Kotlin 协程实战进阶(二、进阶篇:协程的取消、异常处理、Channel、Flow)
前言
上一篇文章对协程的概念和原理、协程框架的基础使用、挂起函数以及挂起与恢复等做了详细的分析,如果您对协程有一定的理解,可以阅读《Kotlin 协程实战进阶(一、筑基篇)》我们来对协程整体认识来做一个整体的交流。由于篇幅原因还有一部分重要的知识点没有讲解到,接下来继续分析 Kotlin 协程的重要要素和使用,首先来回顾一下上篇文章的整体内容:
- 1、
Coroutine:协程的概念和原理:协程是什么以及它的作用和特点,图解分析协程的工作原理。 - 2、
Coroutine builders:协程的构建,协程构建器创建协程的三种方式。 - 3、
CoroutineScope:协程作用域,协程运行的上下文环境,用来提供函数支持,也是用来增加限制。常见的7种作用域(包含Lifecycle支持的协程)以及作用域的分类和行为规则。 - 4、
Job&Deferred:协程的句柄,实现对协程的控制和管理,Deferred有返回值。 - 5、
CoroutineDispatcher:协程调度器,确定相应的协程在那个线程上执行,调度器的四种模式以及withContext主要是为了切换协程上下文环境。 - 6、
CoroutineContext:协程上下文,表示协程的运行环境,包括协程调度器、代表协程本身的Job、协程名称、协程ID以及组合上下文的使用。 - 7、
CoroutineStart:一个枚举类,为协程构建器定义四中启动模式。 - 8、
suspend:挂起函数,Kotlin 协程最核心的关键字。一种避免阻塞线程并用更简单、更可控的操作替代线程阻塞的方法:协程挂起和恢复。
本文大纲
三、协程取消
在日常的开发中,我们都知道应该避免不必要的任务,需要控制好协程的生命周期,在不需要使用的时候将它取消。
1.调用 cancel 方法
协程通过抛出一个特殊的异常CancellationException来处理取消操作。一旦抛出了CancellationException异常,便可以使用这一机制来处理协程的取消。在调用job.cancel时你可以传入一个 CancellationException实例来提供指定错误信息:
public fun cancel(cause: CancellationException? = null)
该参数是可空的,如果不传参数则会使用默认的defaultCancellationException()作为参数。
子协程会通过抛出异常的方式将取消的情况通知到它的父协程。父协程通过传入的取消原因来决定是否来处理该异常。如果子协程因为CancellationException而被取消的,那么对于父协程来说不需要进行额外操作。
我们可以通过直接取消协程启动所涉及的整个作用域 (scope) 来取消所有已创建的子协程:
//创建作用域
val scope = CoroutineScope(Dispatchers.Main)
//启动一个协程
val job = scope.launch {
//TODO
}
//作用域取消
scope.cancel()
取消作用域会取消它的所有子协程。注意:已取消的作用域无法再创建协程。可以使用try…catch捕获到CancellationException。
如果仅仅是因为要取消某个进行中的任务而取消其中某一个协程,那么调用该协程的job.cancel()方法确保只会取消跟job相关的特定协程,而不会影响其它兄弟协程。
//创建作用域
val scope = CoroutineScope(Dispatchers.Main)
//协程job1将会被取消,而另一个job2则不受任何影响
val job1 = scope.launch {
//TODO
}
val job2 = scope.launch {
//TODO
}
//取消单个协程
job1.cancel()
被取消的子协程并不会影响其余兄弟协程。
如果使用的是androidx KTX库的话,在大部分情况下都不需要创建自己的作用域,所以也就不需要负责取消它们。
viewModelScope和lifecycleScope都是 CoroutineScope对象,它们都会在适当的时间点被取消。当ViewModel被清除时,在其作用域内启动的协程也会被一起取消。lifecycleScope会与当前的UI组件绑定生命周期,界面销毁时该协程作用域将被取消,不会造成协程泄漏。
2.协程的状态检查
如果仅仅是调用了cancel方法,并不意味着协程所处理的任务也会停止。在使用协程处理了一些相对较为繁重的工作,比如读取多个文件,不会立即停止此任务的进行。
举个栗子,我们使用协程来500毫秒打印一次数据,先让协程运行1.2秒,然后将其取消:
fun jobTest() = runBlocking {
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (i < 5) {//打印前五条消息
if (System.currentTimeMillis() >= nextPrintTime) {//每秒钟打印两次消息
print("job: I'm sleeping ${i++} ...")
