【学习札记NO.00004】Linux Kernel Pwn学习笔记 I:一切开始之前
【学习札记NO.00004】Linux Kernel Pwn学习笔记 I:一切开始之前
- [GITHUB BLOG ADDR](https://arttnba3.cn/2021/02/21/NOTE-0X02-LINUX-KERNEL-PWN-PART-I/)
- 0x00.Linux Kernel Basic Knowledge
-
- 一、内核
-
- 内核架构:微内核 & 宏内核(单内核)
-
- 宏内核(Monolithic Kernel,又叫单内核)
- 微内核(Micro Kernel)
- 二、分级保护域
-
- Intel Ring Model
- 用户空间 & 内核空间
-
- 用户态 & 内核态
- 进程运行态切换
-
- 用户态 ---> 内核态
-
- I.切换GS段寄存器
- II.保存用户态栈帧信息
- III.保存用户态寄存器信息
- IV.通过汇编指令判断是否为32位
- V.执行系统调用
- 内核态 ---> 用户态
- 三、系统调用
-
- 系统调用表
- 进入系统调用
- 退出系统调用
- 四、进程权限管理
-
- 进程描述符(process descriptor)
-
- cred结构体
- 用户ID & 组ID
- 进程权限改变
-
- 提权
- 五、I/O
-
- “万物皆文件”
- 进程文件系统
- 文件描述符
-
- stdin、stdout、stderr
- 系统调用:ioctl
- 六、Loadable Kernel Modules(LKMs)
- 七、保护机制
-
- KASLR
- STACK PROTECTOR
- SMAP/SMEP
- KPTI
- 0x01.Linux Kernel 编译 & 调试入门
-
- Pre.安装依赖
- 一、获取内核镜像(bzImage)
-
- 方法一:自行编译内核源码
-
- I.获取内核源码
- II.配置编译选项
- III.开始编译
-
- vmlinux:原始内核文件
- bzImage:压缩内核镜像
-
- zImage && bzImage
- EXTRA.添加系统调用
-
- I.修改系统调用表,分配系统调用号
- II.声明系统调用
- III.添加系统调用函数定义
- IV.重新编译内核
- V.测试系统调用
- 方法二:下载现有内核镜像
- 方法三:使用系统内核镜像
- 二、获取busybox
-
- 编译busybox
-
- I.获取busybox源码
- II.编译busybox源码
- 三、构建磁盘镜像
-
- 建立文件系统
-
- I.初始化文件系统
- II.配置初始化脚本
- III.配置用户组
- IV.配置glibc库
- 打包文件系统为镜像文件
- 向文件系统中添加文件
-
- I.解压磁盘镜像
- II.重打包磁盘镜像
- 四、使用qemu运行内核
-
- 配置启动脚本
- 五、使用gdb调试Linux内核
-
- remote连接
- 寻找gadget
- 获取模块加载地址
- 载入符号信息
- 0xFF.reference
GITHUB BLOG ADDR
推荐到我的GitHub blog进行阅读,CSDN太丑啦
0x00.Linux Kernel Basic Knowledge
一、内核
操作系统(Operation System)本质上也是一种软件,可以看作是普通应用程式与硬件之间的一层中间层,其主要作用便是调度系统资源、控制IO设备、操作网络与文件系统等,并为上层应用提供便捷、抽象的应用接口
而运行在内核态的内核(kernel)则是一个操作系统最为核心的部分,提供着一个操作系统最为基础的功能
这张十分经典的图片说明了Kernel在计算机体系结构中的位置:
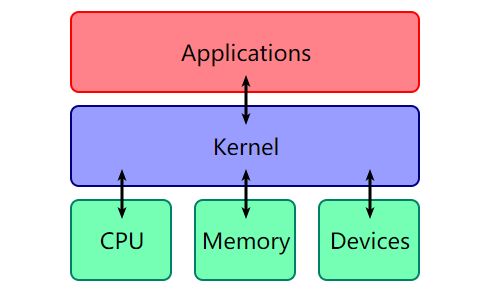
kernel的主要功能可以归为以下三点:
- 控制并与硬件进行交互
- 提供应用程式运行环境
- 调度系统资源
包括 I/O,权限控制,系统调用,进程管理,内存管理等多项功能都可以归结到以上三点中
与一般的应用程式不同,kernel的crash通常会引起重启
内核架构:微内核 & 宏内核(单内核)
通常来说我们可以把内核架构分为两种:宏内核和微内核,大致架构如下图所示:
