【源码学习-spark2.1.1和yarn2.11】SparkOnYarn部署流程(二)ApplicationMaster_CoarseGrainedExecutorBackend
002-源码spark-2.1.1版
- SparkOnYarn部署流程-ApplicationMaster
- SparkOnYarn部署流程-CoarseGrainedExecutorBackend
SparkOnYarn部署流程-ApplicationMaster
如果走集群模式的话,bin/java org.apache.spark.deploy.yarn.ApplicationMaster当该命令提交后,client的事情就算完了。
alt+ctrl+shift+n,搜索ApplicationMaster进入ApplicationMaster.scala源码文件,
如果走的是client客户端,ctrl+shift+alt+n搜索org.apache.spark.deploy.yarn.ExecutorLauncher进入ApplicationMaster.scala源码文件,最终调用的依然是ApplicationMaster.main(args)。就是两种模式走的代码逻辑是一样的。

1.0 启动进程
进入ApplicationMaster.scala源文件后,执行752行main方法。
def main(args: Array[String]): Unit = {
SignalUtils.registerLogger(log)
val amArgs = new ApplicationMasterArguments(args)
// Load the properties file with the Spark configuration and set entries as system properties,
// so that user code run inside the AM also has access to them.
// Note: we must do this before SparkHadoopUtil instantiated
if (amArgs.propertiesFile != null) {
Utils.getPropertiesFromFile(amArgs.propertiesFile).foreach { case (k, v) =>
sys.props(k) = v
}
}
SparkHadoopUtil.get.runAsSparkUser { () =>
master = new ApplicationMaster(amArgs, new YarnRMClient)
System.exit(master.run())
}
}
对参数进行封装(点进去,类似SparkSubmit.scala源码文件中的封装参数类)
new ApplicationMasterArguments(args)
在工具类SparkHadoopUtil中创建应用管理器对象
new ApplicationMaster(amArgs, new YarnRMClient)
ctrl+鼠标左键ApplicationMaster走到ApplicationMaster.scala源码文件的97行有一个心跳周期变量heartbeatInterval;往下111行,有个一个rpc环境变量rpcEnv(RPC是进程与进程之间交互的规则,就是一些协议,早期同台机器进程间交互,一个进程调用另一个进程叫IPC)会有一个进程交互的环境;还有一个终端变量amEndpoint。
运行对象
master.run()
ctrl+鼠标左键run走到183行,该方法中判断是否是集群,
if (isClusterMode) {
runDriver(securityMgr)
} else {
runExecutorLauncher(securityMgr)
}
1.1
ctrl+鼠标左键runDriver运行driver走到392行,然后启动用户应用(即提交命令中的–class)
userClassThread = startUserApplication()
获取用户应用的类的main方法(就是提交命令的SparkPi,或者自己写的程序main方法)
ctrl+鼠标左键startUserApplicaition走到608行,方法中获取用户类加载器,然后加载类信息获取main方法;构建一个new Thread,命名为Driver,然后启动线程执行用户类的main方法。
userThread.setContextClassLoader(userClassLoader)
userThread.setName("Driver")
userThread.start()
userThread
Driver在整个过程中是一个线程的名称。
ApplicationMaster作为中间的桥梁,既和资源交互(RM、NM)又和计算交互(Driver、Executor),资源和计算不直接交互。
1.2
走到418行,
userClassThread.join()
线程进行join表示该线程不执行完,不能往下执行的。把另外线程加入当前线程,目的保证该线程执行完,线程中所需要执行的任务要准备好。
走到409行,注册ApplicationMaster
registerAM(sc.getConf, rpcEnv, driverRef, sc.ui.map(_.appUIAddress).getOrElse(""),
securityMgr)
ApplicationMaster进程与yarn进程交互通过rpcEnv。
ctrl+鼠标左键registerAM走到329行,方法中有RpcEndpointAddress终端地址。
在359行,有client代表的是YarnRMClient,获取yarn资源
allocator = client.register(driverUrl,
driverRef,
yarnConf,
_sparkConf,
uiAddress,
historyAddress,
securityMgr,
localResources)
allocator.allocateResources()
reporterThread = launchReporterThread()
虽然这里client.register看上去像client(RM)进行注册,其实ApplicationMaster向client(RM)注册一下申请资源,然后RM进行allocateResources()分配资源,
1.2.1 分配资源
ctrl+鼠标左键allocateResources进入YarnAllocator.scala源码文件254行,获取资源,查看资源大小,处理资源handleAllocatedContainers(allocatedContainers.asScala)走到407行,
在这里你会发现有你说熟悉的本地化策略(移动数据不如移动计算),最好的是进程本地化,其次节点本地化,然后机架本地化。
然后走到440行运行资源
runAllocatedContainers(containersToUse)
ctrl+鼠标左键runAllocatedContainers走到483行,这时所有可用的container资源都有了。该方法中有个launcherPool,走到138行有对该变量的赋值,是守护线程池。
private val launcherPool = ThreadUtils.newDaemonCachedThreadPool(
