
最近看到一篇文章,讲服务限流主题的,其中罗列了各种思路和技术实现的细枝末节。
其中关于滑动时间窗口的一个代码示例,让我陷入了沉思。。(文章已经被作者删除了。。)
道理我都懂,但这个示例代码让我很难读懂,一度让我选入了大脑死机状态。
遇事不决,该怎么做呢?莽就完了!
首先我们要明确的是,我们追求的方向,是尽可能的高效,简单。
高效需要体现在资源占用率上;简单针对的是算法理解复杂度上。
一些文章中介绍的滑动时间窗口算法,是记录每次合法请求的时刻日志,然后靠当前请求时间与时间窗口大小做一个范围查询数据并求和,来判断是否超过阈值。这种算法的实现思路简单,但却不够高效:假如我们的阈值设置的比较大,如10W,那意味着我们需要至少记录10W个日志数据,这是不满足我们对高效的要求的。
滑动时间窗口之所以会复杂,我认为源于人们无法很好的理解时间!
时间的概念太过于抽象,甚至一些伟大的人都曾尝试否定它的存在。
如果你经历过环球旅行你可能就会感受到时间的“混乱”(时区切换);如果你生活在北美,每年的某一天,你都会感觉到混乱(夏令时切换);如果你所在的项目是时区敏感的,你应该就能明白这种痛苦吧~
记得看过一个视频,曾经有一份古老的职业,工作职责就是设置时区的火车时刻表!(有点扯远了~)
回到主题,其实滑动时间窗口算法的目标很简单,仅仅是要求满足任意一个给定的时间窗口内请求都不能超过阈值!
考虑到时间是线性的,我们用下图来视觉化这个目标:
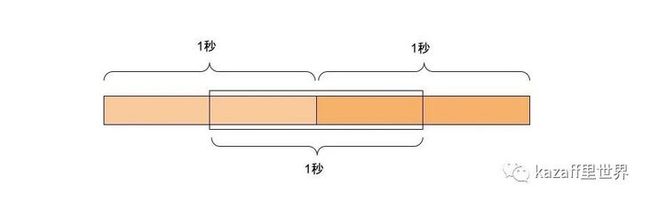
上面这种图,很容易就刺激我们的大脑,让我们将给定的时间窗口拆分,拆分成更小的单元窗口,而真正“滑动”的是这些单元窗口,如下图所示:
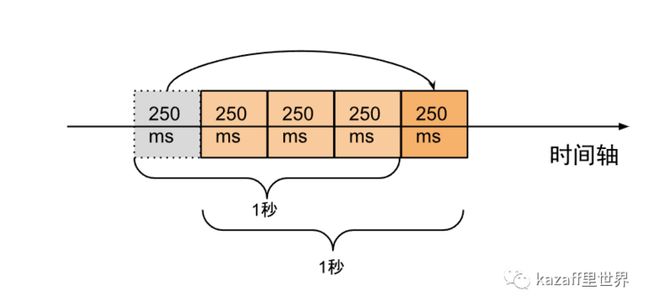
形象吗?
还有更像的!不知道你玩过诺基亚手机上的8bit贪食蛇游戏吗?
每次视觉上的滑动,其实只是最左边的单元格消失,然后最右边创建一个新的单元格,循环往复。
当然我们不需要这么做,毕竟我们不考虑视觉效果。。
那么比较直观对应的一种常用数据结构,就是链表。我相信熟悉链表使用的朋友应该脑子里已经有画面了吧~
不过“滑动”毕竟是种动作,谁来触发呢?交给定时任务吗?假如一个单元窗口表达250毫秒,那我们搞一个定时任务,每250毫秒执行一次,把链表的表头节点删除,并在表尾添加新的节点~~(这么说来,其实数组也可以)
但总感觉不够优雅,假如我们的服务比较冷门,几分钟才一次调用(妈的,这种情况干啥还搞限流。。),那这个定时任务傻傻的维护滑动窗口感觉很浪费资源啊。。
在我们的这个场景里,除了时间是“活”的,还有一个角色也有生命的:请求!
但是它们有一点不同:时间是规律的,可预期的;但请求是随机的,不可规划的!
