当客户端 App 主进程创建 WKWebView 对象时,会创建另外两个子进程:渲染进程与网络进程。主进程 WKWebView 发起请求时,先将请求转发给渲染进程,渲染进程再转发给网络进程,网络进程请求服务器。如果请求的是一个网页,网络进程会将服务器的响应数据 HTML 文件字符流吐给渲染进程。渲染进程拿到 HTML 文件字符流,首先要进行解析,将 HTML 文件字符流转换成 DOM 树,然后在 DOM 树的基础上,进行渲染操作,也就是布局、绘制。最后渲染进程通知主进程 WKWebView 创建对应的 View 展现视图。整个流程如下图所示:

一、什么是DOM树
渲染进程获取到 HTML 文件字符流,会将HTML文件字符流转换成 DOM 树。下图中左侧是一个 HTML 文件,右边就是转换而成的 DOM 树。

可以看到 DOM 树的根节点是 HTMLDocument,代表整个文档。根节点下面的子节点与 HTML 文件中的标签是一一对应的,比如 HTML 中的
标签就对应 DOM 树中的 head 节点。同时 HTML 文件中的文本,也成为 DOM 树中的一个节点,比如文本 'Hello, World!',在 DOM 树中就成为div节点的子节点。在 DOM 树中每一个节点都是具有一定方法与属性的对象,这些对象由对应的类创建出来。比如 HTMLDocument 节点,它对应的类是 class HTMLDocument,下面是 HTMLDocument 的部分源码:
class HTMLDocument : public Document { // 继承自 Document
...
WEBCORE_EXPORT int width();
WEBCORE_EXPORT int height();
...
}从源码中可以看到,HTMLDocument 继承自类 Document,Document 类的部分源码如下:
class Document
: public ContainerNode // Document继承自 ContainerNode,ContainerNode继承自Node
, public TreeScope
, public ScriptExecutionContext
, public FontSelectorClient
, public FrameDestructionObserver
, public Supplementable
, public Logger::Observer
, public CanvasObserver {
WEBCORE_EXPORT ExceptionOr> createElementForBindings(const AtomString& tagName); // 创建Element的方法
WEBCORE_EXPORT Ref createTextNode(const String& data); // 创建文本节点的方法
WEBCORE_EXPORT Ref createComment(const String& data); // 创建注释的方法
WEBCORE_EXPORT Ref createElement(const QualifiedName&, bool createdByParser); // 创建Element方法
....
} 上面源码可以看到 Document 继承自 Node,而且还可以看到前端十分熟悉的 createElement、createTextNode 等方法,JavaScript 对这些方法的调用,最后都转换为对应 C++ 方法的调用。
类 Document 有这些方法,并不是没有原因的,而是 W3C 组织给出的标准规定的,这个标准就是 DOM(Document Object Model,文档对象模型)。DOM 定义了 DOM 树中每个节点需要实现的接口和属性,下面是 HTMLDocument、Document、HTMLDivElement 的部分 IDL(Interactive Data Language,接口描述语言,与具体平台和语言无关)描述,完整的 IDL 可以参看 W3C 。
在 DOM 树中,每一个节点都继承自类 Node,同时 Node 还有一个子类 Element,有的节点直接继承自类 Node,比如文本节点,而有的节点继承自类 Element,比如 div 节点。因此针对上面图中的 DOM 树,执行下面的 JavaScript 语句返回的结果是不一样的:
document.childNodes; // 返回子Node集合,返回DocumentType与HTML节点,都继承自Node
document.children; // 返回子Element集合,只返回HTML节点,DocumentType不继承自Element下图给出部分节点的继承关系图:

二、DOM树构建
DOM 树的构建流程可以分为4个步骤: 解码、分词、创建节点、添加节点。
2.1 解码
渲染进程从网络进程接收过来的是 HTML 字节流,而下一步分词是以字符为单位进行的。由于各种编码规范的存在,比如 ISO-8859-1、UTF-8 等,一个字符常常可能对应一个或者多个编码后的字节,解码的目的就是将 HTML 字节流转换成 HTML 字符流,或者换句话说,就是将原始的 HTML 字节流转换成字符串。

2.1.1 解码类图

从类图上看,类 HTMLDocumentParser 处于解码的核心位置,由这个类调用解码器将 HTML 字节流解码成字符流,存储到类 HTMLInputStream 中。
2.1.2 解码流程

整个解码流程当中,最关健的是如何找到正确的编码方式。只有找到了正确的编码方式,才能使用对应的解码器进行解码。解码发生的地方如下面源代码所示,这个方法在上图第3个栈帧被调用:
// HTMLDocumentParser是DecodedDataDocumentParser的子类
void DecodedDataDocumentParser::appendBytes(DocumentWriter& writer, const uint8_t* data, size_t length)
{
if (!length)
return;
String decoded = writer.decoder().decode(data, length); // 真正解码发生在这里
if (decoded.isEmpty())
return;
writer.reportDataReceived();
append(decoded.releaseImpl());
}上面代码第7行 writer.decoder() 返回一个 TextResourceDecoder 对象,解码操作由 TextResourceDecoder::decode 方法完成。下面逐步查看 TextResourceDecoder::decode 方法的源码:
// 只保留了最重要的部分
String TextResourceDecoder::decode(const char* data, size_t length)
{
...
// 如果是HTML文件,就从head标签中寻找字符集
if ((m_contentType == HTML || m_contentType == XML) && !m_checkedForHeadCharset) // HTML and XML
if (!checkForHeadCharset(data, length, movedDataToBuffer))
return emptyString();
...
// m_encoding存储者从HTML文件中找到的编码名称
if (!m_codec)
m_codec = newTextCodec(m_encoding); // 创建具体的编码器
...
// 解码并返回
String result = m_codec->decode(m_buffer.data() + lengthOfBOM, m_buffer.size() - lengthOfBOM, false, m_contentType == XML && !m_useLenientXMLDecoding, m_sawError);
m_buffer.clear(); // 清空存储的原始未解码的HTML字节流
return result;
}从源码中可以看到,TextResourceDecoder 首先从 HTML 的
标签中去找编码方式,因为 标签可以包含 标签, 标签可以设置 HTML 文件的字符集:
DOM Tree
如果能找到对应的字符集,TextResourceDeocder 将其存储在成员变量 m\_encoding 当中,并且根据对应的编码创建真正的解码器存储在成员变量 m\_codec 中,最终使用 m\_codec 对字节流进行解码,并且返回解码后的字符串。如果带有字符集的 标签没有找到,TextResourceDeocder 的 m\_encoding 有默认值 windows-1252(等同于ISO-8859-1)。
下面看一下 TextResourceDecoder 寻找 标签中字符集的流程,也就是上面源码中第8行对 checkForHeadCharset 函数的调用:
// 只保留了关健代码
bool TextResourceDecoder::checkForHeadCharset(const char* data, size_t len, bool& movedDataToBuffer)
{
...
// This is not completely efficient, since the function might go
// through the HTML head several times.
size_t oldSize = m_buffer.size();
m_buffer.grow(oldSize + len);
memcpy(m_buffer.data() + oldSize, data, len); // 将字节流数据拷贝到自己的缓存m_buffer里面
movedDataToBuffer = true;
// Continue with checking for an HTML meta tag if we were already doing so.
if (m_charsetParser)
return checkForMetaCharset(data, len); // 如果已经存在了meta标签解析器,直接开始解析
....
m_charsetParser = makeUnique(); // 创建meta标签解析器
return checkForMetaCharset(data, len);
} 上面源代码中第11行,类 TextResourceDecoder 内部存储了需要解码的 HTML 字节流,这一步骤很重要,后面会讲到。先看第17行、21行、22行,这3行主要是使用标签解析器解析字符集,使用了懒加载的方式。下面看下 checkForMetaCharset 这个函数的实现:
bool TextResourceDecoder::checkForMetaCharset(const char* data, size_t length)
{
if (!m_charsetParser->checkForMetaCharset(data, length)) // 解析meta标签字符集
return false;
setEncoding(m_charsetParser->encoding(), EncodingFromMetaTag); // 找到后设置字符编码名称
m_charsetParser = nullptr;
m_checkedForHeadCharset = true;
return true;
}上面源码第3行可以看到,整个解析 标签的任务在类 HTMLMetaCharsetParser::checkForMetaCharset 中完成。
// 只保留了关健代码
bool HTMLMetaCharsetParser::checkForMetaCharset(const char* data, size_t length)
{
if (m_doneChecking) // 标志位,避免重复解析
return true;
// We still don't have an encoding, and are in the head.
// The following tags are allowed in :
// SCRIPT|STYLE|META|LINK|OBJECT|TITLE|BASE
//
// We stop scanning when a tag that is not permitted in
// is seen, rather when is seen, because that more closely
// matches behavior in other browsers; more details in
// .
//
// Additionally, we ignore things that looks like tags in , <script>
// and <noscript>; see <http://bugs.webkit.org/show_bug.cgi?id=4560>,
// <http://bugs.webkit.org/show_bug.cgi?id=12165> and
// <http://bugs.webkit.org/show_bug.cgi?id=12389>.
//
// Since many sites have charset declarations after <body> or other tags
// that are disallowed in <head>, we don't bail out until we've checked at
// least bytesToCheckUnconditionally bytes of input.
constexpr int bytesToCheckUnconditionally = 1024; // 如果解析了1024个字符还未找到带有字符集的<meta>标签,整个解析也算完成,此时没有解析到正确的字符集,就使用默认编码windows-1252(等同于ISO-8859-1)
bool ignoredSawErrorFlag;
m_input.append(m_codec->decode(data, length, false, false, ignoredSawErrorFlag)); // 对字节流进行解码
while (auto token = m_tokenizer.nextToken(m_input)) { // m_tokenizer进行分词操作,找meta标签也需要进行分词,分词操作后面讲
bool isEnd = token->type() == HTMLToken::EndTag;
if (isEnd || token->type() == HTMLToken::StartTag) {
AtomString tagName(token->name());
if (!isEnd) {
m_tokenizer.updateStateFor(tagName);
if (tagName == metaTag && processMeta(*token)) { // 找到meta标签进行处理
m_doneChecking = true;
return true; // 如果找到了带有编码的meta标签,直接返回
}
}
if (tagName != scriptTag && tagName != noscriptTag
&& tagName != styleTag && tagName != linkTag
&& tagName != metaTag && tagName != objectTag
&& tagName != titleTag && tagName != baseTag
&& (isEnd || tagName != htmlTag)
&& (isEnd || tagName != headTag)) {
m_inHeadSection = false;
}
}
if (!m_inHeadSection && m_input.numberOfCharactersConsumed() >= bytesToCheckUnconditionally) { // 如果分词已经进入了<body>标签范围,同时分词数量已经超过了1024,也算成功
m_doneChecking = true;
return true;
}
}
return false;
}</code></pre>
<p>上面源码第29行,类 HTMLMetaCharsetParser 也有一个解码器 m\_codec,解码器是在 HTMLMetaCharsetParser 对象创建时生成,这个解码器的真实类型是 TextCodecLatin1(Latin1编码也就是ISO-8859-1,等同于windows-1252编码)。之所以可以直接使用 TextCodecLatin1 解码器,是因为 <meta> 标签如果设置正确,都是英文字符,完全可以使用 TextCodecLatin1 进行解析出来。这样就避免了为了找到 <meta> 标签,需要对字节流进行解码,而要解码就必须要找到 <meta> 标签这种鸡生蛋、蛋生鸡的问题。</p>
<p>代码第37行对找到的 <meta> 标签进行处理,这个函数比较简单,主要是解析 <meta> 标签当中的属性,然后查看这些属性名中有没有 charset。</p>
<pre><code>bool HTMLMetaCharsetParser::processMeta(HTMLToken& token)
{
AttributeList attributes;
for (auto& attribute : token.attributes()) { // 获取meta标签属性
String attributeName = StringImpl::create8BitIfPossible(attribute.name);
String attributeValue = StringImpl::create8BitIfPossible(attribute.value);
attributes.append(std::make_pair(attributeName, attributeValue));
}
m_encoding = encodingFromMetaAttributes(attributes); // 从属性中找字符集设置属性charset
return m_encoding.isValid();
}</code></pre>
<p>上面分析 TextResourceDecoder::checkForHeadCharset 函数时,讲过第11行 TextResourceDecoder 类存储 HTML 字节流的操作很重要。原因是可能整个 HTML 字节流里面可能确实没有设置 charset 的 <meta> 标签,此时 TextResourceDecoder::checkForHeadCharset 函数就要返回 false,导致 TextResourceDecoder::decode 函数返回空字符串,也就是不进行任何解码。是不是这样呢?真实的情况是,在接收HTML字节流整个过程中由于确实没有找到带有 charset 属性的 <meta> 标签,那么整个接收期间都不会解码。但是完整的 HTML 字节流会被存储在 TextResourceDecoder 的成员变量 m\_buffer 里面,当整个 HTML 字节流接收结束的时,会有如下调用栈:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/82e85bbfc70d4aa49280f7e360e35ca8.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第7张图片" title="图片" src="http://img.e-com-net.com/image/info9/82e85bbfc70d4aa49280f7e360e35ca8.jpg" width="650" height="295" style="border:1px solid black;"></a></span></p>
<p>从调用栈可以看到,当 HTML 字节流接收完成,最终会调用 TextResourceDecoder::flush 方法,这个方法会将 TextResourceDecoder 中有 m\_buffer 存储的 HTML 字节流进行解码,由于在接收 HTML 字节流期间未成功找到编码方式,因此 m\_buffer 里面存储的就是所有待解码的 HTML 字节流,然后在这里使用默认的编码 windows-1252 对全部字节流进行解码。因此,如果 HTML 字节流中包含汉字,那么如果不指定字符集,最终页面就会出现乱码。解码完成后,会将解码之后的字符流存储到 HTMLDocumentParser 中。</p>
<pre><code>void DecodedDataDocumentParser::flush(DocumentWriter& writer)
{
String remainingData = writer.decoder().flush();
if (remainingData.isEmpty())
return;
writer.reportDataReceived();
append(remainingData.releaseImpl()); // 解码后的字符流存储到HTMLDocumentParser
}</code></pre>
<h3><strong>2.1.3 解码总结</strong></h3>
<p>整个解码过程可以分为两种情形: 第一种情形是 HTML 字节流可以解析出带有 charset 属性的 <meta> 标签,这样就可以获取相应的编码方式,那么每接收到一个 HML 字节流,都可以使用相应的编码方式进行解码,将解码后的字符流添加到 HTMLInputStream 当中;第二种是 HTML 字节流不能解析带有 charset 属性的 <meta> 标签,这样每接收到一个 HTML 字节流,都缓存到 TextResourceDecoder 的 m\_buffer 缓存,等完整的 HTML 字节流接收完毕,就会使用默认的编码 windows-1252 进行解码。</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/94926cf0a1d5435a97917ed500bc29c8.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第8张图片" title="图片" src="http://img.e-com-net.com/image/info9/94926cf0a1d5435a97917ed500bc29c8.jpg" width="650" height="258" style="border:1px solid black;"></a></span></p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/4b365ed175ef49d7afab17d946f9e488.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第9张图片" title="图片" src="http://img.e-com-net.com/image/info9/4b365ed175ef49d7afab17d946f9e488.jpg" width="650" height="210" style="border:1px solid black;"></a></span></p>
<h2><strong>2.2 分词</strong></h2>
<p>接收到的 HTML 字节流经过解码,成为存储在 HTMLInputStream 中的字符流。分词的过程就是从 HTMLInputStream 中依次取出每一个字符,然后判断字符是否是特殊的 HTML 字符' <'、'/'、'>'、'=' 等。根据这些特殊字符的分割,就能解析出 HTML 标签名以及属性列表,类 HTMLToken 就是存储分词出来的结果。</p>
<h3><strong>2.2.1 分词类图</strong></h3>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/7793a104f93140198132a87537f45269.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第10张图片" title="图片" src="http://img.e-com-net.com/image/info9/7793a104f93140198132a87537f45269.jpg" width="650" height="266" style="border:1px solid black;"></a></span></p>
<p>从类图中可以看到,分词最重要的是类 HTMLTokenizer 和类 HTMLToken。下面是类 HTMLToken 的主要信息:</p>
<pre><code>// 只保留了主要信息
class HTMLToken {
public:
enum Type { // Token的类型
Uninitialized, // Token初始化时的类型
DOCTYPE, // 代表Token是DOCType标签
StartTag, // 代表Token是一个开始标签
EndTag, // 代表Token是一个结束标签
Comment, // 代表Token是一个注释
Character, // 代表Token是文本
EndOfFile, // 代表Token是文件结尾
};
struct Attribute { // 存储属性的数据结构
Vector<UChar, 32> name; // 属性名
Vector<UChar, 64> value; // 属性值
// Used by HTMLSourceTracker.
