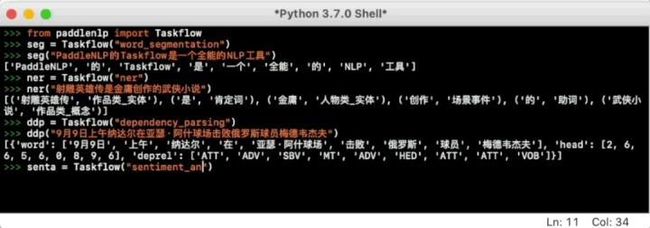
2021年10月,PaddleNLP聚合众多百度自然语言处理领域自研算法以及社区开源模型,并凭借飞桨核心框架的能力升级开放了开箱即用、极致优化的高性能一键预测功能,备受开发者喜爱。开源一年以来,团队精耕细作,不断发布适合产业界应用的模型、场景、预测加速与部署能力,在GitHub和Papers With Code等平台上持续得到开发者的关注。

近日,PaddleNLP中月均模型下载量1.9w的一键预测功能全新升级!带来更丰富的功能、更强的效果、更便捷的使用方式!我们一起来看看吧。
更丰富的功能
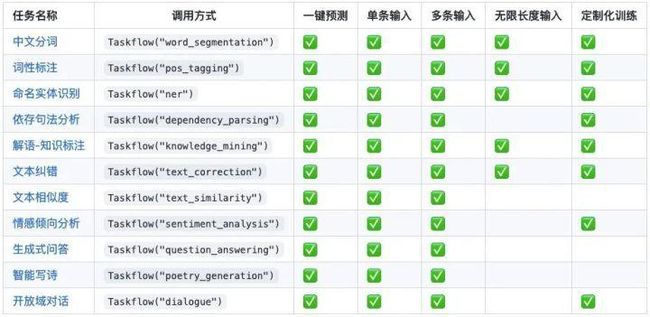
- 全场景支持
覆盖NLU(Natural Language Understanding,自然语言理解)和NLG(Natural LanguageGeneration,自然语言生成)领域十一大经典任务:中文分词、词性标注、命名实体识别、句法分析、中文知识标注、文本纠错、文本相似度、情感分析、生成式问答、智能写诗、开放域对话。
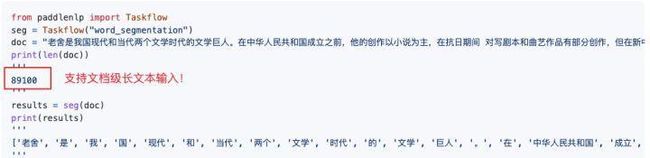
- 文档级输入
首个支持文档级输入的开箱即用NLP工具,解决预训练模型对输入文本的长度限制问题,大大节省用户输入长文本时的代码开发量。
- 定制化训练
除直接预测外,还支持使用自己的数据集,进行定制化训练。传入模型自定义路径后,仍可使用一键预测能力。

产业级效果
PaddleNLP一方面聚合了百度在语言与知识领域多年的业务积淀和领先的开源成果,如词法分析工具LAC、句法分析工具DDParser、情感分析系统Senta、文心ERNIE系列家族模型、开放域对话预训练模型PLATO、文本知识关联框架解语等;另一方面也涵盖了开源社区优秀的中文预训练模型如CPM等。实验证明,PaddleNLP在效果上全面领先同类开源产品。
- 分词
集成jieba、LAC分词工具,重磅推出基于解语(首个覆盖中文全词类的知识库——百科知识树及知识标注框架)的分词模式:实体粒度分词精度更高,语义片段完整,在知识图谱构建等应用中优势明显。