这也是我文章开头提到的那个博主提供的代码示例的一个问题,他就是靠请求发生的时间点来滑动窗口,而且全部单元窗口的开始时间都是相同的。
这直接导致“滑动”失去了意义,退化成了固定时间窗口。。。
那么真的就不能依靠请求来设计算法吗?非也。只是用起来需要转换一下思维。
我记得之前在看技术文章的时候,有注意到一种称为时间轮的算法,我直觉上觉得可以用在这里。
那么我们尝试设计一下~~
我们假设时间窗口为4秒,阈值为2,即:任意4秒内不允许超过2次请求。
(为何是4秒?因为我实在想不出如何把一个圆等分为5份。。)
我们将最小滑动单元格定为1秒,即:一个时间窗口被拆分成了4个滑动单元窗口。
并且,每个滑动单元窗口中,记录2个元素:圈数,请求计数。
简单的将之前的滑动逻辑用时间轮来表达,如下图:
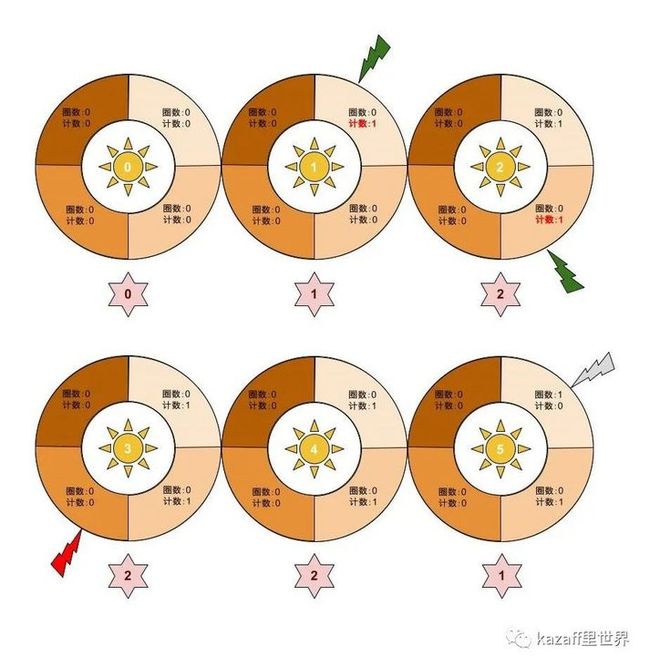
简单解释一下上图的含义:
- 同心圆表示我们的时间窗口
- 每个扇形代表滑动单元窗口
- 同心圆中的太阳表示当前秒数
- 下方的六角形中的数值表示当前所有滑动单元窗口中的计数之和
- 绿色闪电表示实际请求,且小于阈值
- 红色闪电表示实际请求,但超过阈值
- 灰色闪电表示新的请求,等待判断
这样上面的图表达的就是在一个完整的时间窗口循环中,每次请求到达,都会影响在对应时刻的滑动单元窗口的计数器。
同样的,每次请求到达,都需要先将所有滑动单元窗口的计数器求和,来判断是否已经达到阈值。
最后随着时间的推移,下一个时间窗口开始时,会覆盖对应时刻的滑动单元窗口的计数器(重置0)和圈数(+1)。
目前为止,听起来还是按照时间的推进来不停的触发滑动的。听起来我们只是换了一种形式来表达问题而已。
非也非也,请注意我们增加的圈数的概念。
所谓圈数,其实就是定位是第几个时间窗口;
而每个滑动单位窗口,则表示某个时间窗口中具体的单元格坐标。
那么任意时刻发生一个请求,我们都可以:
Math.floor(请求时刻 - 时间轮启动时刻)/时间窗口大小 = 圈数
Math.ceil(请求时刻/滑动单元窗口大小) = 坐标
有了上面这两个公式,我们就不需要“傻傻的”启动一个线程每秒“滑动”一次时间轮了。
任何一个请求一旦发生,套用公式就可以得到对应的圈数和坐标。
接下来就是一顿骚操作来判断请求是否超过阈值和更新滑块信息了:
- 若坐标指向的滑动单元格中圈数不等于请求所在的圈数,则将该坐标滑动单元格初始化(圈数设置为请求圈数,计数归0)
- 取出所有滑动单元格的信息,若(请求所在的圈数 - 单元格记录圈数 > 1),则将单元格计数归0。
- 最后判断所有滑动单元格的技术之和是否大于阈值,若是则拒绝请求,否则对应坐标的单元格计数+1,并允许请求。
请注意两点:其一是上述三步的顺序,其二是第二步的公式是大于1,而非大于等于。
其实之所以第二步,就是为了防止“套圈”,也就是前文提到的冷门服务,若间隔超过1个时间窗口才有新请求时,如何避免过期数据影响计算。
举个栗子:
我们看上图右下角的时间点:当第4秒~第5秒之间有请求时,因为请求圈数不等于单元格记录圈数,所以按照第一步的逻辑,滑动单元格记录的圈数应该为请求圈数(即1),计数归0。然后第二,三步执行完,最终可以得出结论,该请求是有效请求,并更新单元格计数为1。
继续我们的例子,假如又在第10秒~第11秒之间来了请求时,公式计算得到,请求圈数为2,请求坐标为3(坐标从1开始),如下图:
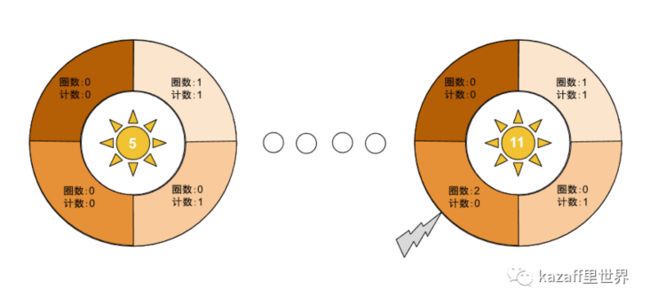
第一步处理完毕,我们的时间轮会处于上图右边的状态;
第二步会将坐标为2的单元格的计数归0(因为请求圈数-其记录圈数 > 1);
最终第三步得到的请求总数为1,小于阈值,所以这个新来的请求为有效请求。
大家可以继续往这个模型里带入各种实例,看是否都满足我们的预期。
这里就不再赘述。
莽完我们还是应该在更高的level思考一下。
目前常见的限流算法之间,各自的优势是什么?最大的差异又是什么?
当然,这方面的资料也数不胜数,我就不再这里高谈阔论了,不过还是希望看到这里的你,能认真思考一下~
都说脱离业务谈算法,都是渣男~
所以当我们选择使用某种算法时,还是应该结合具体业务,团队实际情况,项目时间要求等等方面来做全面的决策。
可能你需要确保任意固定时间窗口内请求都绝对不能超过阈值,那滑动窗口算法你可以考虑考虑(这种场景就比较少见吧,毕竟那么硬性的限制条件听起来就太过于绝对~);
假如后端服务就是需要匀速处理请求(如后端批处理事务),那漏桶算法就是首选;
如果业务需要更好的应对峰值波动(如电商抢购),似乎令牌桶算法更符合。
参考资料
限流算法实践
https://www.infoq.cn/article/...
一张图理解Kafka时间轮(TimingWheel),看不懂算我输!
https://juejin.cn/post/684490...