unsigned startOffset;
unsigned endOffset;
};
typedef Vector<Attribute, 10> AttributeList; // 属性列表
typedef Vector<UChar, 256> DataVector; // 存储Token名
...
private:
Type m_type;
DataVector m_data;
// For StartTag and EndTag
bool m_selfClosing; // Token是注入<img>一样自结束标签
AttributeList m_attributes;
Attribute* m_currentAttribute; // 当前正在解析的属性
};</code></pre>
<h3><strong>2.2.2 分词流程</strong></h3>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/739132e82a154c4688b978fbe6c52d30.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第11张图片" title="图片" src="http://img.e-com-net.com/image/info9/739132e82a154c4688b978fbe6c52d30.jpg" width="650" height="339" style="border:1px solid black;"></a></span></p>
<p>上面分词流程中 HTMLDocumentParser::pumpTokenizerLoop 方法是最重要的,从方法名字可以看出这个方法里面包含循环逻辑:</p>
<pre><code>// 只保留关健代码
bool HTMLDocumentParser::pumpTokenizerLoop(SynchronousMode mode, bool parsingFragment, PumpSession& session)
{
do { // 分词循环体开始
...
if (UNLIKELY(mode == AllowYield && m_parserScheduler->shouldYieldBeforeToken(session))) // 避免长时间处于分词循环中,这里根据条件暂时退出循环
return true;
if (!parsingFragment)
m_sourceTracker.startToken(m_input.current(), m_tokenizer);
auto token = m_tokenizer.nextToken(m_input.current()); // 进行分词操作,取出一个token
if (!token)
return false; // 分词没有产生token,就跳出循环
if (!parsingFragment)
m_sourceTracker.endToken(m_input.current(), m_tokenizer);
constructTreeFromHTMLToken(token); // 根据token构建DOM树
} while (!isStopped());
return false;
}</code></pre>
<p>上面代码中第7行会有一个 yield 退出操作,这是为了避免长时间处于分词循环,占用主线程。当退出条件为真时,会从分词循环中返回,返回值为 true。下面是退出判断代码:</p>
<pre><code>// 只保留关健代码
bool HTMLParserScheduler::shouldYieldBeforeToken(PumpSession& session)
{
...
// numberOfTokensBeforeCheckingForYield是静态变量,定义为4096
// session.processedTokensOnLastCheck表示从上一次退出为止,以及处理过的token个数
// session.didSeeScript表示在分词过程中是否出现过script标签
if (UNLIKELY(session.processedTokens > session.processedTokensOnLastCheck + numberOfTokensBeforeCheckingForYield || session.didSeeScript))
return checkForYield(session);
++session.processedTokens;
return false;
}
bool HTMLParserScheduler::checkForYield(PumpSession& session)
{
session.processedTokensOnLastCheck = session.processedTokens;
session.didSeeScript = false;
Seconds elapsedTime = MonotonicTime::now() - session.startTime;
return elapsedTime > m_parserTimeLimit; // m_parserTimeLimit的值默认是500ms,从分词开始超过500ms就要先yield
}</code></pre>
<p>如果命中了上面的 yield 退出条件,那么什么时候再次进入分词呢?下面的代码展示了再次进入分词的过程:</p>
<pre><code>// 保留关键代码
void HTMLDocumentParser::pumpTokenizer(SynchronousMode mode)
{
...
if (shouldResume) // 从pumpTokenizerLoop中yield退出时返回值为true
m_parserScheduler->scheduleForResume();
}
void HTMLParserScheduler::scheduleForResume()
{
ASSERT(!m_suspended);
m_continueNextChunkTimer.startOneShot(0_s); // 触发timer(0s后触发),触发后的响应函数为HTMLParserScheduler::continueNextChunkTimerFired
}
// 保留关健代码
void HTMLParserScheduler::continueNextChunkTimerFired()
{
...
m_parser.resumeParsingAfterYield(); // 重新Resume分词过程
}
void HTMLDocumentParser::resumeParsingAfterYield()
{
// pumpTokenizer can cause this parser to be detached from the Document,
// but we need to ensure it isn't deleted yet.
Ref<HTMLDocumentParser> protectedThis(*this);
// We should never be here unless we can pump immediately.
// Call pumpTokenizer() directly so that ASSERTS will fire if we're wrong.
pumpTokenizer(AllowYield); // 重新进入分词过程,该函数会调用pumpTokenizerLoop
endIfDelayed();
}</code></pre>
<p>从上面代码可以看出,再次进入分词过程是通过触发一个 Timer 来实现的,虽然这个 Timer 在0s后触发,但是并不意味着 Timer 的响应函数会立刻执行。如果在此之前主线程已经有其他任务到达了执行时机,会有被执行的机会。</p>
<p>继续看 HTMLDocumentParser::pumpTokenizerLoop 函数的第13行,这一行进行分词操作,从解码后的字符流中分出一个 token。实现分词的代码位于 HTMLTokenizer::processToken:</p>
<pre><code>// 只保留关键代码
bool HTMLTokenizer::processToken(SegmentedString& source)
{
...
if (!m_preprocessor.peek(source, isNullCharacterSkippingState(m_state))) // 取出source内部指向的字符,赋给m_nextInputCharacter
return haveBufferedCharacterToken();
UChar character = m_preprocessor.nextInputCharacter(); // 获取character
// https://html.spec.whatwg.org/#tokenization
switch (m_state) { // 进行状态转换,m_state初始值为DataState
...
}
return false;
}</code></pre>
<p>这个方法由于内部要做很多状态转换,总共有1200多行,后面会有4个例子来解释状态转换的逻辑。</p>
<p>首先来看 InputStreamPreprocessor::peek 方法:</p>
<pre><code>// Returns whether we succeeded in peeking at the next character.
// The only way we can fail to peek is if there are no more
// characters in |source| (after collapsing \r\n, etc).
ALWAYS_INLINE bool InputStreamPreprocessor::peek(SegmentedString& source, bool skipNullCharacters = false)
{
if (UNLIKELY(source.isEmpty()))
return false;
m_nextInputCharacter = source.currentCharacter(); // 获取字符流source内部指向的当前字符
// Every branch in this function is expensive, so we have a
// fast-reject branch for characters that don't require special
// handling. Please run the parser benchmark whenever you touch
// this function. It's very hot.
