Flink简单记录
Flink基本介绍
特点
1 事件驱动

2 无界有状态的数据流
3 分层API
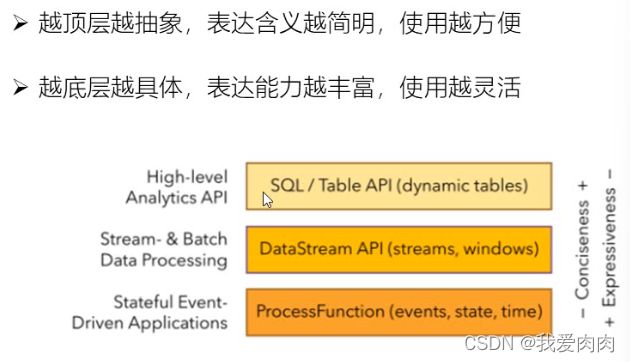
4 支持事件时间和处理时间语义
精确一次的状态一致性保证
低延迟,毫秒级延迟
与众多常用存储系统的连接
高可用,动态扩展,实现7*24小时全天运行
Spark和Flink

Flink Yarn工作模式
1 Session-cluster 模式

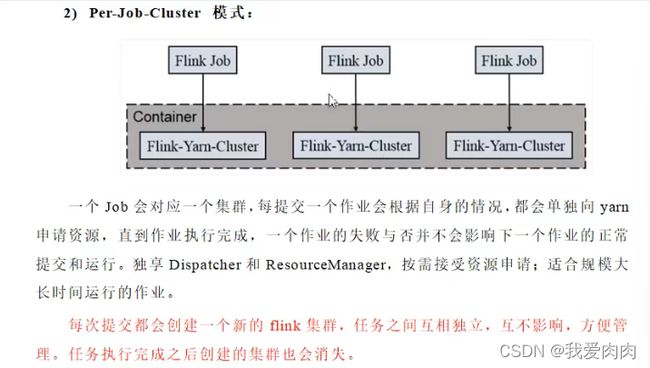
2 Per-Job-Cluster 模式
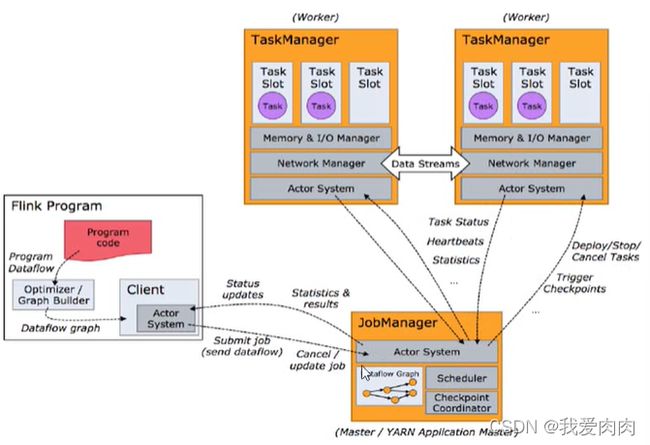
运行时架构
运行时组件
JobManager,TaskManager,ResourceManager,Dispatcher
JobManager

TaskManager

ResourceManager

Dispatcher

任务提交流程/任务调度流程
Yarn 提交

TaskManager和Slot
slot 为最小的计算单元
每个slot内存独享,是资源隔离的
slot可以代码设置共享组 (不同的共享组一定会占用不同的slot)
一个任务占用的slot数量为任务阶段所需slot数量最大的数量。如果slot设置了共享组则为各个共享组最大slot值的总和
TaskManager 就是一个JVM进程,一个TaskManager 包含一个或多个 slot
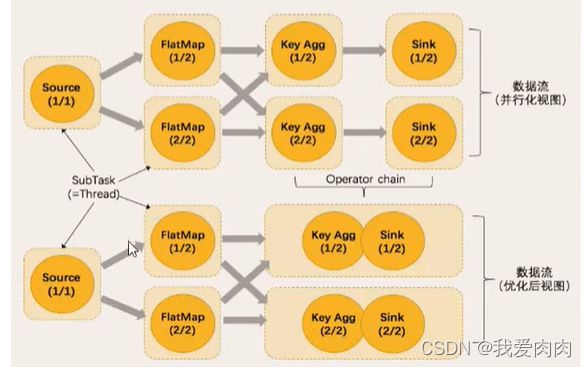
数据流