nextPrintTime += 500
}
}
}
delay(1200)//延迟1.2s
print("等待1.2秒后")
job.cancel()
print("协程被取消")
}
打印数据如下:

当job.cancel方法被调用后,我们的协程转变为取消中 (cancelling) 的状态。但是紧接着我们发现第3和第4条数据打印到了命令行中。当协程处理的任务结束后,协程又转变为了已取消 (cancelled) 状态。
重新来看看Job的生命周期:
一个Job可以包含一系列状态: 新创建 (New)、活跃 (Active)、完成中 (Completing)、已完成 (Completed)、取消中 (Cancelling) 和已取消 (Cancelled)。虽然我们无法直接访问这些状态,但是我们可以访问Job的属性: isActive、isCancelled 和 isCompleted。Job的生命周期如下图(来自官网):

如果协程处于活跃状态,协程运行出错或者调用job.cancel()都会将当前任务置为取消中 (Cancelling) 状态 (isActive = false, isCancelled = true)。当所有的子协程都完成后,协程会进入已取消 (Cancelled) 状态,此时 isCompleted = true。
协程所处理的任务不会仅仅在调用cancel方法时就停止,相反,我们需要修改代码来定期检查协程是否处于活跃状态。在处理任务之前添加对协程状态的检查:
while (i < 5 && isActive) //当job是活跃状态继续执行
那么我们的任务只会在协程处于活跃的状态下执行。在协程取消后,第3和第4条数据不会被打印出来。
3.join() & await() 的取消
等待协程处理结果有两种方法: 来自launch的Job.join()方法,由async返回的Deferred.await()方法。
Job.join()会挂起协程,直到任务处理完成。
val job = launch {
//TODO
}
job.cancel()//取消协程
job.join()//挂起并调用协程,直到job完成
//job.cancelAndJoin()//挂起并调用协程,直到被取消的job完成
与job.cancel()一起使用时,会按照以下方式进行:
- 如果在
job.cancel()之后再调用job.join(),那么协程会一直处于挂起状态直到任务处理完成; - 在
job.join()之后调用job.cancel()没有什么影响,因为job已经完成了。
如果需要获取协程处理结果,那么应该使用Deferred。当协程完成后,结果会由Deferred.await()返回。Deferred继续自Job,它同样可以被取消。
val deferred = async {
delay(1000)
print("asyncTest")
}
deferred.cancel()//取消
deferred.await()//会抛出JobCancellationException
delay():在给定时间内延迟协程而不阻塞线程,并在指定时间后恢复协程。你可以认为它实际上就是触发了一个延时任务,告诉协程调度系统多久之后再来执行后面的代码。
在已取消的deferred上调用await()会抛出JobCancellationException异常。因为await()是负责在协程处理结果出来之前一直将协程挂起,如果协程被取消了那么协程就不会继续进行计算也不会有结果产生。因此,在协程取消后调用await()会抛出JobCancellationException异常: 因为Job已经被取消。
另外,如果在deferred.await()之后调用deferred.cancel()不会有任何情况发生,因为协程已经处理结束。
4.finally释放资源
如果要在协程取消后执行某个特定的操作,比如关闭可能正在使用的资源,或者是针对取消需要进行日志打印,又或者是执行其余的一些清理代码。那该怎么样做?