constexpr UChar specialCharacterMask = '\n' | '\r' | '\0';
if (LIKELY(m_nextInputCharacter & ~specialCharacterMask)) {
m_skipNextNewLine = false;
return true;
}
return processNextInputCharacter(source, skipNullCharacters); // 跳过空字符,将\r\n换行符合并成\n
}
bool InputStreamPreprocessor::processNextInputCharacter(SegmentedString& source, bool skipNullCharacters)
{
ProcessAgain:
ASSERT(m_nextInputCharacter == source.currentCharacter());
// 针对\r\n换行符,下面if语句处理\r字符并且设置m_skipNextNewLine=true,后面处理\n就直接忽略
if (m_nextInputCharacter == '\n' && m_skipNextNewLine) {
m_skipNextNewLine = false;
source.advancePastNewline(); // 向前移动字符
if (source.isEmpty())
return false;
m_nextInputCharacter = source.currentCharacter();
}
// 如果是\r\n连续的换行符,那么第一次遇到\r字符,将\r字符替换成\n字符,同时设置标志m_skipNextNewLine=true
if (m_nextInputCharacter == '\r') {
m_nextInputCharacter = '\n';
m_skipNextNewLine = true;
return true;
}
m_skipNextNewLine = false;
if (m_nextInputCharacter || isAtEndOfFile(source))
return true;
// 跳过空字符
if (skipNullCharacters && !m_tokenizer.neverSkipNullCharacters()) {
source.advancePastNonNewline();
if (source.isEmpty())
return false;
m_nextInputCharacter = source.currentCharacter();
goto ProcessAgain; // 跳转到开头
}
m_nextInputCharacter = replacementCharacter;
return true;
}</code></pre>
<p>由于 peek 方法会跳过空字符,同时合并 \r\n 字符为 \n 字符,所以一个字符流 source 如果包含了空格或者 \r\n 换行符,实际上处理起来如下图所示:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/ec1e3624872e4b7da43662a40c2e1340.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第12张图片" title="图片" src="http://img.e-com-net.com/image/info9/ec1e3624872e4b7da43662a40c2e1340.jpg" width="650" height="173" style="border:1px solid black;"></a></span></p>
<p>HTMLTokenizer::processToken 内部定义了一个状态机,下面以四种情形来进行解释。</p>
<p><strong>Case1:标签</strong></p>
<pre><code>BEGIN_STATE(DataState) // 刚开始解析是DataState状态if (character == '&') ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInDataState);if (character == '<') {// 整个字符流一开始是'<',那么表示是一个标签的开始if (haveBufferedCharacterToken()) RETURN_IN_CURRENT_STATE(true); ADVANCE_PAST_NON_NEWLINE_TO(TagOpenState); // 跳转到TagOpenState状态,并取去下一个字符是'!" }if (character == kEndOfFileMarker)return emitEndOfFile(source); bufferCharacter(character); ADVANCE_TO(DataState);END_STATE()// ADVANCE_PAST_NON_NEWLINE_TO定义#define ADVANCE_PAST_NON_NEWLINE_TO(newState) \do { \if (!m_preprocessor.advancePastNonNewline(source, isNullCharacterSkippingState(newState))) { \ // 如果往下移动取不到下一个字符 m_state = newState; \ // 保存状态return haveBufferedCharacterToken(); \ // 返回 } \ character = m_preprocessor.nextInputCharacter(); \ // 先取出下一个字符 goto newState; \ // 跳转到指定状态 } while (false)BEGIN_STATE(TagOpenState)if (character == '!') // 满足此条件 ADVANCE_PAST_NON_NEWLINE_TO(MarkupDeclarationOpenState); // 同理,跳转到MarkupDeclarationOpenState状态,并且取出下一个字符'D'if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(EndTagOpenState);if (isASCIIAlpha(character)) { m_token.beginStartTag(convertASCIIAlphaToLower(character)); ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); }if (character == '?') { parseError();// The spec consumes the current character before switching// to the bogus comment state, but it's easier to implement// if we reconsume the current character. RECONSUME_IN(BogusCommentState); } parseError(); bufferASCIICharacter('<'); RECONSUME_IN(DataState);END_STATE()BEGIN_STATE(MarkupDeclarationOpenState)if (character == '-') { auto result = source.advancePast("--");if (result == SegmentedString::DidMatch) { m_token.beginComment(); SWITCH_TO(CommentStartState); }if (result == SegmentedString::NotEnoughCharacters) RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); } else if (isASCIIAlphaCaselessEqual(character, 'd')) { // 由于character == 'D',满足此条件 auto result = source.advancePastLettersIgnoringASCIICase("doctype"); // 看解码后的字符流中是否有完整的"doctype"if (result == SegmentedString::DidMatch) SWITCH_TO(DOCTYPEState); // 如果匹配,则跳转到DOCTYPEState,同时取出当前指向的字符,由于上面source字符流已经移动了"doctype",因此此时取出的字符为'>'if (result == SegmentedString::NotEnoughCharacters) // 如果不匹配 RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); // 保存状态,直接返回 } else if (character == '[' && shouldAllowCDATA()) { auto result = source.advancePast("[CDATA[");if (result == SegmentedString::DidMatch) SWITCH_TO(CDATASectionState);if (result == SegmentedString::NotEnoughCharacters) RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); } parseError(); RECONSUME_IN(BogusCommentState);END_STATE()#define SWITCH_TO(newState) \do { \if (!m_preprocessor.peek(source, isNullCharacterSkippingState(newState))) { \ m_state = newState; \return haveBufferedCharacterToken(); \ } \ character = m_preprocessor.nextInputCharacter(); \ // 取出下一个字符 goto newState; \ // 跳转到指定的state } while (false)#define RETURN_IN_CURRENT_STATE(expression) \do { \ m_state = currentState; \ // 保存当前状态return expression; \ } while (false)BEGIN_STATE(DOCTYPEState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeDOCTYPENameState);if (character == kEndOfFileMarker) { parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndReconsumeInDataState(); } parseError(); RECONSUME_IN(BeforeDOCTYPENameState);END_STATE()#define RECONSUME_IN(newState) \do { \ // 直接跳转到指定state goto newState; \ } while (false) BEGIN_STATE(BeforeDOCTYPENameState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeDOCTYPENameState);if (character == '>') { // character == '>',匹配此处,到此DOCTYPE标签匹配完毕 parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) { parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndReconsumeInDataState(); } m_token.beginDOCTYPE(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(DOCTYPENameState);END_STATE()inline bool HTMLTokenizer::emitAndResumeInDataState(SegmentedString& source){ saveEndTagNameIfNeeded(); m_state = DataState; // 重置状态为初始状态DataState source.advancePastNonNewline(); // 移动到下一个字符return true;}</code></pre>
<p>DOCTYPE Token 经历了6个状态最终被解析出来,整个过程如下图所示:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/1f79c943c4ba4565991fbb62ce23c918.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第13张图片" title="图片" src="http://img.e-com-net.com/image/info9/1f79c943c4ba4565991fbb62ce23c918.jpg" width="650" height="228" style="border:1px solid black;"></a></span></p>
<p>当 Token 解析完毕之后,分词状态又被重置为 DataState,同时需要注意的时,此时字符流 source 内部指向的是下一个字符 '<'。</p>
<p>上面代码第61行在用字符流 source 匹配字符串 "doctype" 时,可能出现匹配不上的情形。为什么会这样呢?这是因为整个 DOM 树的构建流程,并不是先要解码完成,解码完成之后获取到完整的字符流才进行分词。从前面解码可以知道,解码可能是一边接收字节流,一边进行解码的,因此分词也是这样,只要能解码出一段字符流,就会立即进行分词。整个流程会出现如下图所示:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/f65df0580ae344cb9ff83a3f6c4ce30d.jpg" target="_blank"><img class="lazy" alt="图片" title="图片" src="http://img.e-com-net.com/image/info9/f65df0580ae344cb9ff83a3f6c4ce30d.jpg" width="650" height="72"></a></span></p>
<p>由于这个原因,用来分词的字符流可能是不完整的。对于出现不完整情形的 DOCTYPE 分词过程如下图所示:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/5ce35d9eda4d447ea789a239369d25bc.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第14张图片" title="图片" src="http://img.e-com-net.com/image/info9/5ce35d9eda4d447ea789a239369d25bc.jpg" width="650" height="512" style="border:1px solid black;"></a></span></p>
<p>上面介绍了解码、分词、解码、分词处理 DOCTYPE 标签的情形,可以看到从逻辑上这种情形与完整解码再分词是一样的。后续介绍时都会只针对完整解码再分词的情形,对于一边解码一边分词的情形,只需要正确的认识 source 字符流内部指针的移动,并不难分析。</p>
<p><strong>Case2:标签</strong></p>
<p><html> 标签的分词过程和 <!DOCTYPE> 类似,其相关代码如下:</p>
<pre><code>BEGIN_STATE(TagOpenState)
if (character == '!')
ADVANCE_PAST_NON_NEWLINE_TO(MarkupDeclarationOpenState);
if (character == '/')
ADVANCE_PAST_NON_NEWLINE_TO(EndTagOpenState);
if (isASCIIAlpha(character)) { // 在开标签状态下,当前字符为'h'
m_token.beginStartTag(convertASCIIAlphaToLower(character)); // 将'h'添加到Token名中
ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); // 跳转到TagNameState,并移动到下一个字符't'
}
if (character == '?') {
parseError();
// The spec consumes the current character before switching
// to the bogus comment state, but it's easier to implement
// if we reconsume the current character.
RECONSUME_IN(BogusCommentState);
}
parseError();
bufferASCIICharacter('<');
RECONSUME_IN(DataState);
END_STATE()
BEGIN_STATE(TagNameState)
if (isTokenizerWhitespace(character))
ADVANCE_TO(BeforeAttributeNameState);
if (character == '/')
ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);
if (character == '>') // 在这个状态下遇到起始标签终止字符
return emitAndResumeInDataState(source); // 当前分词结束,重置分词状态为DataState
if (m_options.usePreHTML5ParserQuirks && character == '<')
return emitAndReconsumeInDataState();
if (character == kEndOfFileMarker) {
parseError();
RECONSUME_IN(DataState);
}
m_token.appendToName(toASCIILower(character)); // 将当前字符添加到Token名
ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); // 继续跳转到当前状态,并移动到下一个字符
END_STATE()</code></pre>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/7786dfb9ce524e7d965eace5b0e9669a.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第15张图片" title="图片" src="http://img.e-com-net.com/image/info9/7786dfb9ce524e7d965eace5b0e9669a.jpg" width="650" height="272" style="border:1px solid black;"></a></span> </p>
<p><strong>Case3:带有属性的标签 <div></strong></p>
<p>HTML 标签可以带有属性,属性由属性名和属性值组成,属性之间以及属性与标签名之间用空格分隔:</p>
<pre><code><!-- div标签有两个属性,属性名为class和align,它们的值都带有引号 -->
<div class="news" align="center">Hello,World!</div>
<!-- 属性值也可以不带引号 -->
<div class=news align=center>Hello,World!</div></code></pre>
<p>整个 <div> 标签的解析中,标签名 div 的解析流程和上面的 <html> 标签解析一样,当在解析标签名的过程中,碰到了空白字符,说明要开始解析属性了,下面是相关代码:</p>
<pre><code>BEGIN_STATE(TagNameState)if (isTokenizerWhitespace(character)) // 在解析TagName时遇到空白字符,标志属性开始 ADVANCE_TO(BeforeAttributeNameState);if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); } m_token.appendToName(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(TagNameState);END_STATE()#define ADVANCE_TO(newState) \do { \if (!m_preprocessor.advance(source, isNullCharacterSkippingState(newState))) { \ // 移动到下一个字符 m_state = newState; \return haveBufferedCharacterToken(); \ } \ character = m_preprocessor.nextInputCharacter(); \ goto newState; \ // 跳转到指定状态 } while (false)BEGIN_STATE(BeforeAttributeNameState)if (isTokenizerWhitespace(character)) // 如果标签名后有连续空格,那么就不停的跳过,在当前状态不停循环 ADVANCE_TO(BeforeAttributeNameState);if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); }if (character == '"' || character == '\'' || character == '<' || character == '=') parseError(); m_token.beginAttribute(source.numberOfCharactersConsumed()); // Token的属性列表增加一个,用来存放新的属性名与属性值 m_token.appendToAttributeName(toASCIILower(character)); // 添加属性名 ADVANCE_PAST_NON_NEWLINE_TO(AttributeNameState); // 跳转到AttributeNameState,并且移动到下一个字符END_STATE()BEGIN_STATE(AttributeNameState)if (isTokenizerWhitespace(character)) ADVANCE_TO(AfterAttributeNameState);if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '=') ADVANCE_PAST_NON_NEWLINE_TO(BeforeAttributeValueState); // 在解析属性名的过程中如果碰到=,说明属性名结束,属性值就要开始if (character == '>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); }if (character == '"' || character == '\'' || character == '<' || character == '=') parseError(); m_token.appendToAttributeName(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(AttributeNameState);END_STATE()BEGIN_STATE(BeforeAttributeValueState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeAttributeValueState);if (character == '"') ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueDoubleQuotedState); // 有的属性值有引号包围,这里跳转到AttributeValueDoubleQuotedState,并移动到下一个字符if (character == '&') RECONSUME_IN(AttributeValueUnquotedState);if (character == '\'') ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueSingleQuotedState);if (character == '>') { parseError();return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); }if (character == '<' || character == '=' || character == '`') parseError(); m_token.appendToAttributeValue(character); // 有的属性值没有引号包围,添加属性值字符到Token ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueUnquotedState); // 跳转到AttributeValueUnquotedState,并移动到下一个字符END_STATE()BEGIN_STATE(AttributeValueDoubleQuotedState)if (character == '"') { // 在当前状态下如果遇到引号,说明属性值结束 m_token.endAttribute(source.numberOfCharactersConsumed()); // 结束属性解析 ADVANCE_PAST_NON_NEWLINE_TO(AfterAttributeValueQuotedState); // 跳转到AfterAttributeValueQuotedState,并移动到下一个字符 }if (character == '&') { m_additionalAllowedCharacter = '"'; ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInAttributeValueState); }if (character == kEndOfFileMarker) { parseError(); m_token.endAttribute(source.numberOfCharactersConsumed()); RECONSUME_IN(DataState); } m_token.appendToAttributeValue(character); // 将属性值字符添加到Token ADVANCE_TO(AttributeValueDoubleQuotedState); // 跳转到当前状态END_STATE()BEGIN_STATE(AfterAttributeValueQuotedState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeAttributeNameState); // 属性值解析完毕,如果后面继续跟着空白字符,说明后续还有属性要解析,调回到BeforeAttributeNameStateif (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '>')return emitAndResumeInDataState(source); // 属性值解析完毕,如果遇到'>'字符,说明整个标签也要解析完毕了,此时结束当前标签解析,并且重置分词状态为DataState,并移动到下一个字符if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); } parseError(); RECONSUME_IN(BeforeAttributeNameState);END_STATE()BEGIN_STATE(AttributeValueUnquotedState)if (isTokenizerWhitespace(character)) { // 当解析不带引号的属性值时遇到空白字符(这与带引号的属性值不一样,带引号的属性值可以包含空白字符),说明当前属性解析完毕,后面还有其他属性,跳转到BeforeAttributeNameState,并且移动到下一个字符 m_token.endAttribute(source.numberOfCharactersConsumed()); ADVANCE_TO(BeforeAttributeNameState); }if (character == '&') { m_additionalAllowedCharacter = '>'; ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInAttributeValueState); }if (character == '>') { // 解析过程中如果遇到'>'字符,说明整个标签也要解析完毕了,此时结束当前标签解析,并且重置分词状态为DataState,并移动到下一个字符 m_token.endAttribute(source.numberOfCharactersConsumed());return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) { parseError(); m_token.endAttribute(source.numberOfCharactersConsumed()); RECONSUME_IN(DataState); }if (character == '"' || character == '\'' || character == '<' || character == '=' || character == '`') parseError(); m_token.appendToAttributeValue(character); // 将遇到的属性值字符添加到Token ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueUnquotedState); // 跳转到当前状态,并且移动到下一个字符END_STATE()</code></pre>
<p>从代码中可以看到,当属性值带引号和不带引号时,解析的逻辑是不一样的。当属性值带有引号时,属性值里面是可以包含空白字符的。如果属性值不带引号,那么一旦碰到空白字符,说明这个属性就解析结束了,会进入下一个属性的解析当中。</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/b8d2e94699bb4d9ea7dab3d1defacb18.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第16张图片" title="图片" src="http://img.e-com-net.com/image/info9/b8d2e94699bb4d9ea7dab3d1defacb18.jpg" width="514" height="732" style="border:1px solid black;"></a></span></p>
<p><strong>Case4:纯文本解析</strong></p>
<p>这里的纯文本指起始标签与结束标签之间的任何纯文字,包括脚本文、CSS 文本等等,如下所示:</p>
<pre><code><!-- div标签中的纯文本 Hello,Word! -->
<div class=news align=center>Hello,World!</div>
<!-- script标签中的纯文本 window.name = 'Lucy'; -->
<script>window.name = 'Lucy';</script></code></pre>
<p>纯文本的解析过程比较简单,就是不停的在 DataState 状态上跳转,缓存遇到的字符,直到遇见一个结束标签的 '<' 字符,相关代码如下:</p>
<pre><code>BEGIN_STATE(DataState)
if (character == '&')
ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInDataState);
if (character == '<') { // 如果在解析文本的过程中遇到开标签,分两种情况
if (haveBufferedCharacterToken()) // 第一种,如果缓存了文本字符就直接按当前DataState返回,并不移动字符,所以下次再进入分词操作时取到的字符仍为'<'
RETURN_IN_CURRENT_STATE(true);
ADVANCE_PAST_NON_NEWLINE_TO(TagOpenState); // 第二种,如果没有缓存任何文本字符,直接进入TagOpenState状态,进入到起始标签解析过程,并且移动下一个字符
}
if (character == kEndOfFileMarker)
return emitEndOfFile(source);
bufferCharacter(character); // 缓存遇到的字符
ADVANCE_TO(DataState); // 循环跳转到当前DataState状态,并且移动到下一个字符
END_STATE()</code></pre>
<p>由于流程比较简单,下面只给出解析div标签中纯文本的结果:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/428776287931417c82089109efbb701a.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第17张图片" title="图片" src="http://img.e-com-net.com/image/info9/428776287931417c82089109efbb701a.jpg" width="650" height="173" style="border:1px solid black;"></a></span></p>
<h3><strong>2.3 创建节点与添加节点</strong></h3>
<h3><strong>2.3.1 相关类图</strong></h3>
<p><strong><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/bc23d246eef84c49a53909fcbaad4600.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第18张图片" title="图片" src="http://img.e-com-net.com/image/info9/bc23d246eef84c49a53909fcbaad4600.jpg" width="650" height="354" style="border:1px solid black;"></a></span></strong></p>
<h3><strong>2.3.2 创建、添加流程</strong></h3>
<p>上面的分词循环中,每分出一个 Token,就会根据 Token 创建对应的 Node,然后将 Node 添加到 DOM 树上(HTMLDocumentParser::pumpTokenizerLoop 方法在上面分词中有介绍)。</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/6323e7ec573041238561fdc40a020166.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第19张图片" title="图片" src="http://img.e-com-net.com/image/info9/6323e7ec573041238561fdc40a020166.jpg" width="650" height="347" style="border:1px solid black;"></a></span></p>
<p>上面方法中首先看 HTMLTreeBuilder::constructTree,代码如下:</p>
<pre><code>// 只保留关健代码
void HTMLTreeBuilder::constructTree(AtomHTMLToken&& token)
{
...
