模型性能评价指标之AUC
模型性能评价指标之AUC
一、准确率和召回率
1.1 定义
在讨论ROC之前,先介绍准确率(Precision)和召回率(Recall)的概念。
| - | 预测+ | 预测- |
|---|---|---|
| 真实+ | TP(真正例) | FN(假反例) |
| 真实- | FP(假正例) | TN(真反例) |
准确率P的意义是,预测为+的样本里,真实label为+的样本比例
召回率R的意义是,真实label为+的样本里,预测为+的样本比例
1.2 P-R trade-off
正确率和准确率往往不可兼得,是一对相互矛盾的度量。基于不同的场景,可能会看重P或者R。例如云主机审查用户里的恶意攻击者,就希望P高一些,宁可放过一些,也不能错怪正常用户。而地震预测的场景,就希望R高一些,宁可发出一些错误警报,也不想漏判。
二、ROC和AUC
2.1 真正例率和假正例率
真正例率TPR的意义是,真实label为+的样本里,预测为+的样本比例(就是召回率)
假正例率FPR的意义是,真实label为-的样本里,预测为+的样本比例
ROC曲线和AUC
ROC的全称是Receiver Operating Characteristic曲线,它是以FPR为横轴,TPR为纵轴绘制的曲线,它越靠近左上角,表明模型的性能越好。如果模型A的ROC曲线能完全“包住”模型B的ROC曲线,则可断言A的性能比B好,但是两个模型的ROC往往是相交的,这时为了比较性能就需要用到AUC。
AUC的全称是Area Under Curve,就是ROC曲线和x轴(FPR轴)之间的面积。AUC考虑的是模型预测的排序质量,反映了模型把正例排在反例前面的比例(如果AUC=1,说明模型100%将所有正例排在反例前面)。
ROC曲线绘制
ROC曲线的具体绘制方法是,曲线从坐标(0,0)开始。对于有 M+ M + 个正例和 M− M − 个反例的样本集,根据模型对它们的预测值(概率)倒序排序,同时将阈值设为最大值,之后遍历各样本概率,作为新的阈值,看看在新的阈值下当前样本的label如何,若label为+(说明样本为真正例),则描绘下一个点 (x,y+1M+) ( x , y + 1 M + ) ,若label为-(说明样本为假正例),则描绘下一个点 (x+1M−,y) ( x + 1 M − , y ) 。总之,真正例则曲线往上走,假正例则曲线往右走。
ROC曲线绘制举例
下面给出一个例子,有10个样本,5个正例5个反例,它们的label以及对应的模型预测值如下(暂时不考虑预测值相同的情况),直接观察发现,模型对于正例的预测值都远大于对反例的预测值,该模型很优秀。
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.95]下面这个函数能调用sklearn的roc_curve函数得到FPR和TPR序列,并绘制出来
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
def plot_ROC(t,s):
fpr, tpr, thr = roc_curve(t, s, drop_intermediate=False)
fpr, tpr = [0] + list(fpr), [0] + list(tpr)
plt.plot(fpr, tpr)
plt.show()调用这个函数绘制一下该模型的ROC曲线
plot_ROC(y_true, y_score)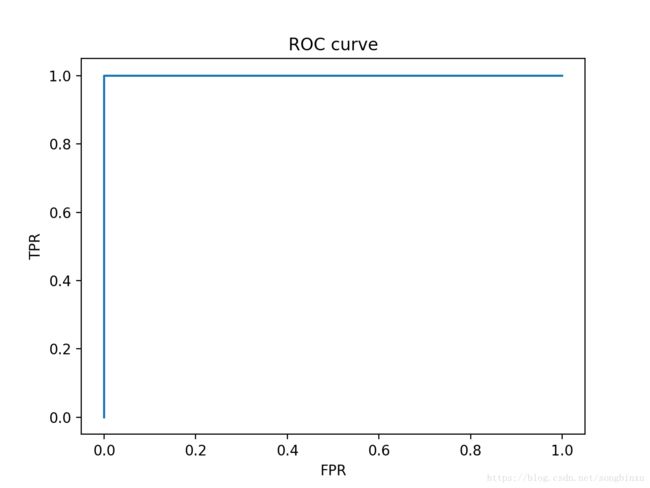
如果模型出了点小问题,对最后一个正例预测值为0.16,可以预计ROC曲线不会变,因为该正例的预测值仍然大于所有反例的预测值。
# 有一点小问题
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.16]
plot_ROC(y_true, y_score)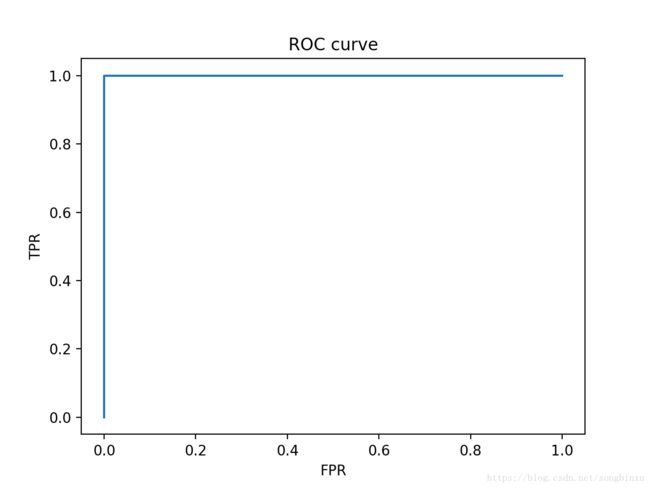