任务链优化 Operator chain
合并任务进行优化,例如read读数据和flatmap操作经常合并为一个任务
条件:同一共享组,同一并行度,不重分区(是one-one-one)

流处理API
1 Environment API 指定默认并行度,JobManager IP/Port等环境配置。flink做了默认封装
2 Source 读取数据本地数据,外部数据 (如kafka),自定义类读取数据源
例如:DataStream xxx = environment.readxxx
3 TransForm
map,flatMap,filter,
keyBy:基本hash重分区
滚动聚合算子,reduce
split 和 select
split 根据某些特征把一个DataStream 拆分成多个DataStream。select在从中选取一个DataStream
select 和 split 都是根据标签拆分和选取
connect 和 coMap
connect 是合并两条(只能两条)流DataStream得到ConnectedStreams,但是合并的内部两条流是独立分开的,数据和形式不变化
coMap,coFlatMap 是对ConnectedStreams 做处理逻辑,真正的合并两条流
union
合并两条或多条流,但是多条流必须是相同的数据类型
4 支持的数据类型
支持所有的java和scala基础数据类型
支持Java和scala的元组Tuples数据类型
scala样例类 case classes
java 简单对象
5 UDF 函数类
6 shuffle,global等api的重分区
7 sink
stream.addSink(new mySink(xxx))
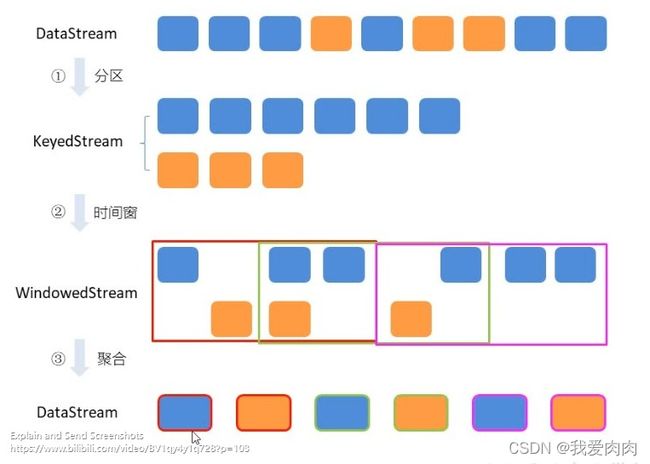
窗口
1 类型
必须keyBy之后才能做window操作,之后对数据做逻辑处理聚合操作
时间窗口
滚动时间:窗口长度固定,没有重叠 (左闭右开)
滑动时间:有重叠
会话窗口:一段时间没有收到数据,则生成新窗口。由指定时间长度间隙组成。时间无对齐
计数窗口
滚动计数
滑动计数
窗口数据处理:
增量聚合:来一条数据就计算,保存一个状态
全窗口聚合:先把所有数据收集起来,等计算时遍历所有数据
时间语义
时间语义
event time:事件创建的时间
ingestion time:数据进入flink的时间
processing time:执行操作算子的本地系统时间,和机器无关 (默认是处理时间)
如果是processing time,水位线默认为0。如果不是processing time模式,水位线默认为200毫秒的周期
设置Event Time
水位线 Watermark
水位线是一条带着时间戳的特殊数据记录
如何避免网络等原因导致乱序数据带来的计算不正确?
-- 水位线是衡量event time进展机制,可以设置延迟触发。可以结合window处理乱序数据问题
水位线传递,引入和设定
延迟时间太久可能会导致得到结果很慢,太快可能会导致数据错误。
1 用水位线
2 如果依然缺数据,可以用flink处理迟到数据机制 allowLateness(Time.minutes(1)) 延长保存时间。
3 如果依然缺数据,用sideOutputLateData(xxxTag) 再收集迟到的数据做额外的处理