if (shouldProcessTokenInForeignContent(token))
processTokenInForeignContent(WTFMove(token));
else
processToken(WTFMove(token)); // HTMLToken在这里被处理
...
m_tree.executeQueuedTasks(); // HTMLContructionSiteTask在这里被执行,有时候也直接在创建的过程中直接执行,然后这个方法发现队列为空就会直接返回
// The tree builder might have been destroyed as an indirect result of executing the queued tasks.
}
void HTMLConstructionSite::executeQueuedTasks()
{
if (m_taskQueue.isEmpty()) // 队列为空,就直接返回
return;
// Copy the task queue into a local variable in case executeTask
// re-enters the parser.
TaskQueue queue = WTFMove(m_taskQueue);
for (auto& task : queue) // 这里的task就是HTMLContructionSiteTask
executeTask(task); // 执行task
// We might be detached now.
}</code></pre>
<p>上面代码中 HTMLTreeBuilder::processToken 就是处理 Token 生成对应 Node 的地方,代码如下所示:</p>
<pre><code>void HTMLTreeBuilder::processToken(AtomHTMLToken&& token)
{
switch (token.type()) {
case HTMLToken::Uninitialized:
ASSERT_NOT_REACHED();
break;
case HTMLToken::DOCTYPE: // HTML中的DOCType标签
m_shouldSkipLeadingNewline = false;
processDoctypeToken(WTFMove(token));
break;
case HTMLToken::StartTag: // 起始HTML标签
m_shouldSkipLeadingNewline = false;
processStartTag(WTFMove(token));
break;
case HTMLToken::EndTag: // 结束HTML标签
m_shouldSkipLeadingNewline = false;
processEndTag(WTFMove(token));
break;
case HTMLToken::Comment: // HTML中的注释
m_shouldSkipLeadingNewline = false;
processComment(WTFMove(token));
return;
case HTMLToken::Character: // HTML中的纯文本
processCharacter(WTFMove(token));
break;
case HTMLToken::EndOfFile: // HTML结束标志
m_shouldSkipLeadingNewline = false;
processEndOfFile(WTFMove(token));
break;
}
}</code></pre>
<p>可以看到上面代码对7类 Token 做了处理,由于处理的流程都是类似的,这里分析5 个节点case的创建添加过程,分别是 <strong><!DOCTYPE> 标签,<html> 起始标签,<title> 起始标签,</strong><title> 文本,<strong><title> 结束标签</strong>,剩下的过程都使用图表示。</p>
<p>Case1:!DOCTYPE 标签</p>
<pre><code>// 只保留关健代码
void HTMLTreeBuilder::processDoctypeToken(AtomHTMLToken&& token)
{
ASSERT(token.type() == HTMLToken::DOCTYPE);
if (m_insertionMode == InsertionMode::Initial) { // m_insertionMode的初始值就是InsertionMode::Initial
m_tree.insertDoctype(WTFMove(token)); // 插入DOCTYPE标签
m_insertionMode = InsertionMode::BeforeHTML; // 插入DOCTYPE标签之后,m_insertionMode设置为InsertionMode::BeforeHTML,表示下面要开是HTML标签插入
return;
}
...
}
// 只保留关健代码
void HTMLConstructionSite::insertDoctype(AtomHTMLToken&& token)
{
...
// m_attachmentRoot就是Document对象,文档根节点
// DocumentType::create方法创建出DOCTYPE节点
// attachLater方法内部创建出HTMLContructionSiteTask
attachLater(m_attachmentRoot, DocumentType::create(m_document, token.name(), publicId, systemId));
...
}
// 只保留关健代码
void HTMLConstructionSite::attachLater(ContainerNode& parent, Ref<Node>&& child, bool selfClosing)
{
...
HTMLConstructionSiteTask task(HTMLConstructionSiteTask::Insert); // 创建HTMLConstructionSiteTask
task.parent = &parent; // task持有当前节点的父节点
task.child = WTFMove(child); // task持有需要操作的节点
task.selfClosing = selfClosing; // 是否自关闭节点
// Add as a sibling of the parent if we have reached the maximum depth allowed.
// m_openElements就是HTMLElementStack,在这里还看不到它的作用,后面会讲。这里可以看到这个stack里面加入的对象个数是有限制的,最大不超过512个。
// 所以如果一个HTML标签嵌套过多的子标签,就会触发这里的操作
if (m_openElements.stackDepth() > m_maximumDOMTreeDepth && task.parent->parentNode())
task.parent = task.parent->parentNode(); // 满足条件,就会将当前节点添加到爷爷节点,而不是父节点
ASSERT(task.parent);
m_taskQueue.append(WTFMove(task)); // 将task添加到Queue当中
}</code></pre>
<p>从代码可以看到,这里只是创建了 DOCTYPE 节点,还没有真正添加。真正执行添加的操作,需要执行 HTMLContructionSite::executeQueuedTasks,这个方法在一开始有列出来。下面就来看下每个 Task 如何被执行。</p>
<pre><code>// 方法位于HTMLContructionSite.cpp
static inline void executeTask(HTMLConstructionSiteTask& task)
{
switch (task.operation) { // HTMLConstructionSiteTask存储了自己要做的操作,构建DOM树一般都是Insert操作
case HTMLConstructionSiteTask::Insert:
executeInsertTask(task); // 这里执行insert操作
return;
// All the cases below this point are only used by the adoption agency.
case HTMLConstructionSiteTask::InsertAlreadyParsedChild:
executeInsertAlreadyParsedChildTask(task);
return;
case HTMLConstructionSiteTask::Reparent:
executeReparentTask(task);
return;
case HTMLConstructionSiteTask::TakeAllChildrenAndReparent:
executeTakeAllChildrenAndReparentTask(task);
return;
}
ASSERT_NOT_REACHED();
}
// 只保留关健代码,方法位于HTMLContructionSite.cpp
static inline void executeInsertTask(HTMLConstructionSiteTask& task)
{
ASSERT(task.operation == HTMLConstructionSiteTask::Insert);
insert(task); // 继续调用插入方法
...
}
// 只保留关健代码,方法位于HTMLContructionSite.cpp
static inline void insert(HTMLConstructionSiteTask& task)
{
...
ASSERT(!task.child->parentNode());
if (task.nextChild)
task.parent->parserInsertBefore(*task.child, *task.nextChild);
else
task.parent->parserAppendChild(*task.child); // 调用父节点方法继续插入
}
// 只保留关健代码
void ContainerNode::parserAppendChild(Node& newChild)
{
...
executeNodeInsertionWithScriptAssertion(*this, newChild, ChildChange::Source::Parser, ReplacedAllChildren::No, [&] {
if (&document() != &newChild.document())
document().adoptNode(newChild);
appendChildCommon(newChild); // 在Block回调中调用此方法继续插入
...
});
}
// 最终调用的是这个方法进行插入
void ContainerNode::appendChildCommon(Node& child)
{
ScriptDisallowedScope::InMainThread scriptDisallowedScope;
child.setParentNode(this);
if (m_lastChild) { // 父节点已经插入子节点,运行在这里
child.setPreviousSibling(m_lastChild);
m_lastChild->setNextSibling(&child);
} else
m_firstChild = &child; // 如果父节点是首次插入子节点,运行在这里
m_lastChild = &child; // 更新m_lastChild
}</code></pre>
<p>经过执行上面方法之后,原来只有一个根节点的 DOM 树变成了下面的样子:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/1c319bae5a4e4079bae7b6d7f65a3aa1.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第20张图片" title="图片" src="http://img.e-com-net.com/image/info9/1c319bae5a4e4079bae7b6d7f65a3aa1.jpg" width="650" height="270" style="border:1px solid black;"></a></span></p>
<p><strong>Case2:html 起始标签</strong></p>
<pre><code>// processStartTag内部有很多状态处理,这里只保留关健代码
void HTMLTreeBuilder::processStartTag(AtomHTMLToken&& token)
{
ASSERT(token.type() == HTMLToken::StartTag);
switch (m_insertionMode) {
case InsertionMode::Initial:
defaultForInitial();
ASSERT(m_insertionMode == InsertionMode::BeforeHTML);
FALLTHROUGH;
case InsertionMode::BeforeHTML:
if (token.name() == htmlTag) { // html标签在这里处理
m_tree.insertHTMLHtmlStartTagBeforeHTML(WTFMove(token));
m_insertionMode = InsertionMode::BeforeHead; // 插入完html标签,m_insertionMode = InsertionMode::BeforeHead,表明即将处理head标签
return;
}
...
}
}
// 只保留关健代码
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomHTMLToken&& token)
{
auto element = HTMLHtmlElement::create(m_document); // 创建html节点
setAttributes(element, token, m_parserContentPolicy);
attachLater(m_attachmentRoot, element.copyRef()); // 同样调用了attachLater方法,与DOCTYPE类似
m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element.copyRef(), WTFMove(token))); // 注意这里,这里向HTMLElementStack中压入了正在插入的html起始标签
executeQueuedTasks(); // 这里在插入操作直接执行了task,外面HTMLTreeBuilder::constructTree方法调用的executeQueuedTasks方法就会直接返回
...