"ContainerLauncher", sparkConf.get(CONTAINER_LAUNCH_MAX_THREADS))
ctrl+鼠标左键newDaemonCachedThreadPool进入ThreadUtils.scala源码文件63行,这一流程说明从线程池里构建我们的线程。
/**
* Create a cached thread pool whose max number of threads is `maxThreadNumber`. Thread names
* are formatted as prefix-ID, where ID is a unique, sequentially assigned integer.
*/
def newDaemonCachedThreadPool(
prefix: String, maxThreadNumber: Int, keepAliveSeconds: Int = 60): ThreadPoolExecutor = {
val threadFactory = namedThreadFactory(prefix)
val threadPool = new ThreadPoolExecutor(
maxThreadNumber, // corePoolSize: the max number of threads to create before queuing the tasks
maxThreadNumber, // maximumPoolSize: because we use LinkedBlockingDeque, this one is not used
keepAliveSeconds,
TimeUnit.SECONDS,
new LinkedBlockingQueue[Runnable],
threadFactory)
threadPool.allowCoreThreadTimeOut(true)
threadPool
}
在YarnAllocator.scala源码文件中505行launcherPool.execute(new Runnable {,从线程池拿一个线程出来执行runnable,运行executor。
new ExecutorRunnable(
Some(container),
conf,
sparkConf,
driverUrl,
executorId,
executorHostname,
executorMemory,
executorCores,
appAttemptId.getApplicationId.toString,
securityMgr,
localResources
).run()
updateInternalState()
ctrl+鼠标左键ExecutorRunnable进入ExecutorRunnable.scala源码文件46行,该类里有rpc属性,还有nmClient属性(说明要和NodeManager进行交互了),在NodeManager上启动container资源。
var rpc: YarnRPC = YarnRPC.create(conf)
var nmClient: NMClient = _
def run(): Unit = {
logDebug("Starting Executor Container")
nmClient = NMClient.createNMClient()
nmClient.init(conf)
nmClient.start()
startContainer()
}
ctrl+鼠标左键startContainer走到87行,方法中准备commands
val commands = prepareCommand()
ctrl+鼠标左键prepareCommand走到132行,方法中和Client.scala源码文件的createContainerLaunchContext一样有很命令准备。
走到210行,Backend后端,前台展示,后台数据交互
YarnSparkHadoopUtil.addOutOfMemoryErrorArgument(javaOpts)
val commands = prefixEnv ++ Seq(
YarnSparkHadoopUtil.expandEnvironment(Environment.JAVA_HOME) + "/bin/java",
"-server") ++
javaOpts ++
Seq("org.apache.spark.executor.CoarseGrainedExecutorBackend",
"--driver-url", masterAddress,
"--executor-id", executorId,
"--hostname", hostname,
"--cores", executorCores.toString,
"--app-id", appId) ++
userClassPath ++
Seq(
s"1>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stdout",
s"2>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stderr")
// TODO: it would be nicer to just make sure there are no null commands here
commands.map(s => if (s == null) "null" else s).toList
因为这里使用的是bin/java,那么肯定是进程启动,而CoarseGrainedExecutorBackend正好是jps下的进程名称。
SparkOnYarn部署流程-CoarseGrainedExecutorBackend
该进程肯定也有main方法,
ctrl+shift+alt+n搜索org.apache.spark.executor.CoarseGrainedExecutorBackend进入CoarseGrainedExecutorBackend.scala源码文件,找到main方法在236行,首先模式匹配进行赋值,最后运行run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)
ctrle+鼠标左键run走到177行,与driver交互,准备环境,在整个spark通信环境中把executor对象注册进去,接着rpc的环境等待执行,
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, port, cores, cfg.ioEncryptionKey, isLocal = false)
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
SparkHadoopUtil.get.stopCredentialUpdater()
这里的Executor并不是真正的executor,因为在CoarseGrainedExecutorBackend中有个executor变量,这里才是真正的计算对象。所谓的executor就是类中的属性,类中的对象。
ctrl+鼠标左键CoarseGrainedExecutorBackend走到39行,该类继承了ThreadSafeRpcEndpoint,点进去,进入RpcEndpoint.scala源码文件148行,
这个终端到底在干什么?