如果模型出的问题有点大,对最后一个正例预测值为0.145,这样就有一个反例被排在一个正例前面,所以可以预测ROC曲线会缺一个角,且该角的面积是0.04。
# 问题稍大
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.145]
plot_ROC(y_true, y_score)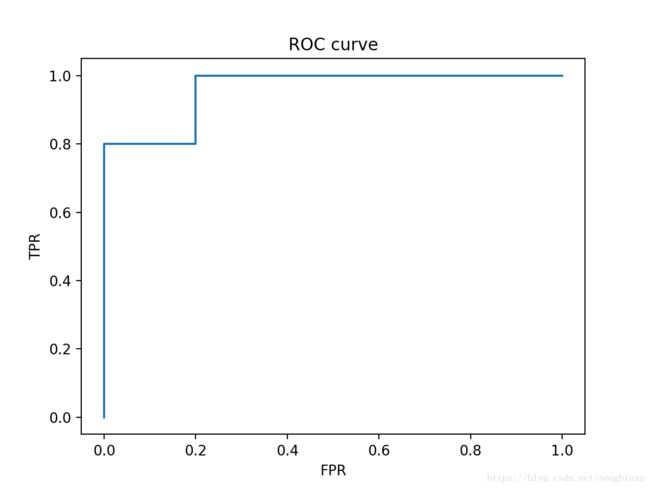
如果模型出的问题很大,对最后一个正例预测值为0.10,这样就有5个反例被排在一个正例前面,所以可以预测ROC曲线会缺一个大角,且该角的面积是0.2。
# 出大问题了
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.10]
plot_ROC(y_true, y_score)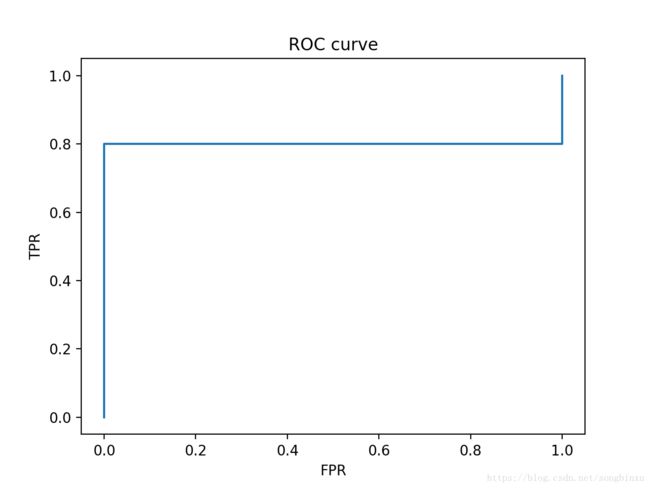
接下来考虑一种特殊的情况,如果最后一个正例的预测值和预测值最大的反例预测值相同会怎么样?例子中预测值最大的反例的预测值是0.15,我们假设最后一个正例的预测值也等于0.15。
# 正反例预测值相同的情况
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.15]
plot_ROC(y_true, y_score)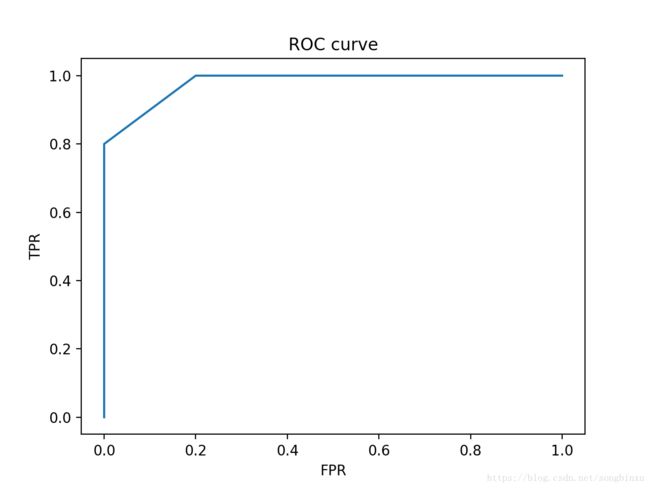
这是怎么回事呢?当阈值下降到0.15时,我们有两个label不同的样例,那么按照ROC曲线绘制的规则,ROC曲线可以“先右再上”,也可以“先上再右”,前者是将正例放在反例后面的结果,而后者是将正例放在反例前面的结果。问题在于,正例和反例的预测值是相同的,凭什么将谁放在谁前面呢?那么公平的做法,就是取一个平均的效果,ROC曲线同时向右和向上,其结果就是图中的“右上”了。从AUC的角度解释,即这个阈值水平下的正例既可能被放在反例前面也可能被放在后面。
那么可不可以默认将具有相同预测值的正例全部排在反例前面,然后按照正常的ROC绘制呢?我认为是不可以的。如果这么做,AUC就会虚高。为什么说虚高,正例竟然会和反例具有一样的预测值,这说明模型有问题,或者特征没提好(可能特征向量完全一致,不具有可分性),还有可能样本是坏样本,“右上”的做法则不偏不倚。
不论如何,只要存在正反例预测值一样的情况,ROC曲线就一定会出现“右上”趋势的斜线,若正例比例大,则斜率偏大,若反例比例大,则斜率偏小。
极端一点,如果所有正反例的预测值都一样,我们应该会得到一条直线 y=x y = x ,这个模型完全没有意义,没有给我们任何信息量,就是在瞎猜。
# 瞎猜
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.1 for _ in range(10)]
plot_ROC(y_true, y_score)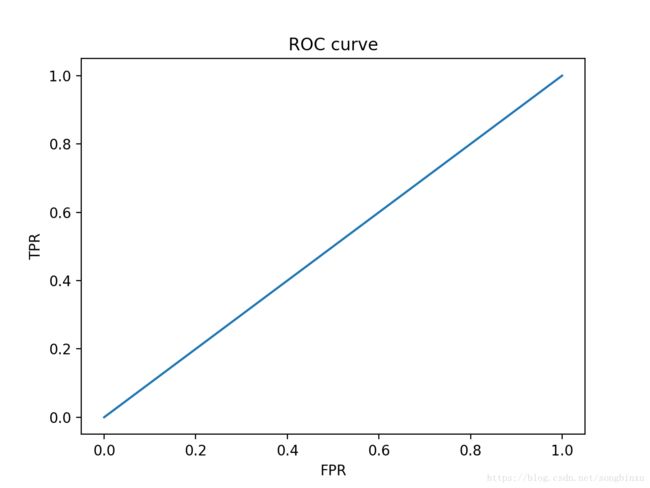
AUC 计算实例
下面这个函数能计算auc
from sklearn.metrics import roc_curve,auc
def compute_auc(t,s):
fpr, tpr, thr = roc_curve(t, s, drop_intermediate=False)
print auc(fpr, tpr)当然sklearn也有自带的,sklearn.metrics.roc_auc_score
# 原始数据
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.95]
compute_auc(y_true, y_score) # should be 1.0# 小问题
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.16]
compute_auc(y_true, y_score) # should be 1.0# 问题有点大
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.145]
