经典深度学习网络(LeNet-5、AlexNet、VGG、ResNet、GoogleNet)
总结经典的深度学习模型(pytorch、tensorflow实现)
参考书目:《深度学习算法原理与编程实战》 | 蒋子阳著
一、LeNet-5
1、LeNet-5网络简介
LeNet-5是一个专为手写数字识别而设计的最经典的卷积神经网络,被誉为早期卷积神经网络中最有代表性的实验系统之一。LeNet-5 模型由Yann LeCun教授于1998年提出, 在MNIST数据集上,LeNet-5模型可以达到大约99.4%的准确率。与近几年的卷积神经网络比较,LeNet-5的网络规模比较小,但却包含了构成现代CNN网络的基本组件——卷积层、 Pooling层、全连接层。
2、模型结构
网络一共有8层(包含输入和输出在内),基本网络架构如下:

备注:图中C表示卷积层 ,S表示池化层。
- Layer1:Input层,输入图片大小32×32×1,MNIST数据集大小是28×28,所以输入reshape为32×32是希望高层特征监测感受野的中心能够收集更多潜在的明显特征。
- Layer2:Conv1层——卷积层,有6个Feature Map,即Convolutions操作时的卷积核的个数为6,卷积核大小为5×5,该层每个单元和输入层的25个单元连接,padding没有使用,stride为1。
- Layer3:S2为下采样层(Subsampling),6个14×14的特征图,是上一层的每个特征图经过2×2的最大池化操作得到的,且长宽步长都为2,S2层每个特征图的每一个单元与C3对应特征图中2×2大小的区域连接。
- Layer4:Conv3层,由上一层的特征图经过卷积操作得到,卷积核大小为5×5,卷积核个数为16,即该层有16个特征图,但并不是与上一层的6个特征图一一对应,而是有固定的连接关系,例如第一个特征图只与Layer3的第1、2、3个特征图的有卷积关系。
- Layer5:S4层,16个5×5的特征图,每个特征图都是由第四层经过一个2×2的最大池化操作得到的,意义同Layer3。
- Layer6:Conv5,120个特征图,是由上一层输出经过120个大小为5×5的卷积核得到的,没有padding,stride为1,上一层的16个特征图都连接到该层的每一个单元,所以这里相当于一个全连接层。
- Layer7:F6是全连接层,有84个神经元,与上一层构成全连接的关系,再经由Sigmoid激活函数传到输出层。
- Layer8:Output层也是一个全连接层,共有10个单元,对应0~9十个数字。本层单元计算的是径向基函数: y i = ∑ j ( x − w i , j ) 2 y_i =\sum_{j}(x-w_{i,j})^2 yi=∑j(x−wi,j)2 ,RBF的计算与第i个数字的比特图编码有关,对于第i个单元,yi的值越接近0,则表示越接近第i个数字的比特编码,即识别当前输入的结果为第i个数字。
3、pytorch和tensorflow实现LeNet-5网络的MNIST手写数字识别
代码地址:GitHub
LeNet-5网络规模比较小,所以它无法很好的处理类似ImageNet的比较大的图像数据集。
二、AlexNet
1、AlexNet网络简介
2012年, Hinton的学生Alex Krizhevsky借助深度学习的相关理论提出了深度卷积神经网络模型AlexNet。卷积层的数量有5个,池化层的数量有3个,也就是说,并不是所有的卷积层后面都连接有池化层。在这些卷积与池化层之后是3个全连层,最后一个全连层的单元数量为1000个,用于完成对ImageNet数据集中的图片完成1000分类(具体分类通过Softmax层实现)。
