DCANet: Learning Connected Attentions for Convolutional Neural Networks
论文链接:https://arxiv.org/pdf/2007.05099.pdf
源码:https://github.com/ma-xu/DCANet/blob/master/models/resnet/resnet_se_dca.py
虽然自我注意机制在许多视觉任务中显示出良好的效果,但它一次只考虑当前的特征,这种方式不能充分利用注意力机制信息。在本文中,作者提出了深度连接注意网络(DCANet),它可以在不改变内部结构的情况下增强CNN模型中的注意模块。该结构是将相邻的注意力模块连接起来,使信息在注意力模块之间流动成为可能。通过DCANet,CNN模型中的所有注意力模块都被联合训练,从而提高了注意学习的能力。DCANet是通用的。它不限于特定的注意力模块或基本网络架构。
一、文章简述
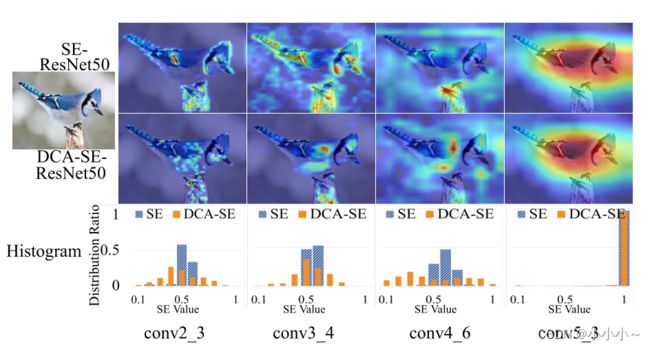
深度连接注意力网络(DCANet),从先前的注意力图中收集信息,并将其传输到下一个注意力模块,使注意块相互协作,从而提高注意力机制的学习能力。在不修改内部结构的情况下,DCANet在注意块之间引入了一系列连接。它可以应用于各种自我注意模块,例如,SENet、CBAM、SKNet等等,而不考虑基础架构的选择。下图展示了基于SE-ResNet50的DCANet的能力。ResNet50包含相邻块之间的跳连接。然而,这些跳连接并不能改善注意力学习。相比之下,DCANet在注意力模块之间包含注意力连接,这不同于卷积块之间的跳连接。
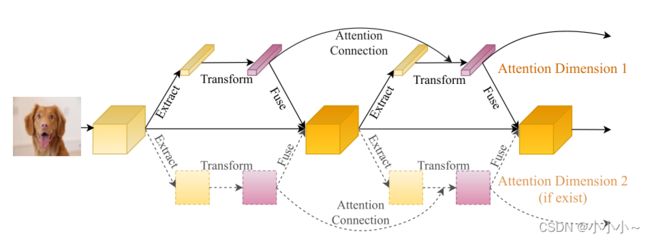
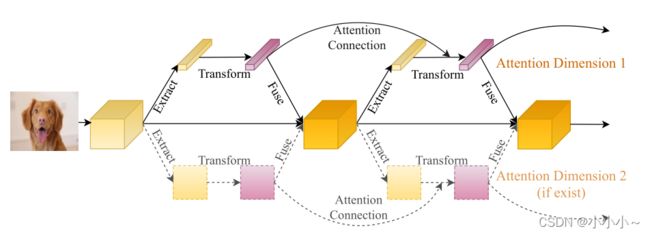
通过分析各种注意力模块的内部结构,本文提出了一种不局限于特定注意力模块的通用连接方案。通过参数化加法将之前的注意特征和当前提取的特征进行合并,以确保所有注意块之间的信息以前馈方式流动,并防止注意信息在每个步骤中发生很大变化。下图展示了该方法的整体流程 。将前一个注意力模块中转换模块的输出连接到当前注意力模块中提取模块的输出。在多个注意维度的背景下,沿着每个维度连接注意力图。下图展示了一个有两个注意维度的例子。它可以是一个、两个甚至更多的注意维度。
如下图,SE块由两个完全连接的层组成,而GC块包括几个卷积层。因此,直接提供一个足以涵盖大多数注意块的通用标准连接模式并不容易。为了解决这个问题,作者研究了最先进的注意块,并总结了它们的处理和组成。
下图从左到右为:SE block, G E θ − GEθ^− GEθ− block、GC block和SK block。“⊕” 表示按元素求和,“⊗” 表示元素乘法。
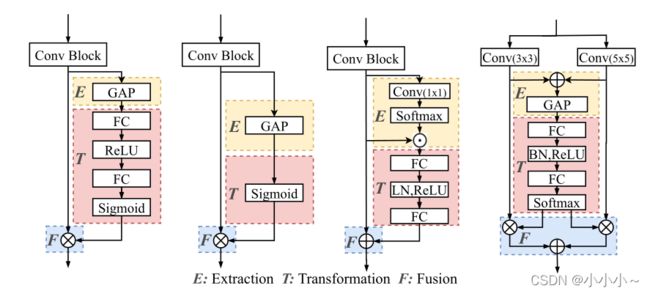
以上注意力模块由三个组成部分组成:上下文提取、转换和融合。提取作为一个简单的特征抽取器,变换将提取的特征转换为一个新的非线性注意空间,而融合将注意和原始特征合并。这些组件是通用的,不限于特定的注意块。上图举例说明了四个著名的注意力模块及其使用三个组件进行的建模。
