 操作人 字段建立索引。
CREATE INDEX idx_user_method_return_cost ON operation_log(operate_user,operate_method,return_class,cost_time);
同上 , 为了查询效率高,我们也需要对 操作方法、返回值类型、操作耗时 等字段进行创建索引,以提高查询效率。
CREATE INDEX idx_optlog_method_return_cost ON operation_log(operate_method,return_class,cost_time);
CREATE INDEX idx_optlog_return_cost ON operation_log(return_class,cost_time);
CREATE INDEX idx_optlog_cost ON operation_log(cost_time);
20.10 性能优化-排序
在查询数据时,如果业务需求中需要我们对结果内容进行了排序处理 ,
这个时候,我们还需要对排序的字段建立适当的索引, 来提高排序的效率 。
20.11 性能优化-读写分离
20.11.1 概述
在Mysql主从复制的基础上,可以使用读写分离来降低单台Mysql节点
压力,从而来提高访问效率,读写分离的架构如下:
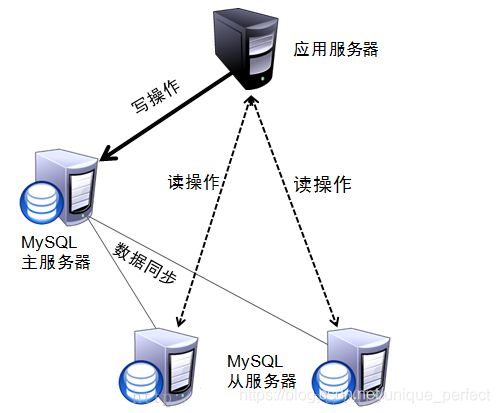
20.11.2 实现方式
db.properties
jdbc.write.driver=com.mysql.jdbc.Driver
jdbc.write.url=jdbc:mysql://192.168.142.128:3306/mysql_demo
jdbc.write.username=root
jdbc.write.password=cqm
jdbc.read.driver=com.mysql.jdbc.Driver
jdbc.read.url=jdbc:mysql://192.168.142.129:3306/mysql_demo
jdbc.read.username=root
jdbc.read.password=yxj
applicationContext-datasource.xml
ChooseDataSource
public class ChooseDataSource extends AbstractRoutingDataSource {
public static Map> METHOD_TYPE_MAP = new HashMap>();
/**
* 实现父类中的抽象方法,获取数据源名称
* @return
*/
protected Object determineCurrentLookupKey() {
return DataSourceHandler.getDataSource();
}
// 设置方法名前缀对应的数据源
public void setMethodType(Map map) {
for (String key : map.keySet()) {
List v = new ArrayList();
String[] types = map.get(key).split(",");
for (String type : types) {
if (!StringUtils.isEmpty(type)) {
v.add(type);
}
}
METHOD_TYPE_MAP.put(key, v);
}
System.out.println("METHOD_TYPE_MAP : "+METHOD_TYPE_MAP);
}
}
DataSourceHandler
public class DataSourceHandler {
// 数据源名称
public static final ThreadLocal holder = new ThreadLocal();
/**
* 在项目启动的时候将配置的读、写数据源加到holder中
*/
public static void putDataSource(String datasource) {
holder.set(datasource);
}
/**
* 从holer中获取数据源字符串
*/
public static String getDataSource() {
return holder.get();
}
}
DataSourceAspect
@Aspect
@Component
@Order(-9999)
@EnableAspectJAutoProxy(proxyTargetClass = true)
public class DataSourceAspect {
protected Logger logger = LoggerFactory.getLogger(this.getClass());
/**
* 配置前置通知,使用在方法aspect()上注册的切入点
*/
@Before("execution(* cn.itcast.service.*.*(..))")
@Order(-9999)
public void before(JoinPoint point) {
String className = point.getTarget().getClass().getName();
String method = point.getSignature().getName();
logger.info(className + "." + method + "(" + Arrays.asList(point.getArgs())+ ")");
try {
for (String key : ChooseDataSource.METHOD_TYPE_MAP.keySet()) {
for (String type : ChooseDataSource.METHOD_TYPE_MAP.get(key)) {
if (method.startsWith(type)) {
System.out.println("key : " + key);
DataSourceHandler.putDataSource(key);
break;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
通过 @Order(-9999) 注解来控制事务管理器, 与该通知类的加载顺序 , 需要让通知类 , 先加载 , 来判定使用哪个数据源 .
20.11.3 验证
在主库和从库中,执行如下SQL语句,来查看是否读的时候,
从从库中读取 ; 写入操作的时候,是否写入到主库。
show status like 'Innodb_rows_%' ;

20.11.4 原理
20.12 性能优化-应用优化
缓存
可以在业务系统中使用redis来做缓存,缓存一些基础性的数据,来
降低关系型数据库的压力,提高访问效率。
全文检索
如果业务系统中的数据量比较大(达到千万级别),这个时候,如果
再对数据库进行查询,特别是进行分页查询,速度将变得很慢(因为
在分页时首先需要count求合计数),为了提高访问效率,这个时候,
可以考虑加入Solr 或者 ElasticSearch全文检索服务,来提高访问效率。
非关系数据库
也可以考虑将非核心(重要)数据,存在 MongoDB 中,这样可以
提高插入以及查询的效率。
想要获取该该课程markdown笔记(脑图+笔记)。可以扫描以下
微信公众号二维码。或者搜索微信公众号-Java大世界。回复
ms即可获取笔记获取方式。