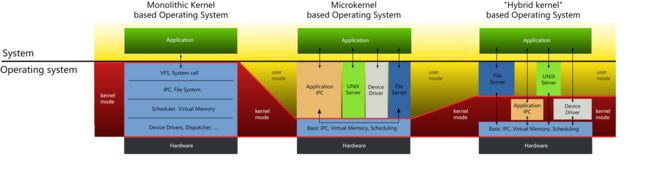
宏内核(Monolithic Kernel,又叫单内核)
宏内核(英语:Monolithic kernel),也译为集成式内核、单体式内核,一种操作系统内核架构,此架构的特性是整个内核程序是一个单一二进制可执行文件,在内核态以监管者模式(Supervisor Mode)来运行。相对于其他类型的操作系统架构,如微内核架构或混合内核架构等,这些内核会定义出一个高端的虚拟接口,由该接口来涵盖描述整个电脑硬件,这些描述会集合成一组硬件描述用词,有时还会附加一些系统调用,如此可以用一个或多个模块来实现各种操作系统服务,如进程管理、并发(Concurrency)控制、存储器管理等。
Wikipedia: 整塊性核心
台湾这什么鬼译名
通俗地说,宏内核几乎将一切都集成到了内核当中,并向上层应用程式提供抽象API(通常是以系统调用的形式)
Unix与类Unix便是宏内核

微内核(Micro Kernel)
对于微内核而言,大部分的系统服务(如文件管理等)都被剥离于内核之外,内核仅仅提供最为基本的一些功能:底层的寻址空间管理、线程管理、进程间通信等
Windows NT与Mach都宣称采用了微内核架构,不过本质上他们更贴近于混合内核(Hybrid Kernel)——在内核中集成了部分需要具备特权的服务组件

本文中我们主要讨论Linux内核
二、分级保护域
分级保护域(hierarchical protection domains)又被称作保护环,简称Rings,是一种将计算机不同的资源划分至不同权限的模型
在一些硬件或者微代码级别上提供不同特权态模式的CPU架构上,保护环通常都是硬件强制的。Rings是从最高特权级(通常被叫作0级)到最低特权级(通常对应最大的数字)排列的
在大多数操作系统中,Ring 0拥有最高特权,并且可以和最多的硬件直接交互(比如CPU,内存)
内层ring可以任意调用外层ring的资源
Intel Ring Model
Intel的CPU将权限分为四个等级:Ring0、Ring1、Ring2、Ring3,权限等级依次降低
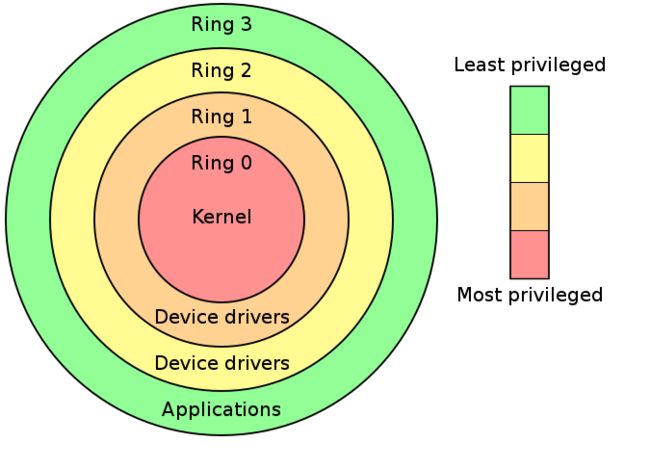
大部分现代操作系统只用到了ring0和ring3,其中kernel运行在ring0,用户态程序运行在ring3
使用 Ring Model 是为了提升系统安全性,例如某个间谍软件作为一个在 Ring 3 运行的用户程序,在不通知用户的时候打开摄像头会被阻止,因为访问硬件需要使用 being 驱动程序保留的 Ring 1 的方法
用户空间 & 内核空间
用户空间为我们的应用程式一般所运行的空间,运行在ring3权限的用户态
内核空间则是kernel所运行的空间,运行在ring0权限的内核态,所有进程共享一份内核空间
用户态 & 内核态
通俗地说,当进程运行在内核空间时就处于内核态,而进程运行在用户空间时则处于用户态
在内核态下,进程运行在内核地址空间中,此时 CPU 可以执行任何指令,运行的代码也不受任何的限制
在用户态下,进程运行在用户地址空间中,此时CPU所执行的指令是受限的,且只能访问用户态下可访问页面的虚拟地址
进程运行态切换
应用程式运行时总会经历无数次的用户态与内核态之间的转换,这是因为用户进程往往需要使用内核所提供的各种功能(如IO等),此时就需要陷入内核,待完成之后再“着陆”回用户态
用户态 —> 内核态
由用户态陷入到内核态主要有以下几种途径:
- 系统调用
- 异常
- 外设产生中断
- …
I.切换GS段寄存器
通过 swapgs 切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用
II.保存用户态栈帧信息
将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入 rsp/esp
III.保存用户态寄存器信息
通过 push 保存各寄存器值到栈上,以便后续“着陆”回用户态
IV.通过汇编指令判断是否为32位
V.执行系统调用
在这里用到一个全局函数表sys_call_table,其中保存着系统调用的函数指针
内核态 —> 用户态
由内核态重新“着陆”回用户态只需要恢复用户空间信息即可:
swapgs指令恢复用户态GS寄存器sysretq或者iretq恢复到用户空间