当协程被取消后会抛出CancellationException异常,我们可以将挂起的任务放置于try…catch…finally代码块中,catch中捕获取消后抛出的异常,在finally代码块中执行需要做的清理任务。
val job = GlobalScope.launch {
try {
//TODO
delay(500L)
} catch (e: CancellationException) {
print("协程取消抛出异常:$e")
} finally {
print("协程清理工作")
}
}
job.cancel()//取消协程
打印数据如下:
[DefaultDispatcher-worker-1] 协程取消抛出异常:kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job=StandaloneCoroutine{Cancelling}@bb81f53
[DefaultDispatcher-worker-1] 协程清理工作
但是,如果需要执行的清理工作也需要挂起,那么上面就行不通了,因为一旦协程处于取消中状态,它将不能再转为挂起 (suspend) 状态。
5.NonCancellable
如果协程被取消后需要调用挂起函数进行清理任务,可使用NonCancellable单例对象用于withContext函数创建一个无法被取消的协程作用域中执行。这样会挂起运行中的代码,并保持协程的取消中状态直到任务处理完成。
val job = launch {
try {
//TODO
} catch (e: CancellationException) {
print("协程取消抛出异常")
} finally {
withContext(NonCancellable) {
delay(100)//或者其他挂起函数
print("协程清理工作")
}
}
}
delay(500L)
job.cancel()//取消协程
但是这个方法需要慎用,这样做风险很高,因为可能会无法控制协程的执行。
6.withTimeout
withTimeout 函数用于指定协程的运行超时时间,如果超时则会抛出TimeoutCancellationException,从而令协程结束运行。
withTimeout(1300) {//1300毫秒后超时抛出TimeoutCancellationException异常
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500)
}
}
打印结果如下:
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Exception in thread "main" kotlinx.coroutines.TimeoutCancellationException: Timed out waiting for 1300 ms
如果你不想抛出异常,可以使用withTimeoutOrNull(),在超时时返回null而不是异常。
四、异常处理
1.try…catch
协程使用一般的 Kotlin 语法处理异常: try…catch或内建的工具方法,比如runCatching(其内部还是使用了 try…catch),所有未捕获的异常一定会被抛出。但是,不同的协程 Builder 对异常有不同的处理方式。
使用launch时,异常会在它发生的第一时间被抛出,就可以将抛出异常的代码包裹到try…catch中:
val scope = CoroutineScope(Dispatchers.Main)
scope.launch {
try {
print("模拟抛出一个数组越界异常")
throw IndexOutOfBoundsException() //launch 抛出异常
} catch (e: Exception) {
//处理异常
print("这里处理抛出的异常")
}
}
打印数据如下:
[main] 模拟抛出一个数组越界异常
[main] 这里处理抛出的异常
当async被用作根协程 (CoroutineScope实例或supervisorScope的直接子协程) 时不会自动抛出异常,而是在调用await()时才会抛出异常。为了捕获其中抛出的异常,可以用try…catch包裹调用await()的代码:
supervisorScope {
val deferred = async {
print("模拟抛出一个算术运算异常")
throw ArithmeticException()
}
try {
deferred.await()
} catch (e: Exception) {
//处理异常
print("这里处理抛出的异常")
}
}
打印数据如下:
[main] 模拟抛出一个算术运算异常
[main] 这里处理抛出的异常
注意:async在 coroutineScope 构建器或在其他协程创建的协程中抛出的异常不会被 try/catch 捕获!
相对来来说,Job是会在层级间自动传播异常,除了当async被用作根协程时不会自动抛出异常外,async中其他协程所创建的协程中产生的异常总是会被传播,无论协程的 Builder 是什么。这样一来catch部分的代码块就不会被调用,异常会被传播和传递到scope:
scope.launch {
try {
val deferred = async {
print("模拟抛出一个空指针异常")
throw NullPointerException()
}
deferred.await()