2、模型结构
网络结构如下图所示,有两个子网络,可以用GPU分别进行训练(特点1),两个GPU之间存在通信:
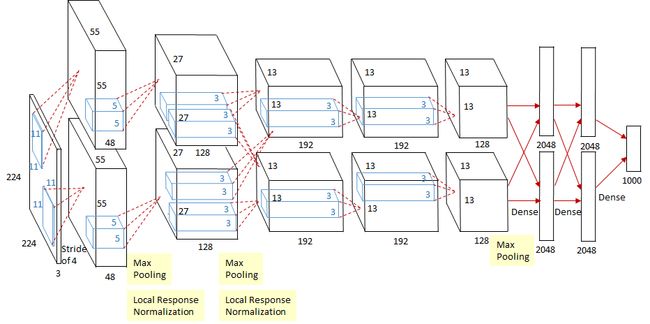
- 第一段卷积: 使用了96个11×11卷积核对输入的224×224×3的RGB图像进行卷积操作,长宽移动步长均为4,得到的结果是96个55x55的特征图;得到基本的卷积数据后,第二个操作是ReLU去线性化(这是AlexNet的特点2);第三个操作是LRN局部归一化(AlexNet首次提出,特点3);第四个操作是3×3的max pooling,步长为2。
- 第二段卷积:流程类似第一阶段,用到的核大小不同,256个深度为3(因为是三通道图像)的5×5的卷积核,stride为1×1,然后ReLU去线性化,再是LRN局部归一化,最后是3×3的最大池化操作,步长为2。
- 第三段卷积:输入上一阶段的特征图,首先经过384个3×3的卷积核,步长参数为1,然后再经过ReLU去线性化,这一阶段没有LRN和池化。
- 第四段卷积:首先经过384个3×3的卷积核,步长参数为1,然后再经过ReLU去线性化。
- 第五段卷积:首先经过256个3×3的卷积核,步长参数为1,然后再经过ReLU去线性化,最后是3×3的最大池化操作,步长为2。
- 第六段全连接(FC):以上过程完了以后经过三层全连接层,前两层有4096个单元,与前一层构成全连接关系,然后都经过一个ReLU函数,左后一层是1000个单元的全连接层(Softmax层),训练时这几个全连接层使用了Dropout(特点4)。
备注:数据增强的运用(特点5),在训练的时候模型随机从大小为256×256的原始图像中截取224×224大小的区域,同时还得到图像水平翻转的镜像图,用以增加样本的数量。在测试时,模型会首先截取一张图片的四个角加中间的位置,并进行左右翻转,这样会获得10张图片,将这10张图片作为预测的输入并对得到的10个预测结果求均值,就是这张图片最终的预测结果。
3、pytorch和tensorflow实现
代码地址:Github
三、VGGNet
1、VGGNet网络简介
2014年ILSVRC图像分类竞赛的第二名是VGGNet网络模型,其 top-5 错误率为 7.3%,它对卷积神经网络的深度与其性能之间的关系进行了探索。在将网络迁移到其他图片数据上进行应用时, VGGNet比GoogleNet有着更好的泛化性。此外,VGGNet模型是从图像中提取特征的CNN首选算法。
2、模型结构
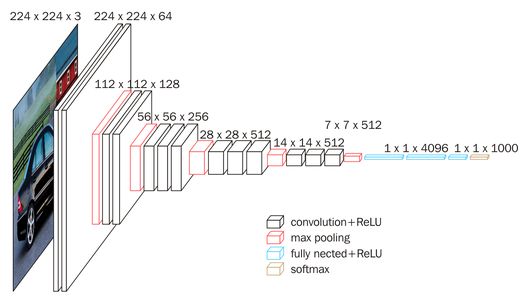
网络的结构非常简洁,在整个网络中全部使用了大小相同的卷积核 (3×3 )和 最大油化核 (2x2 )。VGGNet模型通过不断地加深网络结构来提升性能,通过重复堆叠的方式,使用这些卷积层和最大池化层成功地搭建了11~19层深的卷积神经网络。下表是这些网络的结构组成层:

表中的conv3表示大小为3×3的卷积核,conv1则是1×1的卷积核,参数量主要集中在全连接层,其他卷积层的参数共享和局部连接降低了参数的数量。表中五个阶段的卷积用于提取特征,每段卷积后面都有最大池化操作,目的是缩小图像尺寸。多个卷积的堆叠可以降低参数量,也有助于学习特征,C级的VGG用到conv1是为了在输入通道数和输出通道数不变(不发生数据降维)的情况下实现线性变换,对非线性提升效果有较好的作用,但是换成conv3效果更好。VGG19的效果只比VGG16好一点点,所以牛津的研究团队就停止在VGG19层了,不再增加更多层数了。下图是VGG-16的网络构架图:
3、pytorch和tensorflow实现
这里实现的是VGG-16网络(pytorch中只是搭建了网络),代码地址:GitHub
在通常的网络训练时,VGGNet通过Multi-Scale方法对图像进行数据增强处理,我自己在训练MNIST的时候没有用数据增强。因为卷积神经网络对于图像的缩放有一定的不变性,所以将这种经过 Multi-Scale多尺度缩放裁剪后的图片合在一起输入到卷积神经网络中训练,可以增加网络的这种不变性(不变性的理解:pooling操作时,对局部感受野取其极大值,如果图像在尺度上发生了变化,有一定概率在尺度变化后对应的感受野取到的极大值不变,这样就可以使特征图不变,同样也增加了一定的平移不变性)。在预测时也采用了Multi-Scale的方法,将图像Scale到一个尺寸再裁剪并输入到卷积网络计算。输入到网络中的图片是某一张图片经过缩放裁剪后的多个样本,这样会得到一张图片的多个分类结果,所以紧接着要做的事就是对这些分类结果进行平均以得到最后这张图片的分类结果,这种平均的方式会提高图片数据的利用率并使分类的效果变好。
四、InceptionNet-V3
1、InceptionNet-V3网络简介
Google的InceptionNet首次亮相是在2014年的ILSVRC比赛中,称为 Inception-V1,后来又开发了三个版本,其中InceptionNet-V3最具代表性。相比VGGNet, Inception-V1增加了深度,达到了22层,但是其参数却只有500万个左右(SM),这是远低于AlexNet(60M 左右)和VGGNet (140M 左右)的,是因为该网络将全连层和一般的卷积中采用了稀疏连接的方法(Hebbian原理)。根据相关性高的单元应该被聚集在一起的结论,这些在同一空间位置但在不同通道的卷积核的输出结果也是稀疏的,也可以通过类似将稀疏矩阵聚类为较为密集的子矩阵的方式来提高计算性能。沿着这样的一个思路,Google团队提出了Inception Module结构来实现这样的目标。
2、模型结构
网络中主要用到了稀疏连接的思想提出了Inception Module,其借鉴了论文《Network in Network》的做法,即提出的MLPConv——使用MLP对卷积操作得到的特征图进行进一步的操作,从而得到本层的最终输出特征图,这样可以允许在输出通道之间组合信息,以此提升卷积层的表达能力。在InceptionNet-V3中,Inception Module的基本结构如下图: 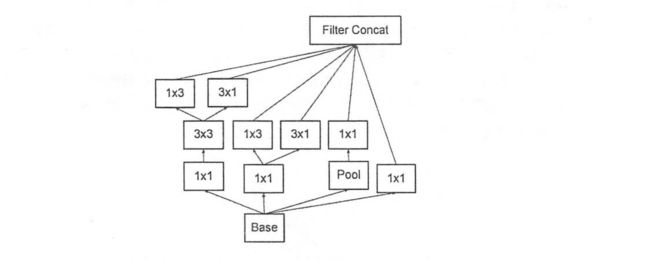
结构中的Filter Concat是将特征图在深度方向(channel维度)进行串联拼接,这样可以构建出符合Hebbian原理的稀疏结构。conv1的作用是把相关性高、同一空间位置不同通道的特征连接在一起,并且计算量小,可以增加一层特征变换和非线性化,最大池化是为了增加网络对不同尺度的适应性。在Inception V2中首次用到了.批标准化(Batch Normalization),V3在V2基础上的Module改进之处就是在分支中使用分支,将二维卷积拆分为两个非对称一维卷积,这种卷积可以在处理更丰富的空间特征以及增加特征多样性等方面做得比普通卷积更好。多个这种Inception Module堆叠起来就形成了InceptionNet-V3,其网络构架如下图,整个网络的主要思想就是找到一个最优的Inception Module结构,更好的实现局部稀疏的稠密化。