三、系统调用
系统调用(system call)是由操作系统内核向上层应用程式提供的应用接口,操作系统负责调度一切的资源,当用户进程想要请求更高权限的服务时,便需要通过由系统提供的应用接口,使用系统调用以陷入内核态,再由操作系统完成请求
系统调用本质上与一般的C库函数没有区别,不同的是系统调用位于内核空间,以内核态运行
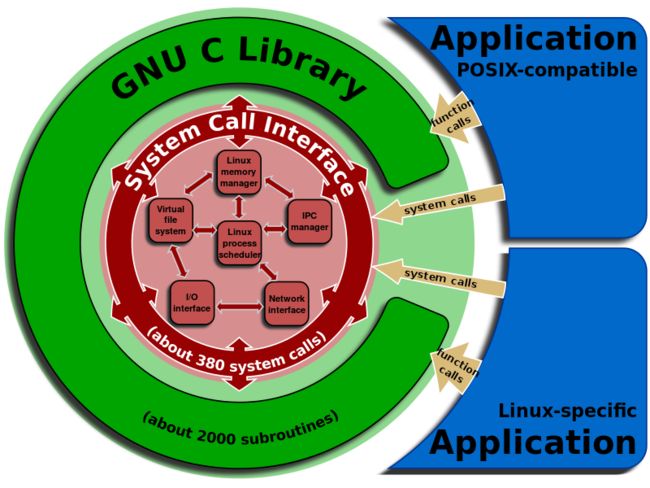
Windows系统下将系统调用封装在win32 API中,不过本篇博文主要讨论Linux
系统调用表
所有的系统调用被声明于内核源码arch/x86/entry/syscalls/syscall_64.tbl中,在该表中声明了系统调用的标号、类型、名称、内核态函数名称
在内核中使用系统调用表(System Call Table)对系统调用进行索引,该表中储存了不同标号的系统调用函数的地址
进入系统调用
进入系统调用有两种主要的方式:
- 执行
int 0x80汇编指令(80号中断) - 执行
sysenter汇编指令(only intel)
接下来就是由用户态进入到内核态的流程
与一般的函数调用规范不同,Linux下的系统调用以eax寄存器作为系统调用号,ebx、ecx、edx、esi、edi、ebp作为第一个参数、第二个参数…进行参数传递
退出系统调用
同样地,退出系统调用也有对应的两种方式:
- 执行
iret汇编指令 - 执行
sysexit汇编指令(only Intel)
接下来就是由内核态回退至用户态的流程
四、进程权限管理
前面我们讲到,kernel调度着一切的系统资源,并为用户应用程式提供运行环境,相应地,应用程式的权限也都是由kernel进行管理的
进程描述符(process descriptor)
在内核中使用结构体task_struct定义一个进程,该结构体定义于内核源码include/linux/sched.h中,代码比较长就不在这里贴出了
一个进程描述符的结构应当如下图所示:

本篇我们主要关心其对于进程权限的管理
注意到task_struct的源码中有如下代码:
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
Process credentials是kernel用以判断一个进程权限的凭据,在kernel中使用cred结构体进行标识,对于一个进程而言应当有三个cred:
- **ptracer_cred:**使用
ptrace系统调用跟踪该进程的上级进程的cred(gdb调试便是使用了这个系统调用,常见的反调试机制的原理便是提前占用了这个位置) - **real_cred:**该进程的真实cred,通常是一个进程最初启动时所具有的权限
- cred:该进程的有效cred,kernel以此作为进程权限的凭据
cred结构体
对于一个进程,在内核当中使用一个结构体cred管理其权限,该结构体定义于内核源码include/linux/cred.h中,如下:
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
/* RCU deletion */
union {
int non_rcu; /* Can we skip RCU deletion? */
struct rcu_head rcu; /* RCU deletion hook */
};
} __randomize_layout;
我们主要关注cred结构体中管理权限的变量
用户ID & 组ID
一个cred结构体中记载了一个进程四种不同的用户ID:
- 真实用户ID(real UID):标识一个进程启动时的用户ID
- 保存用户ID(saved UID):标识一个进程最初的有效用户ID
- 有效用户ID(effective UID):标识一个进程正在运行时所属的用户ID,一个进程在运行途中是可以改变自己所属用户的,因而权限机制也是通过有效用户ID进行认证的
- 文件系统用户ID(UID for VFS ops):标识一个进程创建文件时进行标识的用户ID
在通常情况下这几个ID应当都是相同的
用户组ID同样分为四个:真实组ID、保存组ID、有效组ID、文件系统组ID,与用户ID是类似的,这里便不再赘叙
进程权限改变
