python蓝桥杯(考前一定要掌握的常用函数及问题)
目录
-
- 注意
- 常用函数
-
- Input
- 占位符
- str类型的内建函数
- Print()
- a[起点 :终点 :步长]切片
- 数字运算
- list运算
- 刷题
-
- 1. 回文数
- 2. 水仙花数
- 3. 查找整数
- 4. 数列特征
- 5. 字母图形
- 6. 字串01
- 7. 闰年判断
- 8. 阶乘计算
- 9. 哈夫曼树
- 10. 递归问题
- 11.报时
- 1. FJ字符串
- 2. 矩形面积交
- 3. 字符串对比
- 4. 时间转换
- 5. 石子游戏
- 6. 复数求和
- 7. 最大公约数算法
- 递归
本人不才,以下是蓝桥杯中最为基础的函数,考前一定要掌握。
注意
1. 要保证数据类型对齐
a=[1,3,'5']
b=5
if b in a:
print('true')#这里输出为空,因为一个是int的5,一个是str的5
1.sort()
b=[1,6,2]
b.sort()#这里不能写b=b.sort()
print(b)
以下也是
a.append #添加的可以是str ,int
a.extend
b.insert
a.remove(10)#尽管a中有多个10,只去一个
2. count=0
def sum()
global count#定义一个全局变量
count+=1
3. 把可能出错的点找出来,防止报错
if tx < 0 or tx >= row or ty < 0 or ty >= col: # 越界情况
continue
4. while len(data)>=2:#用于判断循环,一直输出yes
print('yes')
if len(data)>=2:#只输出一个yes
print('yes')
data=5
while data >=2:#while是一直循环,变量一直被附新值
print('yes')
data-=1
6. print(round(3.5),int(3.8)) > 保留4舍5入,只保留整数
- int(input()) float(input())
常用函数
Input
1. 只需要一行输入
data = list(map(int,input().split()))
m,n = map(int,intput().split())
2. 多行输入
多个input语句,如下三种

1. Input输入返回的是str,2. 多个值就是list—input.split() 3. 根据需求map(int,input.split()) 4. 每出现一个input就代表一行 5. 加了map就表示左侧是多接收
a=input()#一个值
a,b=input().split()#左边限定为两值(空格输入,回车执行)
c=input().split()#list
1、输入一个数字直接 m = int(input()),
2、输入两个数字就是
m, n = map(int, input().split())#用了map就意为着左边是多值接收,
3. a,b=map(int,input().split("#")),
4. str=list(map(int,input().split()))#这样可以**一行输入**无线多的数据,用list盛放
5. data=[int(input()) for _ in range(10)]#将**多行input的输入**,放到一个list中
6. data=[list(map(int,input().split())) for i in range(2)]相同的思想生成数组
7. data=[tuple(map(int, input().split())) for _ in range(n)]
8. 连着输入for i in range(t):
x=input()
9. arr = input().split()#list里一个是str,一个是int
print(arr)
a=list(map(int,input().split()))
print(a)
12 6
['12', '6']
45 6
[45, 6]
9.a=2.568
a=str(a)
print(float(a[0:4])+1)#通过变成str,不4舍5入,再float成数值
print('%.2f'%(float(a)))#%.2f直接4舍5入
占位符
主要是填充格式问题,注意加‘ ’号的就成了字符,{ : #x}控制一切
%s 字符串 {:s} {:#x}.format(18)#将18保存为16进制的格式
%d 整数 {:d}
%.2f 浮点数字(用小数点符号,4舍5入) {:.2f}
%.2e 浮点数字(科学计数法) {:.2e}
‘12’12加引号的就是字符,不加就是数值
%对应{:}
print(’{}’.format(‘爱’))# %,{:} 都在print()里面
print(‘11%s’%(‘ss’))
print("我喜欢%s,%s天%.2f时"%('你',32,125.158))
print('我喜欢{},{:d}天{:.2f}时'.format('你',32,123.158))
print('{:0>5}'.format('33'))#一共填充5个数字,前4个为0
format格式化(将n按x格式化赋给a),(#:保留进制前缀)