} catch (e: Exception) {
// async 中抛出的异常将不会在这里被捕获
// 但是异常会被传播和传递到 scope
print("这里不能不会异常,异常向上传播")
}
}
由于scope的直接子协程是launch,如果async中产生了一个异常,这个异常将就会被立即抛出。原因是async (包含一个Job在它的CoroutineContext中) 会自动传播异常到它的父级 (launch),这会让异常被立即抛出。打印数据如下:

2.异常在作用域内的传播
协程的异常是会分发传播的,牵连到其他兄弟协程以及父协程。
当协程因出现异常失败时,它会将异常传播到它的父级,父级会取消其余的子协程,同时取消自身的执行。最后将异常再传播给它的父级。当异常到达当前层次结构的根,在当前协程作用域启动的所有协程都将被取消。
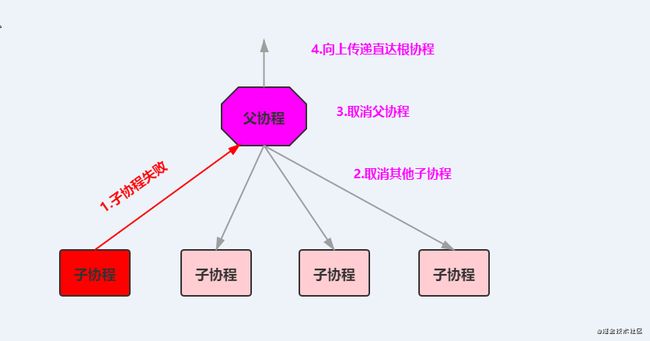
一般情况下这样的异常传播是合理的,但是在应用中处理与用户的交互,当其中一个子协程出现异常,那就可能导致所在作用域被取消,也就无法开启新的协程,最后整个UI组件都无法响应。
可以使用SupervisorJob来解决这个问题,下面会讲解到。这里先给出异常在作用域内的传播的结论。当协程出现异常时,会根据当前作用域触发异常传递:
-
coroutineScope一般情况下,协程的取消操作会通过协程的层次结构来进行传播。如果取消父协程或者父协程抛出异常,那么子协程都会被取消。而如果子协程被取消,则不会影响同级协程和父协程,但如果子协程抛出异常则也会导致同级协程被取消和将异常传递给父协程,进而导致整个协程作用域失败。 -
supervisorScope它的取消操作只会向下传播,一个子协程的运行失败不会影响到其他子协程,内部的异常不会向上传播,不会影响父协程和兄弟协程的运行。
3.SupervisorJob
它类似于常规的Job,唯一不同的是SupervisorJob的取消只会向下传播,一个子协程的运行失败不会影响到其他协程。
SupervisorJob: 它的一个子协程的运行失败或取消不会导致自己失败,也不会影响到其他子协程。SupervisorJob不会取消它自己和它的子协程,也不会传播异常并传递给它的父级,它会让子协程自己处理异常。supervisorScope: 监督作用域,使用SupervisorJob创建一个作用域。一个子域的失败不会导致这个范围失败,也不会影响它的其他子域,可以实现一个自定义的策略来处理其子域的失败。作用域本身的失败(在[block]或取消中抛出异常)会导致作用域及其所有子Job失败,但不会取消父Job。
为了更好理解下面的例子,你需要知道的两个知识点:
1.协程通过抛出一个特殊的异常
CancellationException来处理取消操作。(上面协程取消讲到)2.未被捕获的异常一定会被抛出,无论您使用的是哪种 Job,如果异常没有被捕获处理,而且
CoroutineContext没有一个CoroutineExceptionHandler(稍后讲到) 时,异常会到达默认线程的ExceptionHandler。在JVM中,异常会被打印在控制台;在Android中,无论异常在那个Dispatcher中发生,都会导致应用崩溃。
下面使用suspend main函数举个栗子,方便在控制台打印数据:
suspend fun main() {
try {
coroutineScope {
print("1")
val job1 = launch {//第一个子协程
print("2")
throw NullPointerException()//抛出空指针异常
}
val job2 = launch {//第二个子协程
delay(1000)
print("3")
}
try {//这里try…catch捕获CancellationException
job2.join()
println("4")//等待第二个子协程完成:
} catch (e: Exception) {
print("5. $e")//捕获第二个协程的取消异常
}
}
} catch (e: Exception) {//捕获父协程的取消异常
print("6. $e")
}
Thread.sleep(3000)//阻塞主线程3秒,以保持JVM存活,等待上面执行完成
}

上面代码稍微有点儿复杂,但也不难理解。我们在一个 coroutineScope 当中启动了两个同级的子协程,在job1中抛出了未捕获的异常,那么job2也抛出取消异常,接着job1中的异常向上传递给父协程,在最外层捕获到了传递给父级的NullPointerException。
如果把 coroutineScope 换成 supervisorScope,其他不变,运行结果会是怎样呢?

我们发现job1抛出的异常并没有影响父级作用域以及作用域内的其他子协程job2的执行。注意:将SupervisorJob作为参数传入一个协程的构造参数里面不能带来上面这样的效果。
那么应该在什么时候去使用Job或SupervisorJob呢?如果您想要在出现错误时不会退出父级和其他平级的协程,那就使用SupervisorJob或supervisorScope。比如一个网络请求失败了,所有其他的请求都将被立即取消,这种需求选择coroutineScope。相反,如果即使一个请求失败了其他的请求也要继续,则可以使用 supervisorScope,当一个协程失败了,supervisorScope是不会取消剩余子协程的。
建议大家尽量不要直接使用标准库API,除非对协程的机制非常熟悉。对于可能出异常的情况,尽量做好异常处理,不要将问题复杂化。