前面我们讲到,一个进程的权限是由位于内核空间的cred结构体进行管理的,那么我们不难想到:只要改变一个进程的cred结构体,就能改变其执行权限
在内核空间有如下两个函数,都位于kernel/cred.c中:
struct cred* prepare_kernel_cred(struct task_struct* daemon):该函数用以拷贝一个进程的cred结构体,并返回一个新的cred结构体,需要注意的是daemon参数应为有效的进程描述符地址或NULLint commit_creds(struct cred *new):该函数用以将一个新的cred结构体应用到进程
提权
查看prepare_kernel_cred()函数源码,观察到如下逻辑:
struct cred *prepare_kernel_cred(struct task_struct *daemon)
{
const struct cred *old;
struct cred *new;
new = kmem_cache_alloc(cred_jar, GFP_KERNEL);
if (!new)
return NULL;
kdebug("prepare_kernel_cred() alloc %p", new);
if (daemon)
old = get_task_cred(daemon);
else
old = get_cred(&init_cred);
...
在prepare_kernel_cred()函数中,若传入的参数为NULL,则会缺省使用init进程的cred作为模板进行拷贝,即可以直接获得一个标识着root权限的cred结构体
那么我们不难想到,只要我们能够在内核空间执行commit_cred(prepare_kernel_cred(NULL)),那么就能够将进程的权限提升到root
五、I/O
*NIX/Linux追求高层次抽象上的统一,其设计哲学之一便是万物皆文件
“万物皆文件”
UNIX/Linux设计的哲学之一——万物皆文件,在Linux系统的视角下,无论是文件、设备、管道,还是目录、进程,甚至是磁盘、套接字等等,一切都可以被抽象为文件,一切都可以使用访问文件的方式进行访问
通过这样一种哲学,Linux予开发者以高层次抽象的统一性,提供了操作的一致性:
- 所有的读取操作都可以通过read进行
- 所有的更改操作都可以通过write进行
对于开发者而言,将一切的操作都统一于一个高层次抽象的应用接口,无疑是十分美妙的一件事情——我们不需要去理解实现的细节,只需要完成简单的读写操作
例如,在较老版本的Linux中,可以使用
cat /dev/urandom > .dev.dsp命令令扬声器产生随机噪声

进程文件系统
进程文件系统(process file system, 简写为procfs)用以描述一个进程,其中包括该进程所打开的文件描述符、堆栈内存布局、环境变量等等
进程文件系统本身是一个伪文件系统,通常被挂载到/proc目录下,并不真正占用储存空间,而是占用一定的内存
当一个进程被建立起来时,其进程文件系统便会被挂载到/proc/[PID]下,我们可以在该目录下查看其相关信息
文件描述符
进程通过文件描述符(file descriptor)来完成对文件的访问,其在形式上是一个非负整数,本质上是对文件的索引值,进程所有执行 I/O 操作的系统调用都会通过文件描述符
每个进程都独立有着一个文件描述符表,存放着该进程所打开的文件索引,每当进程成功打开一个现有文件/创建一个新文件时(通过系统调用open进行操作),内核会向进程返回一个文件描述符
在kernel中有着一个文件表,由所有的进程共享
stdin、stdout、stderr
每个*NIX进程都应当有着三个标准的POSIX文件描述符,对应着三个标准文件流:
stdin:标准输入 - 0stdout:标准输出 - 1stderr:标准错误 - 2
此后打开的文件描述符应当从标号3起始
系统调用:ioctl
在*NIX中一切都可以被视为文件,因而一切都可以以访问文件的方式进行操作,为了方便,Linux定义了系统调用ioctl供进程与设备之间进行通信
系统调用ioctl是一个专用于设备输入输出操作的一个系统调用,其调用方式如下:
int ioctl(int fd, unsigned long request, ...)