a=format(n,‘格式’)#格式只能小写
format(18, ‘b’)#二进制
format(18, ‘#b’)#二进制
format(18, ‘x’)#16
format(18, ‘o’)#8
str类型的内建函数
# 小写 s=S.lower()
# 大写 S.upper()
#大小写互换 S.swapcase()
# 只有首字母大写 S.capitalize() L love you
# 只要遇到空格都会大写s.title L Love You
# 输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。
S.ljust(width,[fillchar])
返回字符串第一次出现的索引,如果没有匹配项则返回-1,索引从0开始,s.find针对字符串,会返回-1,s.index()针对列表,找不到直接报错
S.find('a', 0,3)在0-2的索引中找
s.rfind('a',0,3)
s='l love'
print(s.index('l'))#0 只能返回首次出现的地方
print(s.find('l',1,-1))#2 指定位置查询
# 计算substr在S中出现的次数
S.count(substr, start, end)
#把S中的oldstar替换为newstr,count为替换次数
S.replace(oldstr, newstr, count)
S.strip([chars]) 移除s list中指定的chars字符
S.split([sep, [maxsplit]]) # 以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。
S.join(seq)#.join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
a='-'
b='helloword'
print(a.join(b))
>h-e-l-l-o-w-o-r-d
str='sdfWFSDss'
a=str.find('s',0,10)#第一个s返回索引,从0开始
a=str.rfind('s',0,10)#最后一个返回索引
a=str.count('s',0,10)
a=str.replace('s','0')
a=str.strip('s')#剥离str中所有的‘s’
print(a)
Print()
for i in range(10):
print(i,end='')#打印在一行
print(i,end='\n')#换行符结尾
a[起点 :终点 :步长]切片
- 切片可以切列表,字符串,不能且int(可转化)
- 切片包含起点,不包含终点
- 对于未指明起点的,步长=1,从0开始,步长=-1,从最后一位开始
a=[0,1,2,3,4,5]
1. #对于未指明起点的,步长=1,从0开始,步长=-1,从最后一位开始
print(a[:3:1])————[0, 1, 2]
print(a[:3:-1])
>[0, 1, 2]
[5, 4]
print((a[::-1]))————[5, 4, 3, 2, 1, 0]
print(a[:2:-1])————[5, 4, 3]起点为index=-1,从后往前走,不包括终点2
2. #从起点1,倒着走到3,返回空
print(a[1:3:-1])————[]不会返回,所以为空
print(a[3:1:-1])可以
数字运算
##输入32345分别输出每位
%求余(后面只跟10) //求整
sum= a%10+a//10%10+a//100%10+a//1000%10+a//10000
》》5+4+3+2+3
a=25165
print(a%10,a//10%10,a//100%10,a//1000%10,a//10000)
print(a//10000,a//1000%10,a//100%10,a//10%10,a%10)
list运算
##二维列表:列表中的元素是列表,本质:一维列表
a=[[1,2,3],[3,4,5]]
--list.append(lista)#lista当成一个元素加到前面的列表中
--lista+listb #才是拼接
--list.extend(str)#extend()里面是字符串时,每一个字符都是一个元素,里面要是list的话,则list当成一个元素加入
>>list.extend([1,2,3])
--list.insert(index,obj)
--list.remove(obj)移除第一个匹配项
--list.index(obj)找出某个值第一个匹配项的下标
--list(seq)将字符串转为列表
--zip(list1,list2)用zip封装三列表,在for遍历
a=['sds',152, ]
b=['sds',545,'ttt']
a.append('sdf')#当成一个str加入
a.extend('sdf1')#每个字符算一个str
b.insert(1,'love')#在b的第1个位置前插入,自己成为第1个数
a.remove(152)#移除第一个匹配项
print(a)
print(b)
print(list('45125'))#将字符串转为列表
f=['sdf1']