}</code></pre>
<p>执行上面代码之后,DOM 树变成了如下图所示:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/56f5c05ec33a467f9e0a0537438c786b.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第21张图片" title="图片" src="http://img.e-com-net.com/image/info9/56f5c05ec33a467f9e0a0537438c786b.jpg" width="650" height="175" style="border:1px solid black;"></a></span></p>
<p><strong>Case3:title 起始标签</strong></p>
<p>当插入 <title> 起始标签之后,DOM 树以及 HTMLElementStack m\_openElements 如下图所示:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/753be313e65e4181bfa697fad4662e34.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第22张图片" title="图片" src="http://img.e-com-net.com/image/info9/753be313e65e4181bfa697fad4662e34.jpg" width="650" height="274" style="border:1px solid black;"></a></span> </p>
<p><strong>Case4:title 标签文本</strong></p>
<p><title> 标签的文本作为文本节点插入,生成文本节点的代码如下:</p>
<p>`// 只保留关健代码<br>void HTMLConstructionSite::insertTextNode(const String& characters, WhitespaceMode whitespaceMode)<br>{<br>HTMLConstructionSiteTask task(HTMLConstructionSiteTask::Insert);</p>
<pre><code>task.parent = ¤tNode(); // 直接取HTMLElementStack m_openElements的栈顶节点,此时节点是title`
</code></pre>
<p>unsigned currentPosition = 0;<br>unsigned lengthLimit = shouldUseLengthLimit(*task.parent) ? Text::defaultLengthLimit : std::numeric_limits<unsigned>::max(); // 限制文本节点最大包含的字符个数为65536</p>
<p>// 可以看到如果文本过长,会将分割成多个文本节点<br>while (currentPosition < characters.length()) {</p>
<pre><code> AtomString charactersAtom = m_whitespaceCache.lookup(characters, whitespaceMode);</code></pre>
<p>auto textNode = Text::createWithLengthLimit(task.parent->document(), charactersAtom.isNull() ? characters : charactersAtom.string(), currentPosition, lengthLimit);<br>// If we have a whole string of unbreakable characters the above could lead to an infinite loop. Exceeding the length limit is the lesser evil.<br>if (!textNode->length()) {</p>
<pre><code> String substring = characters.substring(currentPosition);
AtomString substringAtom = m_whitespaceCache.lookup(substring, whitespaceMode);
textNode = Text::create(task.parent->document(), substringAtom.isNull() ? substring : substringAtom.string()); // 生成文本节点
}
currentPosition += textNode->length(); // 下一个文本节点包含的字符起点
ASSERT(currentPosition <= characters.length());
task.child = WTFMove(textNode);
executeTask(task); // 直接执行Task插入
}</code></pre>
<p>}</p>
<pre><code>
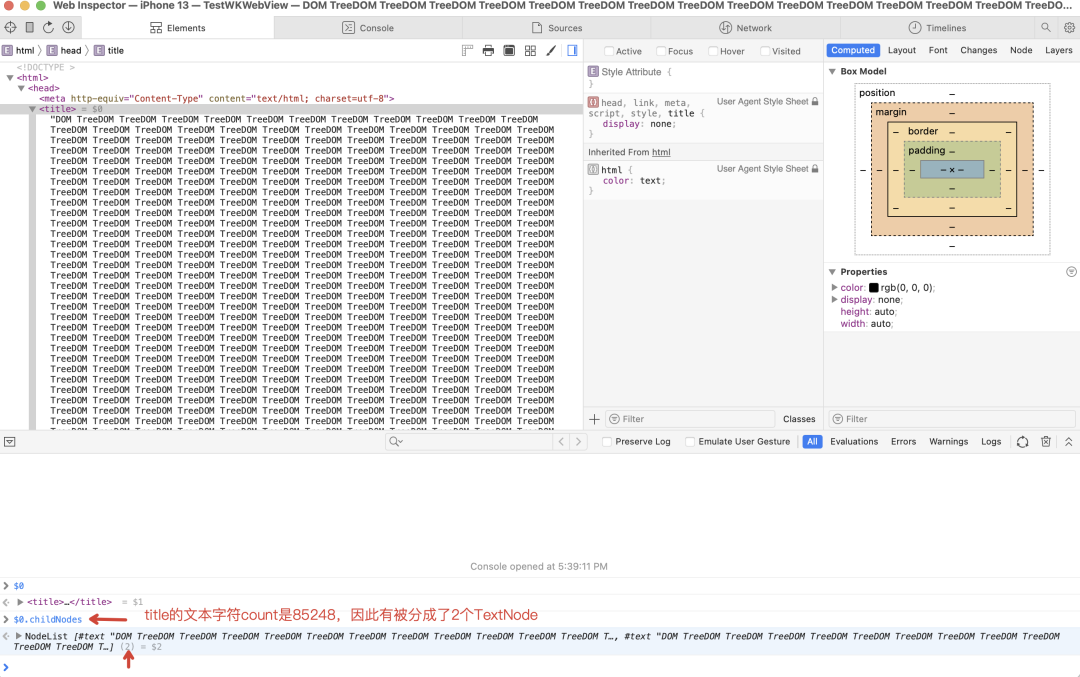
从代码可以看到,如果一个节点后面跟的文本字符过多,会被分割成多个文本节点插入。下面的例子将 <title> 节点后面的文本字符个数设置成85248,使用 Safari 查看确实生成了2个文本节点:
**Case5:结束标签**
当遇到 <title> 结束标签,代码处理如下:
</code></pre>
<p>// 代码内部有很多状态处理,这里只保留关健代码<br>void HTMLTreeBuilder::processEndTag(AtomHTMLToken&& token)<br>{</p>
<pre><code>ASSERT(token.type() == HTMLToken::EndTag);</code></pre>
<p>switch (m_insertionMode) {</p>
<pre><code>...
</code></pre>
<p>case InsertionMode::Text: // 由于遇到title结束标签之前插入了文本,因此此时的插入模式就是InsertionMode::Text</p>
<pre><code> m_tree.openElements().pop(); // 因为遇到了title结束标签,整个标签已经处理完毕,从HTMLElementStack栈中弹出栈顶元素title
m_insertionMode = m_originalInsertionMode; // 恢复之前的插入模式</code></pre>
<p>break;</p>
<p>}</p>
<p>每当遇到一个标签的结束标签,都会像上面一样将 HTMLElementStack m\_openElementsStack 的栈顶元素弹出。执行上面代码之后,DOM 树与 HTMLElementStack 如下图所示:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/fbf0220a0b57421eba9a6b33bfec2275.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第23张图片" title="图片" src="http://img.e-com-net.com/image/info9/fbf0220a0b57421eba9a6b33bfec2275.jpg" width="650" height="313" style="border:1px solid black;"></a></span></p>
<h1><strong>三、内存中的DOM树</strong></h1>
<p>当整个 DOM 树构建完成之后,DOM 树和 HTMLElementStack m\_openElements 如下图所示:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/5c5b85b646af482da5c0036487216114.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第24张图片" title="图片" src="http://img.e-com-net.com/image/info9/5c5b85b646af482da5c0036487216114.jpg" width="650" height="233" style="border:1px solid black;"></a></span></p>
<p>从上图可以看到,当构建完 DOM,HTMLElementStack m\_openElements 并没有将栈完全清空,而是保留了2个节点: html 节点与 body 节点。这可以从 Xcode 的控制台输出看到:</p>
<p><span class="img-wrap"><a href="http://img.e-com-net.com/image/info9/489e905f82f14c4bbde06859bc09b877.jpg" target="_blank"><img class="lazy" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第25张图片" title="图片" src="http://img.e-com-net.com/image/info9/489e905f82f14c4bbde06859bc09b877.jpg" width="650" height="346" style="border:1px solid black;"></a></span></p>
<p>同时可以看到,内存中的 DOM 树结构和文章开头画的逻辑上的 DOM 树结构是不一样的。逻辑上的 DOM 树父节点有多少子节点,就有多少指向子节点的指针,而内存中的 DOM 树,不管父节点有多少子节点,始终只有2个指针指向子节点: m\_firstChild 与 m\_lastChild。同时,内存中的 DOM 树兄弟节点之间也相互有指针引用,而逻辑上的 DOM 树结构是没有的。</p>
<p>举个例子,如果一棵 DOM 树只有1个父节点,100个子节点,那么使用逻辑上的 DOM 树结构,父节点就需要100个指向子节点的指针。如果一个指针占8字节,那么总共占用800字节。使用上面内存中 DOM 树的表示方式,父节点需要2个指向子节点的指针,同时兄弟节点之间需要198个指针,一共200个指针,总共占用1600字节。相比逻辑上的 DOM 树结构,内存上并不占优势,但是内存中的 DOM 树结构,无论父节点有多少子节点,只需要2个指针就可以了,不需要添加子节点时,频繁动态申请内存,创建新的指向子节点的指针。</p>
<p>---------- END ----------</p>
<p>百度 Geek 说</p>
<p>百度官方技术公众号上线啦!</p>
<p>技术干货 · 行业资讯 · 线上沙龙 · 行业大会</p>
<p>招聘信息 · 内推信息 · 技术书籍 · 百度周边</p>
</article>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1506168282154074112"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(后端前端dom)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1835513699826233344.htm"
title="android系统selinux中添加新属性property" target="_blank">android系统selinux中添加新属性property</a>
<span class="text-muted">辉色投像</span>
<div>1.定位/android/system/sepolicy/private/property_contexts声明属性开头:persist.charge声明属性类型:u:object_r:system_prop:s0图12.定位到android/system/sepolicy/public/domain.te删除neverallow{domain-init}default_prop:property</div>
</li>
<li><a href="/article/1835509897106649088.htm"
title="Long类型前后端数据不一致" target="_blank">Long类型前后端数据不一致</a>
<span class="text-muted">igotyback</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>响应给前端的数据浏览器控制台中response中看到的Long类型的数据是正常的到前端数据不一致前后端数据类型不匹配是一个常见问题,尤其是当后端使用Java的Long类型(64位)与前端JavaScript的Number类型(最大安全整数为2^53-1,即16位)进行数据交互时,很容易出现精度丢失的问题。这是因为JavaScript中的Number类型无法安全地表示超过16位的整数。为了解决这个问</div>
</li>
<li><a href="/article/1835508131489214464.htm"
title="高级编程--XML+socket练习题" target="_blank">高级编程--XML+socket练习题</a>
<span class="text-muted">masa010</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>1.北京华北2114.8万人上海华东2,500万人广州华南1292.68万人成都华西1417万人(1)使用dom4j将信息存入xml中(2)读取信息,并打印控制台(3)添加一个city节点与子节点(4)使用socketTCP协议编写服务端与客户端,客户端输入城市ID,服务器响应相应城市信息(5)使用socketTCP协议编写服务端与客户端,客户端要求用户输入city对象,服务端接收并使用dom4j</div>
</li>
<li><a href="/article/1835501948011376640.htm"
title="使用 FinalShell 进行远程连接(ssh 远程连接 Linux 服务器)" target="_blank">使用 FinalShell 进行远程连接(ssh 远程连接 Linux 服务器)</a>
<span class="text-muted">编程经验分享</span>
<a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E5%B7%A5%E5%85%B7/1.htm">开发工具</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/ssh/1.htm">ssh</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>目录前言基本使用教程新建远程连接连接主机自定义命令路由追踪前言后端开发,必然需要和服务器打交道,部署应用,排查问题,查看运行日志等等。一般服务器都是集中部署在机房中,也有一些直接是云服务器,总而言之,程序员不可能直接和服务器直接操作,一般都是通过ssh连接来登录服务器。刚接触远程连接时,使用的是XSHELL来远程连接服务器,连接上就能够操作远程服务器了,但是仅用XSHELL并没有上传下载文件的功能</div>
</li>
<li><a href="/article/1835498925755297792.htm"
title="DIV+CSS+JavaScript技术制作网页(旅游主题网页设计与制作)云南大理" target="_blank">DIV+CSS+JavaScript技术制作网页(旅游主题网页设计与制作)云南大理</a>
<span class="text-muted">STU学生网页设计</span>
<a class="tag" taget="_blank" href="/search/%E7%BD%91%E9%A1%B5%E8%AE%BE%E8%AE%A1/1.htm">网页设计</a><a class="tag" taget="_blank" href="/search/%E6%9C%9F%E6%9C%AB%E7%BD%91%E9%A1%B5%E4%BD%9C%E4%B8%9A/1.htm">期末网页作业</a><a class="tag" taget="_blank" href="/search/html%E9%9D%99%E6%80%81%E7%BD%91%E9%A1%B5/1.htm">html静态网页</a><a class="tag" taget="_blank" href="/search/html5%E6%9C%9F%E6%9C%AB%E5%A4%A7%E4%BD%9C%E4%B8%9A/1.htm">html5期末大作业</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E9%A1%B5%E8%AE%BE%E8%AE%A1/1.htm">网页设计</a><a class="tag" taget="_blank" href="/search/web%E5%A4%A7%E4%BD%9C%E4%B8%9A/1.htm">web大作业</a>
<div>️精彩专栏推荐作者主页:【进入主页—获取更多源码】web前端期末大作业:【HTML5网页期末作业(1000套)】程序员有趣的告白方式:【HTML七夕情人节表白网页制作(110套)】文章目录二、网站介绍三、网站效果▶️1.视频演示2.图片演示四、网站代码HTML结构代码CSS样式代码五、更多源码二、网站介绍网站布局方面:计划采用目前主流的、能兼容各大主流浏览器、显示效果稳定的浮动网页布局结构。网站程</div>
</li>
<li><a href="/article/1835497792265613312.htm"
title="【加密社】Solidity 中的事件机制及其应用" target="_blank">【加密社】Solidity 中的事件机制及其应用</a>
<span class="text-muted">加密社</span>
<a class="tag" taget="_blank" href="/search/%E9%97%B2%E4%BE%83/1.htm">闲侃</a><a class="tag" taget="_blank" href="/search/%E5%8C%BA%E5%9D%97%E9%93%BE/1.htm">区块链</a><a class="tag" taget="_blank" href="/search/%E6%99%BA%E8%83%BD%E5%90%88%E7%BA%A6/1.htm">智能合约</a><a class="tag" taget="_blank" href="/search/%E5%8C%BA%E5%9D%97%E9%93%BE/1.htm">区块链</a>
<div>加密社引言在Solidity合约开发过程中,事件(Events)是一种非常重要的机制。它们不仅能够让开发者记录智能合约的重要状态变更,还能够让外部系统(如前端应用)监听这些状态的变化。本文将详细介绍Solidity中的事件机制以及如何利用不同的手段来触发、监听和获取这些事件。事件存储的地方当我们在Solidity合约中使用emit关键字触发事件时,该事件会被记录在区块链的交易收据中。具体而言,事件</div>