- fd:设备的文件描述符
- request:请求码
- 其他参数
对于一个提供了ioctl通信方式的设备而言,我们可以通过其文件描述符、使用不同的请求码及其他请求参数通过ioctl系统调用完成不同的对设备的I/O操作
例如CD-ROM驱动程序弹出光驱的这一操作就对应着对“光驱设备”这一文件通过ioctl传递特定的请求码与请求参数完成
六、Loadable Kernel Modules(LKMs)
前面我们讲到,Linux Kernle采用的是宏内核架构,一切的系统服务都需要由内核来提供,虽然效率较高,但是缺乏可扩展性与可维护性,同时内核需要装载很多可能用到的服务,但这些服务最终可能未必会用到,还会占据大量内存空间,同时新服务的提供往往意味着要重新编译整个内核
综合以上考虑,可装载内核模块(Loadable Kernel Modules,简称LKMs)出现了,位于内核空间的LKMs可以提供新的系统调用或其他服务,同时LKMs可以像积木一样被装载入内核/从内核中卸载,大大提高了kernel的可拓展性与可维护性
常见的外设驱动便是LKM的一种
LKMs与用户态可执行文件一样都采用ELF格式,但是LKMs运行在内核空间,且无法脱离内核运行
通常与LKM相关的命令有以下三个:
lsmod:列出现有的LKMsinsmod:装载新的LKM(需要root)rmmod:从内核中移除LKM(需要root)
CTF比赛中的kernel pwn的漏洞往往出现在第三方LKM中
七、保护机制
与一般的程序相同,Linux Kernel同样有着各种各样的保护机制:
KASLR
KASLR即内核空间地址随机化(kernel address space layout randomize),与用户态程序的ASLR相类似——在内核镜像映射到实际的地址空间时加上一个偏移值,但是内核内部的相对偏移其实还是不变的
在未开启KASLR保护机制时,内核的基址为0xffffffff80000000, 内核会占用0xffffffff80000000~0xffffffffC0000000这1G虚拟地址空间
STACK PROTECTOR
类似于用户态程序的canary,通常又被称作是stack cookie,用以检测是否发生内核堆栈溢出,若是发生内核堆栈溢出则会产生kernel panic
内核中的canary的值通常取自gs段寄存器某个固定偏移处的值
SMAP/SMEP
SMAP即管理模式访问保护(Supervisor Mode Access Prevention),SMEP即管理模式执行保护(Supervisor Mode Execution Prevention),这两种保护通常是同时开启的,用以阻止内核空间直接访问用户空间的数据,完全地将内核空间与用户空间相分隔开,用以防范ret2usr(return-to-user,将内核空间的指令指针重定向至用户空间上构造好的提权代码)攻击
SMEP保护的绕过有以下两种方式:
-
在设计中,为了使隔离的数据进行交换时具有更高的性能,隐性地址共享始终存在,因此通过隐性页框共享可以完整的绕过软件和硬件的隔离保护,这种攻击方式被称之为ret2dir(return-to-direct-mapped memory )
-
Intel下系统根据CR4控制寄存器的第20位标识是否开启SMEP保护(1为开启,0为关闭),若是能够通过kernel ROP改变CR4寄存器的值便能够关闭SMEP保护,完成SMEP-bypass,就能够重新进行ret2usr
KPTI
KPTI即内核页表隔离(Kernel page-table isolation),内核空间与用户空间分别使用两组不同的页表集,这对于内核的内存管理产生了根本性的变化
0x01.Linux Kernel 编译 & 调试入门
Pre.安装依赖
环境是Ubuntu20.04
$ sudo apt-get update
$ sudo apt-get install git fakeroot build-essential ncurses-dev xz-utils qemu flex libncurses5-dev fakeroot build-essential ncurses-dev xz-utils libssl-dev bc bison libglib2.0-dev libfdt-dev libpixman-1-dev zlib1g-dev
一、获取内核镜像(bzImage)
大概有如下三种方式:
- 下载内核源码后编译
- 直接下载现成的的内核镜像,不过这样我们就不能自己魔改内核了2333
- 直接使用自己系统的镜像
方法一:自行编译内核源码
I.获取内核源码
前往Linux Kernel Archive下载对应版本的内核源码
笔者这里选用5.11这个版本的内核镜像
$ wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.11.tar.xz
II.配置编译选项
解压我们下载来的内核源码
$ tar -xvf linux-5.11.tar.xz
完成后进入文件夹内,执行如下命令开始配置编译选项
$ make menuconfig