4.CoroutineExceptionHandler
CoroutineExceptionHandler异常处理器属于协程上下文的一种,需要将其添加到协程上下文中。可以处理未捕获的异常。在这里进行自定义日志记录或异常处理,它类似于对线程使用Thread.uncaughtExceptionHandler。
异常如果需要被捕获,则需要满足下面两个条件:
- 这个异常是被自动抛出异常的协程所抛出的 (是
launch,而不是async); CoroutineExceptionHandler设置在CoroutineScope的上下文中或者在一个根协程 (CoroutineScope或者supervisorScope的直接子协程) 中。
定义一个异常处理器:
val handler = CoroutineExceptionHandler { context, exception ->
print("捕获到的异常: $exception")
}
举个例子,在下面的代码中,launch产生的异常会被handler捕获,而async的不会:
runBlocking {
val scope = CoroutineScope(Job())
val job = scope.launch(handler) {//父协程中设置异常处理器
launch {//子协程抛出异常
throw NullPointerException()
}
async {//没有任何效果,用户调用await()会异常崩溃
throw IllegalArgumentException()
}
}
job.join()//暂停协程,直到任务完成
}
CoroutineExceptionHandler只会在预计由用户不处理的异常上调用,它可以捕获CoroutineExceptionHandler设置在父协程上下文中并且launch抛出的异常。在async中使用它没有任何效果,因为async构建器始终会捕获所有异常并将其表示在结果Deferred对象中,因此它的CoroutineExceptionHandler也无效。当async内部发生了异常且没有捕获时,那么调用async.await()依然会导致应用崩溃。打印数据如下:
[DefaultDispatcher-worker-1] 捕获到的异常: java.lang.NullPointerException
handler被设置给了一个内部协程,那么它将不会捕获异常,SupervisorJob直接子协程例外:
runBlocking {
val scope = CoroutineScope(Job())
scope.launch {
launch(handler) {//子协程设置没有意义,不会打印数据,因为异常向上传递,而父协程中没有handler则无法捕获
throw NullPointerException()//抛出空指针异常
}
}
supervisorScope {
launch(handler) {//SupervisorJob不会让异常向上传递,会使用子协程内部的异常处理器来处理
throw IllegalArgumentException()//抛出非法参数异常
}
}
}
子协程设置异常处理器是无效的,因为子协程出了异常依然会抛到父协程,而父协程中没有handler则无法捕获,所以在子协程中捕获异常没有意义。在监督作业(SupervisorJob)直接子协程设置异常处理器,不会让异常向上传递,从而被其内部的异常处理器来处理。打印数据如下:
[main] 捕获到的异常: java.lang.IllegalArgumentException
没有被捕获的异常会被传播,想要避免取消操作在异常发生时被传播,记得使用SupervisorJob;反之则使用Job。
注意:
1.协程内部使用CancellationException来进行取消,这个异常会被所有的处理者忽略,所以那些可以被catch代码块捕获的异常仅仅应该被用来作为额外调试使用的资源。
2.当协程的多个子协程因异常失败时,一般规则是"取第一个异常",因此将处理第一个异常。在第一个异常之后发生的所有其他异常读作为被抑制的异常绑定至第一个异常。
五、Channel
Channel是非阻塞的通信基础设施,它实际上就是一个队列,而且是并发安全的,可以用来连接协程,实现不同协程的通信。可以在两个或多个协程之间完成消息传递,多个作用域可以通过一个Channel对象来进行数据的发送和接收。类似于BlockingQueue+挂起函数,称为热数据流。
GlobalScope.launch {
// 1. 创建 Channel
val channel = Channel<Int>()
// 2. Channel 发送数据
launch {
for (i in 1..3) {
delay(100)
channel.send(i)//发送
}
channel.close()//关闭Channel,发送结束
}
// 3. Channel 接收数据
launch {
repeat(3) {
val receive = channel.receive()//接收
print("接收 $receive")
}
}
}
三个步骤使用Channel在实现协程之间数据传输。在一个协程中每隔100毫秒发送一条数据,在另一个协程中接收数据。打印如下:
[main] 接收 1
[main] 接收 2
[main] 接收 3
1.创建 Channel
创建Channel的方式有两种:
- 直接使用
Channel对象创建,如上 - 拓展函数
