文章来源 | 恒源云社区
原文地址 | 两个都比一个好:表序编码器的联合实体和关系提取
原文作者 | Mathor
Abstract
对于联合实体关系抽取,许多研究者将联合任务归结为一个填表问题,他们主要专注于学习单个编码器来捕获同一空间内的两个任务所需的信息(一个表抽取实体和关系)。作者认为设计两个不同的编码器捕获这两种不同类型的信息更好,因此本文提出了一种新颖的Table-Sequence编码器,其中两个不同的编码器(Table和序列编码器)被设计成在表示学习过程中相互帮助,本文并证明了两个编码器比一个更有优势。仍然使用表格结构,引入BERT中的attention权重进行表格中元素表示的学习。
1 Introduction
在几种联合抽取的方法中,将NER和RE转化为一个填表问题,对于形成的2D表,表中每个条目捕获句子内两个独立单词的交互,NER任务再被转化为一个序列标签问题,即对角线的条目是标签,而RE被认为是标签表内其他条目的问题;这种方法将NER和RE整合到一个表格中,实现了两个任务之间的潜在有用的交互。
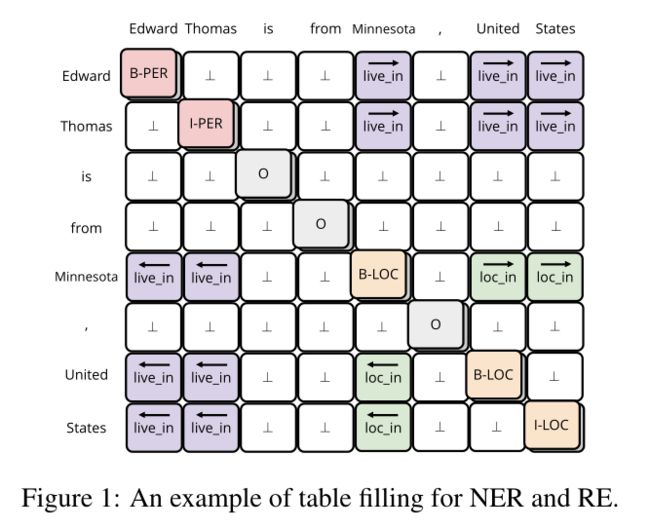
作者认为一张表解决两个问题可能会受到特征混淆的影响(一个任务提取的特征可能与另一个任务的特征一致或冲突,从而导致学习模型变得混乱),其次这种结构没有充分利用到表结构,因为这种方法仍然是将表结构转化为序列,然后使用序列标签方法填表,因此在转化期间2D表中的关键结构信息可能会丢失(图1左下角共享相同的标签)。
针对以上问题,本文提出一种新的方法解决上述限制。使用两种不同的结构(序列表示和表表示)单独表示NER和RE;
通过这种结构不仅可以将这两个单独的表示用于捕获特定于任务的信息,而且作者设计了一种机制使两个子任务进行交互,以便利用NER和RE任务背后的内在联系。
2 Model
2.1 PROBLEM FORMULATION
NER看做序列标注问题,其中gold entity tags \( y^{NER} \)是BIO;RE看做表格填充任务
形式上,给定输入句子\( x=[x_ i]_ {1≤i≤N} \),维护标签表:\( y^{RE}=[y^{RE}_ {i,j}]_ {i≤i,j≤N} \)
假设从mention \( x_{i^b},…,x_{i^e} \)到mention \( x_{j^b},…,x_{j^e} \)有关系r,则:
其中\( i\in [i^b,i^e]\wedge j\in[j^b,j^e] \),\( \bot \)表示没有关系的单词对
表3显示了两个编码器在每一层的详细信息,以及如何交互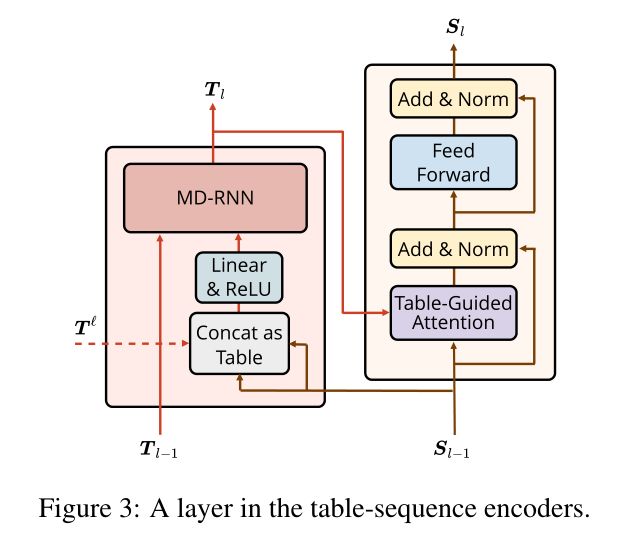
在每一层中,表编码器使用序列表示法来构造表表示法,然后序列编码器使用表表示法来对序列表示法进行上下文处理。
2.2 TEXT EMBEDDER
对于包含N个单词\( x=[x_i]_{1≤i≤N} \)的句子,其中单词嵌入为:\( x^w\in \mathbb{R}^{N\times d_1} \),LSTM计算的字符嵌入为:\( x^c\in \mathbb{R}^{N\times d_2} \),由BERT产生的上下文单词嵌入:\( x^l\in \mathbb{R}^{N\times d_3} \)
将三个特征向量进行拼接,并使用linear来形成初始序列表示\( S_0\in \mathbb{R}^{N\times H} \):
2.3 TABLE ENCODER
图3左侧所示的表格编码器是用于学习表格表示(N×N个向量表格)的神经网络,其中第i行和第j列的向量对应于输入句子的第i和第j个单词。本文首先通过将序列表示的两个向量进行连接,然后是通过一个全连接层来构建一个非上下文表,以将隐藏大小减半。
形式化上,对于第l层(表表示和序列表示交互的第l层),有\( X_l\in \mathbb{R}^{N\times N\times H} \):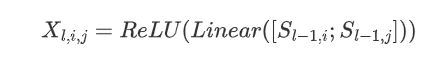
接下来使用GRU的多维递归神经网络来对\( X_l \)进行上下文处理,迭代计算每个单元格的隐藏状态以形成上下文化的表格表示\( T_l \),其中: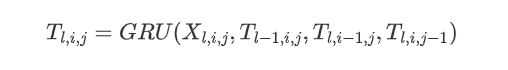
多维GRU通常沿着层、行和列的维度利用上下文,也就是说不仅考虑到了相邻行和列的单元格,还考虑上一层的单元格。对于表格法来说,句子长度为N,那么时间复杂度就变成了\( O^{N\times N} \),对角线条目的计算可以同时计算(将对角线条目定义为位置(i,j)处的偏移),然后通过并行化进行优化,将复杂度降低到\( O^N \)。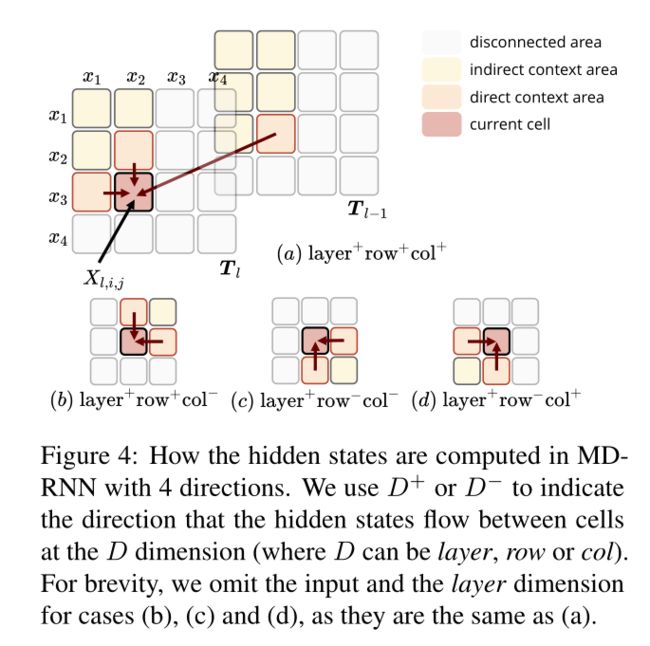