进入如下配置界面

保证勾选如下配置(默认都是勾选了的):
- Kernel hacking —> Kernel debugging
- Kernel hacking —> Compile-time checks and compiler options —> Compile the kernel with debug info
- Kernel hacking —> Generic Kernel Debugging Instruments --> KGDB: kernel debugger
- kernel hacking —> Compile the kernel with frame pointers
一般来说不需要有什么改动,直接保存退出即可
III.开始编译
运行如下命令开始编译,生成内核镜像
$ make bzImage
可以使用make bzImage -j4加速编译
笔者机器比较烂,大概要等一顿饭的时间…
以及编译内核会比较需要空间,一定要保证磁盘剩余空间充足
完成之后会出现如下信息:
Kernel: arch/x86/boot/bzImage is ready (#1)
vmlinux:原始内核文件
在当前目录下提取到vmlinux,为编译出来的原始内核文件
$ file vmlinux
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, BuildID[sha1]=f1fc85f87a5e6f3b5714dad93a8ac55fa7450e06, with debug_info, not stripped
bzImage:压缩内核镜像
在当前目录下的arch/x86/boot/目录下提取到bzImage,为压缩后的内核文件,适用于大内核
$ file arch/x86/boot/bzImage
arch/x86/boot/bzImage: Linux kernel x86 boot executable bzImage, version 5.11.0 (root@iZf3ye3at4zthpZ) #1 SMP Sun Feb 21 21:44:35 CST 2021, RO-rootFS, swap_dev 0xB, Normal VGA
zImage && bzImage
zImage–是vmlinux经过gzip压缩后的文件。
bzImage–bz表示“big zImage”,不是用bzip2压缩的,而是要偏移到一个位置,使用gzip压缩的。两者的不同之处在于,zImage解压缩内核到低端内存(第一个 640K),bzImage解压缩内核到高端内存(1M以上)。如果内核比较小,那么采用zImage或bzImage都行,如果比较大应该用bzImage。https://blog.csdn.net/xiaotengyi2012/article/details/8582886
EXTRA.添加系统调用
据说大二下的操作系统实验里就有这个…不过笔者的寒假还没放完呢233333
以及请先阅读完「0x01.四 」之后再回来看本节内容~
I.修改系统调用表,分配系统调用号
在arch/x86/entry/syscalls/syscall_64.tbl中添加我们自己的系统调用号,这里用笔者个人比较喜欢的数字114514
114514 64 arttnba3_test sys_arttnba3_test
II.声明系统调用
在include/linux/syscalls.h中添加如下函数声明:
/* for arttnba3's personal syscall test */
asmlinkage long sys_arttnba3_test(void);
III.添加系统调用函数定义
在kernel/sys.c中添加如下代码(放置于最后一行的#endif /* CONFIG_COMPAT */之前):
SYSCALL_DEFINE0(arttnba3_test)
{
printk("arttnba3\'s personal syscall has been called!\n");
return 114514;
}
这里的SYSCALL_DEFINE0()本质上是一个宏,意为接收0个参数的系统调用,其第一个参数为系统调用名
笔者定义了一个简单的输出一句话的系统调用,在这里使用了内核态的printk()函数,输出的信息可以使用dmesg进行查看
IV.重新编译内核
这一步参照之前的步骤即可,通过这一步我们要将我们自己的系统调用编译到内核当中
V.测试系统调用
我们使用如下的例程测试我们的新系统调用
#include 编译,放入磁盘镜像中后重新打包,qemu起内核后尝试运行我们的例程,结果如下:
因为dmesg输出的东西太多,这里还附加用了grep命令

可以看到,我们的系统调用arttnba3_test被成功地嵌入了内核当中,并成功地被测试例程所调用,撒花~
方法二:下载现有内核镜像
我们也可以自己下载现有的内核镜像,而不需要自行编译一整套Linux内核
使用如下命令列出可下载内核镜像
$ sudo apt search linux-image-