produce:启动一个生产者协程,返回一个ReceiveChannel。它启动的协程在结束后会自动关闭对应的Channel。
GlobalScope.launch {
// 1. produce创建一个 Channel
val channel = produce<Int> {
for (i in 1..3) {
delay(100)
send(i)//发送数据
}
}
// 2. 接收数据
launch {
for (value in channel) {//for 循环打印接收到的值(直到渠道关闭)
print("接收 $value")
}
}
}
拓展函数produce直接将创建Channel和发送数据合为一步了。
2.发送数据
channel.send():发送数据。channel.close():关闭Channel,数据发送完毕。
当我们数据发送完毕的时候,可以使用Channel.close()关闭通道,数据发送结束。
3.接收数据
channel.receive():接收数据。
一般调用 Channel#receive() 获取数据,但是这个方法只能获取一次传递的数据,如果我们知道获取数据的次数:
repeat(3) {//重复3次接收数据
val receive = channel.receive()//接收数据
print("接收 $receive")
}
如果我们不知道接收的数据有多少,则使用迭代Channel来接收数据:
for (value in channel) {// for 循环打印接收到的值(直到渠道关闭)
print("接收 $value")
}
Channel 的可以说为协程注入了灵魂。每一个独立的协程不再是孤独的个体, Channel 可以让他们更加方便的协作起来。但是在Flow出来之后,就很少使用到Channel了,接下来我们看看冷数据流Flow。
热数据流与冷数据流:
- 热数据流:无观察者时,也会生产数据。你不订阅,它也会发送数据。比如某场影片在电影院播放,你要去电影院看才能看到,你不去这场电影也是会正常放的;
- 冷数据流:无消费者时,则不会生产数据。你触发了,它才有数据发送过来。比如这场电影在网络上公开了,你不去播放他就不会播放,你主动播放了他才会播放。RxJava相对应的是协程的冷数据流
Flow。
六、Flow
Flow是一种异步数据流,它按顺序发出值并正常或异常完成。是 Kotlin 协程的响应式API,类似于 RxJava 的存在。
每一个Flow其内部是按照顺序执行的,这一点跟Sequences很类似。Flow跟Sequences之间的区别是Flow不会阻塞主线程的运行,而Sequences会阻塞主线程的运行。
1.基础
创建 Flow 对象
Flow也为我们提供了快速创建操作:
Flow: 创建Flow的普通方法,从给定的一个挂起函数创建一个冷数据流。channelFlow:支持缓冲通道,线程安全,允许不同的CorotineContext发送事件。.asFlow(): 将其他数据转换成普通的flow,一般是集合向Flow的转换。flowof(vararg elements: T):使用可变数组快速创建flow,类似于listOf()。
比如可以使用 (1..3).asFlow()或者flowof(1..3)创建Flow对象。
消费数据
lifecycleScope.launch {
//1.创建一个Flow
flow {
for (i in 1..3) {
delay(200)
//2.发出数据
emit(i)
}
}.collect {//3.从流中收集值
print("收集:$it")
}
}
打印数据如下:
[main] 收集:1
[main] 收集:2
[main] 收集:3
和 RxJava 一样,在创建 Flow 对象的时候我们也需要调用 emit 方法发射数据,collect 方法用来消费收集数据。
emit(value): 收集上游的值并发出。不是线程安全,不应该并发调用。线程安全请使用channelFlow而不是flow。collect(): 接收给定收集器emit()发出的值。它是一个挂起函数,在所在作用域的线程上执行。
flow的代码块只有调用collected()才开始运行,正如 RxJava 创建的 Observables只有调用subscribe()才开始运行一样。如果熟悉 RxJava 的话,则可以理解为collect()对应subscribe(),而emit()对应onNext()。
| 对比类型 | Flow | RxJava |
|---|---|---|
| 数据源 | Flow |
Observable |
| 订阅 | collect |
subscribe |
| 发射 | emit() |
onNext() |
冷数据流
Flow是一种冷数据流,流生成器中的代码直到流被收集起来才会运行。一个Flow创建出来之后,不消费则不生产,多次消费则多次生产,生产和消费总是相对应的。
所谓冷数据流,就是只有消费时才会生产的数据流,这一点与 Channel 正对应:Channel 的发送端并不依赖于接收端。
val flow = flow {
for (i in 1..3) {
delay(200)
emit(i)//从流中发出值
}
}
lifecycleScope.launch {
flow.collect { print("$it") }
flow.collect { print("$it") }
}
消费它会输出 1,2,3,重复消费它会重复输出 1,2,3。RxJava 的 Observable 也是如此,每次调用它的 subscribe 都会重新消费一次。
2.线程切换