以上面这句话为例,PaddleNLP擅长精准切分实体词如“北京冬奥会”、挖掘领域新词如“自由式滑雪”等。在开源数据集上对模型效果进行评测,分词效果显著优于同类工具。
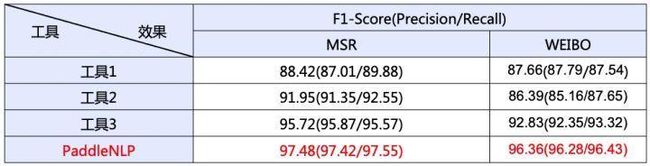
备注:该表格列出的指标是各个工具在不同数据集上进行模型微调训练后得出,这是因为目前分词结果并没有统一的标准,比如WEIBO数据集将『总冠军』作为一个完整的单词,而MSR数据集会切分为『总 冠军』,通过微调训练使得各个工具可在同一个分词标准下进行比较。
- 命名实体识别
两种模式:
1️⃣基于百度词法分析工具LAC的快速模式:训练语料包含近2200万句子,覆盖多种领域;
2️⃣基于百度解语的精确模式:具备最全中文实体标签的命名实体识别工具,不仅适用于通用领域,也适用于生物医疗、教育等垂类领域。包含66种词性及专名类别标签(同类产品的标签数是15个左右)。

PaddleNLP精确模式下的实体标签丰富,且对部分类目做了更细的划分,有利于进行精准信息抽取、构建知识图谱、支撑企业搜索等应用。例如上图例子中,『北京冬奥会』被识别为『文化类_奖项赛事活动』,而非『nz』(其他专名),可以和其他『文化类』实体有效区分开来;『自由式滑雪』也被完整识别为『事件类』实体。
在通用和垂类领域的开源数据集上比较PaddleNLP与其他工具的专名识别效果,PaddleNLP快速模式和精准模式效果均远超同类工具,如下左图所示:
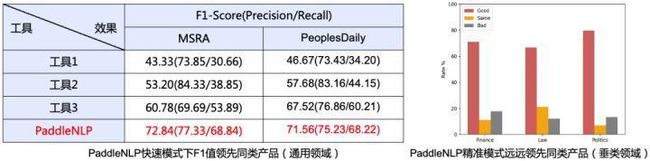
备注:在垂类领域,从金融、法律、经济领域中随机选取100条样本,人工评估精确模式效果,如上右图所示,PaddleNLP的实体抽取效果显著优于同类工具(Good:代表PaddleNLP更优)。
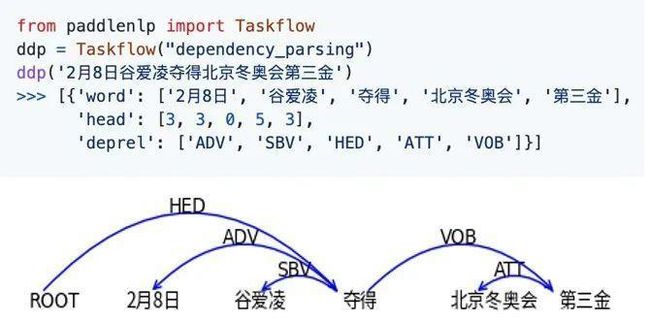
- 依存句法分析
基于已知最大规模中文依存句法树库(包含近100万句子)研发的依存句法分析工具,包含SBV(主谓关系)、VOB(动宾关系)等14种标注关系:
- 情感分析
集成百度自研的情感知识增强预训练模型SKEP,利用情感知识构建预训练目标,在海量中文数据上进行预训练,为各类情感分析任务提供统一且强大的情感语义表示能力。

- 文本相似度
收集百度知道2200万对相似句组,基于SimBERT[1]训练文本相似度模型,在多个数据集上达到了领先效果。

- 文本纠错
ERNIE-CSC在ERNIE预训练模型的基础上,融合了拼音特征的端到端中文拼写纠错模型,在SIGHAN数据集上取得了SOTA的效果。

- 首个中文多轮开放域对话预测接口;支持生成式问答、写诗等趣味应用。
开放域对话使用的PLATO-MINI模型在十亿级别的中文对话数据上进行了预训练,闲聊场景对话效果显著。
生成式问答、写诗基于开源社区优秀中文预训练模型CPM [2],参数规模26亿,预训练中文数据达100GB。

简捷易用
通过调用PaddleNLP的Taskflow API,传入任务名称即可自动选择最优的预置模型,并且以极致优化的方式完成推理。