Extraction :用于从特征图中收集特征信息。对于给定的特征映射 X ∈ R C × W × H X∈R^{C×W×H} X∈RC×W×H 是由卷积块产生的,通过提取器 g : G = g ( X , w g ) g:G=g(X,w_g) g:G=g(X,wg)从X中提取特征,其中 w g w_g wg是提取操作的参数,g是输出。当g是无参数操作时,就不需要 w g w_g wg(比如池化操作)。g的灵活性使g根据提取操作呈现不同的形状。例如,SENet和GCNet将特征图X收集为向量 ( G ) ∈ R C (G)∈R^C (G)∈RC, 而CBAM中的空间注意模块将特征映射收集到张量 G ∈ R 2 × W × H G∈ R^{2×W×H} G∈R2×W×H
Transformation处理从提取模块中收集的特征,并将其转换为非线性注意力空间。形式上,将t定义为特征转换操作,注意力模块的输出可以表示为 T = t ( G , w t ) T=t(G,w_t) T=t(G,wt)。这里, w t w_t wt表示变换操作中使用的参数,T表示提取模块的输出。
Fusion:将注意力图与原始卷积块的输出进行集成。注意力引导的输出 X ′ ∈ R C × W × H X^{'}∈ R^{C×W×H} X′∈RC×W×H可以表示为 X i ′ = T i ∗ X i X^{'}_i= Ti*X_i Xi′=Ti∗Xi,其中i是特征映射的索引,*表示融合函数;*在按比例缩放设计时执行元素乘法,否则执行求和。
二、实现细节
接下来,使用前面提到的注意力成分提出了一个广义注意力连接模式。无论其细节如何,注意力模块都可以建模为:
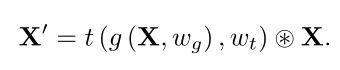
转换组件生成的注意力图对于注意力学习至关重要。为了构建连接注意力,将先前的注意映射提供给当前转换组件,该组件合并先前的转换输出和当前提取输出。这种连接设计确保当前转换模块从提取的特征和之前的注意信息中学习。由此产生的注意模块可以描述为:
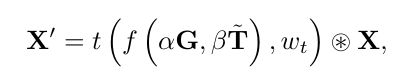
其中 f ( ⋅ ) f(·) f(⋅)表示连接函数,α和β是可学习的参数, T ∽ \overset {\backsim}{T} T∽是前一个注意块生成的注意图。在某些情况下(例如SE和GE), T ∽ \overset {\backsim}{T} T∽被缩放到(0,1)的范围。对于这些注意力模块,我们将 T ∽ \overset {\backsim}{T} T∽乘以 E ∽ \overset {\backsim}{E} E∽以匹配尺度,其中 E ∽ \overset {\backsim}{E} E∽是前一个注意块中提取组件的输出。如果α设置为1,β设置为0,则不使用注意力连接,DCA增强的注意块将变为普通注意力模块。也就是说,vanilla network是DCA增强型注意力网络的一个特例。
Direct Connection,通过直接添加这两个项来实例化 f ( ⋅ ) f(·) f(⋅)。连接功能可以表示为:
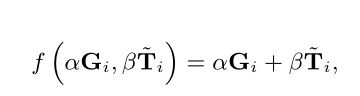
其中i是特征的索引。 T ∽ \overset {\backsim}{T} T∽可被视为G的增强。
Weighted Connection: 直接连接可以通过使用加权求和来增强。为了避免引入额外的参数,使用 α G αG αG和 β T βT βT计算权重。连接函数表示为
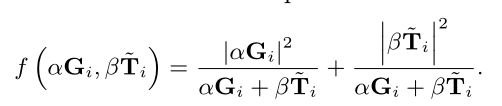
与直接连接相比,加权连接引入了 α G αG αG和 β T βT βT之间的竞争。此外,它可以很容易地扩展为softmax形式,对琐碎的特征不那么敏感。从实验结果表明,结果对连接模式不敏感,表明性能改善更多地来自注意块之间的连接,而不是连接功能的特定形式。
Size Matching
