Hadoop知识点(五)-MapReduce
MapReduce
- 1.MapReduce概念
- 2.MapReduce架构
-
- 2.1oom-killer机制
- 2.2container
- 2.3架构
-
- 2.3.1ResourceManager
- 2.3.2NodeManager
- 2.4yarn
- 3.wordcount应用
- 4.分片split
分布式计算框架,在生产开发比较负责累赘,基本不用。仅仅作为面试理论,生产实际应用Hivesql Spark Flink
大数据各功能需要各司其职:
存储:HDFS hive/hbase cassandra kudu
计算:mapreduce==>hive sql/spark/flink
资源和作业的调度:yarn mesos
1.MapReduce概念
map #映射
将一组数据按照规则,映射为一组,其中数据条数不会发生变化
reduce #规约 汇总
数据条数会发生变化
shuffle #洗牌
数据根据key进行网络传输,规整在一起,按规则进行计算
说明:业界有句话,能不shuffle的就不要shuffle,shuffle会拉长计算的时间
作业,job,应用,任务,工作流基本都认为是一个东西
2.MapReduce架构
面试题:mr on yarn提交流程
yarn的架构设计
包含内存+CPU的vcore,其中大数据占内存的75%,这些是留给进程,系统存留25%
包含内存+CPU的vcore,其中大数据占内存的75%,这些是留给进程,系统存留25%
2.1oom-killer机制
当linux服务器某个进程使用内存超标,linux机器为了保护自己,主动杀死我的进程,会释放内存。
2.2container
房间的面积是 memory
房间的电脑是 cpu vcore
房间是 container 是虚拟的概念 其实是一组memory+cpu vcore资源的组合
tmp目录 #30天释放机制
假设电脑有16G,则留给大数据的内存有1675%=12G,*
12G--》12平方
1平方一个房间 1台电脑 cpu vcore
1平方一个房间 2台电脑
12个房间
每个房间只有1G内存 用来计算
房间的面积是 memory
房间的电脑是 cpu vcore
房间是 container 是虚拟的概念 其实是一组memory+cpu vcore资源的组合
100件货
1 个房间 1个人:100h
升级一下
1 个房间 2个人: 50h
在内存够的情况下,适当增加cpu vcore带来计算效率的提升
2.3架构
主从架构
1>Resourcemanager 主 rm
包含:
ApplicationsManager 应用管理器 作业 程序
ResourceScheduler 资源调度器
2>NodeManager 从 nm
2.3.1ResourceManager
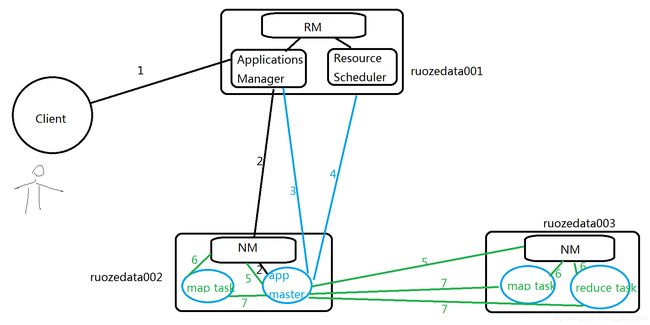
ResourceManager #rm 负责管理
rm=ApplicationsManager(应用管理器:管理作业和程序)+ResourceScheduler(资源调度器)
步骤1.client向rm提交应用(jar包),其中已经包含ApplicationMaster主程序和启动命令。
步骤2.ApplicationsManager会向job分配第一个container。
步骤3.ApplicationMaster向ApplicationsManager注册,就可以在yarn的web界面看到这个(master相当于任务调度分配)
步骤4.ApplicationsManager采取轮询的方式,通过RPC协议向ApplicationsManager申请和领取资源(会告诉你)
===================================
1-4步其实就是启动AppMaster,就是作业的主程序,也叫做应用的主程序,领取资源
===================================
步骤5.一旦app master拿到资源列表,就和对应的nm进程通信,要求启动的任务task 计算代码
步骤6.NM为任务设置好运行环境(container容器 包含jar包等资源) ,将任务启动命令写在一个脚本里,并通过该脚本启动任务task
步骤7.各个任务task通过【rpc】协议向app master汇报自己的进度和状态,以此让app master随时掌握task的运行状态。
当task运行失败,会重启任务。
步骤8.当所有task运行完成后,app master向 apps manager申请注销和关闭作业
这时在页面看 是不是完成的 完成的是成功还是失败的
---------------------
运行任务,直到任务完成。
2.3.2NodeManager
NodeManage 从 nm 负责计算
container是运行在nm进程所在的机器上
main其实就是一个启动类,而其他类才是功能类
2.4yarn
yarn:资源调度管理器
大数据:海量的数据存储和计算(多台计算联合计算,计算的过程中需要内存+cpu,HDFS:存储 MapReduce:计算 yarn:资源调度)
3.wordcount应用

下面从逻辑实体的角度讲解mapreduce运行机制,这些按照时间顺序包括:输入(input )、分片(split)、map阶段、shuffle阶段和reduce阶段。
split个数==map task个数
1>输入文本
split:将文本根据块大小进行分片,分片个数=总文本大小/块大小
map:根据空格进行将文本切分。
就是程序员编写好的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行;
shuffle:将map的输出作为reduce的输入的过程就是shuffle了,这个是mapreduce优化的重点地方。
reduce阶段:和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。
cd app/hadoop
cd src/hadoop-mapreduce1-project/src/examples/org/apache/hadoop/examples/
find ./ -name '*WordCount.java'
sz dir #将这个文件下载到win中
参考:
http://blog.itpub.net/30089851/viewspace-2095837/
4.分片split
在进行map计算之前,
mapreduce会根据输入文件计算输入分片(input split),
每个输入分片(input split)针对一个map任务,
输入分片(input split)存储的并非数据本身,
而是一个分片长度和一个记录数据的位置的数组,
输入分片(input split)往往和hdfs的block(块)关系很密切,
假如我们设定hdfs的块的大小是64mb,
如果我们输入有三个文件,大小分别是3mb、65mb和127mb,
那么mapreduce会把3mb文件分为一个输入分片(input split),
65mb则是两个输入分片(input split)而127mb也是两个输入分片
(input split),
5个分片 5个maptask
块大小有关 还和文件个数有关
换句话说我们如果在map计算前做输入分片调整,
例如不合并小文件,那么就会有5个map任务将执行,
而且每个map执行的数据大小不均,
这个也是mapreduce优化计算的一个关键点。
注意点: 文本格式