由图4直观上可以看到,让网络能够全方位的方位周围环境能提高性能,因此需要4个RNN来完成这个工作,从4个方向上访问上下文以对2D表进行建模,然而作者经验上发现只考虑情况a和c的设置效果与四种情况全部考虑所得到的的性能差不多,因此为了减少计算量,作者使用了两个方向,最终的表格表示是两个RNN的隐藏状态的串联: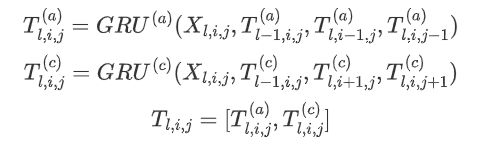
2.4 SEQUENCE ENCODER
通过Sequence Encoder学习序列表示(a sequence of vectors),其中第i个向量表示输入句子中的第i个单词,该结构类似于transformer结构,见图3的右半部分,本文用表格引导注意力(Table-Guided Attention)取代按比例缩放的点积注意力。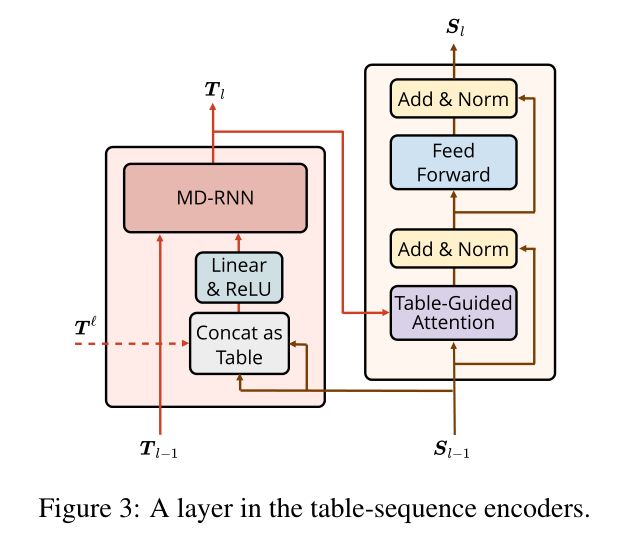
通用注意力的计算过程如下:
对于每个query,输出是这些值的加权和,其中分配给每个value的权重由query与所有key的相关性确定: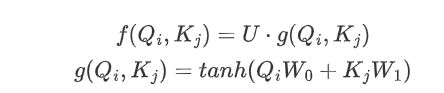
其中U是可学习向量,g是将每个query-key pair 映射到向量的函数,图5中f的输出即是query-key pair构造的注意力权重。
本文的表格引导注意力中,输入即是上一层的序列表示\( S_{l-1} \),表格引导注意力是自注意力,注意力的得分函数f为:
表格引导注意力的优点:
(1)不比计算g函数,因为\( T_l \)已经从表编码器中获得
(2)\( T_l \)是沿行、列和层维度的上下文得到的表征,分别对应于query、key、value,这样的上下文信息使网络能够更好的捕获更难的word-word依存关系
(3)并且允许表编码器参与学习过程,从而形成两个编码器之间的双向交互。序列编码器的其余部件类似于transformer,对于\( l \)层,在自注意力之后使用前馈神经网络FFNN,并使用残差连接和层标准化得到以获取输出序列表示: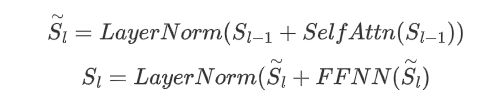
2.5 EXPLOIT PRE-TRAINED ATTENTION WEIGHTS