a.extend('df1')=['sds', 'sdf', 's', 'd', 'f', '1'] a.extend(f)=['sds', 'sdf', 'sdf1']
['sds', 'love', 545, 'ttt']
['4', '5', '1', '2', '5']
用zip封装三列表,在for遍历
a=[1,1,1,1]
b=[1,1,1,1]
c=[1,1,1,1]
for i,j ,k in zip(a,b,c):
print(i,j,k)
刷题
1. 回文数
正着数和倒着数都一样,输出所有的这样的四位数
如 1221
def hui(a):
if str(a) == str(a)[::-1] and len(str(a))==4 :
print(a,end=' ')
for i in range(10000):
hui(i)
2. 水仙花数
问题描述
153是一个非常特殊的数,它等于它的每位数字的立方和,即153=111+555+333。编程求所有满足这种条件的三位十进制数。
输出格式
按从小到大的顺序输出满足条件的三位十进制数,每个数占一行。
三位数&是否满足条件,遍历
def shui(a):
if len(str(a))==3:
if int((str(a)[0]))**3+int((str(a)[1]))**3+int((str(a)[2]))**3==a:
print(a,)
def shui1(a):
if len(str(a))==3:
if (a//100)**3+(a%100//10)**3+(a%100%10)**3 == a:
print(a)
for i in range(1000):
shui(i)
3. 查找整数
给出一个包含n个整数的数列,问整数a在数列中的第一次出现是第几个。
输入格式
第一行包含一个整数n。
第二行包含n个非负整数,为给定的数列,数列中的每个数都不大于10000。
第三行包含一个整数a,为待查找的数。
输出格式
如果a在数列中出现了,输出它第一次出现的位置(位置从1开始编号),否则输出-1。
样例输入
6
1 9 4 8 3 9
9
样例输出
2
数据规模与约定
1 <= n <= 1000。
要匹配好数据格式
n = int(input())#str
arr = input().split()#list中是str
a = input()
n=int(input())#int
m=list(map(int,input().split()))#list中是int
z=int(input())
for i in range(n):
if z==m[i]:
print(i+1)
break
if z not in m:
print(-1)
4. 数列特征
max(列表)
n=int(input())
m=list(map(int,input().split()))
print(max(m))
print(min(m))
print(sum(m))
5. 字母图形
利用字母可以组成一些美丽的图形,下面给出了一个例子:
ABCDEFG
BABCDEF
CBABCDE
DCBABCD
EDCBABC
这是一个5行7列的图形,请找出这个图形的规律,并输出一个n行m列的图形。
输入格式
输入一行,包含两个整数n和m,分别表示你要输出的图形的行数的列数。
输出格式
输出n行,每个m个字符,为你的图形。
样例输入
5 7
样例输出
ABCDEFG
BABCDEF
CBABCDE
DCBABCD
EDCBABC
数据规模与约定
1 <= n, m <= 26。
利用[: : ]切片的方式,把第一个当样本,后面的都在那上面操作
a=[]
str='ABCDEFGHIJKLMNOPQRSTUVWXYZ'
a.extend(str)
m,n=map(int,input().split())
c=a[: n: 1]
for i in range(n):
print(c[i],end='')
print(end='\n')
for j in range(m-1):
d=c[j+1 : :-1]
e=c[1 :n-(j+2)+1 : 1]
for v in range(n):
print((d+e)[v],end='')
print(end='\n')
n,m = map(int,input().split())
a='ABCDEFGHIJKLMNOPQRSTUVWXYZ'
for i in range(n):
s=a[0:m]
print(s[1:i+1][::-1]+s[:m-i])
6. 字串01
对于长度为5位的一个01串,每一位都可能是0或1,一共有32种可能。它们的前几个是:
00000
00001
00010
00011
00100
请按从小到大的顺序输出这32种01串。
输入格式
本试题没有输入。
输出格式
输出32行,按从小到大的顺序每行一个长度为5的01串。
样例输出
00000
00001
00010
00011
for i in range(32):
print('{0:0>5}'.format(format(i,'b')))

7. 闰年判断
给定一个年份,判断这一年是不是闰年。
当以下情况之一满足时,这一年是闰年:
- 年份是4的倍数而不是100的倍数;
- 年份是400的倍数。
其他的年份都不是闰年。
输入格式
输入包含一个整数y,表示当前的年份。
输出格式