在CNN模型的不同阶段生成的特征图可能有不同的大小。因此,相应的注意力图的大小也可能会有所不同,这种不匹配使得DCANet不可能在这两个阶段之间应用。为了解决这个问题,作者沿着通道和空间维度自适应地匹配注意力图的形状。
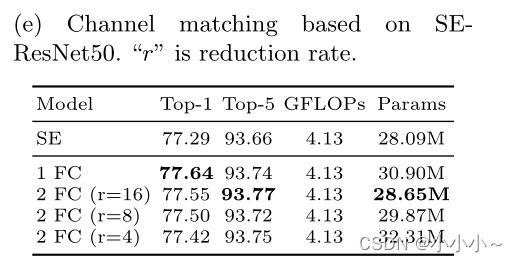
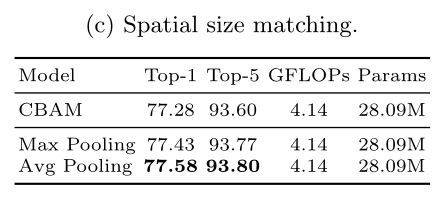
对于通道,使用全连接层(然后是LN和ReLU)匹配大小,将C0通道转换为C通道,其中C0和C分别指以前和当前通道的数量。为了清晰起见,省略了偏差,通道大小匹配引入的参数为C0×C。为了进一步减少注意力连接中的参数负担,通过两个轻量级全连接层重新构造了直接全连接层;输出大小分别为C/r和C,其中r是压缩率。这种修改大大减少了引入的参数数量。通道规模匹配策略的影响如下。
为了匹配空间分辨率,一个简单而有效的策略是采用平均池化层。将步幅和感受野大小设置为分辨率降低的范围。Max pooling只考虑部分信息,而不是整个注意信息。除了池化运算,另一种解决方案是可学习的卷积运算。然而它引入了许多参数,并且不能很好地推广。

Multi-dimensional attention connection:一些注意力模块关注不止一个注意维度。例如,BAM和CBAM沿着通道和空间维度推断注意力图。受Exception和MobileNet的启发,作者一次为一个注意维度设计注意力连接。为了构建一个多维注意块,将注意力图与每个维度连接起来,并确保不同维度的连接相互独立如下。这种注意力连接的解耦带来了两个好处:
1)减少了参数数量和计算开销;
2) 每个维度都可以关注其内在属性。
三、实验结果
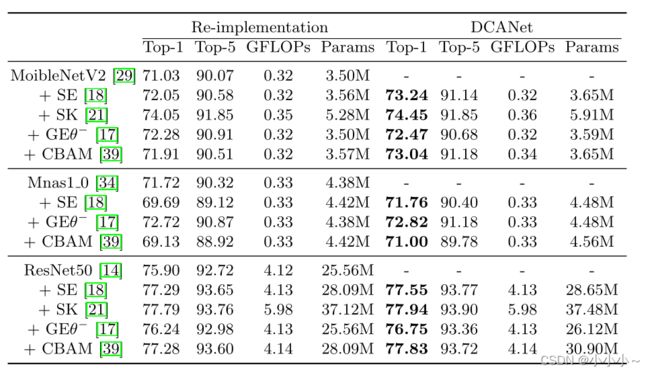
ImageNet验证集上的单一作物分类准确率(%)。重新训练所有模型,并在“重新实施”栏中报告结果。相应的DCANet变体显示在“DCANet”列中。最好的指标被标记为粗体。“-”意味着没有实验,因为DCA是为基本网络中不存在的注意块设计的。
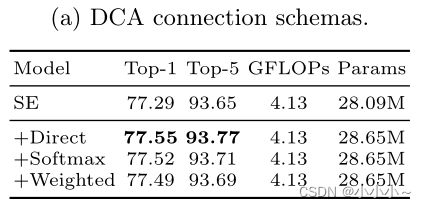
Connection Schema如上所示,所有三种连接模式的性能都优于SE-ResNet50。这表明性能的提高来自注意块之间的连接,而不是特定的连接模式。此外,这三种连接模式的前1名和前5名的准确性几乎没有差异(77.55%对77.52%对77.49%)。默认情况下,使用直接连接,与其他连接相比,这简化了实现。
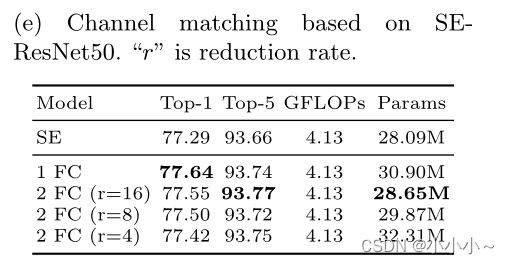
Size matching:使用SE-ResNet50进行实验。使用“1 FC”表示直接匹配,使用“2 FC”表示两个轻量级全连接层。上表给出了结果。直接应用一个完全连接的层可以实现最佳的top-1精度,而另一方面,在两个完全连接的层中,将还原率r设置为16可以减少参数的数量,并实现可比的结果。对于空间分辨率,采用平均池来降低分辨率。在下表中给出了结果。与平均池化的性能相比,最大池化的性能稍差,这表明所有注意信息都应该传递给后续的注意力模块。
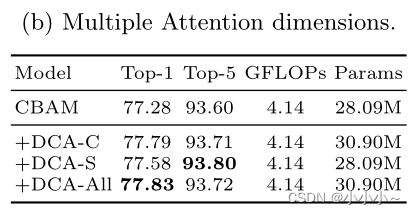
Multiple Attention dimensions:作者使用CBAM-ResNet50作为baseline,因为CBAM模块同时考虑了通道和空间注意。首先将DCANet与每个注意维度分别整合,然后将它们同时整合。使用DCA-C/DCA-S来表示在通道\空间注意上应用DCANet,DCA都表示在CBAM-ResNet50的两个注意维度上应用了DCA模块。