compute_auc(y_true, y_score) # should be 0.96# 大问题
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0.11,0.93,0.94,0.14,0.15,0.91,0.12,0.92,0.13,0.1]
compute_auc(y_true, y_score) # should be 0.8# 瞎猜
y_true = [0,1,1,0,0,1,0,1,0,1]
y_score = [0 for _ in range(10)]
compute_auc(y_true, y_score) # should be 0.5在Keras训练中输出AUC
最近在使用Keras时,惊奇地发现Keras并没有自带AUC计算,必须要自己实现一个回调函数CallBacks。想要在每一个epoch结束时,计算验证集的AUC,只需要在on_epoch_end函数中定义计算即可。由于我的输入数据是一个字典,有29维,所以在on_epoch_end中是29。
另外有一点要注意,目前只在fit函数中有效,fit_generator会因为找不到验证集而报错,原因尚未知。
from sklearn.metrics import roc_auc_score
import keras
class RocAucMetricCallback(keras.callbacks.Callback):
def __init__(self, predict_batch_size=5000, include_on_batch=False):
super(RocAucMetricCallback, self).__init__()
self.predict_batch_size=predict_batch_size
self.include_on_batch=include_on_batch
def on_batch_begin(self, batch, logs={}):
pass
def on_batch_end(self, batch, logs={}):
if(self.include_on_batch):
logs['roc_auc_val']=float('-inf')
if(self.validation_data):
logs['roc_auc_val']=roc_auc_score(self.validation_data[1],
self.model.predict(self.validation_data[0],
batch_size=self.predict_batch_size))
def on_train_begin(self, logs={}):
if not ('roc_auc_val' in self.params['metrics']):
self.params['metrics'].append('roc_auc_val')
def on_train_end(self, logs={}):
pass
def on_epoch_begin(self, epoch, logs={}):
pass
def on_epoch_end(self, epoch, logs={}):
logs['roc_auc_val']=float('-inf')
# print len(self.validation_data)
if(self.validation_data):
logs['roc_auc_val']=roc_auc_score(self.validation_data[29],
self.model.predict(self.validation_data[:29],
batch_size=self.predict_batch_size))
print "valid auc={0}".format(logs['roc_auc_val'])
参考资料
【API】sklearn.metrics.roc_curve
【API】sklearn.metrics.auc
【文档】keras Callbacks