选一个自己喜欢的下载就行,笔者所用的阿里云源似乎没有最新的5.11的镜像,这里用5.8的做个示范:
$ sudo apt download linux-image-5.8.0-43-generic
下载下来是一个deb文件,解压
$ dpkg -X ./linux-image-5.8.0-43-generic_5.8.0-43.49~20.04.1_amd64.deb extract
./
./boot/
./boot/vmlinuz-5.8.0-43-generic
./usr/
./usr/share/
./usr/share/doc/
./usr/share/doc/linux-image-5.8.0-43-generic/
./usr/share/doc/linux-image-5.8.0-43-generic/changelog.Debian.gz
./usr/share/doc/linux-image-5.8.0-43-generic/copyright
其中的./boot/vmlinuz-5.8.0-43-generic便是bzImage内核镜像文件
方法三:使用系统内核镜像
一般位于/boot/目录下,也可以直接拿出来用
二、获取busybox
BusyBox 是一个集成了三百多个最常用Linux命令和工具的软件,包含了例如ls、cat和echo等一些简单的工具
后续构建磁盘镜像我们需要用到busybox
编译busybox
I.获取busybox源码
在busybox.net下载自己想要的版本,笔者这里选用busybox-1.33.0.tar.bz2这个版本
$ wget https://busybox.net/downloads/busybox-1.33.0.tar.bz2
外网下载的速度可能会比较慢,可以在前面下载Linux源码的时候一起下载,也可以选择去国内的镜像站下载
解压
$ tar -jxvf busybox-1.33.0.tar.bz2
II.编译busybox源码
进入配置界面
$ make menuconfig
勾选Settings —> Build static binary file (no shared lib)
若是不勾选则需要单独配置lib,比较麻烦
接下来就是编译了,速度会比编译内核快很多
$ make install
编译完成后会生成一个_install目录,接下来我们将会用它来构建我们的磁盘镜像
三、构建磁盘镜像
建立文件系统
I.初始化文件系统
一些简单的初始化操作…
$ cd _install
$ mkdir -pv {bin,sbin,etc,proc,sys,home,lib64,lib/x86_64-linux-gnu,usr/{bin,sbin}}
$ touch etc/inittab
$ mkdir etc/init.d
$ touch etc/init.d/rcS
$ chmod +x ./etc/init.d/rcS
II.配置初始化脚本
首先配置etc/inttab,写入如下内容:
::sysinit:/etc/init.d/rcS
::askfirst:/bin/ash
::ctrlaltdel:/sbin/reboot
::shutdown:/sbin/swapoff -a
::shutdown:/bin/umount -a -r
::restart:/sbin/init
在上面的文件中指定了系统初始化脚本,因此接下来配置etc/init.d/rcS,写入如下内容:
#!/bin/sh
mount -t proc none /proc
mount -t sys none /sys
/bin/mount -n -t sysfs none /sys
/bin/mount -t ramfs none /dev
/sbin/mdev -s
主要是配置各种目录的挂载
也可以在根目录下创建init文件,写入如下内容:
#!/bin/sh
echo "{==DBG==} INIT SCRIPT"
mkdir /tmp
mount -t proc none /proc
mount -t sysfs none /sys
mount -t debugfs none /sys/kernel/debug
mount -t tmpfs none /tmp
# insmod /xxx.ko # load ko
mdev -s # We need this to find /dev/sda later
echo -e "{==DBG==} Boot took $(cut -d' ' -f1 /proc/uptime) seconds"
setsid /bin/cttyhack setuidgid 1000 /bin/sh #normal user
# exec /bin/sh #root
别忘了添加可执行权限:
$ chmod +x ./init
III.配置用户组
$ echo "root:x:0:0:root:/root:/bin/sh" > etc/passwd
$ echo "ctf:x:1000:1000:ctf:/home/ctf:/bin/sh" >> etc/passwd