1 例如当水位线通过广播传递到下游设置到8,则8之前的数据就不再接收。
2 整体思路:假设延迟设置3,当数据8传递过来时,水位线则为5。例如此时第一个桶范围为0-5,不再接受新数据,计算结束后就丢弃。水位线到5之前,该桶会一直保留等待数据
3 每个任务可能上游有多个并行任务,会同时发送多个水位线,按照木桶原理取最小的水位线
状态管理

算子状态 Operatior State
算子任务范围
列表,联合列表 (会checkpoint保存,故障或重启等情况可以检查点恢复数据),广播列表
根据算子任务共享状态

键控状态 Keyed State
根据输入数据流中定义的key来维护和访问
类型:value状态,list列表状态,key-value状态,聚合状态
根据key共享状态
状态后端 State Backends


ProcessFunction API (底层API)

容错机制
一致性检查点 checkpoint
一致性表达这个时间点,所有任务恰好处理完一个相同的输入数据
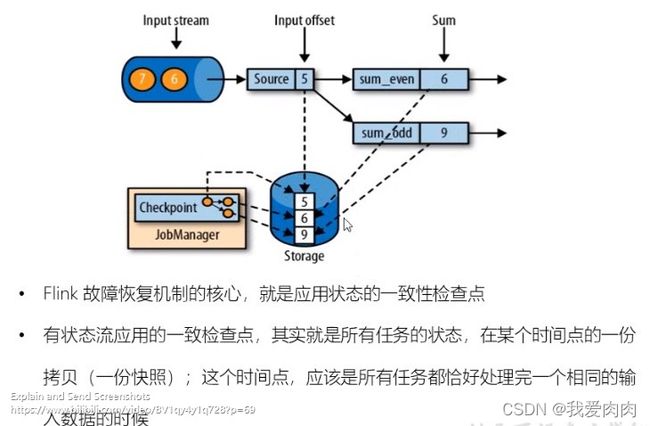
从检查点恢复状态
Flink 检查点算法 (通过时间间隔参数触发)
基于chandy-lamport算法的分布式快照,分别保存最后合并
保存点 Savepoints
和检查点基本一致,额外多了可以有计划的手动备份

状态一致性
状态一致性
就是保证数据计算结果正确,不丢失数据,不重复计算。数据丢失恢复后能完全正确。
flink 使用轻量级快照机制,检查点来保证精确一次
一致性检查点 checkpoint
端到端状态一致性
端到端精确一次保证
内部保证:checkpoint
source端:可重设数据读取位置,数据丢了重传
sink端:从故障恢复时,数据不会重复写入外部系统
幂等写入
事务写入:原子性,所有操作要么全成功,要么全失败。失败就回滚
等所有checkpoint完成,才提交
实现方式:
预写日志:预存,checkpoint全部结束,一批全部写入。但是批处理性能差
两阶段提交 2pc:

flink+kafka端到端状态一致性保证

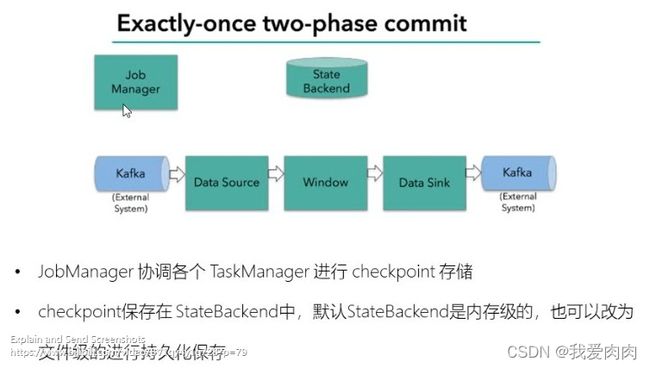

当所有算子都通知Job Manager 计算已完成,Job Manager则决定任务全部完成,状态由预提交改成已提交