RxJava 也是一个基于响应式编程模型的异步框架,牛逼的地方就是切换线程。提供了两个切换调度器的 API 分别是 subscribeOn 和 observeOn,Flow也可以设定它运行时所使用的调度器,它更加简单,只需使用flowOn就可以了:
lifecycleScope.launch {
//创建一个Flow通过flowOn()改变的是Flow函数内部发射数据时的线程,而在collect收集数据时会自动切回创建Flow时的线程。
Flow的调度器 API 中看似只有flowOn与subscribeOn对应,其实不然,collect所在协程的调度器则与observeOn指定的调度器对应。
| 对比类型 | Flow | RxJava |
|---|---|---|
| 改变数据发送的线程 | flowOn |
subscribeOn |
| 改变消费数据的线程 | 它自动切回所在协程的调度器 | observeOn |
注意:不允许在内部使用withContext()来切换flow的线程。因为flow不是线程安全的,如果一定要这么做,请使用channelFlow。
3.异常处理
Flow的异常处理也比较直接,直接调用 catch 函数即可:
lifecycleScope.launch {
flow {
emit(10)//从流中发出值
throw NullPointerException()//抛出空指针异常
}.catch { e ->//捕获上游抛出的异常
print("caught error: $e")
}.collect {
print("收集:$it")
}
}
打印数据如下:
[main] 收集:10
[main] caught error: java.lang.NullPointerException
在Flow的参数中抛了一个空指针异常,在catch函数中就可以直接捕获到这个异常。如果没有调用catch函数,未捕获异常会在消费时抛出。catch 函数只能捕获它的上游的异常。
Flow中的catch对应着 RxJava 中的 onError:
| 对比 | Flow | RxJava |
|---|---|---|
| 异常 | catch |
onError |
注意:流收集还可以使用try{}catch{}块来捕获异常。
4.完成和取消
onCompletion
如果我们想要在流完成时执行逻辑,可以使用 onCompletion:
lifecycleScope.launch {
flow {
emit(10)
}.onCompletion {//流操作完成回调
print("Flow 操作完成")
}.collect {
print("收集:$it")
}
}
打印数据如下:
[main] 收集:10
[main] Flow 操作完成
| 对比 | Flow | RxJava |
|---|---|---|
| 完成 | onCompletion |
onComplete |
注意:流还可以使用try{}finally{}块在收集完成时执行一个动作。
取消
Flow没有提供取消操作,Flow的消费依赖于collect末端操作符,而它们又必须在协程当中调用,因此Flow的取消主要依赖于末端操作符所在的协程的状态。
lifecycleScope.launch {
//1.创建一个子协程
val job = launch {
//2.创建flow
val intFlow = flow {
(1..5).forEach {
delay(1000)
//3.发送数据
emit(it)
}
}
//4.收集数据
intFlow.collect {//收集
print(it)
}
}
//5.在3.5秒后取消协程
delay(3500)
job.cancelAndJoin()
}
1000毫秒发送一次数据,3500毫秒后取消协程,因此flow收集到1,2,3后被取消。想要取消Flow只需要取消它所在的协程。
5.背压
什么是背压?就是在生产者的生产速率高于消费者的处理速率的情况下出现,发射的量大于消费的量,造成了阻塞,就相当于压力往回走,这就是背压。只要是响应式编程,就一定会有背压问题。处理背压问题有以下三种方式:
buffer: 指定固定容量的缓存;conflate: 保留最新值;collectLatest:新值发送时,取消之前的。
添加缓冲
可以为buffer指定一个容量。不需要等待收集执行就立即执行发射数据,只是数据暂时被缓存而已,提高性能,如果我们只是单纯地添加缓存,而不是从根本上解决问题就始终会造成数据积压。
lifecycleScope.launch {
val time = measureTimeMillis {//计算耗时
flow {
for (i in 1..3) {
delay(100)//假设我们正在异步等待100毫秒
emit(i)//发出下一个值
}
}.buffer()//缓存排放,不要等待
.collect { value ->
delay(300)//假设我们处理了300毫秒
print(value)
}
}
print("收集耗时:$time ms")
}
需要100毫秒才能发射一个元素;收集器处理一个元素需要300毫秒。那么顺序执行发送接收三个数据的话大概需要1200毫秒,但是使用buffer()创建缓存,不要等待,运行更快。打印数据如下:
[main] 1
[main] 2
[main] 3
[main] 收集耗时:1110 ms
conflate
当flow表示操作的部分结果或操作状态更新时,可能不需要处理每个值,而是只处理最近的值。
lifecycleScope.launch {