从表中可以看出,在任一维度上应用DCANet肯定会提高精度。由此,作者注意到两个有趣的观察结果:1)改进略有不同:将DCANet应用于通道注意比空间注意多获得0.2%的改进。
2) 与单一维度相比,将DCA应用于两个注意维度可以获得更好的性能。虽然DCA All的改善大于单独使用通道或空间,但总体上小于单个改善的总和。
为了更好地理解之前的注意力信息如何有助于注意学习,作者测量了每个注意力连接的贡献率。将贡献率计算为β/(α+β)。因此,先前注意力的贡献率在[0,1]的范围内。以ResNet50为基础网络,在SE、SK和CBAM模块上评估DCANet。
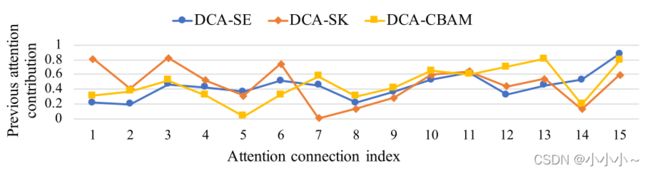
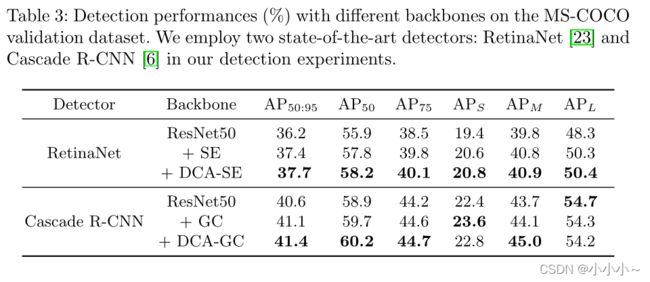
贡献率彼此不同,表明每个注意模块都有其自身的固有属性,并且贡献率不遵循特定的范例。同时,有趣的是,从第7到第13个连接中,所有注意模块的贡献率与其他连接相比是稳定的。显然,第7到第13个连接是ResNet第3阶段的连接。可以看出DCANet将在很大程度上提高后续层的特征提取能力。

如上所示。与CBAM-ResNet50和ResNet50形成鲜明对比的是,DCA-CBAM-ResNet50密切关注狗,在第3阶段几乎没有激活不相关的区域。
第二,所有注意模块在第14个连接中的贡献率接近20%,然后在最后一个连接中扩大。总的来说,所有连接中的贡献率总是大于0,这意味着之前的注意力总是对当前注意块中的注意学习有贡献。
class CSELayer(nn.Module):
def __init__(self,in_channel, channel, reduction = 16):
super(CSELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace = True),
nn.Linear(channel // reduction, channel),
nn.Sigmoid()
)
if in_channel != channel:
self.att_fc = nn.Sequential(
nn.Linear(in_channel, channel),
nn.LayerNorm(channel),
nn.ReLU(inplace=True)
)
self.conv = nn.Sequential(
nn.Conv2d(2, 1, kernel_size=1),
nn.LayerNorm(channel),
nn.ReLU(inplace=True)
)
def forward(self, x):
b, c, _, _ = x[0].size()
gap = self.avg_pool(x[0]).view(b, c)
if x[1] is None:
all_att = self.fc(gap)
else:
pre_att = self.att_fc(x[1]) if hasattr(self, 'att_fc') else x[1]
all_att = torch.cat((gap.view(b, 1, 1, c), pre_att.view(b, 1, 1, c)), dim=1)
all_att = self.conv(all_att).view(b, c)
all_att = self.fc(all_att)
return {0: x[0] * all_att.view(b, c, 1, 1), 1: gap*all_att}