</li>
<li><a href="/article/1835496149843275776.htm"
title="关于城市旅游的HTML网页设计——(旅游风景云南 5页)HTML+CSS+JavaScript" target="_blank">关于城市旅游的HTML网页设计——(旅游风景云南 5页)HTML+CSS+JavaScript</a>
<span class="text-muted">二挡起步</span>
<a class="tag" taget="_blank" href="/search/web%E5%89%8D%E7%AB%AF%E6%9C%9F%E6%9C%AB%E5%A4%A7%E4%BD%9C%E4%B8%9A/1.htm">web前端期末大作业</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/%E6%97%85%E6%B8%B8/1.htm">旅游</a><a class="tag" taget="_blank" href="/search/%E9%A3%8E%E6%99%AF/1.htm">风景</a>
<div>⛵源码获取文末联系✈Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业|游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作|HTML期末大学生网页设计作业,Web大学生网页HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScrip</div>
</li>
<li><a href="/article/1835496148601761792.htm"
title="HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动" target="_blank">HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动</a>
<span class="text-muted">二挡起步</span>
<a class="tag" taget="_blank" href="/search/web%E5%89%8D%E7%AB%AF%E6%9C%9F%E6%9C%AB%E5%A4%A7%E4%BD%9C%E4%B8%9A/1.htm">web前端期末大作业</a><a class="tag" taget="_blank" href="/search/web%E8%AE%BE%E8%AE%A1%E7%BD%91%E9%A1%B5%E8%A7%84%E5%88%92%E4%B8%8E%E8%AE%BE%E8%AE%A1/1.htm">web设计网页规划与设计</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/dreamweaver/1.htm">dreamweaver</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作HTML期末大学生网页设计作业HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScript:做与用户的交互行为文章目录前端学习路线</div>
</li>
<li><a href="/article/1835489438243844096.htm"
title="Low Power概念介绍-Voltage Area" target="_blank">Low Power概念介绍-Voltage Area</a>
<span class="text-muted">飞奔的大虎</span>
<div>随着智能手机,以及物联网的普及,芯片功耗的问题最近几年得到了越来越多的重视。为了实现集成电路的低功耗设计目标,我们需要在系统设计阶段就采用低功耗设计的方案。而且,随着设计流程的逐步推进,到了芯片后端设计阶段,降低芯片功耗的方法已经很少了,节省的功耗百分比也不断下降。芯片的功耗主要由静态功耗(staticleakagepower)和动态功耗(dynamicpower)构成。静态功耗主要是指电路处于等</div>
</li>
<li><a href="/article/1835463874560749568.htm"
title="用Python实现简单的猜数字游戏" target="_blank">用Python实现简单的猜数字游戏</a>
<span class="text-muted">程序媛了了</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E6%B8%B8%E6%88%8F/1.htm">游戏</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>猜数字游戏代码:importrandomdefpythonit():a=random.randint(1,100)n=int(input("输入你猜想的数字:"))whilen!=a:ifn>a:print("很遗憾,猜大了")n=int(input("请再次输入你猜想的数字:"))elifna::如果玩家猜的数字n大于随机数字a,则输出"很遗憾,猜大了",并提示玩家再次输入。elifn<a::如</div>
</li>
<li><a href="/article/1835448238103162880.htm"
title="springboot+vue项目实战一-创建SpringBoot简单项目" target="_blank">springboot+vue项目实战一-创建SpringBoot简单项目</a>
<span class="text-muted">苹果酱0567</span>
<a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95%E9%A2%98%E6%B1%87%E6%80%BB%E4%B8%8E%E8%A7%A3%E6%9E%90/1.htm">面试题汇总与解析</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E4%B8%AD%E9%97%B4%E4%BB%B6/1.htm">中间件</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>这段时间抽空给女朋友搭建一个个人博客,想着记录一下建站的过程,就当做笔记吧。虽然复制zjblog只要一个小时就可以搞定一个网站,或者用cms系统,三四个小时就可以做出一个前后台都有的网站,而且想做成啥样也都行。但是就是要从新做,自己做的意义不一样,更何况,俺就是专门干这个的,嘿嘿嘿要做一个网站,而且从零开始,首先呢就是技术选型了,经过一番思量决定选择-SpringBoot做后端,前端使用Vue做一</div>
</li>
<li><a href="/article/1835448111909138432.htm"
title="react-intl——react国际化使用方案" target="_blank">react-intl——react国际化使用方案</a>
<span class="text-muted">苹果酱0567</span>
<a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95%E9%A2%98%E6%B1%87%E6%80%BB%E4%B8%8E%E8%A7%A3%E6%9E%90/1.htm">面试题汇总与解析</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E4%B8%AD%E9%97%B4%E4%BB%B6/1.htm">中间件</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a>
<div>国际化介绍i18n:internationalization国家化简称,首字母+首尾字母间隔的字母个数+尾字母,类似的还有k8s(Kubernetes)React-intl是React中最受欢迎的库。使用步骤安装#usenpmnpminstallreact-intl-D#useyarn项目入口文件配置//index.tsximportReactfrom"react";importReactDOMf</div>
</li>
<li><a href="/article/1835447479580061696.htm"
title="uniapp map组件自定义markers标记点" target="_blank">uniapp map组件自定义markers标记点</a>
<span class="text-muted">以对_</span>
<a class="tag" taget="_blank" href="/search/uni-app%E5%AD%A6%E4%B9%A0%E8%AE%B0%E5%BD%95/1.htm">uni-app学习记录</a><a class="tag" taget="_blank" href="/search/uni-app/1.htm">uni-app</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>需求是根据后端返回数据在地图上显示标记点,并且根据数据状态控制标记点颜色,标记点背景通过两张图片实现控制{{item.options.labelName}}exportdefault{data(){return{storeIndex:0,locaInfo:{longitude:120.445172,latitude:36.111387},markers:[//标点列表{id:1,//标记点idin</div>
</li>
<li><a href="/article/1835443696431099904.htm"
title="笋丁网页自动回复机器人V3.0.0免授权版源码" target="_blank">笋丁网页自动回复机器人V3.0.0免授权版源码</a>
<span class="text-muted">希希分享</span>
<a class="tag" taget="_blank" href="/search/%E8%BD%AF%E5%B8%8C%E7%BD%9158soho_cn/1.htm">软希网58soho_cn</a><a class="tag" taget="_blank" href="/search/%E6%BA%90%E7%A0%81%E8%B5%84%E6%BA%90/1.htm">源码资源</a><a class="tag" taget="_blank" href="/search/%E7%AC%8B%E4%B8%81%E7%BD%91%E9%A1%B5%E8%87%AA%E5%8A%A8%E5%9B%9E%E5%A4%8D%E6%9C%BA%E5%99%A8%E4%BA%BA/1.htm">笋丁网页自动回复机器人</a>
<div>笋丁网页机器人一款可设置自动回复,默认消息,调用自定义api接口的网页机器人。此程序后端语言使用Golang,内存占用最高不超过30MB,1H1G服务器流畅运行。仅支持Linux服务器部署,不支持虚拟主机,请悉知!使用自定义api功能需要有一定的建站基础。源码下载:https://download.csdn.net/download/m0_66047725/89754250更多资源下载:关注我。安</div>
</li>
<li><a href="/article/1835437775344726016.htm"
title="博客网站制作教程" target="_blank">博客网站制作教程</a>
<span class="text-muted">2401_85194651</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/maven/1.htm">maven</a>
<div>首先就是技术框架:后端:Java+SpringBoot数据库:MySQL前端:Vue.js数据库连接:JPA(JavaPersistenceAPI)1.项目结构blog-app/├──backend/│├──src/main/java/com/example/blogapp/││├──BlogApplication.java││├──config/│││└──DatabaseConfig.java</div>
</li>
<li><a href="/article/1835432358141063168.htm"
title="深入浅出 -- 系统架构之负载均衡Nginx的性能优化" target="_blank">深入浅出 -- 系统架构之负载均衡Nginx的性能优化</a>
<span class="text-muted">xiaoli8748_软件开发</span>
<a class="tag" taget="_blank" href="/search/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84/1.htm">系统架构</a><a class="tag" taget="_blank" href="/search/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84/1.htm">系统架构</a><a class="tag" taget="_blank" href="/search/%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1/1.htm">负载均衡</a><a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a>
<div>一、Nginx性能优化到这里文章的篇幅较长了,最后再来聊一下关于Nginx的性能优化,主要就简单说说收益最高的几个优化项,在这块就不再展开叙述了,毕竟影响性能都有多方面原因导致的,比如网络、服务器硬件、操作系统、后端服务、程序自身、数据库服务等,对于性能调优比较感兴趣的可以参考之前《JVM性能调优》中的调优思想。优化一:打开长连接配置通常Nginx作为代理服务,负责分发客户端的请求,那么建议开启H</div>
</li>
<li><a href="/article/1835428821877223424.htm"
title="计算机毕业设计PHP仓储综合管理系统(源码+程序+VUE+lw+部署)" target="_blank">计算机毕业设计PHP仓储综合管理系统(源码+程序+VUE+lw+部署)</a>
<span class="text-muted">java毕设程序源码王哥</span>
<a class="tag" taget="_blank" href="/search/php/1.htm">php</a><a class="tag" taget="_blank" href="/search/%E8%AF%BE%E7%A8%8B%E8%AE%BE%E8%AE%A1/1.htm">课程设计</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a>
<div>该项目含有源码、文档、程序、数据库、配套开发软件、软件安装教程。欢迎交流项目运行环境配置:phpStudy+Vscode+Mysql5.7+HBuilderX+Navicat11+Vue+Express。项目技术:原生PHP++Vue等等组成,B/S模式+Vscode管理+前后端分离等等。环境需要1.运行环境:最好是小皮phpstudy最新版,我们在这个版本上开发的。其他版本理论上也可以。2.开发</div>
</li>
<li><a href="/article/1835428317084348416.htm"
title="最简单将静态网页挂载到服务器上(不用nginx)" target="_blank">最简单将静态网页挂载到服务器上(不用nginx)</a>
<span class="text-muted">全能全知者</span>
<a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a>
<div>最简单将静态网页挂载到服务器上(不用nginx)如果随便弄个静态网页挂在服务器都要用nignx就太麻烦了,所以直接使用Apache来搭建一些简单前端静态网页会相对方便很多检查Web服务器服务状态:sudosystemctlstatushttpd#ApacheWeb服务器如果发现没有安装web服务器:安装Apache:sudoyuminstallhttpd启动Apache:sudosystemctl</div>
</li>
<li><a href="/article/1835427057752961024.htm"
title="补充元象二面" target="_blank">补充元象二面</a>
<span class="text-muted">Redstone Monstrosity</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a>
<div>1.请尽可能详细地说明,防抖和节流的区别,应用场景?你的回答中不要写出示例代码。防抖(Debounce)和节流(Throttle)是两种常用的前端性能优化技术,它们的主要区别在于如何处理高频事件的触发。以下是防抖和节流的区别和应用场景的详细说明:防抖和节流的定义防抖:在一段时间内,多次执行变为只执行最后一次。防抖的原理是,当事件被触发后,设置一个延迟定时器。如果在这个延迟时间内事件再次被触发,则重</div>
</li>
<li><a href="/article/1835420753252675584.htm"
title="微信小程序开发注意事项" target="_blank">微信小程序开发注意事项</a>
<span class="text-muted">jun778895</span>
<a class="tag" taget="_blank" href="/search/%E5%BE%AE%E4%BF%A1%E5%B0%8F%E7%A8%8B%E5%BA%8F/1.htm">微信小程序</a><a class="tag" taget="_blank" href="/search/%E5%B0%8F%E7%A8%8B%E5%BA%8F/1.htm">小程序</a>
<div>微信小程序开发是一个融合了前端开发、用户体验设计、后端服务(可选)以及微信小程序平台特性的综合性项目。这里,我将详细介绍一个典型的小程序开发项目的全过程,包括项目规划、设计、开发、测试及部署上线等各个环节,并尽量使内容达到或超过2000字的要求。一、项目规划1.1项目背景与目标假设我们要开发一个名为“智慧校园助手”的微信小程序,旨在为学生提供一站式校园生活服务,包括课程表查询、图书馆座位预约、食堂</div>
</li>
<li><a href="/article/1835420248896008192.htm"
title="使用由 Python 编写的 lxml 实现高性能 XML 解析" target="_blank">使用由 Python 编写的 lxml 实现高性能 XML 解析</a>
<span class="text-muted">hunyxv</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/xml/1.htm">xml</a>