val time = measureTimeMillis {//计算耗时
flow {
for (i in 1..3) {
delay(100)//假设我们正在异步等待100毫秒
emit(i)//发出下一个值
}
}.conflate()//合并排放,而不是逐个处理
.collect { value ->
delay(300)//假设我们处理了300毫秒
print(value)
}
}
print("收集耗时:$time ms")
}
当数字1扔在处理时,数字2和数字3已经产生了,所以数字2被合并,只有最近的数字1(数字3)被交付给收集器。打印数据如下:
[main] 1
[main] 3
[main] 收集耗时:802 ms
collectLatest
另一种方法是取消慢速收集器,并在每次发出新值时重新启动它。collectLatest在它们执行和 conflate操作符相同的基本逻辑,但是在新值上取消其块中的代码。
lifecycleScope.launch {
val time = measureTimeMillis {
flow {
for (i in 1..3) {
delay(100)//假设我们正在异步等待100毫秒
emit(i)//发出下一个值
}
}.collectLatest { value ->//取消并重新启动最新的值
print("收集的值:$value")
delay(300)//假设我们处理了300毫秒
print("完成:$value")
}
}
print("收集耗时:$time ms")
}
由于collectLatest的代码需要300毫秒的时间,但是每100毫秒就会发出一个新值,所以我们看到代码块在每个值上运行,但只在最后一个值上完成。打印数据如下:
[main] 收集的值:1
[main] 收集的值:2
[main] 收集的值:3
[main] 完成:3
[main] 收集耗时:698 ms
6.操作符
Kotlin 协程的flow提供了许多操作符来处理数据,下面整理了一些比较常用的操作符:
基本操作符
| Flow 操作符 | 作用 |
|---|---|
map |
转换操作符,将值转换为另一种形式输出 |
take |
接收指定个数发出的值 |
filter |
过滤操作符,返回只包含与给定规则匹配的原始值的流。 |
末端操作符
做 collect 处理,collect 是最基础的末端操作符。
| 末端流操作符 | 作用 |
|---|---|
collect |
最基础的收集数据,触发flow的运行 |
toCollection |
将结果添加到集合 |
launchIn |
在指定作用域直接触发流的执行 |
toList |
给定的流收集到 List 集合 |
toSet |
给定的流收集到 Set 集合 |
reduce |
规约,从第一个元素开始累加值,并将参数应用到当前累加器的值和每个元素。 |
fold |
规约,从[初始]值开始累加值,并应用[操作]当前累加器值和每个元素 |
功能性操作符
| 功能性操作符 | 作用 |
|---|---|
retry |
重试机制 ,当流发生异常时可以重新执行 |
cancellable |
接收的的时候判断 协程是否被取消 ,如果已取消,则抛出异常 |
debounce |
防抖节流 ,指定时间内的值只接收最新的一个,其他的过滤掉。搜索联想场景适用 |
回调操作符
| 回调流操作符 | 作用 |
|---|---|
onStart |
在上游流开始之前被调用。 可以发出额外元素,也可以处理其他事情,比如发埋点 |
onEach |
在上游向下游发出元素之前调用 |
onEmpty |
当流完成却没有发出任何元素时回调,可以用来兜底。 |
组合操作符
| 组合流操作符 | 作用 |
|---|---|
zip |
组合两个流,分别从二者取值,一旦一个流结束了,那整个过程就结束了 |
combine |
组合两个流,在经过第一次发射以后,任意方有新数据来的时候就可以发射,另一方有可能是已经发射过的数据 |
展平流操作符
展平流有点类似于 RxJava 中的 flatmap,将你发射出去的数据源转变为另一种数据源。
| 展平流操作符 | 作用 |
|---|---|
flatMapConcat |
串行处理数据,展开合并成一个流 |
flatMapMerge |
并发地收集所有流,并将它们的值合并到单个流中,以便尽快发出值 |
flatMapLatest |
一旦发出新流,就取消前一个流的集合 |
其他还有一些操作符,我这里就不一一介绍了,感兴趣可以查看 API。在实际场景中按需使用,比如搜索场景使用debounce防抖,网络请求使用retry重试,数据合并使用combine等操作符。
学习协程和Kotlin还是很有必要的,简化代码的逻辑,写出优雅的代码,提升开发效率。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,很感谢您阅读这篇文章。我是suming,感谢各位的支持和认可,您的点赞就是我创作的最大动力。山水有相逢,我们下篇文章见!
本人水平有限,文章难免会有错误,请批评指正,不胜感激 !
Kotlin协程学习三部曲:
- 《Kotlin 协程实战进阶(一、筑基篇)》
- 《Kotlin 协程实战进阶(二、进阶篇)》
- [Kotlin 协程实战进阶(三、原理篇)]
参考链接:
- Kotlin官网
- 《深入理解Kotlin协程》
- 慕课网之《新版Kotlin从入门到精通》
- 最全面的Kotlin协程: Coroutine/Channel/Flow 以及实际应用