图2、3中的虚线来自预训练模型BERT的注意力权重形式的信息,本文将所有头部和所有层的注意力进行叠加,形成\( T^{l}\in \mathbb{R}^{N\times N \times (L^l\times A^l)} \),其中\( L^l \)是transformer的层数,\( A^l \)是每层中head的数量,本文利用\( T^l \)在表编码器中形成MD-RNN的输入,section2.3中的公式1被替换成:
2.6 TRANING AND EVALUATION
本文使用\( S_L \)和\( T_L \)来预测实体标签和关系标签的概率分布: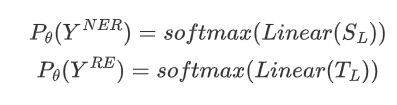
其中\( Y^{NER}、Y^{RE} \)是预测标签的随机变量,\( P_\theta \)是概率估计函数,\( \theta \)是模型参数
采用交叉熵计算损失: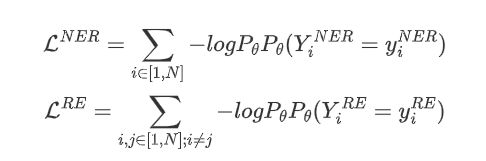
其中,\( y^{NER} \)和\( y^{RE} \)是gold tag,目标函数是:\( L_{NER}+L_{RE} \)在评估过程中,关系的预测依赖于实体的预测,因此首先预测实测,然后查找关系概率表\( P_\theta(Y^{RE}) \),查看预测的实体之间是否存在有效的关系,具体地说,通过选择概率最高的类别来预测每个单词的实体tag: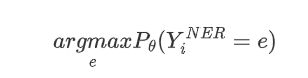
整个tag序列可以被转换成具有其边界和类型的实体。对于给定的两个实体span :\( (i_b,i_e)和(j_b,j_e) \),其关系由下式给出:
其中\( \bot \)表示没有无关系
3 Experiments
3.1 MODEL STEP
根据ACE05验证集调参,其他数据集使用相同的设置,Glove用于初始化词嵌入,BERT使用默认的参数,堆叠了三层具有独立参数的编码层(图2,每层中包含GRU单元),对于表编码器,使用两个独立的MD-RNN;对于序列编码器,使用8-head注意力表示,结果如下: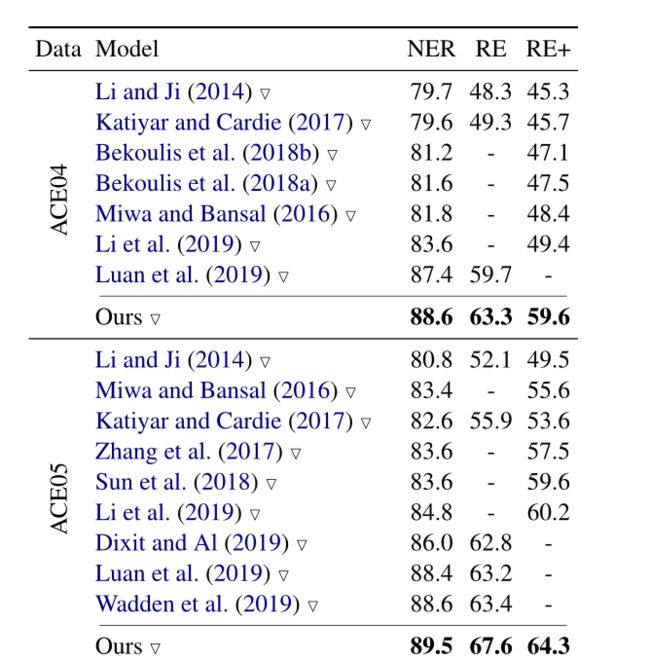
4 启示
- 论文是写的真的好,表达能力很强
- transformer框架的部分应用可以在其他地方使用
- 还是老生常谈的需要占用很多显存
- 表表示和序列表示的交互策略可以尝试修改成其他解码方式并实现交互