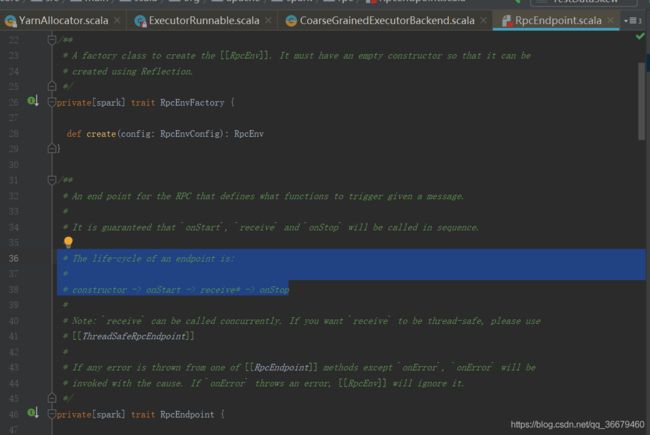
终端的生命周期:构建->启动->接收->停止
因为CoarseGrainedExecutorBackend继承了ThreadSafeRpcEndpoint,所以相应的也实现了onStart()、receive方法
override def onStart() {
logInfo("Connecting to driver: " + driverUrl)
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>
// This is a very fast action so we can use "ThreadUtils.sameThread"
driver = Some(ref)
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls))
}(ThreadUtils.sameThread).onComplete {
// This is a very fast action so we can use "ThreadUtils.sameThread"
case Success(msg) =>
// Always receive `true`. Just ignore it
case Failure(e) =>
exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)
}(ThreadUtils.sameThread)
}
在onStart方法中,有个driver的引用,向引用发送一个注册执行器的请求,executor反向注册到driver,确保driver知道executor的情况。
override def receive: PartialFunction[Any, Unit] = {
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}
case RegisterExecutorFailed(message) =>
exitExecutor(1, "Slave registration failed: " + message)
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
case KillTask(taskId, _, interruptThread) =>
if (executor == null) {
exitExecutor(1, "Received KillTask command but executor was null")
} else {
executor.killTask(taskId, interruptThread)
}
case StopExecutor =>
stopping.set(true)
logInfo("Driver commanded a shutdown")
// Cannot shutdown here because an ack may need to be sent back to the caller. So send
// a message to self to actually do the shutdown.
self.send(Shutdown)
case Shutdown =>
stopping.set(true)
new Thread("CoarseGrainedExecutorBackend-stop-executor") {
override def run(): Unit = {
// executor.stop() will call `SparkEnv.stop()` which waits until RpcEnv stops totally.
// However, if `executor.stop()` runs in some thread of RpcEnv, RpcEnv won't be able to
// stop until `executor.stop()` returns, which becomes a dead-lock (See SPARK-14180).
// Therefore, we put this line in a new thread.
executor.stop()
}
}.start()
}
在recive方法中,接收driver对executor的反馈信息。有创建executor,有加载executor等。