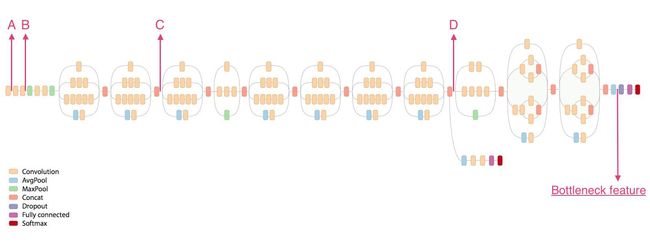
3、使用InceptionNet-V3完成模型迁移学习
- 迁移学习:随着卷积神经网络模型层数的加深以及复杂度的逐渐增加,训练这些模型所需要的带有标注的数据也越来越多。比如对于ResNet,其深度有 152 层,使用ImageNet数据集中带有标注的 120 万张图片才能将其训练到 96.5% 的准确率。尽管这是个比较不错的准确率,但是在真实应用中,几乎很难收集到这么多带有标注的图片数据,而且这些数据训练一个复杂的卷积神经网络也要花费很长的时间 。迁移学习的出现就是为了解决上述标注数据以及训练时间的问题。所谓迁移学习,就是将一个问题上训练好的模型通过简单的调整使其适用于 一个新的问题,例如在 Google 提供的基于 ImageNet 数据集训练好的 Inception V3 模型的基础上进行简单的修改,使其能够解决基于其他数据集的图片分类任务。被修改的全连接层之前的一个网络层叫做瓶颈层(Bottleneck,这里是V3中最后一个Dropout层)。
- 模型迁移学习tensorflow代码地址:Github
五、ResNet
1、ResNet网络简介
ResNet (Residual Neural Network)由微软研究院的何情明等 4 名华人提出,网络深度达到了152 层,top-5 错误率 只有3.57% 。虽然ResNet的深度远远高于 VGGNet,但是参数量却比 VGGNet 低,效果也更好。ResNet 中最创新就是残差学习单元(Residual Unit)的引入,它是参考了瑞士教授 Schmidhuber 的论文《Training Very Deep Networks》中提出的 Highway Network。 Highway Network 的出现是为了解决较深的神经 网络难以训练的问题,主要思想是启发于LSTM的门(Gate)结构,使得有一定比例的前一层的信息没有经过矩阵乘法和非线性变换而是直接传输到下一层,网络要学习的就是原始信息应该以何种比例保留下来。后来残差网络的学习单元就受益于Highway Network加深网络层数的做法。
2、模型结构
随着网络加深,由于反向传播过程的叠乘可能出现梯度消失,结果就是准确率下降,为此ReNet中引入残差学习单元(如图所示,2层和3层),思想就是对于一个达到了准确率饱和的较浅网络,在后面加几个全等映射层允许初始信息直接传到下一层( y = x y=x y=x)时,误差不会因此而增加,并且网络要学习的就是原来输出 H ( x ) H(x) H(x)与原始输入 x x x的残差 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x。
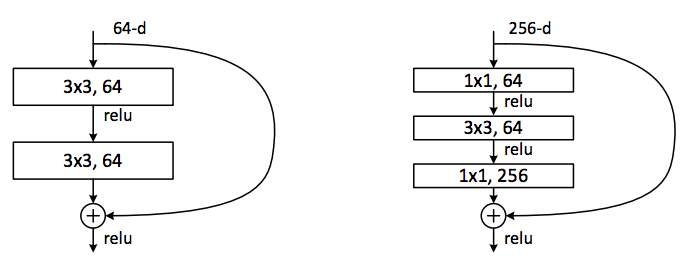
将多个残差单元堆叠起来就组成了ResNet网络,如下图所示是一个34层的残差网络:

旁边的支线就是将上一层残差单元的输出直接参与到该层的输出,这样的连接方式被称为Shortcut和Skip Connection,这样可以一定程度上保护信息的完整性。最后在改进的ResNet V2中通过该连接使用的激活函数(ReLU)被更换为Identity Mappings( y = x y=x y=x),残差单元都使用了BN归一化处理,使得训练更加容易并且泛化能力更强。
3、pytorch和tensorflow实现ResNet
代码地址:GitHub
这里只是搭建的网络,没有进行任何任务的训练,可以在自己的数据集上训练试一下。