输出一行,如果给定的年份是闰年,则输出yes,否则输出no。
说明:当试题指定你输出一个字符串作为结果(比如本题的yes或者no,你需要严格按照试题中给定的大小写,写错大小写将不得分。
样例输入
2013
样例输出
no
样例输入
2016
样例输出
yes
数据规模与约定
1990 <= y <= 2050。
n=int(input())
if n%4==0 and n%400==0 or n%100!=0:
print('yes')
else:
print('no')
8. 阶乘计算
两个参数,一个控制数字递增,一个控制相乘
n=input()
c=1
z=[i for i in range(1,int(n)+1)]
for i in range(int(n)):
c=c*int(z[i])
print(c)
n=int(input())
a=b=1
while a<=n:
b=b*a
a+=1
print(b)
9. 哈夫曼树
问题描述
Huffman树在编码中有着广泛的应用。在这里,我们只关心Huffman树的构造过程。
给出一列数{pi}={p0, p1, …, pn-1},用这列数构造Huffman树的过程如下:
1. 找到{pi}中最小的两个数,设为pa和pb,将pa和pb从{pi}中删除掉,然后将它们的和加入到{pi}中。这个过程的费用记为pa + pb。
2. 重复步骤1,直到{pi}中只剩下一个数。
在上面的操作过程中,把所有的费用相加,就得到了构造Huffman树的总费用。
本题任务:对于给定的一个数列,现在请你求出用该数列构造Huffman树的总费用。
例如,对于数列{pi}={5, 3, 8, 2, 9},Huffman树的构造过程如下:
1. 找到{5, 3, 8, 2, 9}中最小的两个数,分别是2和3,从{pi}中删除它们并将和5加入,得到{5, 8, 9, 5},费用为5。
2. 找到{5, 8, 9, 5}中最小的两个数,分别是5和5,从{pi}中删除它们并将和10加入,得到{8, 9, 10},费用为10。
3. 找到{8, 9, 10}中最小的两个数,分别是8和9,从{pi}中删除它们并将和17加入,得到{10, 17},费用为17。
4. 找到{10, 17}中最小的两个数,分别是10和17,从{pi}中删除它们并将和27加入,得到{27},费用为27。
5. 现在,数列中只剩下一个数27,构造过程结束,总费用为5+10+17+27=59。
输入格式
输入的第一行包含一个正整数n(n<=100)。
接下来是n个正整数,表示p0, p1, …, pn-1,每个数不超过1000。
输出格式
输出用这些数构造Huffman树的总费用。
样例输入
5
5 3 8 2 9
样例输出
59
remove去除,fei+=迭代
m=int(input())
a=list(map(int,input().split()))
fei=0
while len(a)>1:
min1=min(a)
a.remove(min1)
min2=min(a)
a.remove(min2)
a.append(min1+min2)
fei+=(min1+min2)
print(fei)
pop去除,fei存到list中,求sum
m=int(input())
a=list(map(int,input().split()))
b=[0 for i in range(m-1)]
for v in range(m-1):
a.sort()
min1=a.pop(0)
min2=a.pop(0)
b[v]=min1+min2
a.append(b[v])
print(sum(b))
10. 递归问题

斐波那契
def feibo(n):
if n==1 or n==2:
return 1
return feibo(n-1)+feibo(n-2)
a=feibo(5)
print(a)
11.报时
21:54读作“twenty one fifty four”
i,m=map(int,input().split())
dic={0:'zero', 1: 'one', 2:'two', 3:'three', 4:'four', 5:'five', 6:'six', 7:'seven', 8:'eight', 9:'nine', 10:'ten', 11:'eleven', 12:'twelve', 13:'thirteen', 14:'fourteen', 15:'fifteen', 16:'sixteen', 17:'seventeen', 18:'eighteen', 19:'nineteen', 20:'twenty',30:'thirty',40:'forty',50:'fifty'}
def jisuan(n):
if n in list(dic.keys()):
n= dic[n]
return n
else:
ge=dic[n%10]
shi=dic[n-n%10]
a=shi+' '+ge
return a
print(jisuan(i)+' '+jisuan(m))
1. FJ字符串
问题描述
FJ在沙盘上写了这样一些字符串:
A1 = “A”
A2 = “ABA”
A3 = “ABACABA”
A4 = “ABACABADABACABA”
… …
你能找出其中的规律并写所有的数列AN吗?
