SpringBean的加载过程
文章目录
- spring读取配置或注解的过程
- spring的bean的生命周期
-
- 实例化Instantiation
- 初始化
- spring的BeanPostProcessor处理器
-
- 实例化阶段
- 初始化阶段
- 容器启动运行阶段
- 容器的停止销毁
- 一些关键问题
-
- FactoryBean和BeanFactory的区别?
- Spring如何解决循环依赖问题
spring读取配置或注解的过程
先通过扫描指定包路径下的Spring注解,比如@Component,@Service,@Lazy,@Sope等Spring识别的注解或者XML配置的属性(通过读取流,解析成Document,Document)然后Spring会解析这些属性,将这些属性封装到BeanDefintaion这个接口的实现类中

在SpringBoot中,我们可以采用注解配置的方式

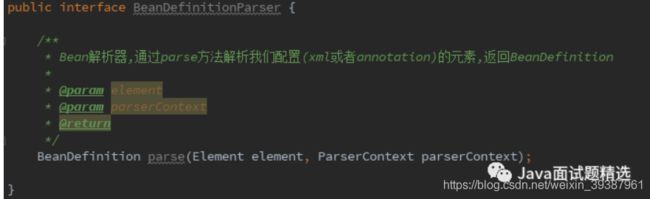
比如这个配置Bean,spring也会将className,scope,lazy等这些属性装配到PersonAction对应的BeanDefintaion中,具体采用的是BeanDefinitionParser接口中的parse(Element element,ParserContext parserContext)方法,该接口有很多不同的实现类。
通过实现类去解析注解或XML然后放到BeanDefintaion中,BeanDefintaion的作用是继承了我们的配置对象中的各种属性,重要的有这个bean的ClassName,还有是否是Singleton,对象的属性和值等(如果是单例的话,后面会将这个单例对象放入到spring的单例池中),spring后期如果需要这些属性就会直接从它里面获取。
然后再注册到一个ConcurrentHashMap中,在Spring中具体的方法就是registerBeanDefinition(),这个map存的key是对象的名字,比如Person这个对象,他的名字就是person,值是BeanDefination,它位于DefaultListableBeanFactory类下面的beanDefinitionMap类属性中,同时将所有的bean的名字放入到beanDefinitionNames这个list中,目的就是方便取beanName;
spring的bean的生命周期
spring的bean生命周期其实最核心的分为4个步骤,只要理清三个关键的步骤,其他的只是在这三个细节中添加不同的细节实现,也就是spring的bean生命周期
实例化和初始化的区别:
实例化是在jvm的堆中创建了这个对象实例,此时它只是一个空的对象,所有的属性为Null,而初始化的过程就是将对象依赖的一些属性及逆行赋值之后,调用某些方法来开启一些默认加载。比如Spring中配置的数据库属性Bean,在初始化的时候就会将这些属性填充,比如driver,jdbcurl等,然后初始化连接
实例化Instantiation
AbstractAutowireCapableBeanFactory.doCreateBean中会调用createBeanInstance()方法,该阶段主要是从beanDefinitionMap循环读取bean,获取它的属性,然后利用反射(core包下有ReflectionUtil会先强行将构造方法setAccessible(true))读取对象的构造方法(spring会自动判断是否是有参还是无参数,以及构造方法中的参数是否可用),然后再去创建实例(newInstance)
初始化
初始化主要包括两个步骤,一个是属性填充,另一个就是具体的初始化过程
-
属性赋值
PopulateBean()会对bean的依赖属性进行填充,@Autowired注解注入的属性就会发生这个阶段,假如我们的bean有很多依赖的对象,那么spring会依次调用这些依赖的对象进行实例化,注意这里可能会有循环依赖问题! -
初始化Initialization
初始化的过程包括将初始化好的bean放入到Spring的缓存中,填充我们预设的属性进一步后置处理等 -
使用和销毁Destruction
在Spring将所有的bean初始化好之后,我们的业务系统就可以调用了,而销毁主要的操作是销毁bean,主要是伴随着bean容器的关闭,此时会将spring的bean移除容器之中,此后spring的生命周期走到这一步彻底结束,不再接收spring的管理和约束
spring的BeanPostProcessor处理器
spring的另一个强大之处就是允许开发者自定义扩展bean的初始化过程,最主要的实现思路就是通过BeanPostProcessor来实现的,spring有各种前置和后置处理器,这些处理器渗透在bean创建的前前后后,穿插在spring生命周期的各个阶段,每一步都会影响着spring的bean加载过程,接下来看看具体的过程,如下:

实例化阶段
该阶段会调用对象的空构造方法进行对象的实例化,在进行实例化之后,会调用InstantiationAwareBeanPostProcessor的postProcessBeforeInstantiation方法
BeanPostProcessor(具体实现是InstantiationAwareBeanPostProcessor).postProcessBeforeInstantiation();
这个阶段允许在Bean进行实例化之前,允许开发者自定义逻辑,如返回一个代理对象,不过需要注意的是假如在这个阶段返回了一个不为null的实例,spring就会中断后续的过程。
BeanPostProcessor.postProcessAfterInstantiation();
这个阶段是Bean实例化完毕后执行的后处理操作,所有在初始化逻辑,装配逻辑之前执行
初始化阶段
- BeanPostProcessor.postProcessBeforeInitialization
该方法在bean初始化方法前被调用,SpringAOP的底层处理也是通过实现BeanPostProcessor来执行代理逻辑的 - InitializingBean.afterPropertiesSet
自定义属性值,该方法允许我们进行对对象中的属性进行设置,假如在某些业务中,一个对象的某些属性为null,但是不能显示为null,比如显示0或者其他的固定数值,我们就可以在这个方法实现中将Null指转换为特定的值 - BeanPostProcessor.postProcessAfterInitialization(Object bean,String beanName)
可以在这个方法中进行bean的实例化之后的处理,比如我们的自定义注解,对依赖对象的版本控制自动路由切换,比如有一个服务依赖了两种版本的实现,我们如何实现自动切换呢?
这个时候可以自定义一个路由注解,假如叫@RouteAnnotation,然后实现BeanPostProcessor接口,在其中通过反射拿到自定义的注解@RouteAnnotaion再进行路由规则的设定

- SmartInitializingSingleton.afterSingletonsInstantiated
容器启动运行阶段
- SmartLifecycle.start
容器正式渲染完毕,开始启动阶段,bean已经在spring容器的管理下,程序可以随时调用
容器的停止销毁
- SmartLifectcle.stop(Runnable callback)
spring容器停止运行 - DisposableBean.destrop()
spring会将所有的bean销毁,实现的bean实例被销毁的时候释放资源被调用
一些关键问题
FactoryBean和BeanFactory的区别?

BeanFactory是个bean工厂类接口,是负责生产和管理bean的工厂,是IOC容器最底层和基础的接口,Spring用它来管理和装配普通bean的IOC容器,它有多种实现,比如:AnnotationConfigApplicationContext,XMLWebApplicationContext等

FactoryBean是FactoryBean属于spring的一个bean,在IOC容器的基础上给Bean的实现加上了一个简单工厂模式和装饰模式,是一个可以生产对象和装饰对象的工厂Bean,由Spring管理,生产的对象是由getObject()方法决定的
注意,FactoryBean是泛型的,只能固定生产某一类对象,而不像BeanFactory那样可以生产多种类型的bean,在对于某些特殊的Bean的处理中,比如Bean本身就是一个工厂,那么在其进行单独的实例化操作逻辑中,可能我们并不想走Spring的那一套逻辑,此时就可以实现FactoryBean接口自己控制逻辑
Spring如何解决循环依赖问题
循环依赖问题就是A->B->A,Spring在创建A的时候,发现需要依赖B,因为去创建B实例,发现B又依赖于A,又去创建A,因为形成一个闭环,无法停止下来就可能会导致cpu计算飙升
如何解决这个问题?Spring解决这个问题主要靠巧妙的三层话缓存,所谓缓存主要是指三个map,singletonObject主要存放的是单例对象,属于第一级缓存:singletonFactories属于单例工厂对象,属于第三级缓存;
earlySingletonObject属于第二级缓存,如何理解early这个标识呢?它表示只是经过了实例化尚未初始化的对象,Spring首先从singletonObject(一级缓存)中尝试获取,如果获取不到并且对象在创建中,则尝试从二级缓存(earlySingletonObjects)中获取,如果还是获取不到并且允许从SingletonFactories通过getObject过去,则通过singletonFactory.getObject()(三级缓存)获取
如果获取到了则移除对应的singletonFactory,将singletonObject放入earlySingletonObjects,其实就是将第三级缓存提升到二级缓存,这个就是缓存升级。Spring在进行对象创建的时候,会依次从一级,二级,三级缓存中寻找对象,如果找到则直接返回
由于是初次创建,只能从第三级缓存中找到(实例化阶段放入进去的),创建完实例,然后将缓存放到第一级缓存中。下次循环依赖的再直接从一级缓存中就可以拿到实例对象了