<div>转载自:文章lxml简介Python从来不出现XML库短缺的情况。从2.0版本开始,它就附带了xml.dom.minidom和相关的pulldom以及SimpleAPIforXML(SAX)模块。从2.4开始,它附带了流行的ElementTreeAPI。此外,很多第三方库可以提供更高级别的或更具有python风格的接口。尽管任何XML库都足够处理简单的DocumentObjectModel(DOM</div>
</li>
<li><a href="/article/1835411044768509952.htm"
title="字节二面" target="_blank">字节二面</a>
<span class="text-muted">Redstone Monstrosity</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a>
<div>1.假设你是正在面试前端开发工程师的候选人,面试官让你详细说出你上一段实习过程的收获和感悟。在上一段实习过程中,我获得了宝贵的实践经验和深刻的行业洞察,以下是我的主要收获和感悟:一、专业技能提升框架应用熟练度:通过实际项目,我深入掌握了React、Vue等前端框架的使用,不仅提升了编码效率,还学会了如何根据项目需求选择合适的框架。问题解决能力:在实习期间,我遇到了许多预料之外的技术难题。通过查阅文</div>
</li>
<li><a href="/article/1835401975269781504.htm"
title="vue render 函数详解 (配参数详解)" target="_blank">vue render 函数详解 (配参数详解)</a>
<span class="text-muted">你的眼睛會笑</span>
<a class="tag" taget="_blank" href="/search/vue2/1.htm">vue2</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>vuerender函数详解(配参数详解)在Vue3中,`render`函数被用来代替Vue2中的模板语法。它接收一个h函数(或者是`createElement`函数的别名),并且返回一个虚拟DOM。render函数的语法结构如下:render(h){returnh('div',{class:'container'},'Hello,World!')}在上面的示例中,我们使用h函数创建了一个div元素</div>
</li>
<li><a href="/article/1835398064727224320.htm"
title="前端代码上传文件" target="_blank">前端代码上传文件</a>
<span class="text-muted">余生逆风飞翔</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>点击上传文件import{ElNotification}from'element-plus'import{API_CONFIG}from'../config/index.js'import{UploadFilled}from'@element-plus/icons-vue'import{reactive}from'vue'import{BASE_URL}from'../config/index'i</div>
</li>
<li><a href="/article/1835393400380157952.htm"
title="VUE3 + xterm + nestjs实现web远程终端 或 连接开启SSH登录的路由器和交换机。" target="_blank">VUE3 + xterm + nestjs实现web远程终端 或 连接开启SSH登录的路由器和交换机。</a>
<span class="text-muted">焚木灵</span>
<a class="tag" taget="_blank" href="/search/node.js/1.htm">node.js</a><a class="tag" taget="_blank" href="/search/vue/1.htm">vue</a>
<div>可远程连接系统终端或开启SSH登录的路由器和交换机。相关资料:xtermjs/xterm.js:Aterminalfortheweb(github.com)后端实现(NestJS):1、安装依赖:npminstallnode-ssh@nestjs/websockets@nestjs/platform-socket.io2、我们将创建一个名为RemoteControlModule的NestJS模块,</div>
</li>
<li><a href="/article/1835385458356482048.htm"
title="uniapp实现动态标记效果详细步骤【前端开发】" target="_blank">uniapp实现动态标记效果详细步骤【前端开发】</a>
<span class="text-muted">2401_85123349</span>
<a class="tag" taget="_blank" href="/search/uni-app/1.htm">uni-app</a>
<div>第二个点在于实现将已经被用户标记的内容在下一次获取后刷新它的状态为已标记。这是什么意思呢?比如说上面gif图中的这些人物对象,有一些已被该用户添加为关心,那么当用户下一次进入该页面时,这些已经被添加关心的对象需要以“红心”状态显现出来。这个点的难度还不算大,只需要在每一次获取后端的内容后对标记对象进行状态更新即可。II.动态标记效果实现思路和步骤首先,整体的思路是利用动态类名对不同的元素进行选择。</div>
</li>
<li><a href="/article/1835376759739084800.htm"
title="处理标签包裹的字符串,并取出前250字符" target="_blank">处理标签包裹的字符串,并取出前250字符</a>
<span class="text-muted">周bro</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>//假设这是你的HTML字符串varhtmlString=`这是一个段落。这是一个标题这是另一个段落,包含一些链接。`;//解析HTML字符串并提取文本functionextractTextFromHTML(html){varparser=newDOMParser();vardoc=parser.parseFromString(html,"text/html");vartextContent=do</div>
</li>
<li><a href="/article/1835373236217540608.htm"
title="360前端星计划-动画可以这么玩" target="_blank">360前端星计划-动画可以这么玩</a>
<span class="text-muted">马小蜗</span>
<div>动画的基本原理定时器改变对象的属性根据新的属性重新渲染动画functionupdate(context){//更新属性}constticker=newTicker();ticker.tick(update,context);动画的种类1、JavaScript动画操作DOMCanvas2、CSS动画transitionanimation3、SVG动画SMILJS动画的优缺点优点:灵活度、可控性、性能</div>
</li>
<li><a href="/article/1835368019430305792.htm"
title="Vue + Express实现一个表单提交" target="_blank">Vue + Express实现一个表单提交</a>
<span class="text-muted">九旬大爷的梦</span>
<div>最近在折腾一个cms系统,用的vue+express,但是就一个表单提交就弄了好久,记录一下。环境:Node10+前端:Vue服务端:Express依赖包:vueexpressaxiosexpress-formidableelement-ui(可选)前言:axiosget请求参数是:paramsaxiospost请求参数是:dataexpressget接受参数是req.queryexpresspo</div>
</li>
<li><a href="/article/1835361001260806144.htm"
title="Kubernetes部署MySQL数据持久化" target="_blank">Kubernetes部署MySQL数据持久化</a>
<span class="text-muted">沫殇-MS</span>
<a class="tag" taget="_blank" href="/search/Kubernetes/1.htm">Kubernetes</a><a class="tag" taget="_blank" href="/search/MySQL%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">MySQL数据库</a><a class="tag" taget="_blank" href="/search/kubernetes/1.htm">kubernetes</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/%E5%AE%B9%E5%99%A8/1.htm">容器</a>
<div>一、安装配置NFS服务端1、安装nfs-kernel-server:sudoapt-yinstallnfs-kernel-server2、服务端创建共享目录#列出所有可用块设备的信息lsblk#格式化磁盘sudomkfs-text4/dev/sdb#创建一个目录:sudomkdir-p/data/nfs/mysql#更改目录权限:sudochown-Rnobody:nogroup/data/nfs</div>
</li>
<li><a href="/article/37.htm"
title="ASM系列五 利用TreeApi 解析生成Class" target="_blank">ASM系列五 利用TreeApi 解析生成Class</a>
<span class="text-muted">lijingyao8206</span>
<a class="tag" taget="_blank" href="/search/ASM/1.htm">ASM</a><a class="tag" taget="_blank" href="/search/%E5%AD%97%E8%8A%82%E7%A0%81%E5%8A%A8%E6%80%81%E7%94%9F%E6%88%90/1.htm">字节码动态生成</a><a class="tag" taget="_blank" href="/search/ClassNode/1.htm">ClassNode</a><a class="tag" taget="_blank" href="/search/TreeAPI/1.htm">TreeAPI</a>
<div> 前面CoreApi的介绍部分基本涵盖了ASMCore包下面的主要API及功能,其中还有一部分关于MetaData的解析和生成就不再赘述。这篇开始介绍ASM另一部分主要的Api。TreeApi。这一部分源码是关联的asm-tree-5.0.4的版本。
在介绍前,先要知道一点, Tree工程的接口基本可以完</div>
</li>
<li><a href="/article/164.htm"
title="链表树——复合数据结构应用实例" target="_blank">链表树——复合数据结构应用实例</a>
<span class="text-muted">bardo</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1.htm">数据结构</a><a class="tag" taget="_blank" href="/search/%E6%A0%91%E5%9E%8B%E7%BB%93%E6%9E%84/1.htm">树型结构</a><a class="tag" taget="_blank" href="/search/%E8%A1%A8%E7%BB%93%E6%9E%84%E8%AE%BE%E8%AE%A1/1.htm">表结构设计</a><a class="tag" taget="_blank" href="/search/%E9%93%BE%E8%A1%A8/1.htm">链表</a><a class="tag" taget="_blank" href="/search/%E8%8F%9C%E5%8D%95%E6%8E%92%E5%BA%8F/1.htm">菜单排序</a>
<div>我们清楚:数据库设计中,表结构设计的好坏,直接影响程序的复杂度。所以,本文就无限级分类(目录)树与链表的复合在表设计中的应用进行探讨。当然,什么是树,什么是链表,这里不作介绍。有兴趣可以去看相关的教材。
需求简介:
经常遇到这样的需求,我们希望能将保存在数据库中的树结构能够按确定的顺序读出来。比如,多级菜单、组织结构、商品分类。更具体的,我们希望某个二级菜单在这一级别中就是第一个。虽然它是最后</div>
</li>
<li><a href="/article/291.htm"
title="为啥要用位运算代替取模呢" target="_blank">为啥要用位运算代替取模呢</a>
<span class="text-muted">chenchao051</span>
<a class="tag" taget="_blank" href="/search/%E4%BD%8D%E8%BF%90%E7%AE%97/1.htm">位运算</a><a class="tag" taget="_blank" href="/search/%E5%93%88%E5%B8%8C/1.htm">哈希</a><a class="tag" taget="_blank" href="/search/%E6%B1%87%E7%BC%96/1.htm">汇编</a>
<div>
在hash中查找key的时候,经常会发现用&取代%,先看两段代码吧,
JDK6中的HashMap中的indexFor方法:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
</div>
</li>
<li><a href="/article/418.htm"
title="最近的情况" target="_blank">最近的情况</a>
<span class="text-muted">麦田的设计者</span>
<a class="tag" taget="_blank" href="/search/%E7%94%9F%E6%B4%BB/1.htm">生活</a><a class="tag" taget="_blank" href="/search/%E6%84%9F%E6%82%9F/1.htm">感悟</a><a class="tag" taget="_blank" href="/search/%E8%AE%A1%E5%88%92/1.htm">计划</a><a class="tag" taget="_blank" href="/search/%E8%BD%AF%E8%80%83/1.htm">软考</a><a class="tag" taget="_blank" href="/search/%E6%83%B3/1.htm">想</a>
<div> 今天是2015年4月27号
整理一下最近的思绪以及要完成的任务
1、最近在驾校科目二练车,每周四天,练三周。其实做什么都要用心,追求合理的途径解决。为</div>
</li>
<li><a href="/article/545.htm"
title="PHP去掉字符串中最后一个字符的方法" target="_blank">PHP去掉字符串中最后一个字符的方法</a>
<span class="text-muted">IT独行者</span>
<a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/%E5%AD%97%E7%AC%A6%E4%B8%B2/1.htm">字符串</a>
<div>今天在PHP项目开发中遇到一个需求,去掉字符串中的最后一个字符 原字符串1,2,3,4,5,6, 去掉最后一个字符",",最终结果为1,2,3,4,5,6 代码如下:
$str = "1,2,3,4,5,6,";
$newstr = substr($str,0,strlen($str)-1);
echo $newstr; </div>
</li>
<li><a href="/article/672.htm"
title="hadoop在linux上单机安装过程" target="_blank">hadoop在linux上单机安装过程</a>
<span class="text-muted">_wy_</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a>
<div>1、安装JDK
jdk版本最好是1.6以上,可以使用执行命令java -version查看当前JAVA版本号,如果报命令不存在或版本比较低,则需要安装一个高版本的JDK,并在/etc/profile的文件末尾,根据本机JDK实际的安装位置加上以下几行:
export JAVA_HOME=/usr/java/jdk1.7.0_25 </div>
</li>
<li><a href="/article/799.htm"
title="JAVA进阶----分布式事务的一种简单处理方法" target="_blank">JAVA进阶----分布式事务的一种简单处理方法</a>
<span class="text-muted">无量</span>
<a class="tag" taget="_blank" href="/search/%E5%A4%9A%E7%B3%BB%E7%BB%9F%E4%BA%A4%E4%BA%92/1.htm">多系统交互</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a><a class="tag" taget="_blank" href="/search/%E4%BA%8B%E5%8A%A1/1.htm">事务</a>
<div>每个方法都是原子操作:
提供第三方服务的系统,要同时提供执行方法和对应的回滚方法
A系统调用B,C,D系统完成分布式事务
=========执行开始========
A.aa();
try {
B.bb();
} catch(Exception e) {
A.rollbackAa();
}
try {
C.cc();
} catch(Excep</div>
</li>
<li><a href="/article/926.htm"
title="安墨移动广 告:移动DSP厚积薄发 引领未来广 告业发展命脉" target="_blank">安墨移动广 告:移动DSP厚积薄发 引领未来广 告业发展命脉</a>
<span class="text-muted">矮蛋蛋</span>
<a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a><a class="tag" taget="_blank" href="/search/%E4%BA%92%E8%81%94%E7%BD%91/1.htm">互联网</a>
<div> “谁掌握了强大的DSP技术,谁将引领未来的广 告行业发展命脉。”2014年,移动广 告行业的热点非移动DSP莫属。各个圈子都在纷纷谈论,认为移动DSP是行业突破点,一时间许多移动广 告联盟风起云涌,竞相推出专属移动DSP产品。
到底什么是移动DSP呢?