输入格式
仅有一个数:N ≤ 26。
输出格式
请输出相应的字符串AN,以一个换行符结束。输出中不得含有多余的空格或换行、回车符。
样例输入
3
样例输出
ABACABA
递归,下一行=上一行+一个字母+上一行
q=int(input())
a='ABCDEFGHIJKLMNOPQRSTUVWXYZ'
b=[]
c=['A']
b.extend(a)
def fj(n):
if n==1:
return c
return fj(n-1)+list(b[n-1])+fj(n-1)
w=fj(q)
for i in range(len(w)):
print(w[i],end='')
chr(ord(‘A’)+i)—利用这个进行asscii和数值的转化,实现ABC自动变
n=int(input())
str=''
for i in range(n):
str=str+ chr(ord('A')+i)+ str
print(str)
2. 矩形面积交
问题描述
平面上有两个矩形,它们的边平行于直角坐标系的X轴或Y轴。对于每个矩形,我们给出它的一对相对顶点的坐标,请你编程算出两个矩形的交的面积。
输入格式
输入仅包含两行,每行描述一个矩形。
在每行中,给出矩形的一对相对顶点的坐标,每个点的坐标都用两个绝对值不超过10^7的实数表示。
输出格式
输出仅包含一个实数,为交的面积,保留到小数后两位。
样例输入
1 1 3 3
2 2 4 4
样例输出
1.00
解题思路:
重点是找到两个矩形产生交集的条件
矩阵1的对角点坐标的横坐标取最小, 矩阵2的对角点坐标的横坐标取最小,然后再从这两个值中取最大,得x1
矩阵1的对角点坐标的横坐标取最大, 矩阵2的对角点坐标的横坐标取最大,然后再从这两个值中取最小,得x2
如果x1<x2,这两个矩形才会有交集
纵坐标同理
最后交集的面积就为:
area = (x2 - x1) * (y2 - y1)
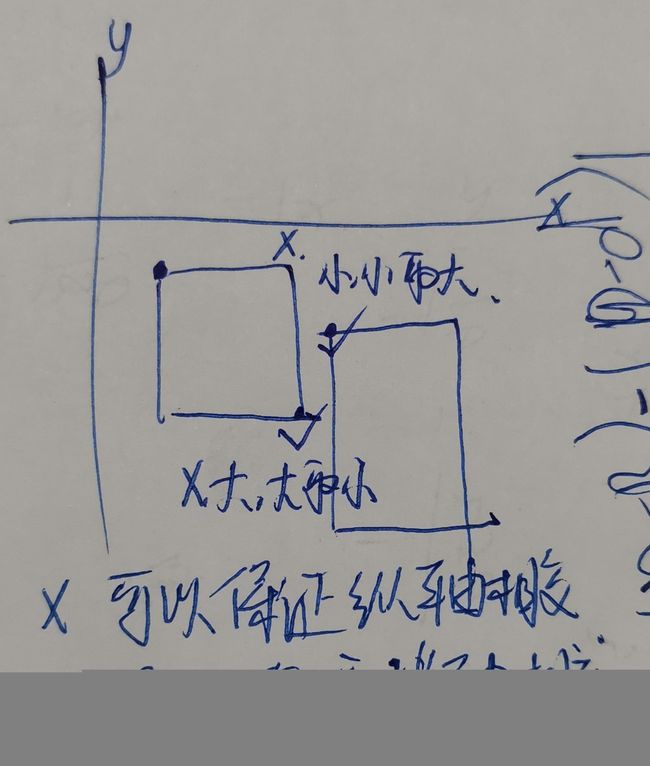
area=0
x1=max(min(rect1[0],rect1[2]),min(rect2[0],rect2[2]))
x2=min(max(rect1[0],rect1[2]),max(rect2[0],rect2[2]))
y1=max(min(rect1[1],rect1[3]),min(rect2[1],rect2[3]))
y2=min(max(rect1[1],rect1[3]),max(rect2[1],rect2[3]))
if x1<x2 and y1<y2:
print('{:.2f}'.format((y2-y1)*(x2-x1)))
else:
print('{:.2f}'.format(area))
3. 字符串对比
if elif elif(顺序执行)
只要满足一个,后面就不执行,反过来就是说它能print(4)说明前面的条件都不满足
因此elif直接是有关系的,每加一个elif就多了一个约束,一层层递进,跟下面单独写的if else是一回事
if if 是(并列运行),它们没什么关系
print(1)
str1=str(input())
str2=str(input())
if len(str1) !=len(str2):
print(1)
else:
if str1 ==str2:
print(2)
else:
if str1.upper() == str1.upper():
print(3)
else:
print(4)
4. 时间转换
问题描述
给定一个以秒为单位的时间t,要求用H:M:S的格式来表示这个时间。H表示时间,M表示分钟,而S表示秒,它们都是整数且没有前导的“0”。例如,若t=0,则应输出是“0:0:0”;若t=3661,则输出“1:1:1”。
输入格式
输入只有一行,是一个整数t(0<=t<=86399)。
输出格式
输出只有一行,是以“H:M:S”的格式所表示的时间,不包括引号。
样例输入
0
样例输出
0:0:0
样例输入
5436
样例输出
1:30:36
解题思路:
time=int(input())
print('{}:{}:{}'.format(time//3600,time%3600//60,time%3600%60))
5. 石子游戏
n=int(input())
data=[int(input()) for i in range(n)]
result=0
while len(data)>=2:
data.sort()
result+=(data[-1]+1)*(data[-2]+1)
data[-2]+=data[-1]
data.pop(-1)
print(result)
6. 复数求和
n=int(input())
data=[list(map(int,input().split())) for i in range(n)]
print(data)
for i in range(n):
if len(data[i])==1:
data[i].append(0)
x=0
y=0
for v in range(n):
x+=data[v][0]
y+=data[v][1]
print('{}+{}i'.format(x,y))
7. 最大公约数算法
辗转相除法
有两整数a和b:
① a%b得余数c
② 若c=0,则b即为两数的最大公约数
③ 若c≠0,则a=b,b=c,再回去执行①
def gong(a,b):
if a%b==0:
return b
else:
c=a%b
a=b
b=c
return gong(a,b)
n=int(input())
data=[list(map(int,input().split())) for _ in range(n)]
for i in range(n):
a=data[i][0]
b=data[i][1]
x=gong(a,b)
print(x)
== while c!=0:
a=b
b=c
c=a%b==通过while循环的方式,一直迭代
n=int(input())
data=[list(map(int,input().split())) for _ in range(n)]
for i in range(n):
a = data[i][0]
b = data[i][1]
c=a%b
while c!=0:
a=b
b=c
c=a%b
print(b)
递归




def func(x):
if x>0:
print('抱着',end='')
func(x-1)
print('的我',end='')
else:
print('我的小鲤鱼',end='')
func(2)