$ echo "root:x:0:" > etc/group
$ echo "ctf:x:1000:" >> etc/group
$ echo "none /dev/pts devpts gid=5,mode=620 0 0" > etc/fstab
在这里建立了两个用户组root和ctf,以及两个用户root和ctf
IV.配置glibc库
将需要的动态链接库拷到相应位置即可
为了方便笔者这里就先不弄了,直接快进到下一步,以后有时间再补充(咕咕咕
打包文件系统为镜像文件
使用如下命令打包文件系统
$ find . | cpio -o --format=newc > ../../rootfs.cpio
这里的位置是笔者随便选的,也可以将之放到自己喜欢的位置
向文件系统中添加文件
若是我们后续需要向文件系统中补充一些其他的文件,可以选择在原先的_install文件夹中添加(不过这样的话若是配置多个文件系统则会变得很混乱),也可以解压文件系统镜像后添加文件再重新进行打包
I.解压磁盘镜像
$ cpio -idv < ./rootfs.cpio
该命令会将磁盘镜像中的所有文件解压到当前目录下
II.重打包磁盘镜像
和打包磁盘镜像的命令一样
$ find . | cpio -o --format=newc > ../new_rootfs.cpio
四、使用qemu运行内核
终于到了最激动人心的时候了:我们即将要将这个Linux内核跑起来——用我们自己配置的文件系统与内核
安全起见,我们并不直接在真机上运行这个内核,而是使用qemu在虚拟机里运行
配置启动脚本
首先将先前的bzImage和rootfs.cpio放到同一个目录下
接下来编写启动脚本
$ touch boot.sh
写入如下内容:
#!/bin/sh
qemu-system-x86_64 \
-m 128M \
-kernel ./bzImage \
-initrd ./rootfs.cpio \
-monitor /dev/null \
-append "root=/dev/ram rdinit=/sbin/init console=ttyS0 oops=panic panic=1 loglevel=3 quiet nokaslr" \
-cpu kvm64,+smep \
-smp cores=2,threads=1 \
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0 \
-nographic \
-s
部分参数说明如下:
-m:虚拟机内存大小-kernel:内存镜像路径-initrd:磁盘镜像路径-append:附加参数选项nokalsr:关闭内核地址随机化,方便我们进行调试loglevel=3&quiet:不输出logconsole=ttyS0:指定终端为/dev/ttyS0,这样一启动就能进入终端界面
-monitor:将监视器重定向到主机设备/dev/null-cpu:设置CPU安全选项,在这里开启了smep保护-s:相当于-gdb tcp::1234的简写(也可以直接这么写),后续我们可以通过gdb连接本地端口进行调试
运行boot.sh,成功启动~撒花~
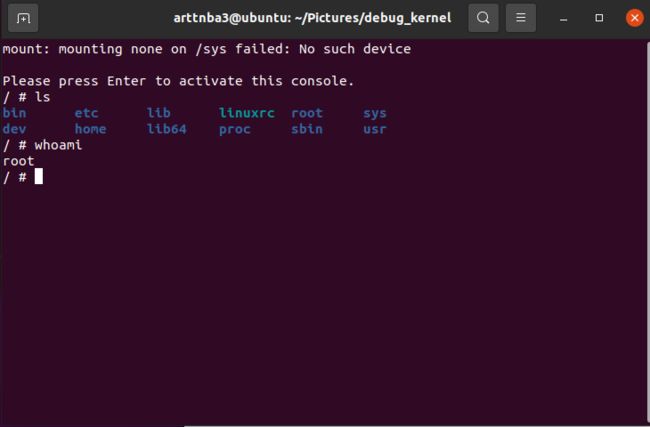
在这里遇到了一条报错信息:
mount: mounting none on /sys failed: No such device暂且没查到原因…
五、使用gdb调试Linux内核
remote连接
我们启动时已经将内核挂载到了本地的1234端口,只需要gdb连接上就行
$ gdb
pwndbg> set architecture i386:x86-64
pwndbg> target remote localhost:1234
笔者的gdb使用了
pwndbg这个插件

寻找gadget
用ROPgadget或者ropper都行,笔者比较喜欢使用ROPgadget
$ ROPgadget --binary ./bzImage > gadget.txt
一般出来大概有个40+m
获取模块加载地址
载入符号信息
0xFF.reference
eqqie - Linux下kernel调试环境搭建
TaQini - Linux Kernel Pwn 入门笔记
Mask - Linux Kernel Pwn I: Basic Knowledge
CTF Wiki - Linux Pwn - kernel - 基础知识
Wikipedia: 整塊性核心
进程描述符
Lab1:Linux内核编译及添加系统调用(详细版) - 睿晞 - 博客园
m4x - Play with file descriptor(II)
文件描述符表、文件表、索引结点表_luotuo44的专栏-CSDN博客_文件描述符表
《Understanding the Linux Kernel(Third Edition)》 —— Daniel P. Bovet & Marco Cesati
《Modern Operating System(Fourth Edition)》 —— Andrew S. Tanenbaum & Herbert Bos