从零开始用YOLOv5训练自己的数据集
本文采用的yolov5的代码地址:https://github.com/ultralytics/yolov5
配置数据集
1.初始设置文件夹如下:
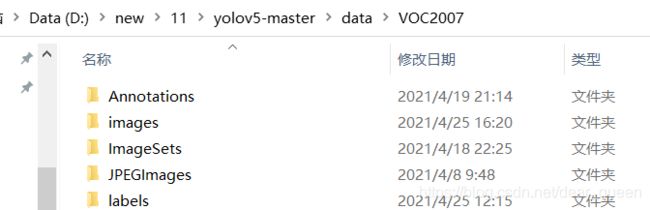
其中Annotations内是xml文件,images是数据集图片,ImageSets下是Main空文件,后续会有train.txt,val.txt,trainval.txt,test.txt.
JPEGImages内跟images文件内一样都是数据集图片。labels是空文件。
- 新建一个文件voc_txt
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default=r'D:\new\11\yolov5-master\data\VOC2007\Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default=r'D:\new\11\yolov5-master\data\VOC2007\ImageSets\Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
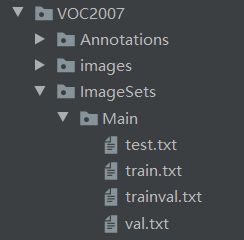
该文件代码生成的为Main文件下的这几个txt文件。
- 新建voc_label文件:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["holothurian", "echinus",'scallop','starfish','waterweeds'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
# in_file = open('/home/trainingai/zyang/yolov5/paper_data/Annotations/%s.xml' % (image_id), encoding='UTF-8')
# out_file = open('/home/trainingai/zyang/yolov5/paper_data/labels/%s.txt' % (image_id), 'w')
in_file = open(r'D:\new\11\yolov5-master\data\VOC2007\Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open(r'D:\new\11\yolov5-master\data\VOC2007/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists(r'D:/new/11/yolov5-master/data/VOC2007/labels/'):
os.makedirs(r'D:\new\11\yolov5-master\data\VOC2007/labels/')
image_ids = open(r'D:\new\11\yolov5-master\data\VOC2007\ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open(abs_path+'VOC2007/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/VOC2007/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
注意这里如果出现difficult报错,就注释掉就可以。
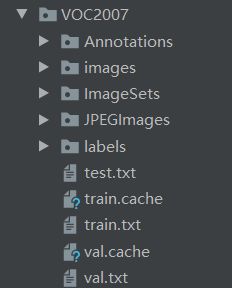
改代码生成的为labels文件下的txt文件,以及VOC2007文件下的三个txt文件。
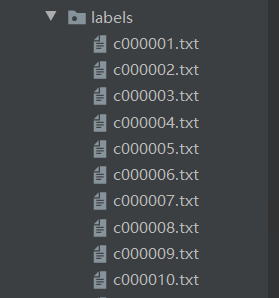
labels文件下的txt文件内容:

VOC2007文件下的train.txt文件内容:
4. 修改data/voc.yaml文件:
修改以下四个地方:注意这里:后面要加一个空格。
-
修改model/yolov5.yaml文件:
此处你想用那个yaml文件就改那个就可。

-
别忘了去官网下载pt权重文件呀,放在weights文件下。
-
修改train.py文件
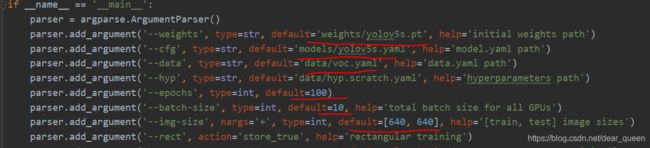
以上部分根据需要自行改动。
运行代码如下:
python train.py --img 640 --batch 10 --epoch 300 --data data/voc.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device '0'
如果你是pytorch<1.7.0版本的请看这里:::
该算法处在更新状态中,本文采用pytorch:1.6.0,因为下载时该代码已经更新,采用的激活函数为SiLU,因此在本文中设置激活函数,才能应用于pytorch1.6.0。
讲解激活函数设置问题:(会出现如下问题)
Can‘t get attribute ‘SiLU‘ on <module ‘torch.nn.modules.activation
在pytorch1.6.0以下版本未更新激活函数SiLU,因此不更改激活函数设置,将无法应用,或者你可以采用pytorch1.7.0以上版本。
方法如下:
打开文件地址如下:
D:\anaconda\envs\pytorch-gpu\Lib\site-packages\torch\nn\modules
即打开torch文件下的nn文件下的modules,本文有虚拟环境,因此目录如上所示。找到下面这个文件:
![]()
打开后作出如下修改:
######新加入的
class SiLU(Module): # export-friendly version of nn.SiLU()
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Hardswish(Module): # export-friendly version of nn.Hardswish()
@staticmethod
def forward(x):
# return x * F.hardsigmoid(x) # for torchscript and CoreML
return x * F.hardtanh(x + 3, 0., 6.) / 6. # for torchscript, CoreML and ONNX
本文测试时只发现了这两个未更新的函数,因此只修改了这两个,如果你的代码报错其他的可以继续添加。

这样就可以继续运行了。
如果你出现了如下问题:
No labels in D:\new\11\yolov5-master\data\VOC2007\train.cache.
不要慌张,该项目是要求images文件和labels文件相对应的,有可能是你没有这两个文件。所以他找不到内容匹配不到图片和标签。
查看tensorboard可视化页面:
在虚拟环境中输入,后面是环境地址
tensorboard --logdir=D:\new\11\yolov5-master\runs\train\exp2
训练过程中也会产生可视化的图片。
最近重新测试了python models/export.py --weights ./weights/yolov5x.pt --img 640 --batch 1
该输入是为了展示onnx网络结构可视化,然鹅,发现之前SiLU的问题实际并没有解决掉,这里对export.py重新进行了修改
将49行附近的地方修改为如下:
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.ReLU):
m.act = SiLU()
同时experimental.py的第123行修改如下:
# Compatibility updates
for m in model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6]:
然后就OK了
好了就这些,散会!懒得看的小伙伴们可以移步资源区自行下载地址哈。