DSP(Demand-SidePlatform),就是需求方平台,为解决广 告主投放的各种需求,真正实现人群定位的精准广 </div>
</li>
<li><a href="/article/1053.htm"
title="myelipse设置" target="_blank">myelipse设置</a>
<span class="text-muted">alafqq</span>
<a class="tag" taget="_blank" href="/search/IP/1.htm">IP</a>
<div> 在一个项目的完整的生命周期中,其维护费用,往往是其开发费用的数倍。因此项目的可维护性、可复用性是衡量一个项目好坏的关键。而注释则是可维护性中必不可少的一环。
注释模板导入步骤
安装方法:
打开eclipse/myeclipse
选择 window-->Preferences-->JAVA-->Code-->Code </div>
</li>
<li><a href="/article/1180.htm"
title="java数组" target="_blank">java数组</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/java%E6%95%B0%E7%BB%84/1.htm">java数组</a>
<div>java数组的 声明 创建 初始化; java支持C语言
数组中的每个数都有唯一的一个下标
一维数组的定义 声明: int[] a = new int[3];声明数组中有三个数int[3]
int[] a 中有三个数,下标从0开始,可以同过for来遍历数组中的数
</div>
</li>
<li><a href="/article/1307.htm"
title="javascript读取表单数据" target="_blank">javascript读取表单数据</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a>
<div>利用javascript读取表单数据,可以利用以下三种方法获取:
1、通过表单ID属性:var a = document.getElementByIdx_x_x("id");
2、通过表单名称属性:var b = document.getElementsByName("name");
3、直接通过表单名字获取:var c = form.content.</div>
</li>
<li><a href="/article/1434.htm"
title="探索JUnit4扩展:使用Theory" target="_blank">探索JUnit4扩展:使用Theory</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/JUnit/1.htm">JUnit</a><a class="tag" taget="_blank" href="/search/Theory/1.htm">Theory</a>
<div>理论机制(Theory)
一.为什么要引用理论机制(Theory)
当今软件开发中,测试驱动开发(TDD — Test-driven development)越发流行。为什么 TDD 会如此流行呢?因为它确实拥有很多优点,它允许开发人员通过简单的例子来指定和表明他们代码的行为意图。
TDD 的优点:
&nb</div>
</li>
<li><a href="/article/1561.htm"
title="[Spring Data Mongo一]Spring Mongo Template操作MongoDB" target="_blank">[Spring Data Mongo一]Spring Mongo Template操作MongoDB</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/template/1.htm">template</a>
<div>什么是Spring Data Mongo
Spring Data MongoDB项目对访问MongoDB的Java客户端API进行了封装,这种封装类似于Spring封装Hibernate和JDBC而提供的HibernateTemplate和JDBCTemplate,主要能力包括
1. 封装客户端跟MongoDB的链接管理
2. 文档-对象映射,通过注解:@Document(collectio</div>
</li>
<li><a href="/article/1688.htm"
title="【Kafka八】Zookeeper上关于Kafka的配置信息" target="_blank">【Kafka八】Zookeeper上关于Kafka的配置信息</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/zookeeper/1.htm">zookeeper</a>
<div>问题:
1. Kafka的哪些信息记录在Zookeeper中 2. Consumer Group消费的每个Partition的Offset信息存放在什么位置
3. Topic的每个Partition存放在哪个Broker上的信息存放在哪里
4. Producer跟Zookeeper究竟有没有关系?没有关系!!!
//consumers、config、brokers、cont</div>
</li>
<li><a href="/article/1815.htm"
title="java OOM内存异常的四种类型及异常与解决方案" target="_blank">java OOM内存异常的四种类型及异常与解决方案</a>
<span class="text-muted">ronin47</span>
<a class="tag" taget="_blank" href="/search/java+OOM+%E5%86%85%E5%AD%98%E5%BC%82%E5%B8%B8/1.htm">java OOM 内存异常</a>
<div> OOM异常的四种类型:
一: StackOverflowError :通常因为递归函数引起(死递归,递归太深)。-Xss 128k 一般够用。
二: out Of memory: PermGen Space:通常是动态类大多,比如web 服务器自动更新部署时引起。-Xmx</div>
</li>
<li><a href="/article/1942.htm"
title="java-实现链表反转-递归和非递归实现" target="_blank">java-实现链表反转-递归和非递归实现</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>20120422更新:
对链表中部分节点进行反转操作,这些节点相隔k个:
0->1->2->3->4->5->6->7->8->9
k=2
8->1->6->3->4->5->2->7->0->9
注意1 3 5 7 9 位置是不变的。
解法:
将链表拆成两部分:
a.0-&</div>
</li>
<li><a href="/article/2069.htm"
title="Netty源码学习-DelimiterBasedFrameDecoder" target="_blank">Netty源码学习-DelimiterBasedFrameDecoder</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/netty/1.htm">netty</a>
<div> 看DelimiterBasedFrameDecoder的API,有举例:
接收到的ChannelBuffer如下:
+--------------+
| ABC\nDEF\r\n |
+--------------+
经过DelimiterBasedFrameDecoder(Delimiters.lineDelimiter())之后,得到:
+-----+----</div>
</li>
<li><a href="/article/2196.htm"
title="linux的一些命令 -查看cc攻击-网口ip统计等" target="_blank">linux的一些命令 -查看cc攻击-网口ip统计等</a>
<span class="text-muted">hotsunshine</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>Linux判断CC攻击命令详解
2011年12月23日 ⁄ 安全 ⁄ 暂无评论
查看所有80端口的连接数
netstat -nat|grep -i '80'|wc -l
对连接的IP按连接数量进行排序
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n
查看TCP连接状态
n</div>
</li>
<li><a href="/article/2323.htm"
title="Spring获取SessionFactory" target="_blank">Spring获取SessionFactory</a>
<span class="text-muted">ctrain</span>
<a class="tag" taget="_blank" href="/search/sessionFactory/1.htm">sessionFactory</a>
<div>
String sql = "select sysdate from dual";
WebApplicationContext wac = ContextLoader.getCurrentWebApplicationContext();
String[] names = wac.getBeanDefinitionNames();
for(int i=0; i&</div>
</li>
<li><a href="/article/2450.htm"
title="Hive几种导出数据方式" target="_blank">Hive几种导出数据方式</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/hive/1.htm">hive</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%AF%BC%E5%87%BA/1.htm">数据导出</a>
<div>Hive几种导出数据方式
1.拷贝文件
如果数据文件恰好是用户需要的格式,那么只需要拷贝文件或文件夹就可以。
hadoop fs –cp source_path target_path
2.导出到本地文件系统
--不能使用insert into local directory来导出数据,会报错
--只能使用</div>
</li>
<li><a href="/article/2577.htm"
title="编程之美" target="_blank">编程之美</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/%E9%87%8D%E6%9E%84/1.htm">重构</a>
<div>我个人的 PHP 编程经验中,递归调用常常与静态变量使用。静态变量的含义可以参考 PHP 手册。希望下面的代码,会更有利于对递归以及静态变量的理解
header("Content-type: text/plain");
function static_function () {
static $i = 0;
if ($i++ < 1</div>
</li>
<li><a href="/article/2704.htm"
title="Android保存用户名和密码" target="_blank">Android保存用户名和密码</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a>
<div>转自:http://www.2cto.com/kf/201401/272336.html
我们不管在开发一个项目或者使用别人的项目,都有用户登录功能,为了让用户的体验效果更好,我们通常会做一个功能,叫做保存用户,这样做的目地就是为了让用户下一次再使用该程序不会重新输入用户名和密码,这里我使用3种方式来存储用户名和密码
1、通过普通 的txt文本存储
2、通过properties属性文件进行存</div>
</li>
<li><a href="/article/2831.htm"
title="Oracle 复习笔记之同义词" target="_blank">Oracle 复习笔记之同义词</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/Oracle+%E5%90%8C%E4%B9%89%E8%AF%8D/1.htm">Oracle 同义词</a><a class="tag" taget="_blank" href="/search/Oracle+synonym/1.htm">Oracle synonym</a>
<div>转载请出自出处:http://eksliang.iteye.com/blog/2098861
1.什么是同义词
同义词是现有模式对象的一个别名。
概念性的东西,什么是模式呢?创建一个用户,就相应的创建了 一个模式。模式是指数据库对象,是对用户所创建的数据对象的总称。模式对象包括表、视图、索引、同义词、序列、过</div>
</li>
<li><a href="/article/2958.htm"
title="Ajax案例" target="_blank">Ajax案例</a>
<span class="text-muted">gongmeitao</span>
<a class="tag" taget="_blank" href="/search/Ajax/1.htm">Ajax</a><a class="tag" taget="_blank" href="/search/jsp/1.htm">jsp</a>
<div>数据库采用Sql Server2005
项目名称为:Ajax_Demo
1.com.demo.conn包
package com.demo.conn;
import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;
//获取数据库连接的类public class DBConnec</div>
</li>
<li><a href="/article/3085.htm"
title="ASP.NET中Request.RawUrl、Request.Url的区别" target="_blank">ASP.NET中Request.RawUrl、Request.Url的区别</a>
<span class="text-muted">hvt</span>
<a class="tag" taget="_blank" href="/search/.net/1.htm">.net</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/C%23/1.htm">C#</a><a class="tag" taget="_blank" href="/search/asp.net/1.htm">asp.net</a><a class="tag" taget="_blank" href="/search/hovertree/1.htm">hovertree</a>
<div>
如果访问的地址是:http://h.keleyi.com/guestbook/addmessage.aspx?key=hovertree%3C&n=myslider#zonemenu那么Request.Url.ToString() 的值是:http://h.keleyi.com/guestbook/addmessage.aspx?key=hovertree<&</div>
</li>
<li><a href="/article/3212.htm"
title="SVG 教程 (七)SVG 实例,SVG 参考手册" target="_blank">SVG 教程 (七)SVG 实例,SVG 参考手册</a>
<span class="text-muted">天梯梦</span>
<a class="tag" taget="_blank" href="/search/svg/1.htm">svg</a>
<div>SVG 实例 在线实例
下面的例子是把SVG代码直接嵌入到HTML代码中。
谷歌Chrome,火狐,Internet Explorer9,和Safari都支持。
注意:下面的例子将不会在Opera运行,即使Opera支持SVG - 它也不支持SVG在HTML代码中直接使用。 SVG 实例
SVG基本形状
一个圆
矩形
不透明矩形
一个矩形不透明2
一个带圆角矩</div>
</li>
<li><a href="/article/3339.htm"
title="事务管理" target="_blank">事务管理</a>
<span class="text-muted">luyulong</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/%E4%BA%8B%E5%8A%A1/1.htm">事务</a>
<div>事物管理
spring事物的好处
为不同的事物API提供了一致的编程模型
支持声明式事务管理
提供比大多数事务API更简单更易于使用的编程式事务管理API
整合spring的各种数据访问抽象
TransactionDefinition
定义了事务策略
int getIsolationLevel()得到当前事务的隔离级别
READ_COMMITTED </div>
</li>
<li><a href="/article/3466.htm"
title="基础数据结构和算法十一:Red-black binary search tree" target="_blank">基础数据结构和算法十一:Red-black binary search tree</a>
<span class="text-muted">sunwinner</span>
<a class="tag" taget="_blank" href="/search/Algorithm/1.htm">Algorithm</a><a class="tag" taget="_blank" href="/search/Red-black/1.htm">Red-black</a>
<div>
The insertion algorithm for 2-3 trees just described is not difficult to understand; now, we will see that it is also not difficult to implement. We will consider a simple representation known</div>
</li>
<li><a href="/article/3593.htm"
title="centos同步时间" target="_blank">centos同步时间</a>
<span class="text-muted">stunizhengjia</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E9%9B%86%E7%BE%A4%E5%90%8C%E6%AD%A5%E6%97%B6%E9%97%B4/1.htm">集群同步时间</a>
<div>做了集群,时间的同步就显得非常必要了。 以下是查到的如何做时间同步。 在CentOS 5不再区分客户端和服务器,只要配置了NTP,它就会提供NTP服务。 1)确认已经ntp程序包: # yum install ntp 2)配置时间源(默认就行,不需要修改) # vi /etc/ntp.conf server pool.ntp.o</div>
</li>
<li><a href="/article/3720.htm"
title="ITeye 9月技术图书有奖试读获奖名单公布" target="_blank">ITeye 9月技术图书有奖试读获奖名单公布</a>
<span class="text-muted">ITeye管理员</span>
<a class="tag" taget="_blank" href="/search/ITeye/1.htm">ITeye</a>
<div>ITeye携手博文视点举办的9月技术图书有奖试读活动已圆满结束,非常感谢广大用户对本次活动的关注与参与。 9月试读活动回顾:http://webmaster.iteye.com/blog/2118112本次技术图书试读活动的优秀奖获奖名单及相应作品如下(优秀文章有很多,但名额有限,没获奖并不代表不优秀):
《NFC:Arduino、Andro</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>